基于货运车辆高速通行数据保险风险评估研究
2024-12-11吴学宁朱倩倩刘英男蔡建军


摘 要:货运车辆承载公路货物运输是货物供应链中的关键运输环节,与我国国民经济运行、产业链条衔接、居民生活水平提升等有紧密关联性。而货运车辆的高速通行数据是能够记载货运车辆主要行驶行为的信息记录。在车险定价方面,货运车辆高速通行数据可以帮助保险公司提升对货运车辆车险的定价精算化,有助于提升保险公司的营利性。本文主要研究方向聚焦于数据应用的微观方面,即货运车辆高速通行数据的在货运车辆保险场景的应用。
关键词:高速通行数据 货运车 车险
1 绪论
在保险行业,一直以来,市场出现营运货车投保难引起广泛关注。于此同时,随着车险市场迅速发展,车险产品配置逐渐达到饱和状态,且车险产品同质化现象较为严重,车险市场亟待创新破局。当前,从监管到企业,从外部到内部,行业变化趋势持续推动商业车险改革。
当前,对于保险企业而言,因货运车辆的原有问题导致保险公司对于商用车产品推广、车险定价和反欺诈等方面,存在薄弱环节,限制了保险企业对该类“边缘市场”的渗透力度和发展规模。为解决该问题,本报告尝试引入货运车辆高速通行数据结合其他已有数据尝试进行研究分析。
2 数据来源及处理
2.1 数据来源
2.1.1 车辆理赔数据
已经获取某保险公司近一年的理赔数据,其中包括理赔类型、理赔原因、地域分布等数据,其利用保险公司出险数据持续优化出险模型。
2.1.2 高速通行数据
高速通行数据来源于交通运输部采集的动态数据,具有全覆盖、实时性、真实性等特点[1]。覆盖全国范围高速通行车辆数据,借助地面道路固定通信设施实现车辆与道路间的信息交互数据,更新频率从T+1和实时两种频率,具有较高的开放程度。因开放程度较高可以弥补保险企业和行业内数据共享不充分等问题。货运车辆高速通行数据整体来看,以2021年为例,全国超过3292万辆货车产生了20.74亿条高速出入站通行记录(不含门架通行记录),月均超过2.1亿条通行记录,一型货车高速通行次数占比达到42%。全国高速路网共计超过3292万辆货车产生货物周转量为2.78万亿吨公里。可见数据量庞大,对于保险场景的货运车辆基本可以实现全覆盖。
具体货运车辆高速通行数据包含的内容包括入口通行数据,出口通行数据,门架通行数据。具体字段如下。
入口通行数据包括的字段:通行标识、通行介质和OBU编码即用于标识通行车辆的编码,入口标签时间和日期等时间字段,入口车辆型号、车牌、车型代码、车种代码和轴数等车辆信息,入口车辆的载重数等车辆营运信息,入口站名等入口站信息。
出口通行数据包括的字段:通行标识、通行介质和OBU编码即用于标识通行车辆的编码,出口标签时间和日期等时间字段,出口车辆型号、车牌、车型代码、车种qz61b+UBxIffdcd6zrQM1HBk/J1yH6RW66BmBaEWcoU=代码和轴数等车辆信息,出口车辆的载重数等车辆营运信息,出口站名等入口站信息。
门架通行数据包括的字段:通行标识、通行介质和OBU编码即用于标识通行车辆的编码,通过门架的时间和日期等时间字段,门架通过时的车辆型号、车辆编号、车牌、车型代码、车种代码和轴数等车辆信息,行驶速度、计费里程数等车辆营运信息,门架类型、门架编号等门架信息。
2.2 数据处理
数据处理主要包含两方面工作,缺失值处理与异常值处理。数据缺失是数据分析与建模经常遇到的问题,缺失值一般分为真缺失与假缺失,在处理缺失值的时候就要根据具体需求而定。具体采用如下几种方法进行处理:
均值/中位数补救法:对于数值型字段,可以使用样本均值或中位数补救;对于分类型字段,可以使用中位数补救。
频度最高值补救法:对于分类型字段,使用出现频度最高的类别补救;对于数值型字段,可以通过先分箱,然后使用出现频度最高的分箱的均值或者中位数进行补救。
统计方法补救法:针对数值型字段,可以使用诸如基于聚类的均值补救或者基于分类的插值补救等先进方法进行处理。
3 货运车辆高速通行风险模型研究
3.1 货车车辆高速通行风险特征因子
货运车辆高速通行数据包括仅依据货运车辆高速通行数据形成特征因子,依据货运车辆高速通行数据形成的驾驶习惯特征因子主要如表1所示。
3.2 模型建立(XGBoost模型)
XGBoost(eXtreme Gradient Boosting)极度梯度提升树,是一种基于梯度提升树的机器学习算法。XGBoost结合了梯度提升框架和决策树模型,通过迭代地训练一系列的决策树来逐步改进预测性能。它的目标是优化损失函数,使得预测值与实际值之间的误差最小化。XGBoost的参数主要分为三类:通用参数、Booster参数和学习目标参数。[2]
3.2.1 通用参数
这些参数用来控制XGBoost的宏观功能,在这里主要介绍通用参数中的重点参数。
1)booster[default=gbtree]
booster的基础树模型,包括三种 :gbtree, gblinear or dart,其中gbtree与dart的应用效果较为一致,dglinear应用效果稍差。
2)verbosity [default=1]
训练中是否打印信息,0 (silent), 1 (warning), 2 (info), 3 (debug)。
3.2.2 Booster参数
1)eta [default=0.3, alias: learning_rate]; range[0,1]
相当于神经网络中的学习率,与二叉树的分裂有关,可以增加XGBoost的稳定性。
2)gamma [default=0, alias: min_split_loss]
子叶节点分裂所需要的最小损失,gamma越大,算法越保守(鲁棒性)。
3)max_depth [default=6]
树的深度,深度越大,XGBoost的越复杂越容易过拟合。
4)subsample [default=1]
训练每一颗新的树时候的采样率,有点类似与神经网络中的批量训练,每次训练新的二叉树时使用数据在全数据集中的占比。
5)sampling_method [default= uniform]
采样采用的概率模型:uniform 正态分布 gradient_based。
6)lambda [default=1]
权重的L2正则化项。这个参数是用来控制XGBoost的正则化部分的。
7)alpha [default=1]
权重的L1正则化项。 能够应用在很高维度的状况下,使得算法的速度更快。
3.2.3 学习目标参数
这类参数用来控制理想的优化目标和每一步结果的度量方法。
1)objective[default=reg:linear]
这个参数定义需要要被最小化的损失函数。最经常使用的值有:binary:logistic二分类的逻辑回归,返回预测的几率; multi:softmax使用softmax的多分类器,返回预测的类别。
2)eval_metric[默认值取决于objective参数的取值]
对于有效数据的度量方法。 对于回归问题,默认值是rmse,对于分类问题,默认值是error。
seed(default=0)
随机数的种子设置它能够复现随机数据的结果,也能够用于调整参数。
3.3 模型验证
3.3.1 模型效果
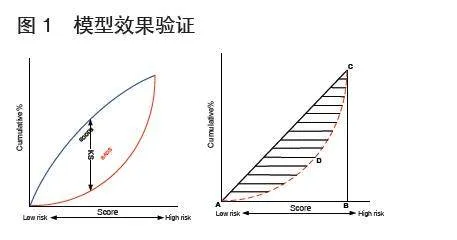
对模型表现的评估,基于Kolmogorov-Smirnov(K-S)和基尼(Gini)或ROC系数这两个统计值,Gini = 2*AUC - 1, AUC是ROC曲线下面积,经常用作衡量分类模型质量的指标。Kolmogorov-Smirnov(K-S)值和基尼系数(Gini)用来衡量模型区分好坏的能力,也就是模型的预测能力[3]。通过两者的计算来验证模型的预测能力,如下图1所示。
KS值由多种因素决定,如:
·数据源和数据信息的可获取度
·数据的质量
·产品类型
·群体的稳定性
3.3.2 模型验证
货运车风险识别除了结合货运车辆高速通行数据风险因子之外,还增加相关风险因子,例如车牌车架一致性;两客一危判定;超载超限黑名单;套牌车识别等数据,通过对风险因子赋权,形成车辆级的模型评分,评分区间为1-100分,其中1-10分为E类高风险车辆,11-30分为D类高风险车辆,31-60分为C类风险车辆,61-80分为B类优质车辆,81-100分为A类优质车辆。不同的评分对应不同的风险等级。最终输出营运车辆的风险等级,将车辆划分为A\B优质车辆,C类风险车辆,D\E类高风险车辆。应用于营运货车的风险识别中。
通过结合保险公司赔付数据分析。该模型评分对保前业务将有较高区分度。评分为E档业务赔付率高达136%,E档与A档赔付率相差3.3倍以上。如图2所示。
4 总结
本文对基于货运车辆高速通行数据保险风险评估进行研究。通过对行业已论证的车辆风险要素与货运车辆高速通行数据特征因子的关系进行实证分析,提出差异化车险产品,在最大化体现公平性的原则的前提下验证了本文研究结果的创新性,并为后续开展不同客户的车险定价提供了参考借鉴价值。本研究通过货运车辆高速通行数据获取与车辆风险定价相关的数据信息,并纳入到风险因素和定价模型分析范畴,以期实现保险定价模型的精确性。然而,本研究也存在一些局限性,如数据集的选择和算法的局限性,随着高速通行数据进一步的应用与拓展和货运车辆市场的不断扩大,我们预期将有更多的数据和技术可供利用。未来结合国内外相关研究成果创新性构建车险定价模型,并通过联动机制对车险费率进行调整,动态反映出不同车辆及其通行行为所呈现的潜在风险性,减少保险公司与客户之间的信息不对称情况的发生,从而提高保险行业的交易效率。
