基于改进YOLOv8的小棚架下无核白葡萄果梗识别
2025-02-26李涛买买提明⋅艾尼古丽巴哈尔⋅托乎提杨佳雨



摘要:小棚架下准确识别无核白葡萄果梗是葡萄采摘机器人自动采摘任务的关键。针对新疆吐鲁番市小棚架下鲜食无核白葡萄果梗识别效果差的问题,提出一种基于YOLOv8的无核白葡萄果梗识别模型Small—YOLO,实现无核白葡萄果梗的自动识别。在原有的模型结构上改进目标检测头,提高浅层与深层网络的特征融合,增加对无核白葡萄果梗信息提取的能力。在浅层网络中采用可变形卷积DCN以增强卷积操作对形态变化的建模能力,使得卷积核可以更好地适应输入特征图中的不规则变形,有助于提高视觉模型在处理不同尺度、形态和变换目标时的性能。增加坐标注意力机制CA,优化无核白葡萄果梗识别的准确率。结果表明,改进后的识别模型对无核白葡萄果梗平均精度mAP值达到76.2%。与YOLOv3—tiny、YOLOv5n、YOLOv6、YOLOv7、YOLOv8n等算法相比,mAP值分别提升23.9%、8%、7.6%、9.2%、7%,同时保持较快的检测速度,实现在小棚架下无核白葡萄机械采摘可能性。
关键词:无核白葡萄;采摘机器人;果梗识别;坐标注意力机制;可变形卷积;视觉模型
中图分类号:S663.1; TP391.4""""""文献标识码:A""""""文章编号:2095‑5553"(2025)"02‑0259‑06
Seedless white grape stem recognition under small trellises based on improved YOLOv8
Li Tao1, Mamtimin"⋅"Geni1, 2, Gulbahar"⋅"Tohti1, Yang Jiayu1
(1. School of Intelligent Manufacturing Modern Industry, Xinjiang University, Urumqi, 830047, China;
2. Urumqi Baybol Metronocs Technology Co. Ltd., Urumqi, 830002, China)
Abstract: Accurate identification of seedless white grape stem under small trellises is the key to the automatic picking task of grape picking robot. Aiming at the problem of poor recognition effect of fresh seedless white grape stem under Small trellises in Turfan City, Xinjiang, a seedless white grape stems recognition model Small—YOLO based on YOLOv8 was proposed to realize automatic recognition of seedless white grape stem, improve the target detection head on the original model structure, and improve the feature fusion of shallow and deep networks. The ability of extracting information from the seedless white grape stem was increased. Deformable convolutional DCN is used in the shallow network to enhance the modeling ability of convolution operation on morphological changes, so that the convolutional kernel can better adapt to the irregular deformation in the input feature map, which is helpful to improve the performance of the visual model when dealing with targets of different scales, shapes and transformations, increase the coordinate attention mechanism CA, optimize the accuracy rate of the seedless white grape peduncle recognition. The test results showed that the mAP value of the improved recognition model for the seedless white grape stem reached 76.2%. Compared with YOLOv3—tiny, YOLOv5n, YOLOv6, YOLOv7, YOLOv8n and other algorithms, the mAP value was improved by 23.9%, 8%, 7.6%, 9.2%, 7%, respectively, while maintaining a fast detection speed, realizing the possibility of the seedless white grape mechanical picking under small tallows.
Keywords: seedless white grapes; harvesting robot; stem recognition; coordinate attention mechanism; deformable convolution; visual model
收稿日期:2023年10月24日""""""" 修回日期:2023年12月18日
∗ 基金项目:国家自然科学基金资助项目(12162031)
第一作者:李涛,男,1995年生,四川南充人,硕士;研究方向为机械设计和图像识别。E‑mail: 1378800938@qq.com
通讯作者:买买提明"⋅"艾尼,男,1958年生,乌鲁木齐人,博士,教授;研究方向为农牧机械设计理论与方法、图像识别等。E‑mail: mgheni@263.com
0 引言
2022年,中国葡萄产量15"378"kt,新疆葡萄产量完成3"165"kt,占全国葡萄总产量的20.58%[1],新疆吐鲁番市葡萄种植面积达36"khm2,占新疆葡萄种植总面积的39.6%,占全国葡萄种植总面积的8.1%[2],其中无核白葡萄产量占比90%[3]。吐鲁番市葡萄种植采用小棚架模式,小棚架高1.6"m,宽2"m,长10~50"m,葡萄架低矮,采摘高度较为低矮,人工采摘效率低,用工季节葡萄采摘费昂贵。在图像处理领域,对于小目标的定义有多种方式,一种是将大小低于图像高度10%的检测目标或大小低于图像高度的20%的识别目标定义为小目标[4]。另一种方式,如MSCOCO数据集[5]则将像素绝对值小于32×32的目标定义为小目标。
在现有葡萄识别研究中,识别对象主要是葡萄果实,且通常针对篱架和大棚架种植模式下的葡萄,这些场景相对开阔。Liu等[6]在研究葡萄采摘机器人中提出一种葡萄串分割算法,检测准确率为88.0%。Reis等[7]在夜间利用闪光灯拍摄白葡萄与红葡萄在进行图像处理得到葡萄串,正确率为97%。Wu等[8]使用YOLOv5目标检测算法来识别葡萄串,并应用关键点检测模型来定位葡萄果梗,平均准确率约为92%。Qiu等[9]用一种基于改进YOLOv4的葡萄成熟度检测和视觉预定位算法,平均准确率达到93.52%,平均检测时间为10.82"ms。罗陆锋等[10]采用基于深度学习的葡萄果梗识别与最优采摘定位方法,利用Mask"R—CNN模型在不同天气光照下该方法对葡萄果梗的检测精确率平均值为88%。李慧鹏等[11]使用PSPNet(MobileNetv2)语义分割模型分割葡萄图像,采用霍夫变换检测果梗边缘上的直线段并进行直线拟合,采摘点定位准确率为91.94%,定位时间为187.47"ms。然而,在吐鲁番地区的小棚架环境中,针对吐鲁番特有的无核白葡萄的果梗识别研究尚属空白。
本文提出一种基于YOLOv8n的无核白葡萄果梗识别模型(Small—YOLO),为评估Small—YOLO模型的性能,分析吐鲁番小棚架下无核白葡萄果梗数据集,在无核白葡萄果梗数据集中,进行YOLOv3—tiny、YOLOv5n、YOLOv6、YOLOv7和YOLOv8n模型试验对比。此外,还分析基于YOLOv8n改进Small模型、Small+DCN模型、Small+CA模型和Small—YOLO模型的性能,得到各个模型改进的有效性。
1 数据获取
数据来源于新疆维吾尔自治区吐鲁番市高昌区(北纬41°12′~43°40′,东经87°16′~91°55′)。数据采集时间是葡萄采收时期,采集设备是OnePlus"Ace"2V,vivo手机。为确保数据的多样性与可靠性,分别采集经过农艺处理、近景、强光和遮光等场景中无核白葡萄果梗图像,共3"994张(分辨率为3"468像素×4"624像素的RGB图像)。图1为小棚架下无核白葡萄果梗样本。
2 改进YOLOv8n模型
2.1"YOLOv8n模型
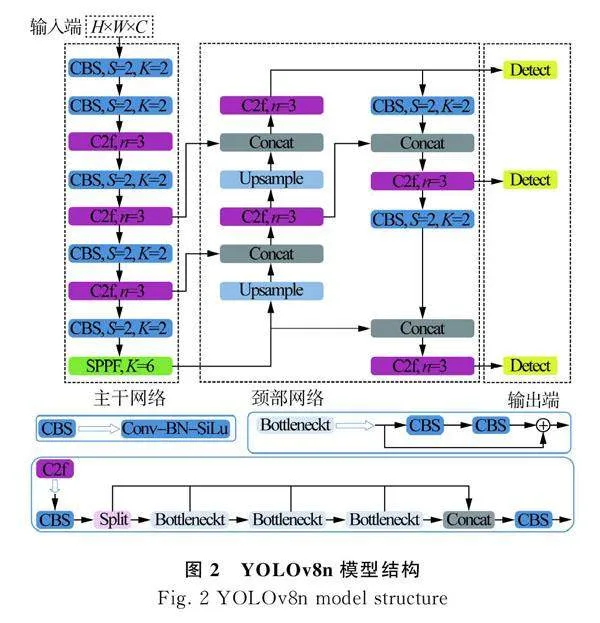
YOLOv8n模型主要由输入端、主干网络、颈部网络和输出端4部分组成。YOLOv8n[12]在输入端会对输入图片大小进行归一化处理。主干网络主要由Conv[13]、C2f、SPPF等模块组成。Conv包括Conv2d、BatchNorm2d和SiLU激活函数。C2f模块是对C3模块的改进,主要用来增强特征融合能力,提高检测速度,实现模型整体的轻量化。SPPF是YOLOv8n对SPP[14]模块改进的一个空间金字塔池化层,可以扩展接受域,实现局部和全局特征融合,丰富特征信息。颈部网络通过FPN[15]+PAN[16]的结构来解决特征信息的多尺度融合问题。输出端采用解耦头结构将分类和检测头分离,使用Anchor—Free[17]的思想。YOLOv8n模型结构如图2所示。
2.2"Small—YOLO模型
2.2.1"YOLOv8n模型的改进
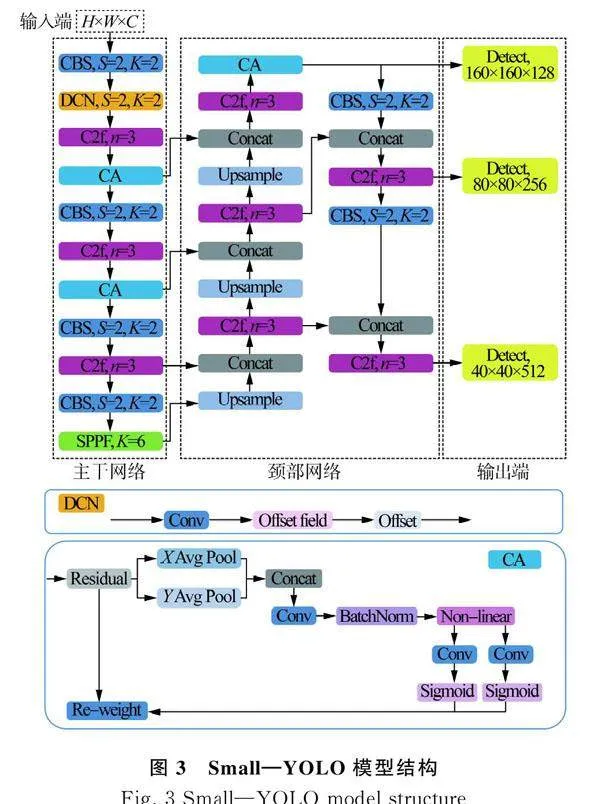
随着网络模型层数增多,深层特征图的感受野更大,但分辨率低,特征图信息更少;浅层的特征图含有小的感受野,特征细节信息丰富。采用改进的Small模型将YOLOv8n模型主干网络第2层与颈部网络14层融合引出一个目标检测头,提取浅层的特征图中无核白葡萄果梗的特征信息,解决无核白葡萄果梗特征信息随着网络模型层数增多而特征信息丢失问题,由于无核白葡萄果梗数据集中没有大目标,将深层检测头去掉,减少模型参数量,在此基础上使用160×160、80×80、40×40网络的检测头,得到的整体信息更加全面。Small—YOLO模型结构是在Small模型基础上,为解决浅层的特征图中无核白葡萄果梗特征信息提取不充分问题,将浅层的标准卷积替换为可变形卷积DCN,在主干网络和颈部网络添加CA坐标注意力机制[18],分别加在第3层和21层,充分提取无核白葡萄果梗的特征。Small—YOLO模型结构如图3所示。
2.2.2 坐标注意力机制CA
受小棚架种植模式影响,光线、遮挡因素严重,无核白葡萄果梗识别效果不好,采用坐标注意力机制CA增强网络模型对无核白葡萄果梗特征提取能力。坐标注意力机制CA的核心思想是利用水平和垂直方向上的平均池化计算坐标信息,将坐标信息与原始特征图相结合,从而提高特征的提取能力。坐标注意力机制CA的工作流程包括以下步骤:首先,输入特征图经过自适应平均池化,得到水平和垂直方向上的均值信息;然后,这两个均值信息被连接在一起,经过卷积和归一化操作,降低通道数;接下来,特征图被分割为水平和垂直部分,分别通过卷积层计算注意力权重;最后,特征图根据注意力权重进行加权,得到增强后的表示。捕获特征图中的细节信息和上下文信息,且具有较小计算开销。
2.2.3 可变形卷积DCN
标准卷积核通常采用规则的采样点对输入特征图进行卷积操作。在同一卷积层中,所有卷积核的感受野都相同。由于输入特征图中不同位置可能对应不同尺度、形态、视角和几何变化的目标,如何适应这些目标的多样性是视觉识别的一项重要挑战。为解决该问题,采用可变形卷积模块,以增强卷积操作对形态变化的建模能力。如图3所示,可变形卷积DCN对输入特征图进行卷积生成位置偏移量,根据位置偏移量对卷积和进行像素位置变换,输出特征图。可变形卷积引入对卷积核中每个采样点位置的自适应偏移,从而实现灵活的采样,不再受限于规则的格点采样,使得卷积核可以更好地适应输入特征图中的不规则变形,有助于提高视觉模型在处理不同尺度、形态和变换目标时的性能。
2.3 平台配置与训练策略
试验平台在Windows10操作系统和cudnn11.0环境下进行,GPU配置NVIDIAGeForceRTX3070,显存8"GB,调用GPU进行训练,中央处理器Intel(R)Core(TM)"i7-10875"H"CPU"@2.30"GHz,运行内存为16"GB,固态硬盘500"GB,所有程序在pytorch1.12深度学习框架下用Python语言编写,并使用NVIDIA"CUDA11.6并行运算驱动加速训练。
在所有试验训练参数设置中,输入图像大小为640像素×640像素。优化器采用SGD驱动量优化器。初始学习率设置为0.001,衰减系数为0.01,动量为0.9,批次大小为16个,共进行300轮训练。在训练过程中使用了热身训练,为提高模型的鲁棒性,在模型训练过程中使用马赛克增强,通过随机剪裁、缩放、翻转、色彩变化的图像增强操作后,再随机拼接成一张图片进行训练,丰富数据的多样性。
2.4 评价指标
采用召回率R、精确率P、平均精度均值mAP和每秒检测图像帧数FPS作为评价指标。
式中: [TP]——模型将正样本识别为正样本,即正确识别出目标的情况;
[FP]——模型将正样本识别为负样本,即未被识别到目标的情况;
[FN]——负样本被识别为正样本,即背景被错误认为是目标的情况。
3 结果与分析
3.1 无核白葡萄果梗数据集分析
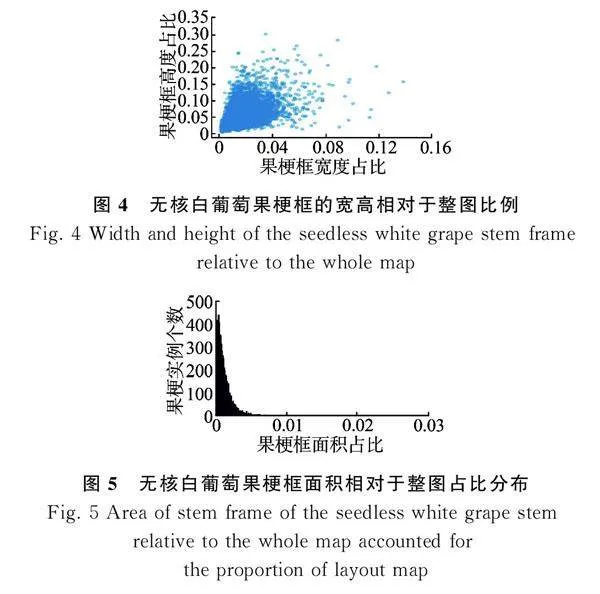
从最初的3"994张RGB图像中剔除没有果梗、虚影、拖影、重复的图像后,剩余3"435张RGB"图像作为原始数据集。使用YOLO格式的数据集,采用LabelImg图像标注工具在RGB图像上进行葡萄果梗标注。为精确识别无核白葡萄果梗,其余未标注部分由LabelImg默认为背景。将标记好的图像按照8∶1∶1的比例划分成训练集、验证集与测试集,其中训练集图像2"747张,验证集图像344张,测试集图像344张。如图4所示。无核白葡萄果梗框的宽相对于整幅图比例集中在0~0.025,无核白葡萄果梗框高相对于整幅图比例集中在0~0.15,可以看出无核白葡萄果梗更细。如图5所示,果梗框的面积相对于整幅图面积占比0~0.005为主要集中区域,因此无核白葡萄果梗属于小目标的检测范围。
3.2"YOLOv8n模型与其他模型对比
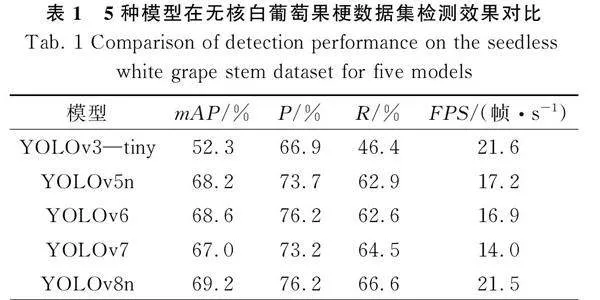
为验证YOLOv8n在无核白葡萄果梗数据集上检测效果,分别将YOLOv3—tiny、YOLOv5n、YOLOv6、YOLOv7和YOLOv8n五种网络模型在无核白葡萄数据集上进行训练,在相同迭代次数内,YOLOv8n的mAP值比YOLOv3—tiny、YOLOv5n、YOLOv6网络模型高16.9%、1%、0.6%、2.2%,说明YOLOv8n模型对无核白葡萄果梗特征提取效果更好,试验结果如表1所示。
3.3 消融试验
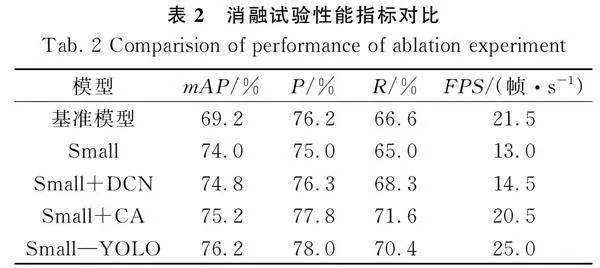
将YOLOv8n模型作为基准模型,以平均精度均值mAP、精确率P、召回率R和FPS作为评价指标,在无核白葡萄果梗数据集上进行4组消融试验,验证不同改进点的有效性。通过对YOLOv8n模型改进进行消融试验分别取模型在无核白葡萄果梗验证集进行验证,试验结果如表2所示。
Small模型表示对YOLOv8n模型检测头进行改进,Small+DCN模型表示在Small模型的基础上将主干网络第2层的标准卷积替换成可变形卷积DCN,Small+CA模型表示在Small模型的基础上,主干网络第3层和第6层以及颈部网络第20层添加坐标注意力机制CA,Small—YOLO模型是融合以上3种模型。改进Small—YOLO相对YOLOv8n基准模型在mAP、P、R上分别高7%、2%、3.8%,FPS基本保持不变。采用Small模型相对基准模型在mAP、P、R上均有提升,但是FPS下降了40%,采用Small+DCN模型使得召回率R提升1.7%,精确率P提升0.1%,平均精度均值mAP值提升5.6%,采用Small+CA模型使得平均精度均值mAP值提升6%,精确率P提升1.6%,召回率R提升5%。可见所用方法都能有效提升网络性能。
3.4 小棚架下无核白葡萄果梗识别效果
利用改进后的Small—YOLO模型对无核白葡萄果梗数据集进行训练与验证,并在验证集中进行测试,测试效果如图6所示。将无核白葡萄果梗识别效果图中果梗局部放大,发现无核白葡萄在小棚架下农艺处理后、近景、遮光远景及强光场景中,无核白葡萄果梗都能被识别出来,说明Small—YOLO模型在复杂情景中鲁棒性较好。枝叶与果梗十分相近的情况下也会出现错识别情况,在错误识别果梗的情况中,其置信度较低,因此可以通过设置置信度阈值来减少错误识别,在后续的实际部署上可以规避此类问题。
4 结论
提出Small—YOLO模型实现无核白葡萄果梗识别,完成鲜食无核白葡萄无损采摘机器人的关键环节,建立无核白葡萄果梗数据集,改进模型检测头,采用DCN动态卷积和CA坐标注意力机制提升模型识别效果,实现对小目标识别,并与其他算法相比。
1)"在无核白葡萄果梗数据集上,相比YOLOv3—tiny、YOLOv5"n、YOLOv6、YOLOv7、YOLOv8模型,Small—YOLO模型在平均精度均值上分别提高23.9%、8%、7.6%、9.2%、7%,在准确率上提高11.1%、4.3%、1.8%、4.8%、1.8%,在召回率上提升24%、7.5%、7.8%、5.9%、3.8%。
2)"无核白葡萄果梗数据集中,果梗面积占比在0.005以下,属于小目标,采用改进Small—YOLO模型的FPS由21.5帧/s提高至25帧/s,有效提升模型识别果梗性能。
3)"针对目标特征提取不充分问题,Small—YOLO模型采用坐标注意力机制CA和将浅层标准卷积替换为可变形卷积DCN,有效提升模型的识别性能。该模型特别针对吐鲁番市小棚架下无核白葡萄的果梗进行识别,为采摘机器人在无核白葡萄果梗采摘作业中的应用提供研究基础。
参 考 文 献
[ 1 ]""""" 国家统计局. 中国统计年鉴[J]. 北京: 中国统计出版社, 2022.
[ 2 ]""""" 吾尔尼沙⋅卡得尔, 刘凤之, 刘丽媛. 新疆吐鲁番葡萄产业发展及转型升级建议[J]. 中国果树, 2021(11): 94-97.
[ 3 ]""""" 满保德. 新疆吐鲁番地区葡萄产业发展对策研究[D]. 石河子: 石河子大学, 2017.
[ 4 ]""""" Akyon F C, Altinuc S O, Temizel A. Slicing aided hyper inference and fine‑tuning for small object detection [C]. 2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022: 966-970.
[ 5 ]""""" Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: Common objects in context [C]. Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer International Publishing, 2014: 740-755.
[ 6 ]"""" Liu S, Whitty M. Automatic grape bunch detection in vineyards with an SVM classifier [J]. Journal of Applied Logic, 2015, 13(4): 643-653.
[ 7 ]""""" Reis M J C S, Morais R, Peres E, et al. Automatic detection of bunches of grapes in natural environment from color images [J]. Journal of Applied Logic, 2012, 10(4): 285-290.
[ 8 ]""""" Wu Z, Xia F, Zhou S, et al. A method for identifying grape stems using keypoints [J]. Computers and Electronics in Agriculture, 2023, 209: 107825.
[ 9 ]""""" Qiu C, Tian G, Zhao J, et al. Grape maturity detection and visual pre‑positioning based on improved Yolov4 [J]. Electronics, 2022, 11(17): 2677.
[10]""""" 罗陆锋, 邹湘军, 熊俊涛, 等. 自然环境下葡萄采摘机器人采摘点的自动定位[J]. 农业工程学报, 2015, 31(2): 14-21.
Luo Lufeng, Zou Xiangjun, Xiong Juntao, et al. Automatic positioning for picking point of grape picking robot in natural environment [J]. Transactions of the Chinese Society of Agricultural Engineering, 2015, 31(2): 14-21.
[11]""""" 李惠鹏, 李长勇, 李贵宾, 等. 基于深度学习的多品种鲜食葡萄采摘点定位[J]. 中国农机化学报, 2022, 43(12): 155-161.
Li Huipeng, Li Changyong, Li Guibing, et al. Picking point positioning of multi‑variety table grapes based on deep‑learning [J]. Journal of Chinese Agricultural Mechanization, 2022, 43(12): 155-161.
[12]""""" Terven J, Córdova‑Esparza D M, Romero‑González J A. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS[J]. Machine Learning and Knowledge Extraction, 2023, 5(4): 1680-1716.
[13]"""" Liu Z, Mao H, Wu C Y, et al. A convnet for the 2020s [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 11976-11986.
[14]""""" He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[15]""""" Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2117-2125.
[16]""""" Wang C, Xu C, Wang C, et al. Perceptual adversarial networks for image‑to‑image transformation [J]. IEEE Transactions on Image Processing, 2018, 27(8): 4066-4079.
[17]""""" Tian Z, Shen C, Chen H, et al. FCOS: Fully convolutional one‑stage object detection [C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 9627-9636.
[18]""""" Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13713-13722.
