分布式光伏前端数据采集技术研究
2024-12-21夏长生管佩祥

摘 要:本文针对分布式光伏的前端数据采集问题,提出了一种基于卷积神经网络的深度学习估计方法,将辐射照度、输出功率为基本特征向量,用于深度学习网络输入,进而对深度学习网络的结构、迭代过程、池化处理进行理论描述,并在试验过程中给出采集数据的估计流程,对估计结果和真实采集结果进行类比。关联系数的结果表明,本文提出的采集方法是有效的。
关键词:分布式;光伏;前端数据采集
中图分类号:TM 61" " 文献标志码:A
随着石化能源日益濒临枯竭,世界各国开始普遍重视太阳能利用。太阳能不仅是可再生资源,也是一种清洁型能源[1]。光伏发电技术是利用太阳能的有效手段,可以将太阳能转化为电能。近年来,我国一直致力于光伏发电的新能源开发,配置的光伏发电设备总容量已经超过2.0亿千瓦[2]。在各种光伏发电的技术构成中,分布式光伏具有十分重要的地位,在光伏发电总容量中的占比超过30%。如果能高效利用分布式光伏,太阳能将得到最大限度的利用。目前,困扰分布式光伏技术的一个突出难题就是太阳能采集的前端设备分散到不同位置,而不同位置的采集条件、工作场景和气象情况存在很大差异,导致数据采集情况复杂[3]。部分条件不成熟的位置无法配置采集设备,导致整体上采集数据不全。因此对分布式光伏进行前端数据采集研究是解决光伏发电的关键问题。
1 分布式光伏前端缺失数据的虚拟采集策略
分布式光伏和集中式光伏的发电模式不同。分布式光伏采用的是分布式发电模式,即将发电设备分散在分散的地区,形成覆盖较广的太阳能发电系统。分布式光伏的装机容量相对较小,一般为几十千瓦到几百千瓦不等。而集中式光伏的装机容量较大,一般为几百千瓦甚至上千兆瓦级别。分布式光伏建设相对简单,不需要太多的投资和土地资源,可以在农田、屋顶和工业园区等地区布建,以便更充分地利用资源。
分布式光伏的前端数据采集覆盖范围更大,因此涉及的地形条件、气象条件和采集环境存在较大差异。部分需要覆盖的地区因架设困难而无法安装前端设备。部分地区虽然架设了设备,但工作条件恶劣,无法采集到有效数据。因此,本文的主要工作就是对分布式光伏前端缺失的数据进行虚拟采集。其基本思路是利用可采集数据区域关键参数的相似性,对无法采集数据的区域进行预测,从而补足缺失区域。
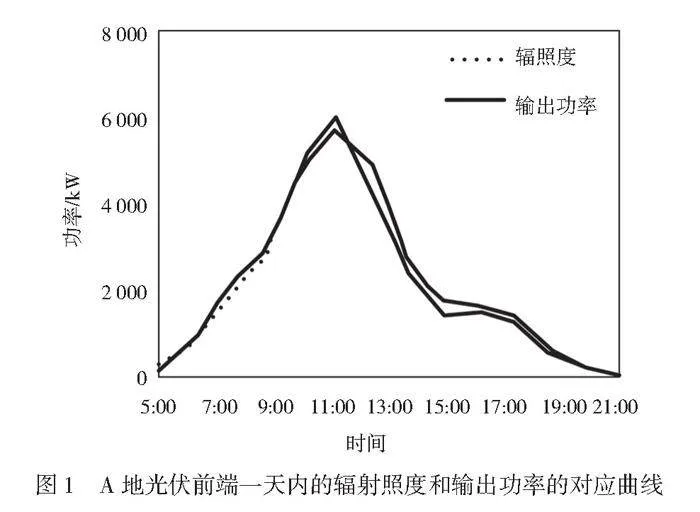
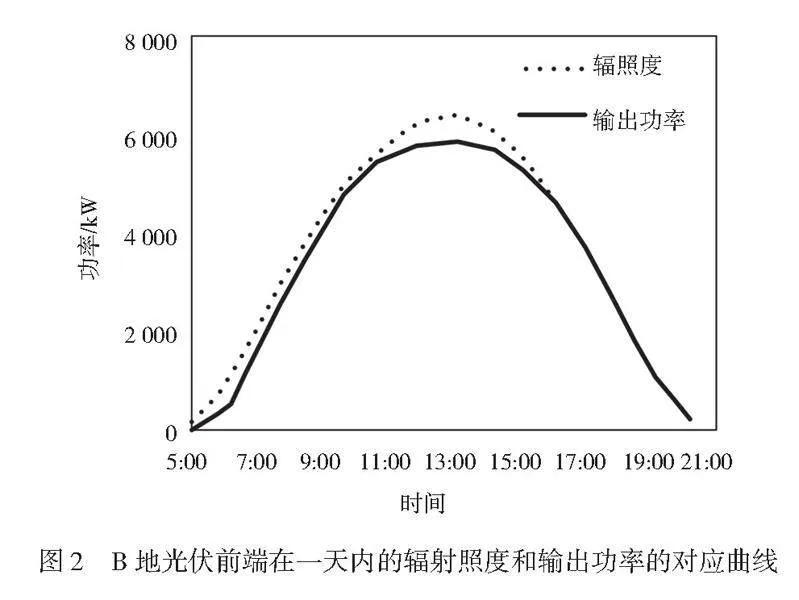
对分布式光伏的前端设备来说,太阳光照射到光伏板材上,采集装置就会吸收太阳能,并根据采集能量的大小完成功率输出。因此太阳光的辐射照度和光伏前端的输出功率具有对应性。如果能得到某一区域的输出功率,就可以估算出该区域对应的辐射照度。同样的原理,如果可以判断出某一区域的辐射照度,就可以估算出该区域的输出功率。如图1和图2所示。
根据图1和图2可知,A地和B地2个不同区域布置的分布式光伏前端采集装置的辐射照度曲线和输出功率曲线的变化基本一致,幅度的波动范围也具有较好的一致性。
假设A地和B地的光照强度接近,分布式光伏前端需要分别安置在A地和B地并进行数据采集,但是B地因为条件不允许无法安装,因此可以用A地的光伏前端数据对B地的光伏前端数据进行预测,从而形成B地光伏前端数据的虚拟采集。因为B地的光照强度和A地接近,所以可以通过A地的历史数据对B地进行估计。
2 基于卷积神经网络的前端数据预测方法
根据第1节给出的思路,进一步构建基于卷积神经网络的光伏前端数据的预测方法。经验表明,如果用一个可以实际采集数据的地区的历史信息去估计一个光照强度类似地区的光伏数据,需要在时间上尽可能处于同一跨度。最好的时间差异不超过15 d,这样进行的预测才是准确的。同时,历史数据和预测数据要建立某种联系,可以采用深度学习网络进行联系机制训练。本文采用的是卷积神经网络训练方法,其深度学习训练框架如图3所示。
根据图3可知,将实地采集的各种数据信息作为输入和输出对卷积神经网络进行训练,得到稳定的网络结构和准确的对应关系后,就可以利用该网络对缺失地区的光伏前端数据进行预测。
进而本文使用卷积神经网络识别与输入数据中的局部信息进行较低维度的相关语义表达。该卷积神经网络由滑动窗口和回归层组成,滑动窗口由几组3×3卷积核组成,用于提取输入数据信息的低语义表达。在每个滑动位置o都有一个c1维跨通道特征向量v,这些数据中的一个分量如公式(1)所示。
vsi=θ(W3×3i·w3(o)),i=1,2,...,c1 " "(1)
式中:v为特征向量;o为滑动位置;Wi 3×3为一个窗口,窗口可以用于滑动;w3为一个以o为中心的3×3区域。
然后将几个1×1卷积核作用于vs,如公式(2)所示。
vrj=BReLU(W1×1j·vs),j=1,2,...,c2" (2)
式中:vrj为vr的第j个元素,每个元素中包括c2个要传输的候选对象。
为了保证输出值为[0,1],本文将双边整流线性激活单元作为输出层的激活函数,其定义为x→min(max(x,0),1)。
与wr(p)相关的最终预估媒介透射率是对vr的池化结果,如公式(3)所示。
(3)
式中:(p)为池化结果;c2为要传输的候选对象的数量;v为特征向量。
均方误差用于计算预期结果与实际输出间差异的损失函数,如公式(4)所示。
(4)
式中:T为期望输出;为实际输出的池化结果;L为预期结果与实际输出间差异的损失函数。
在神经网络模型中的区块操作下,网络输出的池化结果存在区块伪信息。为了进一步细化池化结果,使用导向滤波算法平滑预测数据的池化结果。
导向滤波算法假设导向图和局部区域中的滤波输出线性相关。基于该关键假设,可以将池化结果的结构线性转换为精细池化结果,如公式(5)所示。
t(i)=a(p)Igray(i)+b(p),i∈wr(p) " "(5)
式中:a(p)为预测数据的线性系数;b(p)为预测数据的线性常数;I(i)为光伏前端的预测数据;t(i)为池化结果,如公式(6)所示。
t(i)=(i)-μ(i) " "(6)
式中:μ为一些冗余信息,例如噪声和干扰等。
公式(6)可以保证最终输出t的值近似于。在窗口wr(p)中,可以将如公式(7)所示的代价函数最小化来求解(a(p),b(p))。
(7)
式中:E为代价函数;t(i)为正则化系数,用来调整过大的a(p)。
公式(7)的解可以使用线性岭回归模型来解。
3 分布式光伏前端数据采集试验与结果分析
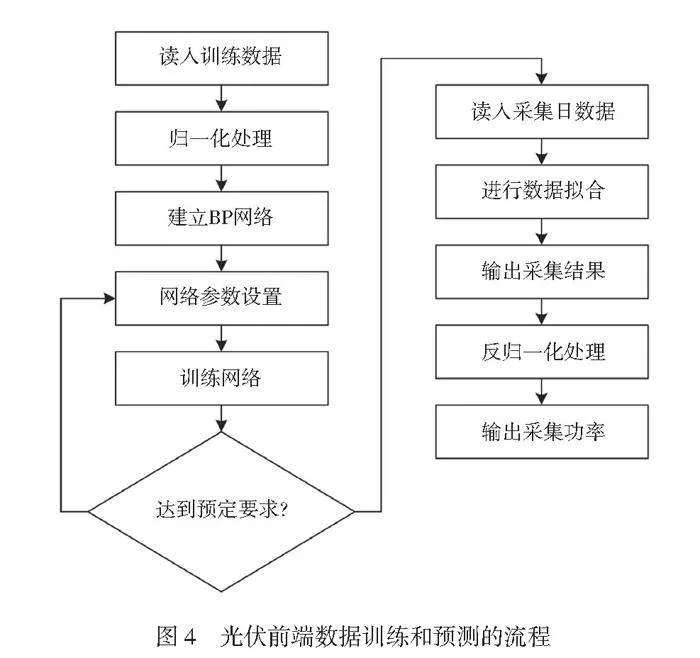
本文将试验地某区域内已安装数据采集装置的一个分布式光伏电站的辐照数据与功率数据作为样本数据。在原始的光伏功率与辐照历史数据中,每日数据有效采集的起始时间并不都是完全统一的,而且数据采集时间点较密集,因此模型的输入变量不一致且较复杂,增加了模型开销。为了实现数据的统一性,将数据采集的时间窗口定为05:00—19:00,数据采集时间间隔为1 h。试验中,光伏前端数据训练和预测流程如图4所示。
经过上述多个处理步骤并根据相似地区的历史数据来预测未知地区的光伏前端数据,从而完成缺失数据地区的虚拟采集。
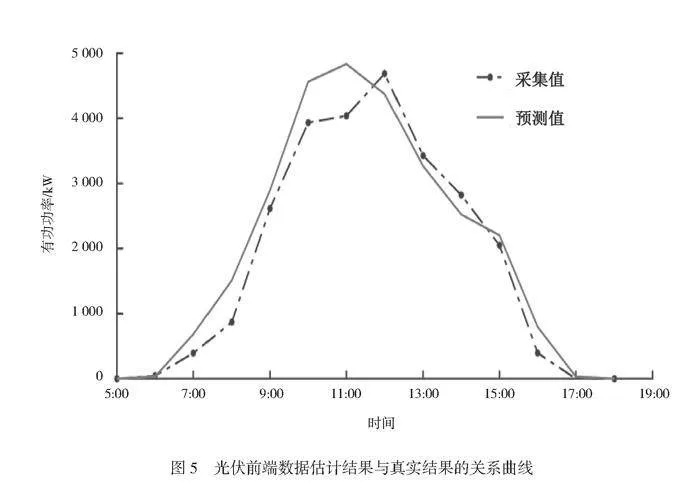
按照上述的方法和流程估计试验地的光伏前端输出功率数据。估计时段在一天的05:00—19:00。估计结果显示,在10:00—13:00光伏前端的输出功率达到峰值区域,该时间也正是试验地日照最强的时间。由于该时间段的辐射照度高、辐射能大,因此该光伏设备的输出功率也较大。为了验证估计结果,同时配置光伏前端设备并进行采集,二者的关系曲线如图5所示。
可以看出,2组曲线的拟合程度非常高,06:00—17:00严格吻合,输出功率的幅值、曲线的变化形态也基本一致,充分表明了预测方法的有效性。
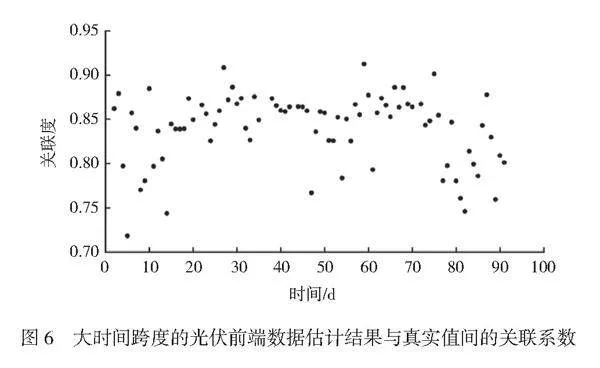
扩大光伏前端数据的虚拟采集时间范围,从单日预测增加到100 d,如图6所示。如果虚拟采集的估计结果与真实结果相符,那么2组数据的关联程度必须维持在较高水平。根据关联系数分析方法原则,如果大数据样本间的关联程度持续维持在0.7以上,则表明2组数据的关联性强。根据本文统计结果,光伏前端数据的估计结果和真实结果间的关联系数均分布在0.7以上,95%以上的关联系数分布在0.75以上,85%以上的关联系数分布在0.80以上,充分表明本文光伏前端数据采集方法的有效性。
4 结论
光伏发电是利用太阳能最有效的方法之一,也是目前正在广泛研究的实用技术。在众多光伏发电设备中,分布式光伏具有十分重要的地位。但是,分布式光伏分布节点多,受不同位置的采集条件、环境状况和气象因素的影响,数据采集困难。为了保证分布式光伏前端数据采集的完整性,本文提出了一种基于卷积神经网络的深度学习方法,用可采集地区的历史数据对类似地区的光伏前端数据进行估计。并通过多组试验进行验证,证实了该方法对分布式光伏前端数据采集的有效性。
参考文献
[1]许晓艳,黄越辉,刘纯,等.分布式光伏发电对配电网电压的影响及电压越限的解决方案[J].电网技术,2010(10):140-146.
[2]陈璨,樊小伟,张文浩,等.促进分布式光伏消纳的两阶段源网荷储互动优化运行策略[J].电网技术,2022,46(10):3786-3796.
[3]葛俊雄,蔡国伟,姜柳,等.基于天气变化自适应分型与匹配的分布式光伏短期功率预测方法[J].激光与光电子学进展,2024,61(15):101-109.
