面向对抗干扰的小样本人脸识别算法研究
2025-02-23王一波杨玉华娄伯韬张胜利




摘 要:由于目前的人脸识别算法在样本不足且有对抗干扰的人脸识别应用场景中存在局限性,提出一种基于对称网络的识别算法。首先基于小样本进行对称网络训练,以获得样本的特征向量,确保同类样本特征向量距离近,异类样本特征向量距离远;然后基于样本特征向量训练SVM分类器,以进行人脸检测;同时引入PGD攻击算法,通过对抗攻击获得对抗样本,基于对抗样本进行模型训练,提升模型的鲁棒性。在ORL数据集上进行实验,结果表明,该面向对抗干扰的小样本人脸识别算法准确率较高,优于传统单边CNN模型的效果,能够实现样本不足且有对抗干扰的人脸识别。
关键词:对称网络;小样本;人脸识别;对抗干扰;PGD攻击算法;支持向量机
中图分类号:TP39 文献标识码:A 文章编号:2095-1302(2025)04-00-04
0 引 言
人脸识别目前已得到广泛的使用。如何不断提升算法的准确率和鲁棒性仍然是模式识别及机器视觉领域研究的热点。该算法的基本原理:将二维或者三维的人脸图像通过某种方法进行简化的特征表达,然后运用相关分类算法对其进行类别划分。如果从特征抽取角度来看,人脸识别主要包括人工设计特征与深度学习自动表示特征2种技术路线。2种路线各有优势,其中前者属于传统的方法。目前仍有许多研究人员力求通过把握人脸的本质特性,设计出能够鲁棒表达人脸的简洁特征。文献[1]较好地融合了降维和稀疏描述的优势,达到了对人脸特征降维的目的。文献[2]通过改进局部二值模式(Local Binary Patterns, LBP),在不同灰度层内提取人脸的LBP 特征,再通过加权融合实现复杂光照下的人脸识别。文献[3]提出了新的Face Relighting方法,即对多种阴影进行建模,同时保留局部人脸细节。文献[4]提出了一种用于面部模板保护的模块化体系架构,可以与使用角距离度量的任何面部表情识别系统结合使用。
人工设计特征费时费力,需要研究人员具有高度的敏锐性,而随着深度学习技术的不断发展,借助深度模型无监督获取特征表示,越来越受到研究人员的青睐。目前广泛使用的单阶段人脸识别深度框架有YOLO、SSD[5-6],两阶段人脸识别框架(即特征抽取和目标检测)有R-CNN、FastR-CNN[7-8]。之后在以上模型的基础上,通过不断改进,基于深度学习的人脸识别算法的性能也得到不断提升,但其优越的性能建立在不断庞大的数据集和不断扩充的网络深度基础上,对于难以得到大量数据以及需要轻量化部署的场合并不适用。同时,人脸识别在很多应用场景中对于容错性要求非常高,但在实际生产中,由于图像采集时的灯光、镜头、图像传输等多种设备的影响,可能采集到对抗样本[9-10]。根据正常图像分类梯度信息,将对抗攻击算法生成的对抗扰动叠加在正常图像上可以形成对抗样本,导致深度网络错误地推理对抗样本的类别。所以如何基于小样本实现具有一定抗攻击能力的人脸识别算法成为当下重要的研究课题。
本文将构建小规模的孪生卷积,对小样本进行训练,学习稳定的人脸特征,同时引入攻击算法,提升人脸识别的鲁棒性。
1 算法基本原理
1.1 对称网络特征提取的基本原理
对称网络是一种特殊的神经网络架构,由2个或更多相同的子网络组成,如图1所示。每个子网络接收1个输入并提取出对应的特征向量,然后通过度量层计算这些特征向量之间的相似性得分,在训练过程中,使用对比损失或三元组损失等损失函数,最小化相似输入对的特征距离,最大化不相似输入对的特征距离,从而自动学习输入之间的相似度度量[11]。子网络通常由卷积层、池化层、全连接层等构成。对于每个输入,子网络会提取出一个特征向量。在训练过程中,孪生网络的子网络会共享权重参数,反向传播算法更新这些共享参数,使得相似输入对的特征向量距离最小化,不相似对的特征向量距离最大化。
1.2 PGD攻击的基本原理
PGD(Projected Gradient Descent)对抗攻击为FGSM(Fast Gradient Sign Method)的一种迭代改进。核心思想为通过多次迭代来逐步逼近最优的对抗样本,同时每次迭代都根据当前样本的梯度信息来更新样本,并将更新后的样本裁剪到规定的范围内。具体过程如下:
(1)初始化一个被添加对抗扰动的样本;
(2)计算损失函数的梯度;
(3)计算扰动;
(4)添加并将扰动约束在邻域内,得到对抗样本;
(5)将对抗样本输入模型,计算新的损失函数,重复步骤(2)~步骤(4),多次迭代。
与FGSM相比,PGD攻击通过多次迭代和裁剪操作,能够更精确地找到误导目标模型的对抗样本。同时,由于PGD攻击在每次迭代中都会根据最新的梯度信息来更新样本,因此它对于非线性模型具有更好的攻击效果。这是因为对于非线性模型,仅仅进行一次迭代可能无法找到最优的对抗方向,而多次迭代则能够逐步逼近最优解。
2 基于对称网络的识别算法
2.1 网络结构
子图像特征提取的网络结构如图2所示,包含2个卷积层、1个最大池化层、1个Dropout层及1个Flatten层。接受输入(input)的第1个卷积层拥有最少32个卷积核,第2个卷积层拥有64个卷积核数,即该层输出的特征通道数为64,其中每个卷积层都伴有ReLU层。为降低过拟合风险,加入Dropout层,最后通过Flatten层展平为1个向量。在提取图像特征时会通过降维的方式优化网络模型,不仅能减少网络参数,还有利于得到图像高层级的语义信息,但网络在降维的同时也丢失了低层级的像素信息,使得其在表面图像人脸识别时不太友好,所以本文使用128维特征信息作为后续模块的输入,最大限度保留原有图像的特征信息。
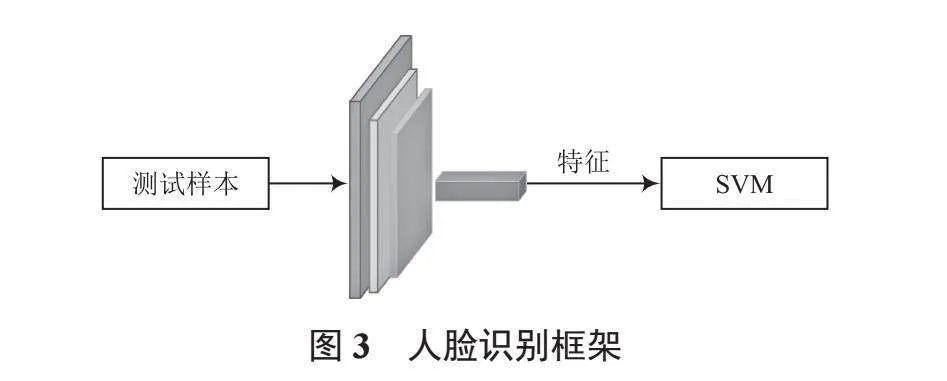
在上述过程中得到特征提取模块,在此基础上构建完整的表面人脸检测模型,如图3所示。首先将训练样本输入到特征提取网络得到训练特征向量,用其训练SVM分类器,然后将测试样本输入特征提取网络,得到测试特征向量,再基于已训练好的SVM分类器进行检测。
2.2 损失函数
为了增强模型对类间样本特征差异的敏感性,本文构建了基于类别敏感的正负样本对。三元数表示样本对(a, a', ya),a、a'表示输入对称网络的样本对,ya表示样本对标签。当ya=0时,表示正样本对,即a与a'为同类别;否则表示负样本对,即a与a'为相反类别。
由于训练目标为最小化正样本之间的差异,并扩大负样本之间的差异,本文设计并提出了特征一致性约束策略的模型特征提取模块损失函数:
(1)
式中:θ表示对称特征提取模块的模型参数;Fa、Fa'分别表示经特征提取模块产生的特征;N表示样本对的总数;m表示决定负样本对距离上限的边界值(Margin),该值根据实际情况确定;Dθ表示样本对经过特征提取后特征空间上的距离表达。本文在此使用欧几里得距离公式,如式(2)所示:
(2)
这种损失函数可以很好地表达成对样本的匹配程度,也能够很好地用于训练相关模型。根据特征一致性约束公式可以发现,当ya=0时,模型会更新最小化原始图像与其对抗变体之间的距离,即最小化类内间距;相反,当ya=1时,且负样本对之间的距离大于m时,损失值等于0,即模型不做优化,而当负样本对之间的距离小于m时,此时模型将负样本对的距离增大到m,即增大类间间距。
2.3 网络训练
模型训练分为2个阶段。首先对特征提取模块进行对抗训练,然后再对分类模块进行训练。特征提取模块训练过程
如下:
(1)训练开始时,将训练样本设置为相同尺寸;
(2)运用PGD算法攻击训练样本;
(3)将各类样本打乱顺序分别放入2个队列之中;
(4)以20的batch size分批随机读取以上队列中的数据,送入对称网络;
(5)经过特征提取网络提取特征向量后,计算出该批次的平均loss值,之后通过Adam自适应梯度下降算法,更新各层的权值与偏置等参数;
(6)重复步骤(2)~步骤(4),直至达到最大训练轮次。
在特征提取模块训练基础上,基于训练特征向量对SVM分类模块进行训练,在此选用线性核函数。
3 实 验
3.1 数据集
本文采用的ORL人脸数据库共有400幅图像,涉及40个人的不同表情、不同穿戴,其中每人10幅图像。ORL人脸数据库中原始图像大小为112×92,实验中采用的图像大小为50×50。随机选取若干幅图像作为训练样本,其余图像作为测试样本,归一化处理每一幅图像。部分人脸样本图像如图4所示。
实验所采用的硬件和软件配置:CPU为17-12700K"3.6 GHz,GPU为英伟达RTX3090TI,Python版本为3.8.5。深度学习框架采用PyTorch 1.13.0搭建,操作系统采用Windows 10。实验参数中batch size为30,epoch为20,学习率为0.01。
3.2 结果与分析
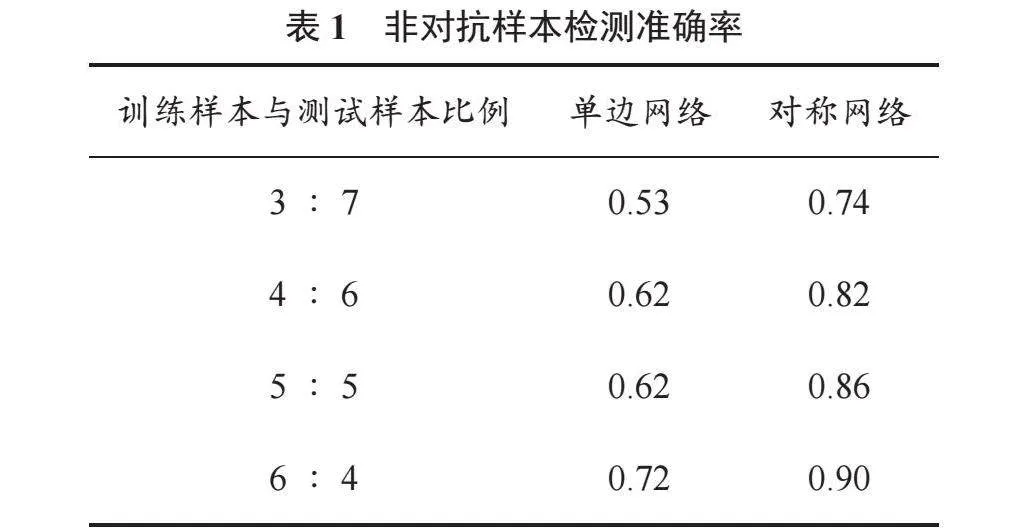
将非对抗样本集按照一定比例划分为训练集和测试集,使用训练集分别训练单边分类网络(由特征提取模块和分类模块构成,其中特征提取模块与对称网络相同)及对称网络。单边分类网络具有分类模块,可以直接使用测试集进行人脸检测测试;对称网络利用训练好的特征提取网络对训练集和测试集进行处理,得到对应的训练特征向量集与测试特征向量集,然后利用训练特征向量集基于SVM进行分类训练,最后利用SVM分类器计算测试特征向量集的准确率(图像分辨率为250)。非对抗样本检测准确率见表1。
在未对样本集进行增强的情况下,以上训练样本数量分别是120、160、200、240,相较于一般模型训练需要的样本数量非常少。由表1看出,训练样本数量与模型检测准确率呈正相关,即训练数量越大,则检测准确率越高;单边网络在低样本情况下,准确率维持在0.6左右,而对称网络通过重塑特征空间,让相同类别样本特征向量尽量靠近,不同类别样本特征向量尽可能远离,为分类提供了良好的基础。结果表明,对对称网络,即使在训练样本数量仅为120时,其检测准确率也可以达到0.742 9;当训练样本数量为240时,其检测准确率超过了0.9,远远高于单边网络。
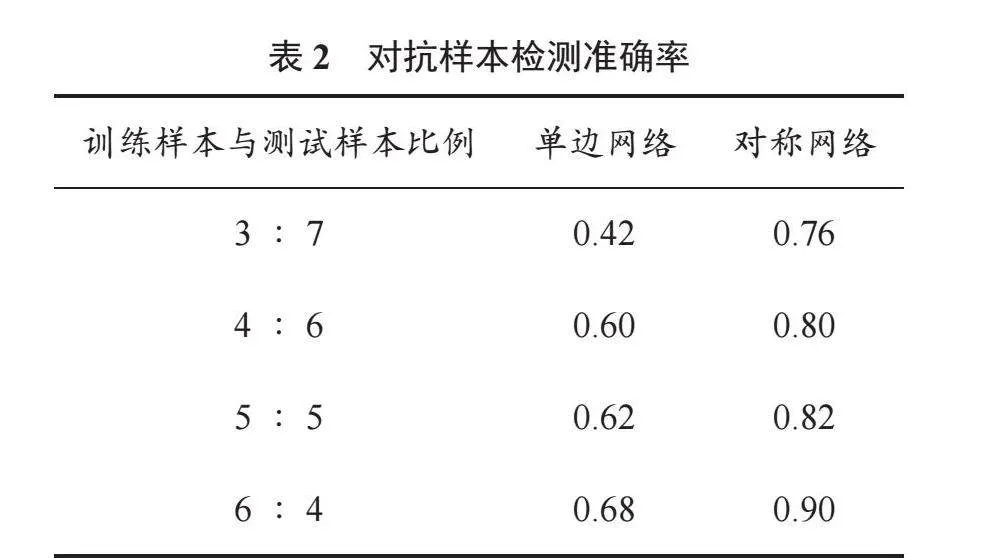
使用对抗样本集分别训练单边分类网络及对称网络。对抗样本检测准确率见表2。
由表2可以看出:对抗样本的检测准确率整体下降。其中,单边网络受影响更加明显,同时其检测准确率与训练样本数量的正相关性消失。这是因为训练样本数量越多,则受到攻击的样本也越多,因此对网络产生的不良影响也将越大。对称网络虽然也受到对抗样本的影响,但当训练样本数量增加后,这种影响将变得很小。由此可见,对称网络抗干扰性较单边网络更强,具有较好的鲁棒性。
4 结 语
本文提出了一种新的人脸识别方法。该方法使用对称网络对人脸图像进行识别分类。与传统人脸识别方法相比,其具有以下优势:
(1)在传统DNN网络的基础上引入对称思想,使特征空间类内间距尽可能小、类间间距尽可能大,约束网络训练,实现对于干扰样本的鲁棒检测;
(2)充分发挥对称网络可以实现“one shot learning”的特点,在不需要扩充大量训练数据的前提下,可以自定义增加需要检测的人脸数目。
未来,本文的研究将涉及复杂背景下精确的人脸定位等方面,通过进一步优化模型结构,提升模型泛化能力。
注:本文通讯作者为张胜利。
参考文献
[1]程鸿芳,祝军.基于改进的稀疏描述和降维人脸识别方法[J].绵阳师范学院学报(自然科学版),2023,42(11):89-96.
[2]李根,岳望.复杂光照下LBP人脸识别算法的改进[J].信息与电脑,2023,15:106-109.
[3] HOU A, ZHANG Z, SARKIS M, et al. Towards high fidelity face relighting with realistic shadows [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021.
[4] KIM S, JEONG Y, KIM J, et al. IronMask: modular architecture for protecting deep face template [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021.
[5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 779-788.
[6] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multi box detector [C]// European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
[7] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014: 580-587.
[8] GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1440-1448.
[9] GOODFELLOW I, SHLENS J, SZEGEDY C. Explaining and harnessing adversarial examples [C]// Proceedings of International Conference on Learning Representations 2015 (ICLR 2015). San Diego, California, USA: Yoshua Bengio, Yann LeCun, 2015:"1-11.
[10] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks [C]// Proceedings of the 6th International Conference on Learning Representations (ICLR 2018). Vancouver, British Columbia, Canada; Yoshua Bengio, Yann LeCun, 2018: 1-28.
[11] LAKE B M, SALAKHUTDINOV R, GROSS J, et al. One shot learning of simple visual concepts [C]// Proceedings of the 33rd Annual Conference of the Cognitive Science Society. Boston, Massachusetts, USA: Cognitive Science Society, 2011: 2568-2573.
