一种带有注意力机制的大基线场景端到端单应性估计方法
2024-12-03林佐江曹旭陈玮白宇米博张学伟方浩












文章编号:1008-1542(2024)06-0669-14
摘" 要:
针对目前现有单应性估计方法存在的精度不高、对大基线场景与运动模糊场景适应性不强的问题,构建了一种带有注意力机制的大基线场景端到端单应性估计方法,采用无监督学习的方式进行单应性估计。首先,引入SE通道注意力模块,构建带有注意力机制的单应性回归网络层,获得网络对于图像各通道间关联性的学习;其次,构建基于掩膜与感知损失度量的二元无监督损失方式,提高网络感知域范围以及网络对于大基线场景的适应性;最后,构建Homo-COCO合成数据集,采用数据增强使得网络模型对于光照变化与运动模糊具有一定的鲁棒性,获得更强的真实场景泛化能力。经过充分的对比及消融实验表明,该方法在精度指标与场景适应性方面优于现有方法,具有良好的准确性与适应性。本方法可以有效估计图像单应性,为图像拼接、图像校正等计算机视觉后续任务提供准确参数估计。
关键词:
计算机图像处理;单应性估计;无监督学习;注意力机制;数据增强;深度学习
中图分类号:TP391
文献标识码:A
DOI:10.7535/hbkd.2024yx06012
收稿日期:2024-09-05;修回日期:2024-10-21;责任编辑:胡姝洋
基金项目:国家自然科学基金(62133002)
第一作者简介:
林佐江(1977—),男,天津人,正高级工程师,主要从事智慧建筑等方面的研究。
通信作者:
方浩,教授。E-mail:fangh@bit.edu.cn
林佐江,曹旭,陈玮,等.
一种带有注意力机制的大基线场景端到端单应性估计方法
[J].河北科技大学学报,2024,45(6):669-682.
LIN Zuojiang,CAO Xu,CHEN Wei,et al.
An end-to-end homography estimation method for large baseline scenes with an attention mechanism
[J].Journal of Hebei University of Science and Technology,2024,45(6):669-682.
An end-to-end homography estimation method for large
baseline scenes with an attention mechanism
LIN Zuojiang1, CAO Xu2, CHEN Wei1, BAI Yu3, MI Bo1, ZHANG Xuewei3, FANG Hao2
(1.China Construction First Group Construction amp; Development Corporation Limited, Beijing 100102,China;
2.School of Automation, Beijing Institute of Technology, Beijing 100081, China;
3.China Construction Municipal Engineering Corporation Limited, Beijing 102627, China)
Abstract:
Aiming at the problems of low accuracy and limited adaptability to large baseline scenes and motion blur scenarios in current homography estimation methods, an end-to-end homography estimation methodwith attention mechanism for large baseline scenes was constructed, which utilized unsupervised learning for homography estimation. Firstly, by introducing the SE channel attention module, a homography regression network layer with attention mechanism was constructed, enabling the network to learn the inter-channel correlations of images. Secondly, a binary unsupervised loss construction method based on mask and perceptual loss metrics was proposed to enhance the network′s perception range and adaptability to large baseline scenes. Finally, a Homo-COCO synthetic dataset was created, and data augmentation was used to improve the network model′s robustness to changes in lighting and motion blur, resulting in stronger generalization capabilities in real-world scenes. Extensive comparative and ablation experiments demonstrate that this method outperforms existing methods in terms of accuracy and scene adaptability, showing good precision and adaptability. It can effectively estimate image homography and provide accurate parameter estimation for subsequent computer vision tasks such as image stitching and image correction.
Keywords:
computer image processing; homography estimation; unsupervised learning; attention mechanism; data augmentation; deep learning
单应性变换是指从一个图像平面到另一个图像平面的可逆映射,其提供了2幅图像像素点之间的线性映射关系[1]。单应性是机器人与计算机视觉领域中的重要概念,广泛应用于图像拼接[2]、视觉定位与地图构建(simultaneous localization and mapping, SLAM)[3]、相机校准[4]以及增强现实[5]等领域。单应性变换所表征的2幅图像之间的映射通常用3×3的矩阵表示,该矩阵也常被称为单应性矩阵,由于尺度的不确定性,9参数的单应性矩阵具有8个自由度。
单应性估计通常指估计单应性变换所对应的单应性矩阵,以获取2幅图像之间的映射关系。传统的单应性估计方法包括基于像素的方法与基于特征的方法2种。基于像素的方法[6]通过假设猜测的从图a到图b的初始单应性矩阵对图a做单应性变换,对其与图b使用误差度量进行像素强度值(SSD)的比较,使用如梯度下降法的优化方法来最小化像素误差[7]。基于像素的方法在图像重叠率较低或视差较大时存在失效的风险,且由于涉及在线优化迭代的过程,其单应性估计速度较慢。基于特征的方法通常包含特征检测与鲁棒单应性估计2个过程,特征检测采用例如尺度不变特征变换(SIFT)[8]的特征提取方法提取2幅图像中的关键点并进行匹配,建立对应关系,在鲁棒单应性估计中采用例如RANSAC[9]的方法迭代以寻找最优的单应性矩阵。过往的研究在寻找可靠的特征中做出了努力,如在特征检测过程中添加线特征[10]或引入更复杂的几何形状[11]。基于特征的方法整体来说稳定性与精度比基于像素的方法有所提升,但其依赖于稳定的特征检测,当无法检测或匹配到足够数目的特征时,其单应性估计结果会出现较大的偏差[12]。
随着深度卷积神经网络(CNN)在计算机视觉领域的快速发展,基于深度学习的方法已经在光流估计[13]、密集匹配[14]、深度估计[15]等密集几何视觉任务中取得了良好的结果,通过深度学习进行单应性估计逐渐代表了最先进的性能。ETONE等[16]提出的HomographyNet在基于深度学习的方法中开创先河,其首次尝试将深度学习应用于单应性估计,构建了VGG结构[17]的单应性回归网络。在该工作中,网络预测图像中4个像素点的8个方向的像素偏移运动,而不是直接回归单应性矩阵,这也为之后的工作奠定了基础,其取得了与传统方法类似的性能。ZENG等[18]提出了PFNet有监督模型,使用U-net架构[19]直接估计2幅图像逐像素对的偏移,并在后处理阶段引入RANSAC生成最终的单应性估计结构,通过与传统方法进行结合获得了更好的性能。
由于在实际单应性估计任务中,获得图像对之间的单应性真值的成本极高,因而尝试构建无监督学习是该领域的发展方向。NGUYEN 等[20]通过将空间变换网络(STN)[21]引入单应性估计网络中而首次实现了端到端的无监督单应性估计模型。其通过比较单应性变换后的源图像块和目标图像块的像素级光度损失来训练单应性回归网络。LIU等[22]在此基础上通过学习内容感知的注意力掩膜来拒绝前景物体和动态对象,提出了用于滤除非鲁棒区域的三重损失。KOGUCIUK等[23]在PFNet[18]的基础上提出了一个双向隐式(biHomE)损失函数,提高了无监督模型的精度表现。以上提出的无监督模型对光照变化具有一定的鲁棒性,减轻了动态前景对于精度的影响,但其均对视差较大的图像不具有鲁棒性,无法适用于实际的低重叠场景。
基于以上研究现状,现有的基于深度学习的单应性估计方法存在的主要问题包括:基于监督学习的方法依赖于数据集真值的生成,在单应性估计任务中难以获取实际的单应性真值,真值获取成本较高且效果不佳;基于无监督学习的方法目前是研究的主流方案,但绝大部分方案采用基于图像块像素级光度损失的网络损失构建方案,网络感知域较小,对于大基线场景适应性较差;现有技术采用了数据增强的思路来解决图像的光照变化问题,但其对单应性估计任务中常见的运动模糊现象适应性较差;此外,从整体来看,目前基于深度学习的单应性估计方法受限于网络结构,几乎无法学习到图像各通道间的关联性,导致相比于传统方法,其单应性估计精度仍不存在明显优势。
为了解决上述问题,本文构建了一种带有注意力机制的大基线场景端到端单应性估计方法,采用无监督学习的方式进行单应性估计。构建了带有注意力机制的单应性回归网络层,采用ResNet基本网络架构[24],引入SE通道注意力[25]模块,获得网络对于图像各通道间关联性的学习;提出了基于掩膜与感知损失度量的二元无监督损失构建方式,利用图像掩膜的方式将图像整体引入网络损失计算;构建了Homo-COCO合成数据集,数据集中引入随机注入颜色、亮度和伽马位移、高斯模糊,采用数据增强使得网络模型对于光照变化与运动模糊具有一定的鲁棒性,以获得更强的真实场景泛化能力。
1" 端到端单应性估计算法结构
1.1" 网络整体架构
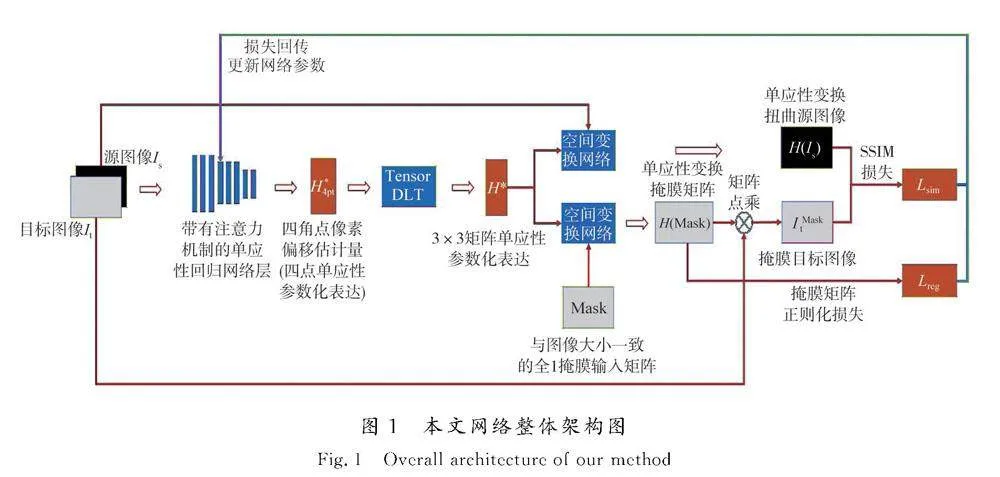
本文提出的端到端单应性估计方法采用无监督学习进行模型训练,因而其网络构建的核心包括单应性参数回归网络层的设计、网络无监督损失的设计以及训练数据集的构建方法。本文构建了带有注意力机制的单应性回归网络层,其以6通道堆叠图像作为输入,经过网络回归及张量直接线性变换层估计3×3矩阵单应性参数化表达。提出了基于掩膜与感知损失度量的二元无监督损失作为网络损失以更新网络参数。图1所示为网络的整体架构。
1.2" 带有注意力机制的单应性回归网络层
常见的表示单应性变换的方法为3×3矩阵表示的参数化方法,其由于尺度的不确定性而具有8个待回归参数,可以直接对这8个参数进行回归,但由于其中混合了旋转与平移项,作为优化问题的神经网络在处理这种量纲不一致的问题时会难以收敛。根据文献[16]中的思路,选择另一种四点参数化的方法,其用源图像中4个点与目标图像中对应的4个点之间的8个x、y像素偏移量来表征单应性变换。四点参数化表示同样具有8个维度,变换表征上与3×3矩阵表示一一对应,但其每个维度均为像素点的偏移量,量纲表示一致,更适合神经网络进行回归。
构建四点参数化单应性矩阵回归网络层,实现对输入图像的特征提取以及8维单应性矩阵的参数回归。单应性网络回归层的输入是2幅具有单应性变换的通道叠加的RGB图像,经过网络的特征提取以及全连接层参数回归,最终输出得到源图像4个角点对应的8个像素偏移量。
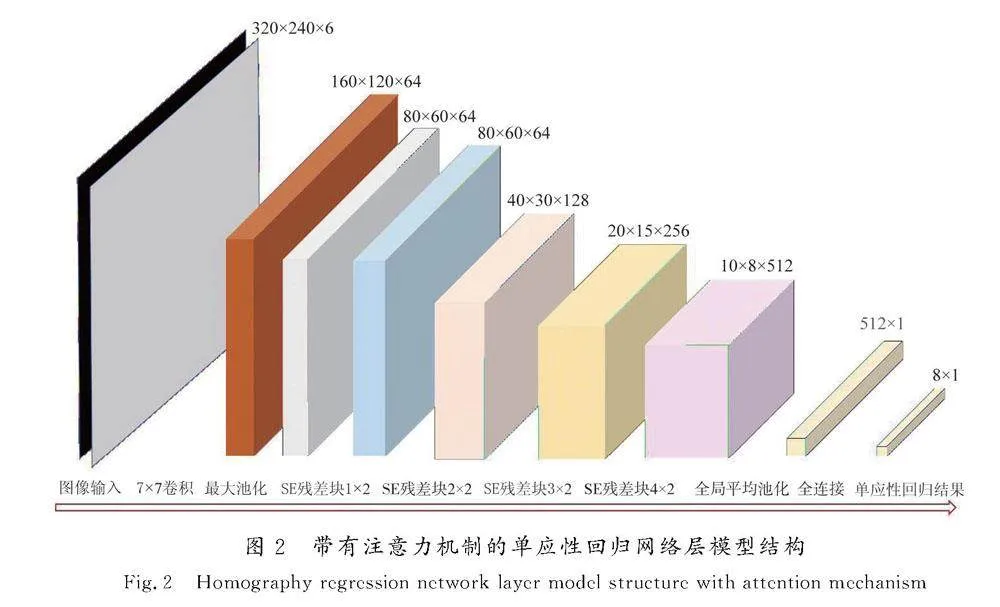
本文构建的单应性回归网络,摒弃了先前工作中常用的VGGNet网络架构,以残差神经网络ResNet[24]作为主要架构,引入SE(squeeze-and-excitation)[26]模块用于为网络引入通道注意力机制,提高卷积神经网络在特征图通道层面的关联,网络模型结构如图2所示。
ResNet网络相比于传统VGG网络添加了残差结构以解决因网络深度增加而产生的退化问题,使得网络在深度增加的情况下保证网络整体的特征提取能力不下降。出于在嵌入式设备上进行模型部署对于模型大小的考虑,本文采用ResNet18作为主体网络架构,相比于VGG网络提高了模型的表达能力和性能,且网络学习过程更加顺畅和稳定,模型精度以及泛化能力有所提高,可以更稳定精准地提取到2张对应输入图像中的特征关联,稳定的特征关联保证了模型单应性回归的精度。
卷积操作是卷积神经网络的核心,保证卷积层高效、正确地学习到图像特征是至关重要的。单应性回归网络采用叠加的6通道图像作为输入,6个通道之间在单应性变换中存在明显的特征关联,因而在卷积操作中引入关于通道的注意力机制从直观上讲可以提高通道之间关联的特征提取效果,进而增强网络整体的单应性回归性能。
本文在单应性网络回归层中引入了SE模块,旨在关注特征图在通道维度上的联系,筛选出针对通道的注意力,自动学习到不同通道特征的重要程度。常见的卷积操作只能作用于一个局部区域,使得输出的特征图几乎无法关注通道之间的联系,SE模块引入了Squeeze和Excitation两部分来引入通道之间的注意力。
Squeeze操作首先对特征图每一个通道上的特征通过全局平均池化(GAP)进行融合,也就是实现了压缩操作,构建全局特征。Excitation对得到的全局特征输入带有ReLU的2个全连接过程,实现对不同通道之间权重值的回归。最终将原始特征图与通过学习回归得到的各通道的权重值进行相乘即可得到最终的带有通道注意力的输出特征图。通过实验发现,在网络中过早引入SE操作会由于提取到的特征不够高维而缺少通道之间的相关性,破坏图像信息的连续性。因此选择在ResNet网络中第2个残差块即完成2次特征提取后引入SE操作,此时对特征图通道维度之间的信息关注可以有效提升模型在单应性回归任务中的表现。采用此种方式构造的SE残差块内部结构如图3所示。
1.3" 张量直接线性变换(DLT)与空间变换层
基于文献[20]的思路,本文设计了张量直接线性变换(direct linear transform,DLT)与空间变换层,用于实现基于单应性回归结果的可微分的源图像单应性扭曲变换。
张量直接线性变换操作紧随在单应性网络回归层之后,用以将单应性网络回归得到的四点参数化单应性回归结果通过直接线性变换的方法转换为常规的3×3矩阵参数化,用以对图像实现单应性扭曲变换。DLT算法是常用的单应性参数计算方法,张量直接线性变换是将其应用在网络中回归得到的张量上,在实现网络训练并行化的同时保持整体的可微分性用于网络整体的反向传播训练。整体该层网络的输入是上一层回归网络得到的4对坐标偏移量,输出的是3×3矩阵参数化的单应性H矩阵。
空间变换层串联张量直接线性变换之后,通过STN实现对源图像的单应性变换以获取其扭曲源图像。该层网络主要利用了空间变换网络的可微分透视变换特性,包含3个主要组成部分:单应性估计的归一化逆运算、参数化采样网格生成器、可微分采样。利用这3部分可以实现依靠3×3矩阵参数化的单应性H矩阵作为输入,可微分地输出经过单应性变换扭曲后的源图像,变换图像的同时保证了网络的可微分性用于神经网络反向传播训练。
1.4" 基于掩膜的无监督损失构造方式
在之前的无监督深度学习方案中,通常采用2个经过裁剪的小图像块作为输入,根据输入前向推理回归单应性变换之后,通过单应性变换将源图像进行变换后再取源图像块位置的新图像块与目标图像块构建L1光度误差损失,通过衡量图像块中的像素相似程度间接反映单应性估计的准确性,在没有单应性真值的情况下构建间接光度损失实现无监督学习。该过程网络的整体损失表示为
L=‖P(H(Is))-P(It)‖1 ,(1)
式中:Is代表输入源图像;It代表目标图像;H代表对图像进行单应性变换的过程;P代表获取图像块的过程。
损失的构建方式是无监督单应性估计训练过程中的重要一环,直接影响单应性矩阵训练的收敛性和稳定性。分析总结发现,大部分之前的无监督学习方案采用图像块输入的原因是图像经过单应性变换后生成的新图像是形状不固定的,在原始图像分辨率下观察新图像是带有形状填充黑边的,如果直接使用变换后的源图像与目标图像构建光度误差损失会出现很多错误损失点,无法正确计算网络损失。通过选择小图像块计算损失的方法可规避该问题,在小图像块中经过单应性变换后原像素位置会由别的像素进行填充,不会有图像中出现黑边的情况,保证损失计算的正确性。一方面,这种妥协的做法限制了网络输入图像的尺寸,降低了网络感知域从而限制了网络精度;另一方面,这种输入方式在2幅输入图像之间基线较大重叠较小的情况下,可能会出现图像中存在重叠区域但2个图像块中不存在重叠区域的现象,此时网络的推理将会完全失效。
为了解决以上总结的使用图像块作为输入的方法中存在的问题,本文使用了一种基于掩膜的无监督损失构造方式,直接使用2张原始分辨率尺寸的图像作为输入,确保所有的重叠区域都在网络的输入中进行体现,在提高网络感知域精度的同时加强网络对于图像基线长度变化的鲁棒性。具体地讲,本方法通过将2幅完整图像输入单应性网络回归层得到源图像到目标图像的单应性变换参数,通过空间变换层对源图像进行单应性变换,同时构建一个与源图像分辨率一致的全1掩膜输入矩阵,将掩膜同样输入参数相同的空间变换层得到单应性变换后的掩膜,因而变换后的掩膜中像素值为1的区域表示变换后源图像的有效像素区域,为0的表示无效像素区域。通过将掩膜与目标图像按像素相乘即可滤除掉变换中的无效像素区域,得到掩膜处理后的目标图像,其与变换后的源图像之间不存在边界效应,即可直接进行图像相似度衡量构建有效误差损失,监督该损失进行学习即可实现对单应性变换参数的学习。该构建损失的过程如图4所示,其中SSIM代表结构相似性指数。
基于掩膜的无监督损失表示为
L′=‖H(Is)-H(Mask)·It‖1,(2)
式中:H表示单应性变化过程;Mask表示与源图像相同分辨率的全1掩膜输入矩阵;·代表按图像像素相乘。式(2)表示了以L1光度误差的方式衡量图像相似性,计算网络整体损失。
1.5" 基于感知损失度量的二元损失
构建无监督损失的过程即为衡量单应性变换后的源图像与目标图像之间相似性的过程,2幅图像相似性越高代表网络单应性变换回归越准确,因此如何准确、鲁棒地衡量2幅图像的相似度是准确构建网络损失的关键问题。本方法以感知损失度量为相似度指标损失,并引入了约束图像掩膜完整性的正则指标损失,将2类损失结合构建了最终的二元网络损失。
在之前的无监督深度单应性回归工作中,研究人员通常采用直接计算2幅图像之间的平均像素光度损失(L1损失)作为网络损失,例如文献[20]中定义网络损失的公式为
LPW=1|xi|∑xi|Is(H(xi))-It(xi)|,(3)
式中:xi代表图像中的离散像素;Is(H(xi))表示经过单应性变换后的源图像像素点;It(xi)表示目标图像像素点,网络损失基于2幅图像所有像素光度误差的均值来建立。对于图像中每个像素,L1损失计算其在2个图像之间的差的绝对值,然后对这些值取平均,其整体计算较为简单,易于实现。但在实际应用过程中,由于拍摄原因2幅图像之间可能存在亮度、对比度等因素变化,直接计算L1损失会引入额外的像素误差导致损失偏差较大,从而影响网络整体的收敛效果。
SSIM[27]损失是基于视觉感知的一种图像相似度度量,考虑了图像的亮度、对比度和结构3个方面,旨在改善传统像素对比的方法无法充分反映人类视觉感知特性的问题。本文网络损失函数主体采用了基于SSIM损失的设计思路,可以更好地处理亮度、对比度和图像结构的变化,在图像单应性估计的工作中获得了更高的泛化性。
其计算相似性的过程由亮度、对比度和结构3部分构成,其中亮度部分的计算公式为
l(x,y)=2μxμy+c1μ2x+μ2y+c1 。(4)
对比度部分的计算公式为
c(x,y)=2σxσy+c2σ2x+σ2y+c2。(5)
结构部分的计算公式为
s(x,y)=σxy+c3σxσy+c3。(6)
式中:μx和μy分别表示2幅图像的均值;σx和σy分别表示2幅图像的方差;σxy表示2幅图像之间的协方差;c1、c2和c3是3个常数,用于避免分母为0。整体构建SSIM损失是三者的乘积,通常得到最终的计算公式为
SSIM′(x,y)=(2μxμy+c1)(2σxy+c2)
(μ2x+μ2y+c1)(σ2x+σ2y+c2) 。(7)
此时计算出的取值范围在-1~1之间,数值越大代表图像相似度越高,为了构建损失用于网络整体损失递减收敛训练,构建:
SSIM(x,y)=1-SSIM′(x,y)2 。(8)
得到最终在0~1范围内的损失,且数值越小代表图像相似度越高,进而代表网络单应性估计越准确。因而采用SSIM指标的网络的相似度指标损失可以表示为
Lsim=SSIM(H(Is),H(Mask)·It) ,(9)
由于网络采用了基于掩膜的无监督损失构造方式,当单应性变换后的源图像H(Is)与源图像Is之间重叠较小甚至没有重叠时,H(Is)趋近于全0矩阵,H(Mask)同样也会趋向于一个几乎全0的矩阵,此时参与计算相似度损失的有效像素量趋近于零,但计算得到的Lsim也趋近于零,相似度损失极小。此时如果只采用图像相似度损失作为网络损失,网络训练过程会陷入局部最优解,无法完成正常的训练过程,该种错误情况如图5所示。
因而本文在损失函数设计中引入了基于变换掩膜均值的正则项作为约束图像掩膜完整性的正则指标损失,其计算方法为
Lreg=1Mean(H(Mask))+0.001 ,(10)
式中:Mean为计算该矩阵所有元素的均值;Lreg取值范围为0~1,其中越接近1代表图像掩膜越完整,当Lreg趋向于0时,代表网络陷入了局部最优解,对其进行正则损失惩罚,增加网络整体损失。将相似度指标损失与正则指标损失结合,最终共同构建的二元损失如下:
L=λLsim+(1-λ)Lreg,(11)
式中λ为网络超参数,用于调整2个损失部分的权重大小。
1.6" 无监督数据生成方法
神经网络的训练过程需要大量数据集作为输入以实现网络的参数学习,由于带有单应性变换真值标签的真实数据集的获取成本较高,因而在单应性估计任务中通常采用基于一般图像数据集生成的合成数据集。本文构建的网络结构采用无监督学习方法,网络需要的训练集仅需要2幅具有单应性变换特性的图片对进行构建。本文基于MSCOCO图像数据集[27]自行构建了Homo-COCO合成数据集,相比于之前工作采用图像块作为单应性变换来构建数据集,本文直接基于原始图像尺寸进行单应性变换获取训练图像对,得到更稳定、噪声更小的数据集,以显著提高网络整体的收敛效果;且在引入随机注入颜色、亮度和伽马位移的基础上,引入图像的随机高斯模糊,以使模型对光照变化具有鲁棒性的同时,具有对于单应性估计中相机运动图像模糊的鲁棒性。
生成训练数据集的主要过程包含以下步骤。首先,根据读入源图像的分辨率获取图像4个角点的像素坐标;然后,对4个角点进行随机扰动获取角点像素偏移量,根据扰动得到的4组像素偏移量计算单应性变换矩阵H,将H矩阵的逆矩阵作用于整张源图像得到生成的目标图像;最后,将源图像与生成的目标图像组成一组训练对放入训练集中。其简要过程图如图6所示。
为使模型具有对光照变化的鲁棒性,根据文献[20]的思路,考虑在数据集制作基本流程的基础上,随机注入颜色、亮度和伽马位移,以使训练出的模型具有对光照变化的泛化性。此外,现实世界相机运动过程中由于运动所带来的图像模糊现象时有发生,而单应性估计任务中的合成数据集并未考虑该模糊因素,故本文额外引入对于模糊的数据增强来解决该问题。相机运动过程产生的噪声可以近似为高斯噪声,因而采用随机的高斯模糊操作作用生成的目标图像,用随机产生的高斯模糊半径对应随机的运动模糊效果,最终得到带有随机运动噪声效果的目标图像与源图像对,加入最终的训练集中。生成的训练图像中,对目标图像相比源图像带有随机单应性变换、颜色变化、亮度变化、伽马位移和高斯模糊效果。
2" 实验验证
目前常见的单应性估计方法包括传统方法、有监督学习方法与无监督学习方法,本文综合这3种典型方法进行实验比较。具体而言,在传统方法中选择了SIFT+RANSAC的方法作为代表,其相比于ORB等大多数传统方法具有更高的准确性;在有监督学习中选择了文献[16]中的HomographyNet模型,其是首个采用学习方式估计图像单应性的模型,是有监督学习的典型代表;在无监督学习中选择了文献[20]和文献[23]中的模型,文献[20]首次将无监督学习引入单应性估计任务中,文献[23]是目前无监督深度单应性估计任务中的SOTA解决方案。
针对3种对比方法,本文在实验环节进行了准确性的定量比较,并设计实验测试了各种方法对于重叠率、光照变化以及运动模糊的鲁棒性。本文在自行构建的Homo-COCO数据集测试集上对各种方法的表现进行评估,其是典型生活化场景,且包含了不同重叠率、不同光照变化以及不同运动模糊效果的测试数据。
本文中训练集和测试集均采用了上文所述的数据集生成方法,在MSCOCO数据集[28]的基础上自行构建Homo-COCO数据集,其中训练集包含100 000对图像,测试集包含(5 000+2 000)对图像。数据集来源于MSCOCO数据集,因而其覆盖了包含弱纹理、暗光、重复纹理等多种复杂条件的生活化场景,内容全面。在测试集生成过程中控制了图像对之间的重叠率,用于在测试阶段测试算法对基线长度变化方面的鲁棒性,其中图像对之间重叠率变化依靠数据集生成方法中的随机扰动量控制。为了测试算法对于光照变化以及运动模糊的鲁棒性,在测试集中额外生成了2 000对明确引入随机光照变化与高斯模糊的图像,以验证本文方法在这2部分极端场景下的表现。
此外,本文方法预期应用场景为隧道内部的掌子面场景,因而实际采集、构建了一部分隧道图像数据对本文算法进行测试。隧道图像在广西桂林某实际隧道项目中进行采集,采集设备为DJI Osmo Action 3,图像原始分辨率为2 688×1 512。为了便于进行模型测试,将图像同样缩放为320×240的像素尺寸。该场景具有重复纹理、低光照、位移变化大、噪声模糊大等技术难点,其可完美考验模型对于视差、光照、噪声等的鲁棒性,该部分测试图像对的生成方法与上文方法保持一致,主要覆盖了典型的隧道内部作业场景,测试集大小为700组图片。所有测试集下的评估指标均采用4pt-Homography RMSE方法,其计算如式(12)所示。
LH=‖H4pt-H*4pt‖2,(12)
式中:H4pt为估计的4个边缘点偏移量;H*4pt为真实的边缘点偏移量。计算估计的图像4个边缘点偏移量与真实的边缘点偏移量之间的二范数,用以衡量各个方法在测试集上单应性估计的准确性。
本文提出的无监督深度学习方法在Pytorch框架中实现,使用批大小为256的随机梯度下降方法进行训练,训练过程中采用了Adam优化器,根据经验设置了初始学习率为0.000 1,网络超参数λ初始值设置为0.9,在训练过程中学习率逐渐下降,超参数λ逐渐上升以提高感知误差的损失权重。硬件上使用了1张Nivdia A6000显卡,在16 h的训练时间中,模型在训练集上总计进行了150轮的迭代训练。
训练采用了丰富的图像数据,模型得到了充分的预训练,在其他特定数据集上可以进行后续微调优化。
基于特征的传统SIFT+RANSAC方法采用标准的OpenCV Python进行实现,在双路Intel Xeon Platinum 8336C CPU上进行运行测试,通过对2张测试对图像提取SIFT特征,并基于提取到的特征做特征匹配,根据经验采用阈值为5像素的RANSAC进行鲁棒单应性估计,保证特征匹配的准确性。基于深度学习的对比方法采用预训练模型直接进行推理,同样采用1张Nivdia A6000显卡进行推理,以便与本文提出的方法对比准确性与鲁棒性。
2.1" 不同方法的定性及定量比较
本文主要设计了4组对比试验,以比较各种单应性估计方案。4组对比实验主要包括:Homo-COCO测试集RMSE对比效果、隧道环境测试集RMSE对比效果、针对基线长度变化的对比效果,以及针对光照变化与运动模糊的对比效果。
2.1.1" Homo-COCO测试集RMSE对比效果
在依据上文介绍方法构建的Homo-COCO测试集上进行第1组对比测试,其中测试集生成过程中的随机扰动量最大值设置为45,即图像4个角点最大随机偏移45个像素值。本实验主要验证包含本文方法在内的5种不同方法的准确率,其中准确率评价指标采用式(12)介绍的均方根误差RMSE方法,其取值越小代表单应性估计得越准确。最终得到的测试结果如表1所示。
根据表1中的测试数据可以发现:首先,本文提出的基于深度学习的方法在准确度方面优于以SIFT方法为代表的传统方法;其次,本文提出的无监督学习方法同样优于有监督学习方法,有监督学习方法相比于一般的无监督学习方法通常有着更高的准确率;最后,本文的无监督学习方法优于现有的无监督学习方法,由于采用了更大的网络模型与网络深度,本文的方法在测试集所有部分的表现均优于目前最优的无监督学习方法。综上所述,本文方法在5 000对测试集上的RMSE准确度表现大幅度领先其余4种对比方案,在典型生活化场景下的测试表现出了显著的单应性估计效果。
2.1.2" 隧道环境测试集RMSE对比效果
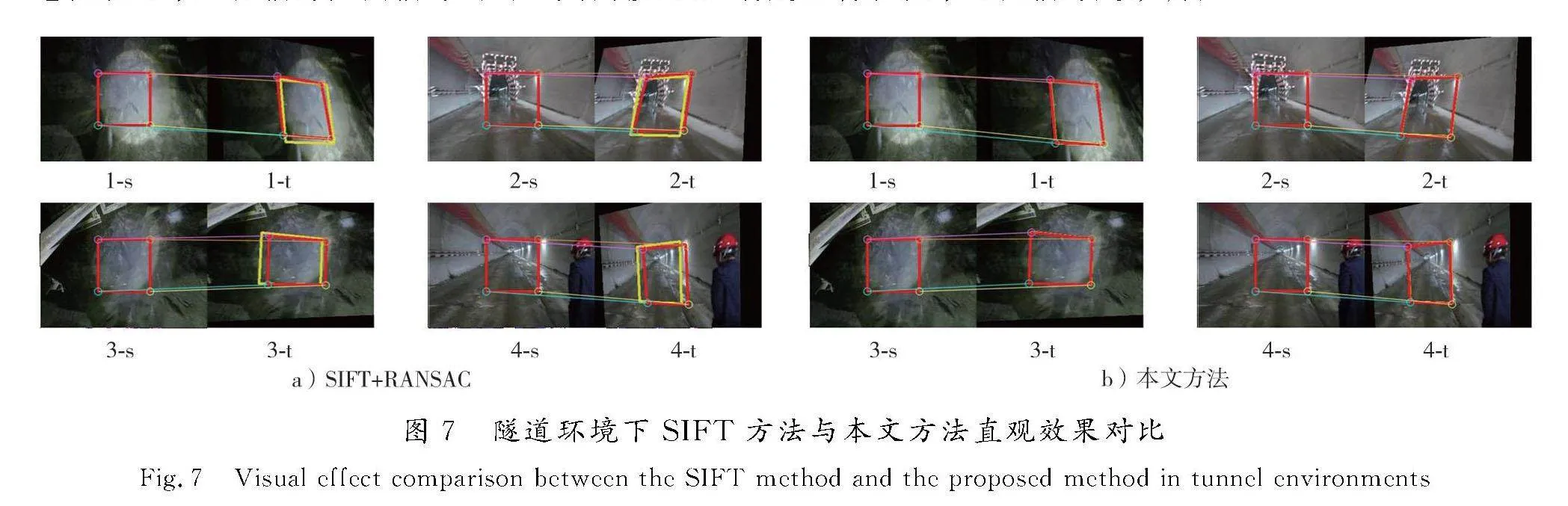
在自行构建的隧道测试集上进行第2组对比试验,依旧进行RMSE准确率的量化对比,以及展示部分样例的定性对比。隧道测试集中涵盖了典型的隧道内部环境场景,其相比于Homo-COCO数据集中的生活化场景更加凸显了图像中的强光、暗光、重复或缺乏纹理以及运动模糊等极端场景,更加考验单应性估计的稳定性。基于深度学习的方法均未在此类场景上进行训练,考验了模型整体的环境泛化性。如表2所示,展示了5种单应性估计方法在700对隧道测试集上的RMSE均值以及估计成功数量和百分比。其中本文实验设定当单应性估计的RMSE小于10时,认为此次单应性估计成功,否则认为此时偏差过大,单应性估计结果已经失效不可用。
本方法由于统计的是全图4个边角偏移量的大小,因而偏移尺度自然会更大,评价过程中存在天然劣势,但在RMSE过程中仍旧远超其他方法,进而表明了本方法在非训练过的隧道场景的准确性、鲁棒性与泛化性。几种其他对比方法中,SIFT+RANSAC的方法表现出了稍好的效果。图7展示了本方法在某些基于SIFT+RANSAC的方法失效场景下的对比效果,以直观观察其他单应性回归方法失效场景的主要特点。其中s、t图分别表示源图像与目标图像,2幅图像中的红色框表示单应性估计真值所对应的四点偏移量,黄色框表示单应性估计方法估计出的四点偏移量,两者越贴合表明单应性估计越准确。
2.1.3" 针对基线长度变化的对比效果
为了验证本文方法对于大基线场景的适应性,在不同基线长度的Homo-COCO测试集上进行了分类对比分析,采用RMSE评价方法的单应性回归对比效果。其中测试集上的不同基线长度依靠不同范围的角点随机扰动量进行生成,将4点x、y坐标随机扰动量的绝对值均值作为基线控制参数,当基线控制参数小于等于20时,认为当前图像对为小基线;当基线控制参数大于20而小于等于25时,认为当前图像对为中基线;当基线控制参数大于25时,认为当前图像对为大基线。以此为标准分类过后的Homo-COCO测试集组成如表3所示。
作为目前无监督学习单应性估计中的SOTA解决方案,Unsup-PFNet方法是本文无监督学习方法的主要对比方案,因而在本实验部分主要测试了本方法、Unsup-HomoNet方法和Unsup-PFNet方法在以基线大小分类后的Homo-COCO测试集上的单应性估计表现。同样以RMSE指标进行量化评估,各基线长度的实验结果如表4所示。
根据实验结果首先可以发现,3种方法的单应性估计效果均与图像对之间的基线大小存在直接关联,因而可以认为基线大小是决定单应性网络估计效果的关键参数。其次,作为无监督学习类方案中的代表性方法,Unsup-HomoNet方法在小基线场景的RMSE评估均值为9.33,基本满足成功单应性估计的目标,证明该方法在小基线场景具有一定的适应性;但经过实验可以发现,在大基线场景下,Unsup-HomoNet方法的RMSE评估均值为33.84,明显差于该方法在小基线场景的表现。本方法在大基线场景下的RMSE评估均值为5.00,明显优于其他2种无监督方法,且相比于本方法在小基线场景与中基线场景的表现也并无明显落后。
由此可见,本方法在整体RMSE评估指标优于既有方法的同时,在基线大小这个主要影响因素下也具有一定的鲁棒性,在大基线场景下同样可以保持不明显逊色于小基线场景的单应性估计表现,RMSE评估指标满足成功单应性估计的需要。相比于既有方法,本方法对大基线场景有显著的适应性。
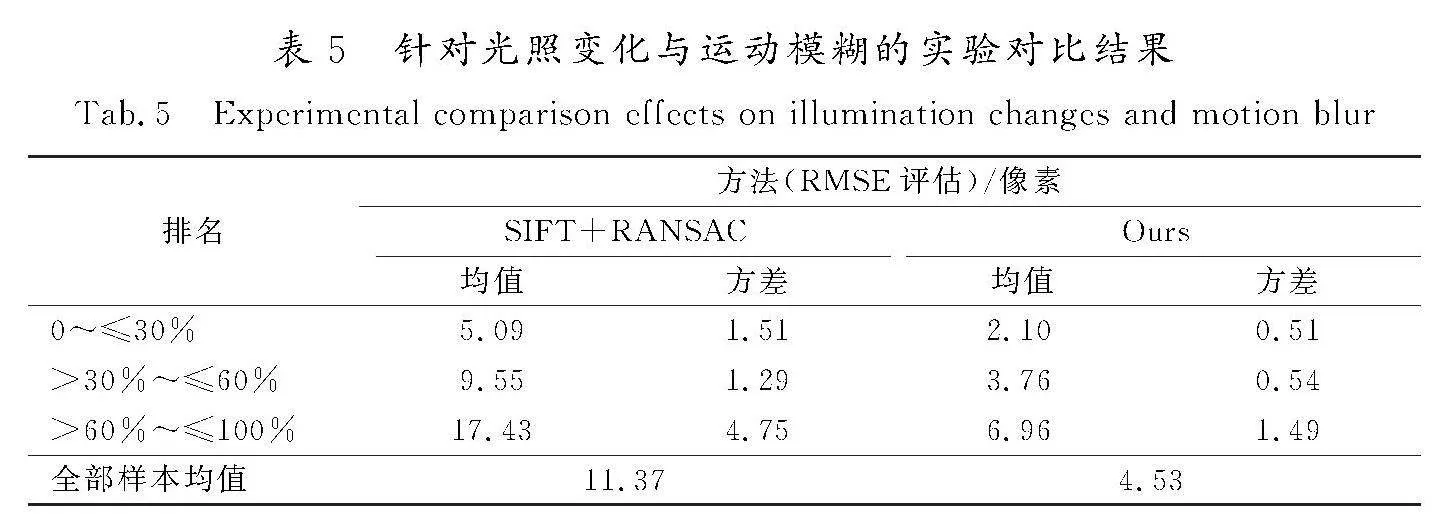
2.1.4" 针对光照变化与运动模糊的对比效果
为了验证本文方法对于现实应用场景中常见的光照变化与运动模糊效果的适应性,在2 000对明确引入随机光照变化与高斯模糊的图像测试集上进行了实验测试。该部分测试集基本的生成方法与之前的方法保持一致,但经单应性变换生成目标图像后,额外对测试集中所有目标图像进行了从0.9~1.1范围内的随机伽马偏移、0.8~1.2范围内的随机亮度调整,以及0.9~1.1范围内的随机RGB三通道颜色调整,并额外引入了0.01~1.0范围内大小高斯核的随机高斯噪声作为运动模糊项。
从原理上来讲,SIFT等传统方法由于特征点具有光照不变性等技术特点,与基于深度学习的端到端估计方法相比,其对于光照变化与运动模糊的鲁棒性会更高。因而在本实验部分,选择与SIFT+RANSAC的单应性估计方法进行对比,横向比较本方法在多种场景的适应性。实验数据对比结果如表5所示。
由定量实验结果可以发现,SIFT+RANSAC方法在该特定环境数据集上仍旧有着与一般数据集相当的单应性估计效果,说明传统方法对于一般的光照变化与运动模糊的适应性较好,这2个因素对其几乎没有影响;同时本方法由于无监督学习网络的倾向图像相似特性,在该特定环境数据集上的表现相比于一般数据集有少许退步,但整体效果相比于SIFT+RANSAC方法仍具有明显竞争力,整体网络单应性估计成功率为99.8%,绝大部分估计结果可以认为是有效的。因而总体来看,本方法对于光照变化与运动模糊具有一定的适应性。
图8展示了一些测试样下的单应性估计定性对比结果,其中s、t图以及黄色、红色框的定义与前文保持一致。从图中可
以直观看出,SIFT+RANSAC方法在某些具有光照变化与运动模糊的场景存在估计失效的问题,而本文方法在这些场景下表现良好。
2.2" 消融实验
带有注意力机制的单应性回归网络层、基于掩膜与感知损失度量的二元无监督损失以及带有随机光照变化与运动模糊的Homo-COCO数据集是本工作的3部分主要贡献。其中关于带有随机光照变化与运动模糊的Homo-COCO数据集的数据增强训练作用已经在针对光照变化与运动模糊的对比效果中有所体现,其显著增强了网络对随机光照变化与运动模糊的适应效果,验证了应用该数据集相比于应用之前的合成数据集在网络训练效果上的优越性。消融实验将主要就带有注意力机制的单应性回归网络层与基于掩膜与感知损失度量的二元无监督损失进行,验证这2部分贡献对于本文方法的有效作用。
2.2.1" 带有注意力机制的单应性回归网络层验证
为了验证本文引入的带有注意力机制的单应性回归网络层对于单应性估计准确度的提升效果,将本文架构中的单应性回归网络层替换为与文献[20]中类似的VGG型架构,在损失函数构建部分保持不变的情况下,该部分实验在Homo-COCO测试集的5 000对图像数据上以RMSE的值定量对比单应性估计的准确度,实验结果如表6所示。
结果表明,本文在单应性回归网络层中引入的SE注意力机制以及ResNet型网络架构,可以优化网络模型,提升网络的适应性与回归效果,从而提升了本文网络整体在单应性回归任务中的精度表现。
2.2.2" 基于掩膜与感知损失度量的二元无监督损失验证
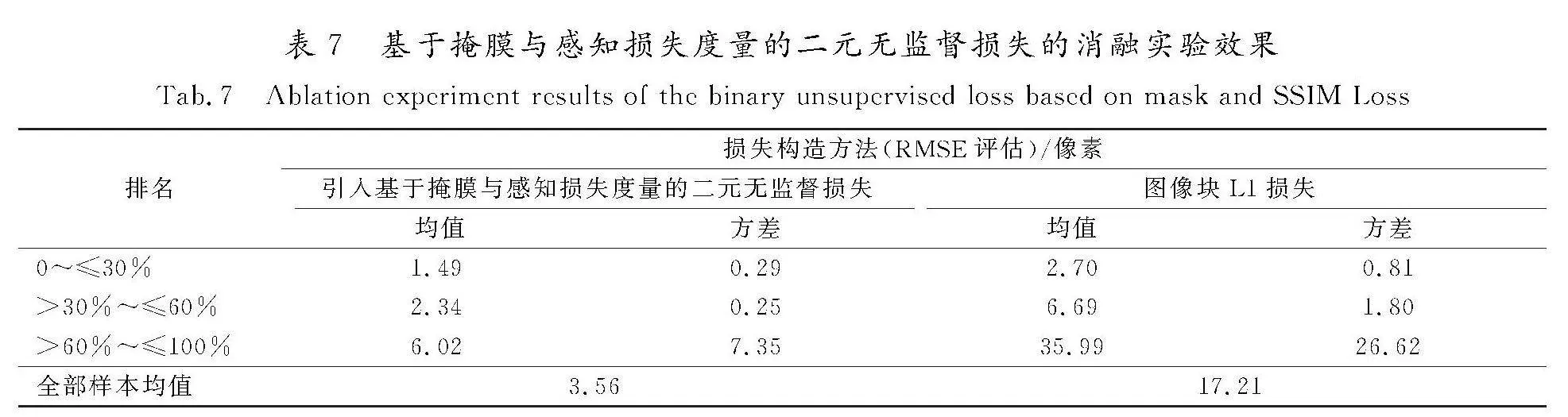
为了验证本文提出的基于掩膜与感知损失度量的二元无监督损失对于网络模型的应用效果,在此进行类似的消融实验设置。保持本文架构中带有注意力机制的单应性回归网络层不变,采用与文献[20]中类似的损失构造方式,直接将单应性变换后的源图像块与目标图像块之间的L1损失,作为网络损失进行回传以更新网络参数。该部分实验同样在Homo-COCO测试集的5 000对图像数据上,以RMSE的值定量对比单应性估计的准确度,实验结果如表7所示。
结果表明,本文在无监督损失构建过程中引入的基于掩膜与感知损失度量的二元无监督损失构造方式,可以优化模型训练过程,提升网络的收敛效果,且基于掩膜的损失构造方式主要提高了模型的感知域,提升了对于大基线场景单应性估计的精度,进而从整体上提升了本方法在单应性回归任务中的性能表现。图9展示了5组场景下采用图像块L1损失与采用基于掩膜与感知损失度量的二元无监督损失时,单应性估计准确性的对比效果。
其中第1行图像表示输入本文方法的源图像与目标图像,红框内的区域表示输入消融方法的源图像块与目标图像块,可以直观发现,2个图像块间重叠区域较小,网络感知域受限;第2行与第3行图像分别表示本文方法与消融方法的单应性估计效果对比,可以发现在图像块间重叠区域较小时,本文方法由于扩大了网络感知域,进而提高了网络整体的单应性估计表现,相较于消融方法有明显的准确度提升。
3" 结" 语
本文提出了一种带有注意力机制的大基线场景端到端单应性估计方法,用于以无监督学习的方式解决图像单应性估计问题。构建了带有SE注意力机制的单应性网络回归层,在传统单应性回归模型的基础上采用了ResNet架构,利用SE注意力机制关注了图像对通道间的联系,提高了模型的适应性。摒弃了传统的以图像块间L1损失作为网络损失进行回传的方法,提出了基于图像掩膜与感知损失度量的二元无监督损失,利用图像掩膜的方式将图像整体引入网络损失计算,提高网络感知域,进而提高网络对于大基线场景的适应性。构建了Homo-COCO合成数据集,其中包括100 000对训练数据以及5 000对测试数据,数据集中引入随机注入颜色、亮度和伽马位移、高斯模糊,使得以此训练集训练的网络模型对于光照变化与运动模糊具有一定的鲁棒性,获得更强的真实场景泛化能力。充分的对比及消融实验表明,本文提出的单应性估计方法对比现有方法在精度上具有较强的优越性,且3部分均对于精度指标提升有所贡献,方法在大部分场景下具有适应性。值得注意的是,由于网络参数量较大,在典型场景下相比于其他单应性估计方法,本文方法在估计速度上不占优势,将本文方法轻量化以更便捷地部署在移动设备上将是下一步工作的重点。
参考文献/References:
[1]" YE
Nianjin,WANG Chuan,LIU Shuaicheng,et al.DeepMeshFlow:Content adaptive mesh deformation for robust image registration[EB/OL].(2019-12-11)[2024-08-20].https://arxiv.org/abs/1912.05131.
[2]" WANG Lang,YU Wen,LI Bao.Multi-scenes image stitching based on autonomous driving[C]//2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC).Chongqing:IEEE,2020:694-698.
[3]" CAMPOS C,ELVIRA R,RODRGUEZ J J G,et al.ORB-SLAM3: An accurate open-source library for visual, visual-inertial, and multimap SLAM[J].IEEE Transactions on Robotics,2021,37(6):1874-1890.
[4]" ZHANG Zhengyou.A flexible new technique for camera calibration[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(11):1330-1334.
[5]" SIMON G,FITZGIBBON A W,ZISSERMAN A.Markerless tracking using planar structures in the scene[C]//Proceedings IEEE and ACM International Symposium on Augmented Reality (ISAR 2000).Munich:IEEE,2000:120-128.
[6]" LUCAS B D,KANADE T.An iterative image registration technique with an application to stereo vision[C]//Proceedings of the 7th International Joint Conference on Artificial Intelligence.San Francisco:Morgan Kaufmann Publishers,1981:674-679.
[7]" BAKER S,MATTHEWS I.Lucas-kanade 20 years on:A unifying framework[J].International Journal of Computer Vision,2004,56(3):221-255.
[8]" LOWE D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[9]" FISCHLER M A,BOLLES R C.Random sample consensus:A paradigm for model fitting with applications to image analysis and automated Cartography[J].Readings in Computer Vision,1987.DOI: 10.1016/B978-0-08-051581-6.50070-2.
[10]PUMAROLA A,VAKHITOV A,AGUDO A,et al.PL-SLAM:Real-time monocular visual SLAM with points and lines[C]//2017 IEEE International Conference on Robotics and Automation (ICRA).Singapore:IEEE,2017:4503-4508.
[11]GEE A P,CHEKHLOV D,CALWAY A,et al.Discovering higher level structure in visual SLAM[J].IEEE Transactions on Robotics,2008,24(5):980-990.
[12]FANGXIANYONG W U F.An improved ransachomography algorithm for feature based image Mosaic[C]//Proceedings of the 7th WSEAS International Conference on Signal Processing.Athens:[s.n.],2007:202-207.
[13]SUN Deqing,YANG Xiaodong,LIU Mingyu,et al.PWC-Net:CNNs for optical flow using pyramid,warping,and cost volume[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8934-8943.
[14]REVAUD J,WEINZAEPFEL P,HARCHAOUI Z,et al.DeepMatching:Hierarchical deformable dense matching[J].International Journal of Computer Vision,2016,120(3):300-323.
[15]LI Jingliang,LU Zhengda,WANG Yiqun,et al.DS-MVSNet:Unsupervised multi-view stereo via depth synthesis[C]//Proceedings of the 30th ACM International Conference on Multimedia.New York:Association for Computing Machinery,2022:5593-5601.
[16]ETONE D,MALISIEWICZ T,RABINOVICH A.Deep image homography estimation[EB/OL].(2016-06-13)[2024-08-20].https://arxiv.org/abs/1606.03798.
[17]SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].(2014-09-04)[2024-08-20].https://arxiv.org/abs/1409.1556.
[18]ZENG Rui,DENMAN S,SRIDHARAN S,et al.Rethinking planar homography estimation using perspective fields[C]//Computer Vision: ACCV 2018.Cham:Springer,2019:571-586.
[19]RONNEBERGER O,FISCHER P,BROX T.U-Net:Convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer-Assisted Intervention: MICCAI 2015.Cham:Springer,2015:234-241.
[20]NGUYEN T,CHEN S W,SHIVAKUMAR S S,et al.Unsupervised deep homography:A fast and robust homography estimation model[J].IEEE Robotics and Automation Letters,2018,3(3):2346-2353.
[21]JADERBERG M,SIMONYAN K,ZISSERMAN A,et al.Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems.Cambridge:MIT Press,2015:2017-2025.
[22]LIU Shuaicheng,YE Nianjin,WANG Chuan,et al.Content-aware unsupervised deep homography estimation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,45(3):653-669.
[23]KOGUCIUK D,ARANI E,ZONOOZ B.Perceptual loss for robust unsupervised homography estimation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.Nashville:IEEE,2021:4269-4278.
[24]HE Kaiming,ZHANG Xiangyu,REN Shaoqing,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:770-778.
[25]王珂,张根耀.基于ResNet模型的甲状腺SPECT影像诊断[J].河北科技大学学报,2020,41(3):242-248.
WANG Ke,ZHANG Genyao.Diagnosis of thyroid SPECT image based on ResNet model[J].Journal of Hebei University of Science and Technology,2020,41(3):242-248.
[26]HU Jie,SHEN Li,SUN Gang.Squeeze-and-Excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[27]WANG Zhou,BOVIK A C,SHEIKH H R,et al.Image quality assessment: From error visibility to structural similarity[J].IEEE Transactions on Image Processing,2004,13(4):600-612.
[28]LIN T Y,MAIRE M,BELONGIE S,et al.Microsoft COCO:Common objects in context[C]//Computer Vision:ECCV 2014.Cham:Springer,2014:740-755.
