基于中医疫病古籍文本自动分词的药物规律挖掘研究
2025-02-16刘嘉宇李贺于琳时倩如侯力铁





摘 要: [目的/ 意义] 数字人文背景下的中医疫病古籍文本自动分词和基于分词结果的药物规律挖掘, 是促进古籍知识活化与支持临床诊疗的重要途径。[方法/ 过程] 本文提出了一种基于中医疫病古籍文本自动分词的药物规律挖掘框架, 该框架包含了数据获取层、序列标注层、自动分词层和应用服务层, 通过4 层协作联动最终实现了疫病古籍文本的自动分词和药物规律挖掘应用。[结果/ 结论] 实证结果表明, 框架包含的基于BiLSTMCRF的中医疫病古籍文本自动分词效果综合性能达92%。在分词结果基础上统计方剂中各类剂型、常用中药和常用药对等药物规律挖掘结果, 为未来疫情防控指导、诊疗决策辅助提供了支持。
关键词: 数字人文; 文本分词; BiLSTM-CRF; 中医疫病; 知识挖掘
DOI:10.3969 / j.issn.1008-0821.2025.02.002
〔中图分类号〕G254 〔文献标识码〕A 〔文章编号〕1008-0821 (2025) 02-0017-09
疫病是人类社会长期以来面临的重大威胁之一。作为传统医学的重要组成部分, 中医积累了丰富的疫病防治经验, 其遗留的古籍记载了大量有关疫病的描述和治疗方法, 对于研究疫病的起源、传播规律以及药物治疗等具有重要价值[1] 。数字人文背景下, 利用现代科技手段实现传统医学知识的数字化表达与活化再现, 可提高对中医疫病古籍内容的理解和分析能力, 发掘其中隐含的药物规律, 明晰中医药在疫病防治中的特点和优势, 为现代疫病防治提供参考借鉴。作为自然语言处理的基础任务之一,文本分词是挖掘中医疫病古籍中蕴含的疫病治疗经验的前提[2] 。
但现有针对中医疫病古籍文本自动分词及药物规律挖掘的研究存在以下问题: 第一, 缺乏专门结合人工标注而构建的大规模中医疫病古籍文本语料库。第二, 可用于中医疫病古籍文本自动分词的机器学习或深度学习模型的分词训练精度有待提升。第三, 现有的中医疫病古籍文本自动分词结果对基于古籍文本的药物规律挖掘应用支持有限[3] 。上述问题阻碍了中医疫病古籍的创造性转化和创新性发展。为解决这些问题, 需要建立大规模的中医疫病古籍文本语料库, 并结合人工标注进行深度学习模型训练, 提高分词和挖掘的精准度。同时, 也需要加强对中医疫病古籍文本的语义理解和知识推理能力, 以提高中医疫病古籍文本的药物规律挖掘效果。
综上, 本文提出了基于中医疫病古籍文本自动分词的药物规律挖掘研究, 旨在借鉴古籍领域的分词规范标准, 通过对中医疫病古籍文本的序列标注,构建适用于中医疫病领域的古籍文本分词和药物规律挖掘语料库, 并利用基于深度学习中的BiLSTMCRF实现疫病古籍文本的自动分词和分词基础上的药物规律挖掘, 发挥古籍助力中医迈向数字化循证的作用, 辅助中医疫病学家和从业者通过抽取、发现和分析以词为单位的疫病知识, 为当代及未来疫情防控提供决策支持。
1 相关工作
本文核心工作为中医疫病古籍文本自动分词和基于分词结果的疫病药物规律挖掘, 是数字人文视角下的古籍文本自动分词技术在中医疫病领域的具体实践。此外, 现有的中医古籍文本分词主要用于构建能够高效准确地抽取中医文献潜在临床经验和用药规律的计算机算法模型。因此, 本文文献综述主要围绕古籍文本的自动分词及基于中医文献的药物规律挖掘研究展开。
1.1 古籍文本自动分词相关研究
古籍文本自动分词是将古文献中有实义的文字片段进行切分, 将连续文字序列分割成有意义词语的过程[4] 。既往对古籍文本自动分词的方法技术包含基于规则、基于统计、基于字典和基于深度学习的方法。例如, 张素华等[5] 提出一种根据字符连通度实现中医古籍无监督分词的规则式自动分词技术。Fu X J 等[6] 基于HMM 的统计式词性标注方法, 构建了中医专用词性标注方法, 并以Ansj 为核心的分词算法开发了一个中文古籍分词系统。李筱瑜[7] 在基于《汉书》识别未登录词基础上, 结合古代汉语词汇表、古代人名词表和古代地名表构建了古籍文本分词词典, 对《汉书》实现了分词处理。在基于深度学习的古籍文本自动分词方面, 钟昕妤等[8] 面对针灸古籍中的大量通假字、歧义词和专业术语等限制分词性能问题, 提出了基于CmabBERT-BiLSTMCRF的针灸古籍分词技术并取得了良好的性能成果。
1. 2 基于中医文献的药物规律挖掘相关研究
基于中医文献的药物规律挖掘是通过对中医文献中药物的相关信息进行分析和整理, 寻找药物规律和特点的环节。用药规律分析、药方挖掘与整理、组方配伍规律分析等是目前基于中医文献的药物规律挖掘的几个聚焦方向。例如, 姜威等[9] 通过收集中医药知识服务平台中治疗便秘的中成药, 在频次统计的基础上挖掘了中成药治疗便秘的用药规律。马洪微[10] 借助文献检索、逐本阅读梳理的方法, 从方剂剂型、药物性味归经、配伍等方面研究了民国时期中医医籍痹证内服方药。李妮等[11] 运用中医传承辅助系统提供的中药药类分析、药物频次分析、关联规则分析和复杂系统聚类分析等功能, 分析了白志军教授治疗肾病蛋白尿的组方用药规律。总之,基于中医文献的药物规律挖掘通过研究中医文献中包含的中药性味、归经及中药间相互配伍关系, 为促进中医走向循证治疗发挥了积极作用。
中医疫病古籍文本既具有一般汉语古籍的表达结构及语言特点, 又拥有大量的医学专业术语。由于古籍文本的语言风格与现代汉语有所不同, 因此需要特殊的方法和工具进行分词, 结合人工标注和深度学习中BiLSTM-CRF 的古籍文本自动分词在既往研究中表现出了卓越的性能。此外, 融合中医疫病古籍文献和现代数据挖掘技术以研究古代医家治疗疫病时的方药应用规律, 可以帮助深入理解前人在防疫抗疫时的用药经验, 并为未来疫情防控提供有益的指导。综上, 本文提出了基于深度学习的中医疫病古籍文本自动分词模型, 并实现了基于分词结果的药物规律挖掘研究。
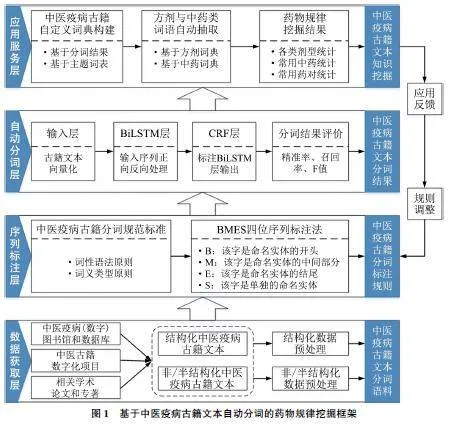
2 基于中医疫病古籍文本自动分词的药物规律挖掘框架
本文提出的基于中医疫病古籍文本自动分词的药物规律挖掘框架主要功能在于实现中医疫病古籍文本自动分词以及基于分词结果的药物规律挖掘(方剂中各类剂型、常用中药和常用药对统计)两大任务。二者之间存在紧密的依赖关系: 第一, 自动分词作为一项基础技术, 主要用于将连续的文本数据拆分成有独立意义的词汇, 该步骤是理解和分析古籍文本内容的前置条件, 也是后续进行深入药物规律挖掘的基础。第二, 通过自动分词技术可以有效地识别和提取方剂中的相关信息, 如各类剂型、使用的中药材名称等, 上述信息为后续的方剂中各类剂型、常用中药和常用药对统计提供了原始材料。研究人员可以对分词后的中药材名称进行频率统计,分析哪些药材在疫病治疗中被频繁使用, 或者哪些药对是常见的组合, 以及它们在不同剂型中的分布情况等。总之, 分词提供了准确的数据基础, 而深入分析这些数据则进一步揭示了中医药物使用的内在规律和治疗原则, 二者相辅相成, 共同推动着中医学的传承和发展。
基于中医疫病古籍文本自动分词的药物规律挖掘框架主要包括数据获取层、序列标注层、自动分词层和应用服务层。通过上述4 层协作, 可以将海量的中医疫病古籍文本数据转化为离散的词语或短语等结构化且机器可处理的数据形式, 以便后续实现以词或短语为单位的常用方剂中的各类剂型统计、常用中药统计和常用药对统计分析等, 进而在这些药物规律挖掘工作基础上实现中医疫病领域古籍文本的用药规律和临床经验抽取。具体内容如图1 所示。
2. 1 数据获取层
数据获取层目标是构建中医疫病古籍文本分词语料库, 以保证语料库拥有大量疫病领域的古籍文本数据, 为后续中医疫病古籍文本自动分词和药物规律研究提供可靠的底层数据支持。该层主要工作包含以下两个方面: ①数据采集: 通过各种渠道,如图书馆借阅、数字图书馆或古籍数据库线上阅览、中医古籍数字化项目咨询、中医领域学者专家撰写学术论文和专著等的释读, 收集包括经典著作、医案、方剂等大量中医疫病古籍相关文本数据。②数据清洗和预处理: 对收集到的疫病古籍文本数据使用正则表达式、文本处理库等工具进行清洗。针对以文档网页为主的非/ 半结构化中医疫病古籍文本数据, 主要通过噪声数据去除、格式转换、非中文字符删除等工作实现预处理[12] ; 针对结构化中医疫病古籍文本数据则是以数据解析、文件导入与读取以及结构化存储为主, 最终确保疫病古籍文本语料库的完整性和一致性。
2. 2 序列标注层
序列标注层的主要作用在于中医疫病古籍分词规范标准构建和中医疫病古籍文本序列标注实施,目标是形成一套统一且完整的中医疫病古籍文本分词规则和标注规则, 以指导疫病古籍文本的人工标注, 为基于深度学习的自动分词提供高质量的训练和测试语料数据。
2. 2. 1 中医疫病古籍分词规范标准构建
先前关于中医疫病文本的标注数据集较少, 无法实现本文的研究目标。因此, 基于付璐等[13] 提出的中医古籍分词规则并结合中医疫病领域古籍特色,本文构建了中医疫病领域古籍分词规则。该规则同样包含了词性语法规则和语义类型原则两个部分。其中, 词性语法规则主要是根据古代汉语的词性特点进行分词细则的拟定, 以提高中医疫病古籍文本分词准确性和语法正确性。在该原则指导下, 需要综合考虑文本中涉及的名词、动词、形容词、副词、数词和虚词等均在何种情况下需要切分, 何种情境下不需要切分。中医疫病领域有着独特的专业术语和语言表达方式, 因此, 语义类型原则主要是在分词时对这些特点进行考虑。本文考虑了与疫病相关的生理、症状、证候、病理因素、病理产物、功效、治法、经络腧穴、四诊、中药、方剂、性味、毒性、炮制、禁忌、煎服法和涉及的专有词等相关术语内容。
2. 2. 2 基于BMES 的中医疫病古籍文本序列标注
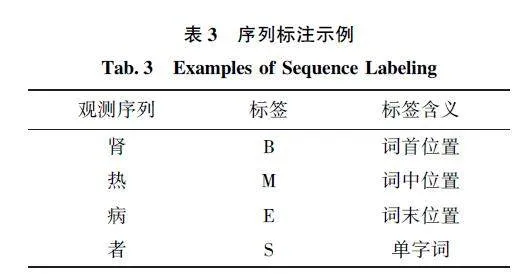
数据标注是实现基于深度学习自动文本分词的基础工作。BMES 是一种用于中文命名实体识别的序列标注方法, 该方法将每个字标注为4 个标签,即B、M、E 和S[14] 。本文在基于深度学习的中医疫病古籍文本自动分词训练语料标注过程中, 采用BMES 四位序列标注法。具体操作过程如下: 首先,将每个语句划分为不同的片段, 然后根据词语的位置和关系使用BMES 标记法对每个片段进行标注,最后将人工标注的语料结果提供给领域专家检查,以确保人工标注语料的有效性和准确性。
2. 3 自动分词层
自动分词层主要采用深度学习模型BiLSTMCRF实现中医疫病古籍文本自动分词。作为一种适用于中文文本分词的模型, BiLSTM-CRF 由输入层、BiLSTM 层和CRF 层组成。基于该模型的中医疫病古籍文本自动分词的原理流程如下:
2. 3. 1 输入层
鉴于神经网络只能处理数值型数据, 而中医疫病古籍文本是以文字形式存在的。因此, 输入层的作用是将文本数据转化为神经网络可以处理的数值表示, 以便后续的神经网络模型进行处理。此外,输入层通过将每个字或词转化为向量表示后, 还可以捕捉到字或词表达的语义信息。因此, 在后续的BiLSTM 和CRF 层就可以利用这些语义信息更好地进行分词任务。
2. 3. 2 BiLSTM 层
BiLSTM 层是双向长短期记忆网络(Bidirection⁃al Long Short-Term Memory)的缩写, 它的作用是对输入的疫病古籍文本进行序列建模, 从而捕捉上下文信息。相较LSTM, BiLSTM 摆脱了只能依据先前时刻的时序信息来预测下一时刻输出的限制, 能更好地结合上下文进行输出。具体而言, BiLSTM 层通过堆叠前向和后向两个LSTM 网络, 分别对输入疫病文本序列进行正向和反向处理, 然后将两个方向的隐藏状态进行拼接得到更全面的上下文表示, 可以更好地捕捉疫病古籍文本序列中的长程依赖关系[15] 。
2. 3. 3 CRF 层
CRF 层代表了条件随机场(Conditional RandomField), 其作用是对分词结果进行建模, 通过考虑标签之间的相互依赖关系, 来完成分词的预测[16] 。该层可以对BiLSTM 层的输出进行标注, 将标注结果作为模型的输出。在训练过程中, CRF 层会根据训练数据的标签序列来学习标注过程中定义的约束条件(如BMES 的标签序列), 通过最大化训练数据的对数似然函数来优化转移矩阵。因此, CRF 层可以通过学习这些约束条件来提高模型的性能, 并且在预测时可以保证输出的标签序列满足这些约束条件。
2. 4 应用服务层
应用服务层建立在疫病古籍文本自动分词基础上, 旨在实现疫病古籍文本的词汇级应用, 聚焦药物规律挖掘的决策辅助和知识抽取方向。借鉴目前几款受欢迎的中医知识挖掘数据平台的应用功能,在了解现有诊疗实践中业务需求的基础上, 本文的药物规律挖掘主要包含疫病古籍文本中记载相关方剂中的各类剂型、常用中药和常用药对的统计分析等内容。通过统计分析古籍中的方剂剂型、常用中药和常用药对的使用情况, 可以了解古代医家在治疗疫病时的用药经验和偏好, 这些经验可以为现代临床实践提供参考, 指导医生在治疗疫病时选择合适的剂型和药物组合。此外, 通过统计分析方剂中常用中药和常用药对的使用频率与组合情况, 可以揭示中医药的药物组合的规律和特点。依据这些规律, 有助于深入理解中药的药理作用和相互作用机制, 为中药复方的合理设计和优化提供依据。同时, 这些应用还有助于整理、归纳和总结中医药经典著作中关于疫病治疗的药物组合和用法, 促进中医药知识的传承和发展。
3 实证研究
为验证上文提出的基于中医疫病古籍文本自动分词的药物规律挖掘框架的合理性和实用性, 本文通过收集疫病古籍文本语料数据, 在中医疫病古籍分词规范标准构建和文本序列标注的基础上, 计算了基于BiLSTM-CRF 的中医疫病古籍文本自动分词结果, 并实现了中医疫病古籍文本自动分词基础上的药物规律挖掘。
3. 1 数据来源及预处理
清代吴瑭所著的疫病古籍《温病条辨》在医学界影响广泛, 是中医疫病学的重要著作。该书系统地总结了中医疫病学中温病的理论和实践经验, 对于后世医学家的学习和研究具有重要的参考价值[17] 。同时, 吴瑭在《温病条辨》中也提出了一些独特的观点和治疗方法, 对疫病学发展和临床实践起到了积极推动作用。综上, 本文以《温病条辨》作为分词实验原始数据。在数据预处理环节, 将原文转换为以句子为单位的语料格式后, 形成了中医疫病古籍文本自动分词小型语料库, 语料库的规模和相关信息如表1 所示。
3. 2 中医疫病古籍分词规范标准构建和文本序列标注
3."2. 1 中医疫病古籍分词规范标准构建结果
经过两位领域专家对分词规范标准修改调整,例如“脾胃” 在某些语境下是一个整体词, 在某些语境下则需切分成人体的两个不同部位, 在分词规范标准中需要考虑具体情境等, 本文最终构建了中医疫病古籍分词规范标准。
表2 以“症状类” 语词为例, 解释中医疫病古籍分词规范标准中的分词规则。如表2 所示, 当一个名词短语完整地描述一个人体疾病的症状时, 此短语可不作切分。例如, “耳聋” “腰痛” “身热”“咳喘” 等病症可作为一个整体来处理。同样, 对于“名词+名词+形容词” (如“心腹痛”“邪热结”)和“名词+形容词+形容词” (如“心烦懊” “腹满泄”)结构也可以不做切分, 以保持症状描述的完整性。不同的是, 对于含有复合症状的“名词+形容词+名词+形容词” 结构应进行分词, 以表明各个症状的独立性。例如, “神迷肢厥” 可以切分为“神迷/ 肢厥”, “头痛面赤” 可以切分为“头痛/ 面赤”, 这样的分词方式有助于更清楚地表示各个症状的独特性, 并有助于诊断的精确性。
基于上述规则, 本文对语料库进行分词标注,分词标注结果由领域专家检查后, 修改了部分未结合语义或术语识别不清的切分错误。例如, 将“风温/ 咳嗽” 修改为“风温咳嗽”。最终得到包含64 666个语词的标注数据, 总字数95 125字, 最大词长为6。标注样例如下:
神昏/ 谵语/ 者/ ,/ 清宫汤/ 主/ 之/ ,/ 牛黄丸/ 、/紫雪丹/ 、/ 局方至宝丹/ 亦/ 主/ 之/ 。/
温病/ 忌汗/ 者/ ,/ 病/ 由/ 口鼻/ 而/ 入/ ,/ 邪/ 不在/ 足太阳/ 之/ 表/ ,/ 故/ 不得/ 伤/ 太阳经/ 也/ 。/
3. 2. 2 基于BMES 的文本序列标注结果
为训练模型实现自动化分词, 本文采用BMES序列标注方法对语料实现了序列标注。作为一种四位序列标注法, 采用BMES 序列标注获得的标签示例如表3 所示。鉴于本文基于BMES 文本序列标注由两位标注者人工进行, 本文借鉴Kappa 系数这一统计指标, 以衡量标注者之间在序列标注任务中的一致性水平。当Kappa 值大于或等于0."80 时, 则通常被认为是几乎完全一致, 标注结果质量被认为非常好。经计算, 本文标注人员基于BMES 的文本序列标注结果的Kappa 值为0. 83, 说明不同标注者之间一致性较强, 标注结果质量良好。
3. 3 基于BiLSTM-CRF 的中医疫病古籍文本自动
3. 3. 1 实验过程
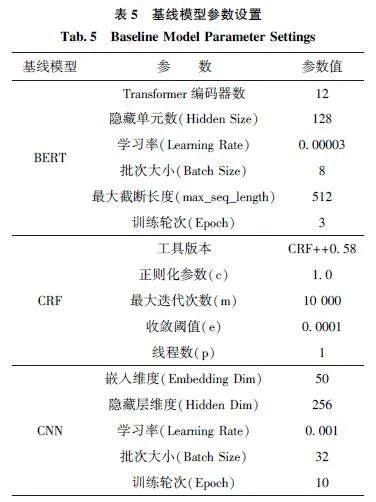
将经过序列标注的语料数据作为深度学习模型的输入, 并基于评价指标判断基于BiLSTM-CRF模型的中医疫病领域古籍文本自动分词效果。深度学习模型在Pytorch 1 6 0 环境下运行。此外, 实验中将中医疫病古籍文本数据集按7 ∶3 的比例设为训练集和测试集, 表4 报告了实验过程中深度学习模型BiLSTM-CRF 的最优参数。
3. 3. 2 实验测评
为验证基于BiLSTM-CRF 的中医疫病古籍文本自动分词的有效性, 本文在选择评价指标与基线模型对比的基础上, 测评了深度学习模型应用于疫病古籍文本自动分词任务的效果。
1) 评价指标
采用精确率(Precision, P)、召回率(Recall,R)、调和平均值(F-measure, F)作为基于深度学习模型的中医古籍疫病文本自动分词效果的评价指标。其中, P 和R 分别体现了分词模型的准确性和全面性, F 则是调和了前两个评价指标的综合性指标。
2) 基线模型
本文设定CRF、CNN 和BERT 为基线模型, 以判别本文提出的中医疫病古籍文本分词效果。其中,BERT(Bidirectional Encoder Representations from Trans⁃formers)是Google 于2018 年发布的一种预训练的自然语言处理模型, 其优点在于它能够学习到上下文相关的词向量表示, 即同一个词在不同上下文中可能有不同的语义[18] 。这种上下文敏感的表示在文本分类、命名实体识别、语义角色标注等自然语言处理任务中均表现出卓越性能。例如, 刘畅等[19] 利用SikuBERT 和BERT 等预训练模型, 对记载春秋至魏晋历史最具有代表性的6 部官修史籍实现了文本分词, 结果表明, BERT 在基于原始的语料中分词性能最佳。此外, BiLSTM-CRF 结合了LSTM 对长距离依赖关系的建模能力与CRF 对序列标注的精确建模能力, 而CNN 能够从序列数据中捕捉到局部重要信息, 如古籍中特有的词汇结构和短语模式, 在处理非连续文本特征上具有显著优势。因此,本文将CRF、CNN 和BERT 等模型视为基线以判断本文使用模型的优越性。实验环节, 各基线模型实验参数设置如表5 所示。
3. 3. 3 分词结果与评价
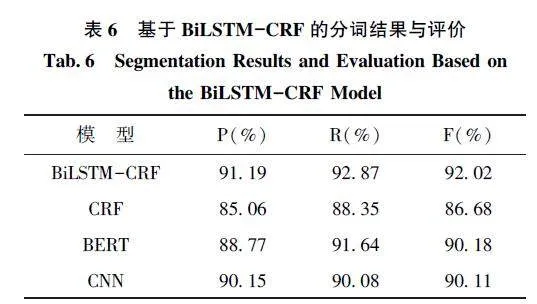
基于BiLSTM-CRF 模型的中医疫病古籍文本分词结果如表6 所示。由表6 可知, BiLSTM-CRF模型在P、R 和F 上的指标均大于基线, 其分词效果优于BERT、CRF 和CNN 模型。这表明基于深度学习模型中的BiLSTM-CRF 可以基本实现中医疫病古籍文本的自动分词, 这对辅助中医疫病学家等从业者实现疫病领域古籍文本的自然语言处理提供了良好的方法工具。
3. 4 基于中医疫病古籍文本自动分词的药物规律挖掘
中医领域的药物规律挖掘主要从聚类分析、词频统计、关联规则分析和组方配伍规律分析几个方面实现[20] 。现有的古今医案云平台、中医传承辅助平台等是中医药领域常用的数据挖掘工具, 上述功能均包含在内[21] 。因此, 本文基于中医疫病古籍文本自动分词的药物规律挖掘主要统计了语料库所含方剂中的各类剂型、部分常用中药和部分常用药对。其中, 中医疫病古籍自定义词典构建和基于自定义词典的方剂与中药类词语自动抽取是实现中医疫病古籍文本药物规律挖掘的前提。
3. 4. 1 中医疫病古籍自定义词典构建
上述自动分词实验表明, BiLSTM-CRF 模型在处理中医疫病古籍时效果更优。在此基础上, 本文利用该模型相继完成了《温热经纬》《温疫论》两本中医经典疫病古籍文本的自动分词, 并将分词结果与《温病条辨》融合形成了新的中医疫病古籍文本语料库。人工删除语料库中的停用词后, 参考《中国中医药学主题词表》《中医大辞典》和《中药大辞典》等, 本文选择方剂、中药两个大类构建了中医疫病古籍领域的“方剂类” 和“中药类” 自定义词典, 为后文基于自定义词典抽取与方剂和中药类下的名词术语实现药物规律挖掘提供参考。本文构建的中医疫病古籍中“方剂类” 和“中药类” 自定义词典如图2、图3 所示。其中, “方剂类” 词典提供了512 种成熟的中医治疗配方的相关词汇, 而“中药类” 词典提供了1 678味中药材名称。
3. 4. 2 基于自定义词典的方剂与中药类词语自动抽取
中医疫病古籍文本中描述了大量方剂配制方法和中药使用情况, 对其自动抽取可以分析药物的用药规律和组方配伍规律。基于上文构建的自定义词典, 本文通过词典匹配的方式实现了基于自定义词典的方剂与中药类词语自动抽取。抽取的过程如下:首先, 将疫病文本语料库在自动分词后转换为列表格式; 其次, 采用词典匹配的方式将列表中的词语与自定义词典匹配, 并筛选出匹配到的结果; 第三,将抽取出的中药和方剂相关词汇转存为新的列表,并将每个词语定义为一条完整的方剂内容, 该内容包含方剂名称与所含的中药名称; 最后, 共抽取出128 个方剂词汇(不包含未描写具体内容的方剂)和337 个中药词汇, 并以此作为后文的药物规律挖掘基础。
3. 4. 3 药物规律挖掘结果
为体现本文研究对中医药诊疗和研究的辅助决策支持, 本文分别统计了方剂中各类剂型、方剂中部分常用中药、方剂中部分常用药对, 具体的药物规律挖掘结果如下:
1) 方剂中各类剂型统计
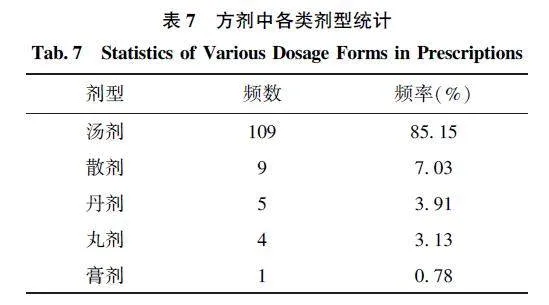
如表7 所示, 在《温病条辨》《温热经纬》和《温疫论》三本经典的中医疫病古籍构建的疫病古籍文本语料库包含的128 个方剂中, 占比最多的是汤剂, 其次是散剂和丹剂。统计结果显示, 古代医家在治疗疫病时更常使用汤剂这种剂型。汤剂是指将药物煎煮后的药液, 常用于治疗内科疾病; 散剂是将药物研磨成粉末后使用, 常用于治疗外科疾病,具有消肿、止痛、止血等作用; 丹剂是将药物研磨成细粉后加入其他药物制成丸剂, 常用于治疗虚劳、气血不足等疾病, 具有补益、固涩、安神等作用[22] 。这些方剂类型的占比情况可以为研究中医疫病治疗提供一些参考, 同时也反映了古代医家在治疗疫病时的用药特点和经验。
2) 方剂中部分常用中药统计
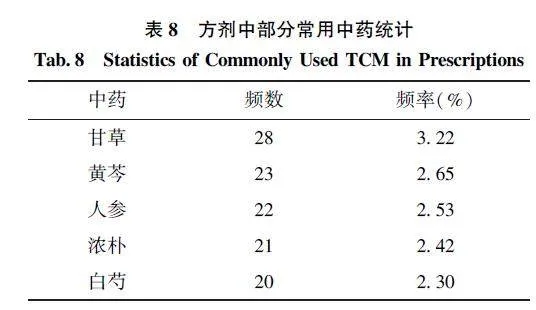
如表8 所示, 疫病古籍文本语料库中的337 味中药在128 个方剂中出现的总频数为869 次, 使用频次最多的是甘草, 其次是黄芩、人参等中药, 说明这些中药在古代医家治疗疫病时被广泛应用, 并且具有一定的疗效。
3) 方剂中部分常用药对统计
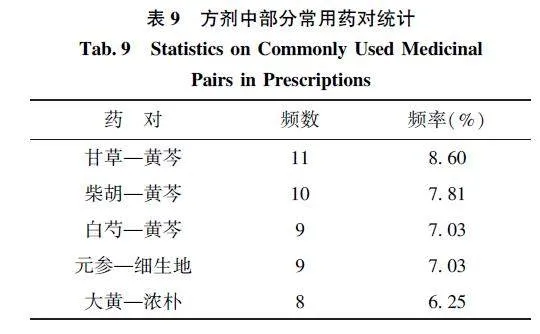
统计方剂中常用药对组方配伍规律挖掘、药物相互作用和方剂优化具有一定的指导意义。如表9所示, 甘草—黄芩是疫病方剂中常搭配出现的药对,其次是柴胡—黄芩和白芍—黄芩。这些药对的搭配常用于疫病方剂中, 能够协同作用, 增强疗效, 对于治疗疫病具有一定的作用, 这为日后治疗疫病用药选方提供了参考。
4 结 论
在疫病文本语料库构建的基础上, 构建文本序列标注和分词规范标准, 实现中医疫病古籍文本的自动分词和分词基础上的药物规律挖掘研究, 对促进中医疫病古籍活化、挖掘中医药治病经验和用药规律、提升中医药临床应用水平和促进中医药高质量发展具有积极的意义。鉴于此, 本文提出并构建了一个包含数据获取层、序列标注层、自动分词层和应用服务层的基于中医疫病古籍文本自动分词的药物规律挖掘框架, 实现了疫病领域古籍文本的自动分词和分词基础上的药物规律挖掘。具体来说,本文主要贡献如下:
1) 构建了适用于中医疫病领域的古籍文本自动分词小型语料库。在获取经过句读和电子化的《温病条辨》《温热经纬》和《温疫论》基础上, 构建了中医疫病领域的古籍文本分词和药物规律挖掘语料库, 该语料库进一步丰富了数字人文领域的语料库资源, 为促进多领域、大规模的古籍智能化工作提供了底层数据资源。
2) 提出了基于深度学习的中医疫病古籍文本自动分词模型。基于深度学习的分词技术是目前准确率最高的分词方法, 为满足中医疫病领域文本实现词汇级分析需求, 本文提出了基于BiLSTM-CRF的中医疫病古籍文本自动分词研究。与基线相比,该自动分词模型在各项评价指标上都表现出了卓越性能, 表明结合了双向长短期记忆网络和条件随机场的序列标注模型, 在提取疫病古籍文本中的上下文信息发挥出显著的优势, 适用于中医疫病古籍文本的自动分词任务。
3) 实现了基于中医疫病古籍文本自动分词的药物规律挖掘研究。基于语料库分词结果, 本文通过方剂中的各类剂型统计、部分常用中药统计和部分常用药对统计, 实现了初步的中医疫病领域古籍文本词汇级药物规律挖掘应用, 这为日后疫情防控、诊疗决策辅助和人文计算工具的智慧化开发应用提供了一定的参考价值。
参考文献
[1] 白明, 李杨波, 苗明三. 基于古籍数据挖掘的中医防治疫病用药规律分析[J]. 中药药理与临床, 2020, 36 (1): 32-36.
[2] 胡昊天, 邓三鸿, 张逸勤, 等. 数字人文视角下的非物质文化遗产文本自动分词及应用研究[J]. 图书馆杂志, 2022, 41 (8):76-83.
[3] 李盼飞, 张楚楚, 李海燕. 科技赋能中医古籍精华传承与创新
[4] 欧阳剑. 面向数字人文研究的大规模古籍文本可视化分析与挖
[5] 张素华, 叶青, 程春雷, 等. 面向中医古籍文本的领域自适应性无监督分词[J]. 软件导刊, 2022, 21 (1): 96-100.
[6] Fu X J, Yuan T, Li X B, et al. Research on the Method and Sys⁃tem of Word Segmentation and POS Tagging for Ancient ChineseMedicine Literature [C] / / IEEE International Conference on Bioin⁃formatics and Biomedicine(BIBM), San Diego, CA, USA. IEEE,2019: 2493-2498.
[7] 李筱瑜. 基于新词发现与词典信息的古籍文本分词研究[ J].软件导刊, 2019, 18 (4): 60-63.
[8] 钟昕妤, 李燕, 徐丽娜, 等. 基于CmabBERT-BILSTM-CRF 的针灸古籍分词技术研究[J]. 计算机时代, 2023, (4): 11-15.
[9] 姜威, 李敬华, 于琦, 等. 基于数据挖掘的中成药治疗便秘用药规律研究[J]. 中国中医药图书情报杂志, 2023, 47 (5): 91-94.
[10] 马洪微. 民国时期中医医籍痹证内服方药文献挖掘与整理研究[D]. 合肥: 安徽中医药大学, 2023.
[11] 李妮, 张倩, 李芳, 等. 基于中医传承辅助系统肾病蛋白尿防治组方配伍规律的数据挖掘研究[J]. 药学研究, 2023, 42(8): 620-626.
[12] 李豪, 周爽. 基于三维知识超图的电力智库知识服务平台建设[J]. 智库理论与实践, 2022, 7 (3): 84-92, 99.
[13] 付璐, 李思, 李明正, 等. 以清代医籍为例探讨中医古籍分词规范标准[J]. 中华中医药杂志, 2018, 33 (10): 4700-4705.
[14] Meng W C, Liu L C, Chen A Y. A Comparative Study on Chi⁃nese Word Segmentation Using Statistical Models [ C] / /2010IEEE International Conference on Software Engineering and ServiceSciences, Beijing, China. IEEE, 2010: 482-486.
[ 15] Ma J, Ganchev K, Weiss D. State-of-the-Art Chinese Word Seg⁃mentation with BI-LSTMs [C] / / Proceedings of the 2018 Confer⁃ence on Empirical Methods in Natural Language Processing, Brussels,Belgium. New York, USA: Association for Computational Linguistics,2018: 4902-4908.
[16] Huang Z H, Xu W, Yu K. Bidirectional LSTM-CRF Models forSequence Tagging [J]. arXiv: 1508.01991, 2015.
[17] 钱琳琳, 张美伦, 马晓北. 《温病条辨》中温热类病证用药规律探究[J]. 陕西中医, 2022, 43 (3): 380-383.
[18] Cui Y M, Che W X, Liu T, et al. Pre-Training with WholeWord Masking for Chinese BERT [J]. IEEE/ ACM Transactions onAudio, Speech, and Language Processing, 2021, 29: 3504-3514.
[19] 刘畅, 王东波, 胡昊天, 等. 面向数字人文的融合外部特征的典籍自动分词研究———以SikuBERT 预训练模型为例[ J]. 图书馆论坛, 2022, 42 (6): 44-54.
[20] 孙晓花. 基于聚类分析探讨中医药干预肿瘤疾病的用药规律[J]. 中医药管理杂志, 2023, 31 (5): 119-121.
[21] 郑婉婷, 李敬华, 田少磊, 等. 基于数据挖掘的李军祥治疗溃疡性结肠炎用药规律分析[J]. 中国中医药信息杂志, 2022, 29(9): 59-64.
[22] 刘洋. 探讨逍遥散汤剂和散剂治疗肝郁脾虚证的临床效果[J].中国现代药物应用, 2022, 16 (19): 168-170.
(责任编辑: 郭沫含)
基金项目: 国家社会科学基金冷门绝学专项研究项目“本草典籍整理、知识组织与智慧化建设研究” (项目编号: 23VJXT024)。