基于编辑序列的跨语言重构检测方法
2024-12-03李涛张冬雯张杨郑琨


文章编号:1008-1542(2024)06-0627-09
摘" 要:
针对基于深度学习的重构检测方法中开发人员没有一致性地记录重构操作,导致提交的信息不可靠以及语言单一性问题,提出了一种新的跨语言重构检测方法RefCode。首先,采用重构收集工具从不同编程语言中收集提交信息、代码变更信息和重构类型,通过代码变更信息生成编辑序列,将所有数据组合为数据集;其次,将CodeBERT预训练模型与BiLSTM-attention模型相结合,在数据集上进行训练和测试;最后,从6个方面对模型进行评估,以验证方法的有效性。结果表明,RefCode相较于只采用提交信息作为LSTM模型输入的重构检测方法,在精确度和召回率方面均实现了约50个百分点的显著提升。研究结果实现了跨语言重构检测,并有效弥补了提交信息不可靠的缺陷,可为其他编程语言和重构类型的检测提供参考。
关键词:
软件工程;重构检测;深度学习;跨语言;代码变更;编辑序列
中图分类号:TP311
文献标识码:A
DOI:10.7535/hbkd.2024yx06007
收稿日期:2023-12-20;修回日期:2024-04-06;责任编辑:冯民
基金项目:国家自然科学基金(61440012);
河北省自然科学基金(F2023208001);河北省引进留学人员资助项目(C20230358)
第一作者简介:
李涛(1998—),男,四川眉山人,硕士研究生,主要从事智能化软件方面的研究。
通信作者:
张冬雯,教授。E-mail:zdwwtx@163.com
李涛,张冬雯,张杨,等.
基于编辑序列的跨语言重构检测方法
[J].河北科技大学学报,2024,45(6):627-635.
LI Tao, ZHANG Dongwen, ZHANG Yang,et al.
Cross-language refactoring detection method based on edit sequence
[J].Journal of Hebei University of Science and Technology,2024,45(6):627-635.
Cross-language refactoring detection method based on edit sequence
LI Tao1, ZHANG Dongwen1,2, ZHANG Yang1,2, ZHENG Kun1
(1.School of Information Science and Engineering, Hebei University of Science and Technology,
Shijiazhuang, Hebei 050018, China;
2.Hebei Technology Innovation Center of Intelligent IoT, Shijiazhuang, Hebei 050018, China)
Abstract:
Aiming at the problems of unreliable commit message caused by developers not consistently recording refactoring operations, and language singularityin deep learning-based refactoring detection methods, a cross-language refactoring detection method RefCode was proposed. Firstly, refactoring collection tools were employed to collect commit messages, code change information, and refactoring types from different programming languages, the edit sequences were generated from the code change information, and all the data were combined to create a dataset. Secondly, the CodeBERT pre-training model was combined with the BiLSTM-attention model to train and test on the dataset. Finally, the effectiveness of the proposed method was evaluated from six perspectives. The results show that RefCode achieves a significant improvement of about 50% in both precision and recall compared to the refactoring detection method which only uses commit messages as inputs to the LSTM model. The research results realize cross-language refactoring detection and effectively compensate for the defect of unreliable commit messages, which provides some reference for the detection of other programming languages and refactoring types.
Keywords:
software engineering; refactoring detection; deep learning; cross-language; code change;edit sequence
重构检测工具对开发人员至关重要,其能够自动检测和分类重构操作,从而提高代码质量和可维护性,帮助管理和维护代码,提升软件的可靠性和效率。大多数重构检测工具[1-4]通过设定相似度阈值来帮助开发者自动化地检测和分类代码重构,但阈值设定经常需要人为干预,且受主观因素和项目差异影响,无法找到通用阈值。RMINER[5]是一款基于AST语句匹配的代码重构检测工具,它无需用户设定阈值,能够根据特征进行重构类型识别,但仅限于Java代码的检测。
深度学习技术具有自适应性和灵活性,能够根据不同的编程语言、项目和场景进行学习和调整,并且已经被应用于各种软件工程任务中[6-19]。在重构检测任务中,一些研究人员将深度学习技术与重构检测工具相结合,提高了重构检测工具的准确率[20-21]。然而,数据收集和检测语言单一等问题仍然存在。一些工作将提交信息作为输入,采用深度学习技术挖掘提交信息中的特征信息,预测提交信息中潜在的重构操作[22-23]。然而,大多数开发者并未在提交信息中一致地记录重构操作[24],导致提交信息成为预测重构操作的不可靠指标。
针对上述问题,本文提出基于编辑序列的跨语言重构检测方法RefCode。使用数据收集工具从Java和Python项目中获取数据样本,并添加代码变更信息和编辑序列,弥补提交信息不可靠的问题;此外,将CodeBERT预训练模型[25]和BiLSTM-attention模型[26]相结合,实现跨语言重构检测。
1" RefCode重构检测方法
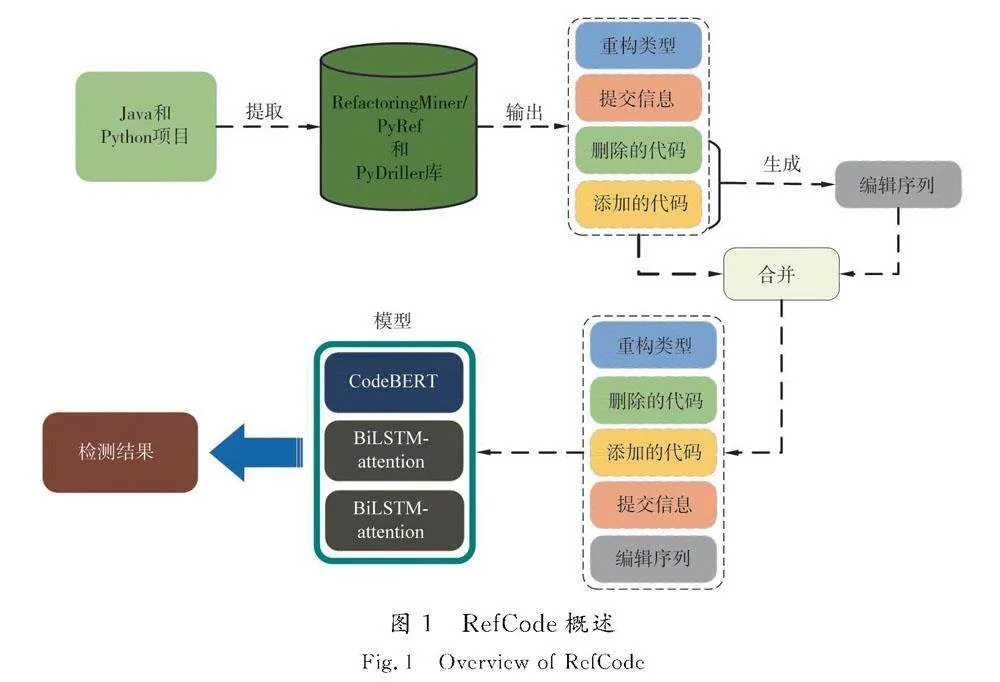
基于编辑序列的重构检测方法RefCode框架图如图1所示。首先,收集了110个Java和Python实际应用程序,从源程序中提取提交信息、重构类型等信息,并对重构检测实例进行数据预处理;然后根据代码变更信息生成编辑序列,将编辑序列与提交信息等数据相结合生成数据样本,以此作为深度学习模型的输入,其中代码变更信息作为CodeBERT模型的输入,提交信息和编辑序列分别作为2个BiLSTM-attention模型的输入,重构检测类型作为样本标签,模型的预期输出是样本的标签(即重构类型)。经过多次在训练集上训练,最终获取训练好的分类器,通过测试集评估分类器的性能,并给出重构检测结果。
1.1" 数据收集
为了在深度学习模型中实现跨语言的重构检测,关键是要收集来自多种编程语言的数据集。首先,需要选择并克隆托管在GitHub上的开源项目。Java项目是从文献[27]提供的项目列表中随机选择的,而Python项目则来自文献[28]。随机选择项目之后,优先克隆包含大量提交消息的项目。最终,收集了GitHub中的60个开源Java项目和50个开源Python项目作为实验的数据集。
对于Java数据集,使用RMINER重构检测工具从Java项目中提取数据。该工具采用基于AST的语句匹配算法来检测重构,可以获得提交ID、重构操作类型以及重构前后的代码块的起始行号。考虑到一个文件中可能存在多个代码更改,首先获取与重构类型对应的代码块的起始行号,以便精确定位更改的代码块。然后,使用PyDriller[29]获取与每个提交ID关联的提交消息和与起始行号对应的代码块。PyDriller是一个帮助开发人员解析Git仓库的Python框架。Python数据集的收集过程与Java数据集相似,但选择的重构检测工具是PyRef [30]。目前,这个重构检测工具只识别5种重构类型,如添加参数和重命名方法。因此,Java数据集中的重构类型也被过滤以选择相应的5种类型。
为了提高模型的精确度,数据预处理是必不可少的。收集的提交信息包含无关的信息,如评论和特殊字符。此外,更改前后的代码包含单行或多行注释。为了减少数据中的噪声,使用正则表达式过滤掉这些评论、特殊字符和其他冗余信息。
样本数据包含提交消息、重构前后的代码块、编辑序列,以及作为分类标签的重构类型,其他数据作为模型的输入。最终,收集了21 393个样本,其中包括
17 115个Java样本和4 278个Python样本。
为了确保数据的准确性,需要进一步校对数据。首先,使用PyDriller中的change_type参数与重构类型进行比对。change_type表示更改的类型,包括添加、删除、修改和重命名。然后,手动验证与重构类型不匹配的样本。
1.2" 编辑序列
编辑序列(edit sequence)[31-32]是一种在计算机科学和生物信息学中广泛使用的概念,主要用于度量2个字符串之间的相似性。编辑序列是一系列操作,通过这些操作可以将一个字符串转换为另一个字符串。
在本文中,删除和添加的代码是被转换的2个字符串,它们被视为2个令牌序列。为了构建编辑序列,将基于Levenshtein距离[33]的确定性差异算法应用于2个令牌序列。编辑序列的对齐方式如图2所示,图中包含3个序列。序列①是表示令牌发生的操作,它使用各种特殊符号标记发生更改的操作:
替换()、添加(+)、删除(-)和未更改(=)。序号②是更改前的令牌序列,序号③是更改后的令牌序列。在发生添加或修改操作时,使用填充符号()保证序列长度的一致。3个序列的长度相同,每一列都相互对应,当第2行的令牌和第3行的令牌相同时,第1行使用“=”表示未更改操作;当第2行和第3行的令牌不同时,第1行使用“”表示替换操作;当第2行有令牌,但是第3行没有令牌时,第1行使用“-”表示删除操作;当第2行没有令牌,但是第3行有令牌时,第1行使用“+”表示添加操作。
本文的方法采用编辑序列从代码变更信息中获取代码重构所对应的修改,由于CodeBERT预训练模型是在不同编程语言的数据集中进行训练,所以本文采用CodeBERT预训练模型从不同编程语言的代码变更信息中提取语义特征,采用BiLSTM从特殊符号标记中提取代码变更的结构特征,最后结合2种特征对重构类型进行检测。
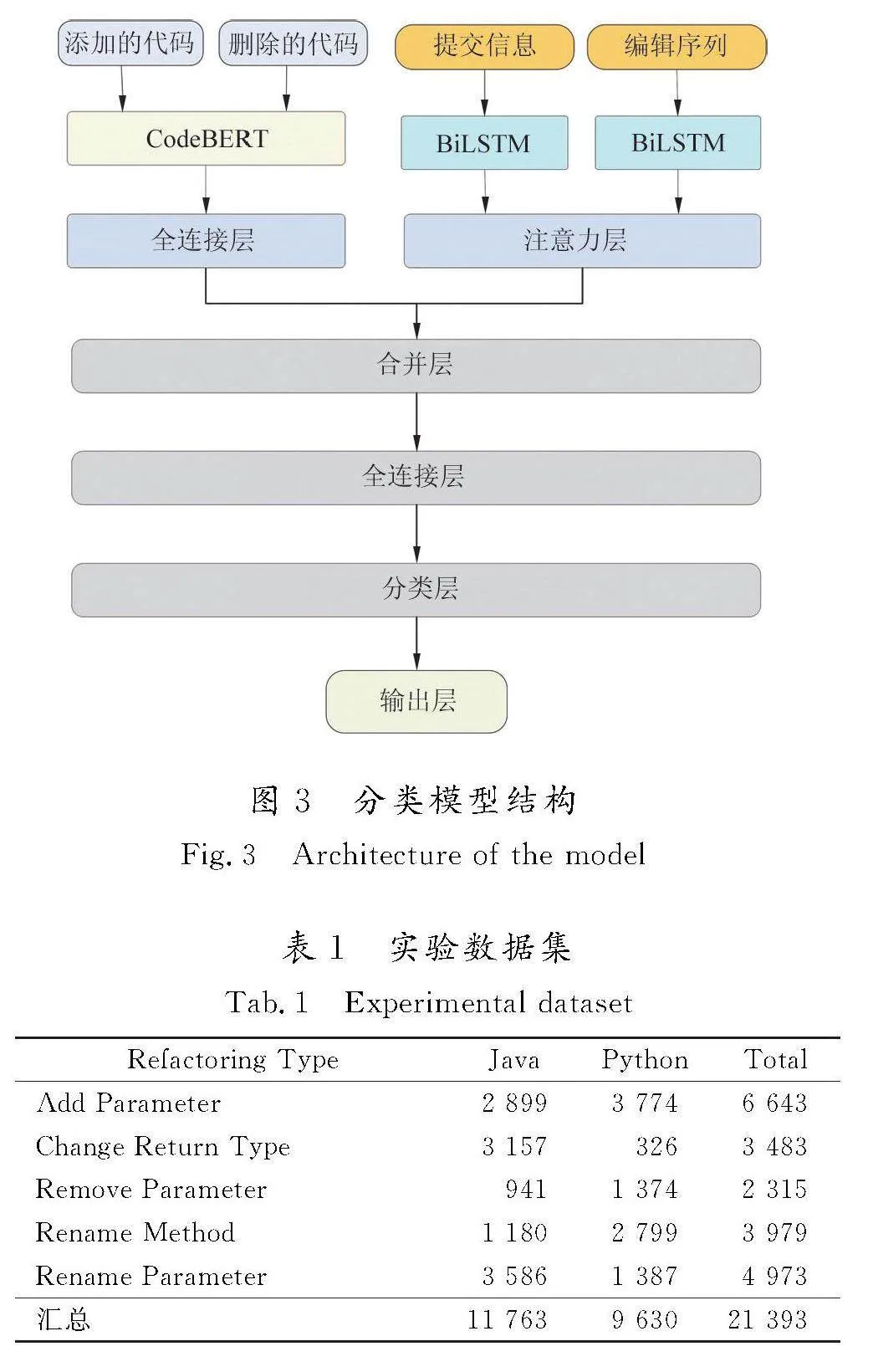
1.3" 分类模型结构
为了实现跨语言重构检测,本文将重构检测作为多分类任务,提出了一个将CodeBERT和BiLSTM-attention相结合的分类器模型。
分类模型的总体结构如图3所示,包含CodeBERT预训练模型和BiLSTM-attention模型2个部分。在第1部分中,将代码变更信息作为输入信息,通过CodeBERT预训练模型将代码变更信息编码为词向量,并且通过CodeBERT中的多层双向Transformer网络和self-attention机制获取代码变更信息中的语义信息。在第2部分中,
将提交信息和编辑序列均视为文本信息,作为BiLSTM模型的输入。通过BiLSTM模型对文本信息进行编码,使用 attention机制计算特征信息对重构操作的重要程度,增加对预测结果重要信息的关注。
输入的数据经过CodeBERT模型处理,使用一个全连接层对CodeBERT模型的输出进行一个维度的转换,然后将输出的文本特征表示和代码特征表示通过合并层(merge layer)进行拼接,最后通过一个全连接层和分类层输出结果。
2" 实" 验
使用Ubuntu 20.04.2操作系统,且安装了Python 3.7和PyTorch1.10作为深度学习运行环境。
2.1" 实验数据
为了评估模型的性能,对数据集进行划分。首先,将Java数据集和Python数据集分别按照8∶2的比例划分为训练集和
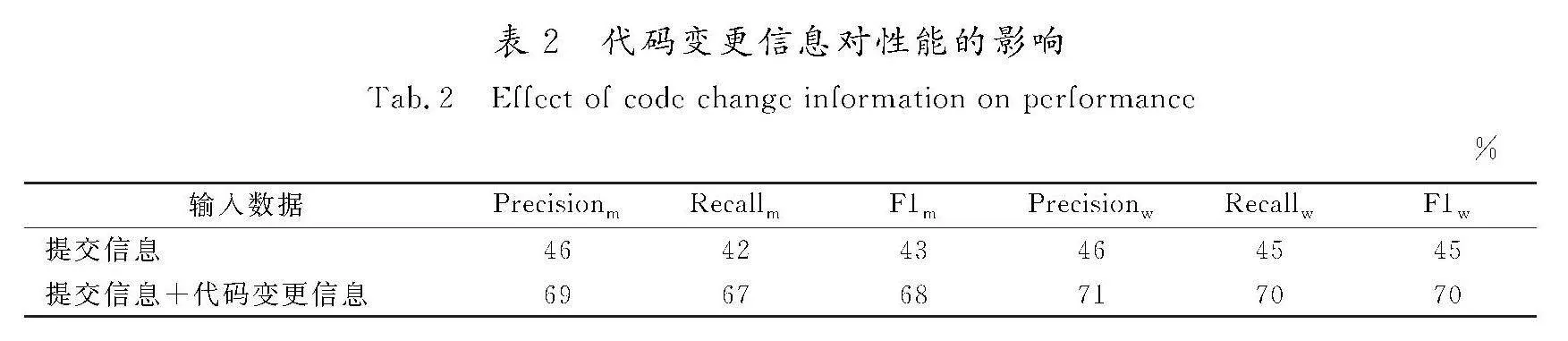
测试集,然后将Java训练集和Python训练集组成混合训练集,再将Java测试集和Python测试集混合形成新的混合测试集。最终数据集由混合数据集(混合训练集、混合测试集)、Java测试集和Python测试集组成,数据集的具体分布如表1所示,表中展示了每种重构类型在整体数据集中的分布。
2.2" 研究问题
通过回答以下研究问题(RQ)来评估RefCode方法的有效性:
RQ1 "RefCode在不同的编程语言中重构检测的性能如何?
RQ2" 代码变更信息能否有效提升重构检测的性能?
RQ3" 编辑序列能否有效提升模型的性能?
RQ4" 与现有工作相比,RefCode性能如何?
RQ5" 与其他机器学习模型相比,RefCode模型的性能如何?
RQ6" 与其他深度学习模型相比,RefCode模型的性能如何?
2.3" 评估指标
实验使用精确度、召回率和F1分数作为评估每种重构类型的指标。为了评估方法的整体性能,采用了宏平均和加权平均2种测量方法。
精确度、召回率和F1分数是评价分类性能的关键指标,见式(1)—(3)。
Precision=TPTP+FP" ,(1)
Recall=TPTP+FN" ,(2)
F1=2×Precision×RecallPrecision+Recall" 。(3)
宏平均是所有类别的精确度、召回率和F1分数的算术平均值,见式(4)—(6)。
Precisionm=1n∑ni=1Precisioni ,(4)
Recallm=1n∑ni=1Recalli ,(5)
F1m=1n∑ni=1F1i ,(6)
式中:n表示所有类的类别数量;Precisioni是第i个类的精确度;Recalli是第i个类的召回率;F1i是第i个类的F1分数。
另一方面,加权平均是每个类别的精确度、召回率和F1分数的加权平均值,其中的权重是基于数据集中每个类别的支持度而定,见式(7)—式(9)。
Precisionw=∑ni=1Supporti×Precisioni
∑ni=1Supporti" ,(7)
Recallw=∑ni=1Supporti×Recalli∑ni=1Supporti" ,(8)
F1w=∑ni=1Supporti×F1i∑ni=1Supporti" ,(9)
式中Supporti是第i个类在数据集中的样本数量。
2.4" 实验结果与分析
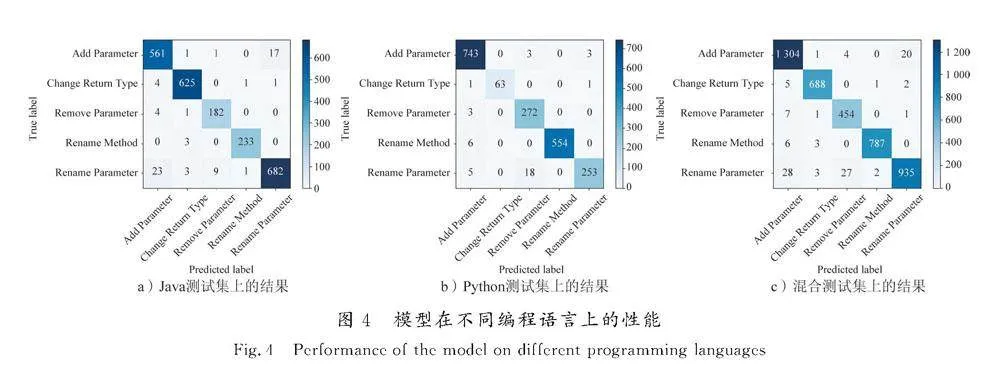
2.4.1" RQ1的结果
为了回答RQ1,将RefCode分别在Java测试集、Python测试集和混合测试集上进行评估。 图4展示了RefCode在3个测试集上的实验结果。图中将实际标签和预测标签组合在一起,结果是一个5×5的混淆矩阵。矩阵的行代表真实类别,而列代表模型的预测结果。图中对角线上的数字表示模型预测正确的数量,而其他位置的数字表示模型预测错误的数量。颜色的深浅表示数量的多少,数量越多,颜色就越深。
图4 a)展示了模型在Java测试集上的实验结果。图中5种重构类型分类正确的数量都集中在混淆矩阵的对角线上,且颜色较深,表明RefCode能够准确检测Java项目中的5种重构类型。图4 b)展示了模型在Python测试集上的实验结果。图中5种重构类型分类正确的数量也集中在对角线上,虽然Python测试集的数据不平衡,特别是Change Return Type重构类型的样本数量相对较少,但RefCode预测错误的样本数量只有2个,表明RefCode在不平衡的Python测试集中仍然能够准确检测5种重构类型。图4 c)展示了模型在混合测试集上的测试结果。图中5种重构类型分类正确的数量也都集中在对角线上,且颜色较深,其中Rename Parameter重构类型被预测错误的数量相对较多,但该类的样本数量偏多,所以准确率依然达到了90%以上。实验结果表明,RefCode能够准确检测2种编程语言项目中的5种重构类型。
2.4.2" RQ2的结果
为了回答RQ2,本文在混合测试集上评估添加代码变更信息前后的表现差异。为确保实验结果的公正性,展示性能提升确实源于代码变更信息的加入而非由于使用了更高级的模型,本文对代码变更信息采用了与处理提交信息相同的LSTM模型进行实验。
实验结果见表2。由表可知,在仅依赖提交信息进行重构检测的条件下,可以观察到宏平均的精确度、召回率和F1分数分别为46%、42%和43%,而加权平均的这3个指标分别为46%、45%和45%。这一结果揭示了在未引入代码变更信息时,重构检测的性能相对较低,尤其是在加权平均的F1分数上,性能明显不足。然而,将代码变更信息纳入考量后,重构检测的性能得到了显著提升。具体来说,宏平均的精确度、召回率和F1分数分别提升到了69%、67%和68%,而加权平均的这3个指标分别提升到了71%、70%和70%。这表明代码变更信息对于提高重构检测的准确性具有关键性的作用。
实验结果表明,引入代码变更信息能够有效地提高重构检测的性能。这种性能的提高很可能源自于代码变更信息对上下文和细节的丰富补充,这为模型识别和定位与重构相关的特征提供了更多的信息支持。
2.4.3" RQ3的结果
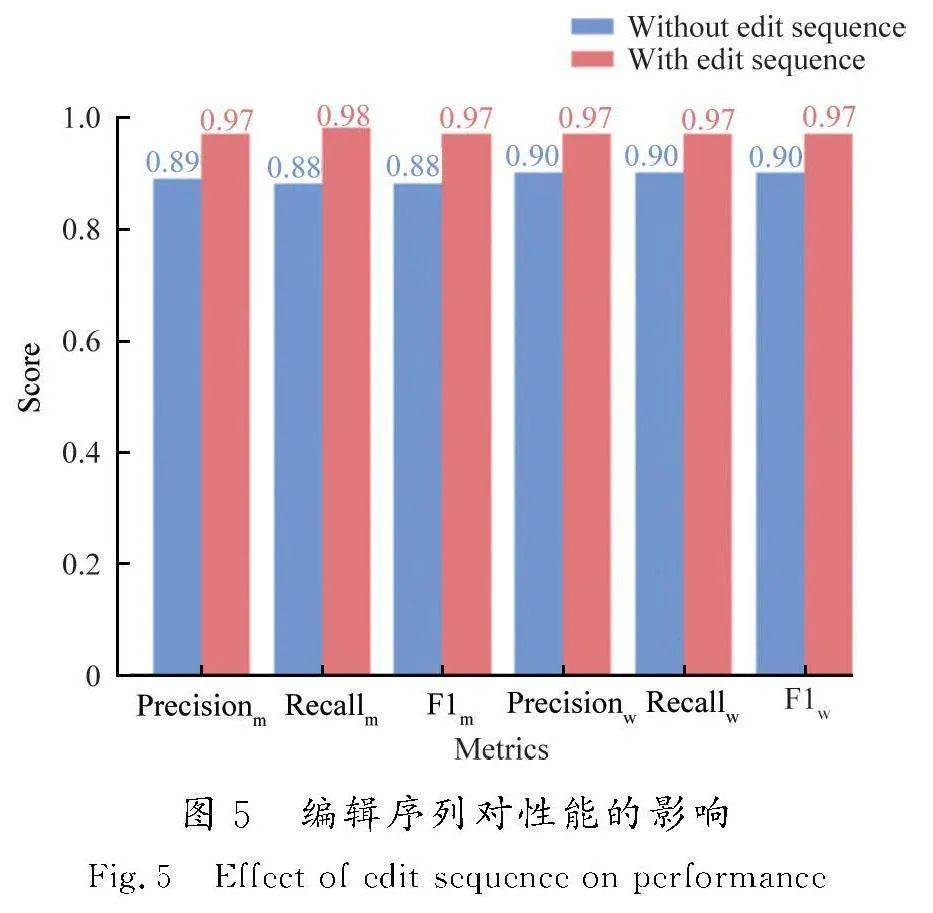
为了回答RQ3,构建了包含编辑序列和不包含编辑序列的2个数据集。
图5为RefCode模型在2种数据集上的对比。相较于不包含编辑序列的数据集,RefCode 在使用包含编辑序列的数据集之后,宏精确度、宏召回率和宏F1分数分别提升了8个百分点、10个百分点和9个百分点,而且加权精确度、加权召回率和加权F1分数均提升了7个百分点。
从实验结果可以看出,采用编辑序列之后,模型的性能有了明显的提高,说明编辑序列能够有效地构建代码变更的分布式表示,帮助模型学习到更好的代码特征,从而提高模型的精度。
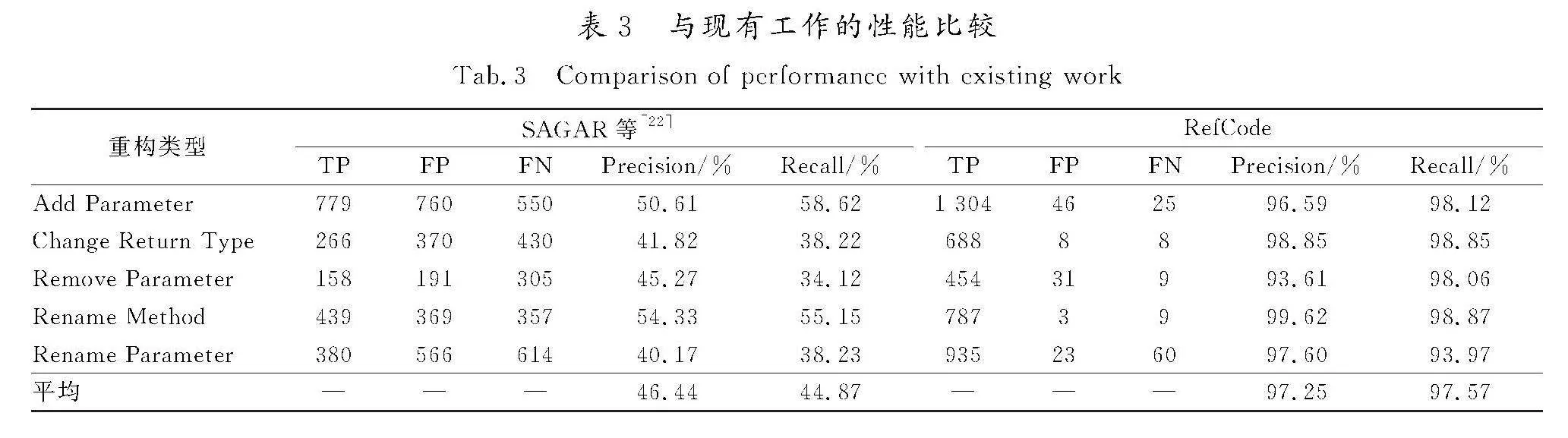
2.4.4" RQ4的结果
为了回答RQ4,将RefCode模型与SAGAR等[22]提出的重构检测方法进行比较,后者使用提交信息作为输入并采用了LSTM模型。表3显示了2种方法在混合测试集上检测5种重构类型的性能比较。总体来说,RefCode的精确度和召回率均分别为97.25%和97.57%,而SAGAR等的方法的精确度为46.44%,召回率为44.87%。性能在不同的重构类型间也有所变化,例如,RefCode检测Remove Parameter的精确度为93.61%,是所有重构类型中最低的,而检测Rename Parameter的召回率相对较低,仅为93.97%。相比之下,SAGAR等的方法在检测Rename Parameter时精确度最低(40.17%),在检测Remove Parameter时召回率最低(34.12%)。
从实验结果来看,RefCode在5种重构类型的平均精度和召回率上均提高了约50个百分点。这可能是因为SAGAR等仅使用提交信息作为输入,提取的特征不足或不可靠,而添加代码变更信息能够提取到更有价值和可靠的特征,显著提高了预测的精度。
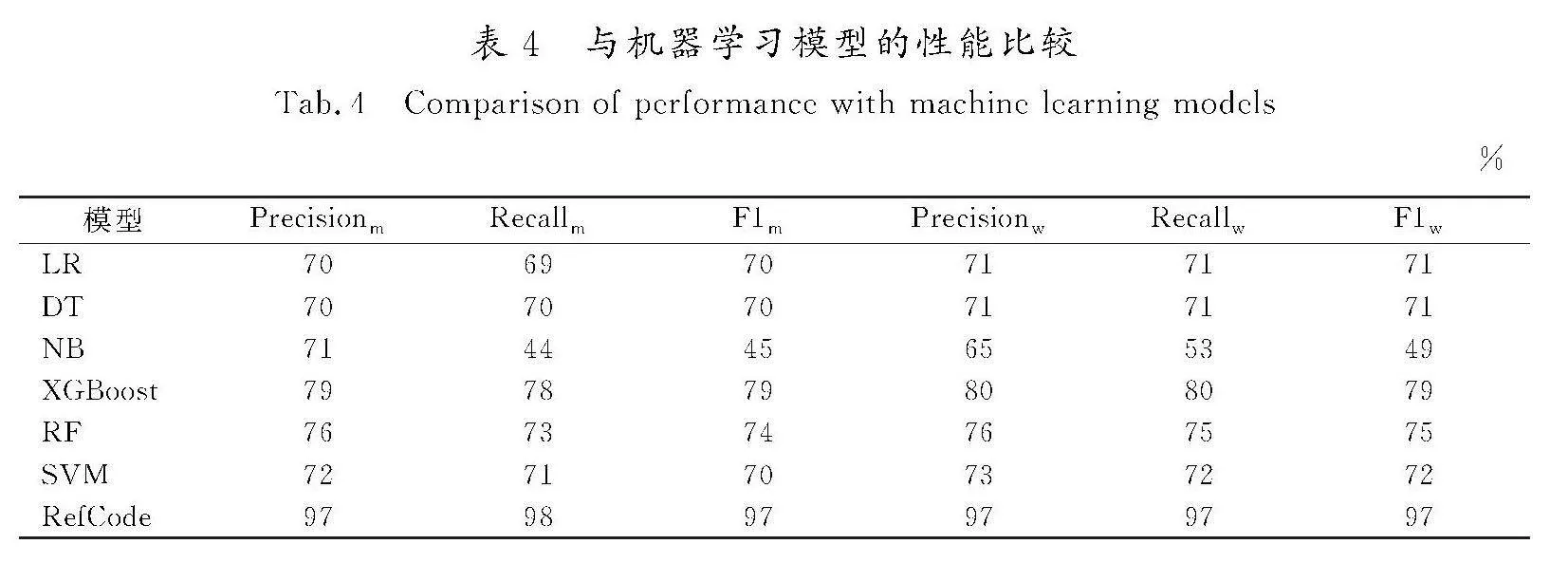
2.4.5" RQ5的结果
为了回答 RQ5,将RefCode模型与6种机器学习模型(支持向量机(SVM)[34]、随机森林(RF)[35]、朴素贝叶斯(NB)[36]、决策树(DT)[37]、逻辑回归(LR)[38]和极端梯度提升树(XGBoost)[39])进行比较,所有的模型都使用混合数据集进行训练和测试。表4展示了与机器学习模型对比的结果。所有的机器学习模型中 XGBoost 的各方面的表现都是最好的,但是RefCode的准确率比 XGBoost 高17个百分点,在宏精确度、宏召回率、宏F1分数、加权精确度、加权召回率和加权F1分数上,RefCode比XGBoost 提高了17~20个百分点,原因可能是RefCode使用了CodeBERT预训练模型,CodeBERT利用大规模预训练和Transformer等高效的神经网络框架,使其能够有效地捕捉代码中的语义和结构信息,而且CodeBERT使用的预训练数据集包含多种编程语言。朴素贝叶斯除了宏精确率之外,准确率和其他指标都是最低的;RefCode比NB的准确率高44个百分点,宏精确率、宏召回率和宏F1分数分别比NB高26、54和52个百分点,加权精确率、加权召回率和加权F1分数分别比NB高32、44和48个百分点。NB的整体性能明显低于其他模型,可能原因是NB分类器的性能受到特征独立性假设、不平衡数据、难以捕捉代码上下文信息等因素的影响。实验结果表明,在处理代码数据和文本数据时,RefCode 检测重构类型的性能明显优于SVM、LR等机器学习方法。
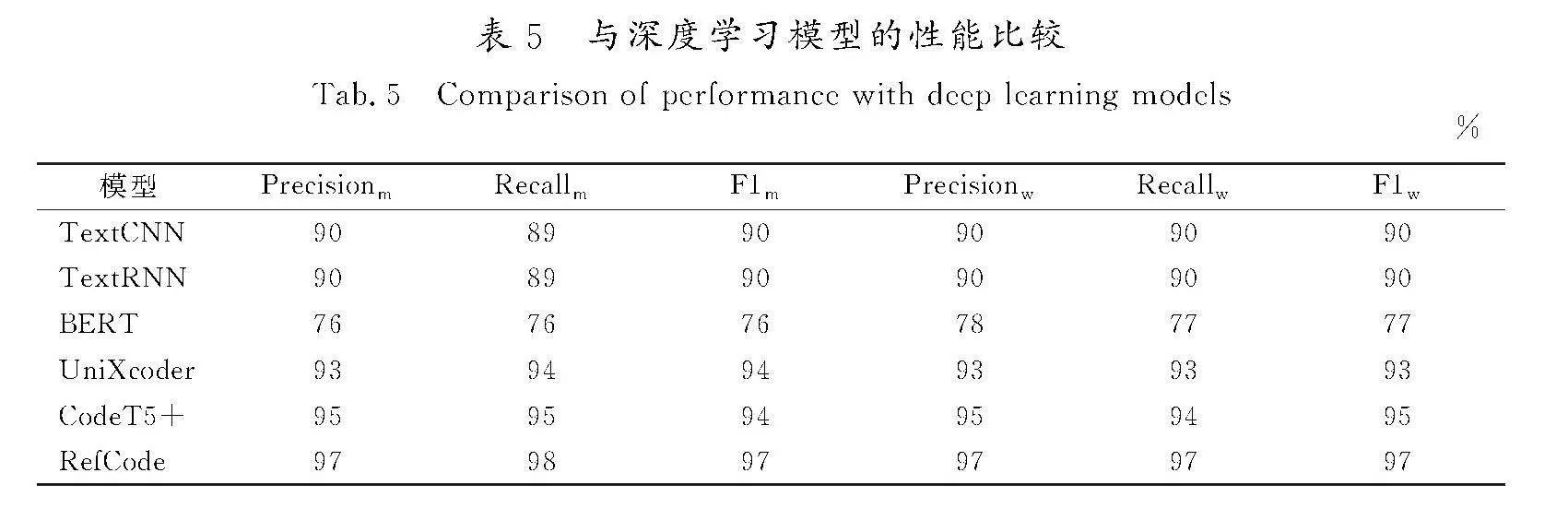
2.4.6" RQ6的结果
为了回答RQ6,将RefCode与几个深度学习模型进行比较,包括TextCNN[40]、TextRNN[41]、BERT预训练模型[42]、UniXcoder[43]和CodeT5+[44]。由于输入数据是多源文本数据,TextCNN和TextRNN都使用了多通道技术。所有模型都使用Java和Python的混合数据集进行训练和测试。
评估的结果如表5所示。传统的文本分类模型TextCNN和TextRNN在跨语言重构检测任务上展现了相似的性能,它们的宏平均和加权平均均达到了90%的水平。尽管这2个模型表现出了良好的性能,但它们没有专门针对代码数据进行优化。BERT模型作为一种广泛应用的预训练语言表示模型,在这一任务中的性能相对较低,宏平均和加权平均的精确度、召回率和F1分数均在76%~78%之间。这可能是因为BERT模型虽然在自然语言处理方面表现出色,但未针对代码结构和语义进行特别优化。相比之下,专门为处理代码信息设计的UniXcoder和CodeT5+模型在所有指标上都显示出了更高的性能。特别是CodeT5+模型,在宏平均和加权平均的精确度、召回率和F1分数上均超过了94%,这证明了这些专为代码设计的模型能够更好地理解和处理编程语言的特点。本文提出的RefCode模型在所有评估指标上均达到了97%,明显优于其他模型,这归功于该方法采用的CodeBERT模型结合了代码的结构和语义特征,并且利用了针对代码数据优化的tokenizer。这一结果不仅证实了RefCode模型在处理代码数据方面的高效性,也展现了其在跨语言重构检测任务上的潜力。
3" 结" 语
本文提出了一种基于编辑序列的跨语言重构检测方法,该方法添加了代码变更信息和代码编辑序列,并将CodeBERT预训练模型与BiLSTM-attention模型相结合,弥补了提交信息不可靠的缺陷,实现了跨语言重构检测,在2种编程语言的重构检测结果中都表现出较高的精确度和召回率。
本研究的数据集仅涵盖2种编程语言和5种重构操作类型,对其他编程语言和重构类型检测的精确度和召回率尚不明确。未来拟拓展至更广泛的编程语言和重构类型,并持续优化模型和方法,以提高检测性能。
参考文献/References:
[1]" ALMOGAHED
A,OMAR M,ZAKARIA N H.Recent studies on the effects of refactoring in software quality:challenges and open issues[C]//2022 2nd International Conference on Emerging Smart Technologies and Applications (eSmarTA).Ibb:IEEE,2022:1-7.
[2]" ALZAHRANI M.Extract class refactoring based on cohesion and coupling:A greedy approach[J].Computers,2022. DOI:10.3390/COMPUTERS11080123.
[3]" TAN L.Improving the Accuracy of Refactoring Detection[D].Marburg:Phillips University of Marlborough,2023.
[4]" SILVA D,SILVA J,SANTOS G,et al.RefDiff 2.0:A multi-language refactoring detection tool[J].IEEE Transactions on Software Engineering,2021,47(12):2786-2802.
[5]" TSANTALIS N,KETKAR A,DIG D.Refactoring Miner 2.0[J].IEEE Transactions on Software Engineering,2022,48(3):930-950.
[6]" 艾禄.基于深度学习的代码克隆检测技术的研究与实现[D].北京:北京邮电大学,2021.
AI Lu.Research and Implementation of Code Clone Detection Technology Based on Deep Learning[D].Beijing:Beijing University of Posts and Telecommunications,2021.
[7]" 王文杰,徐云.基于Token语义构建的代码克隆检测[J].计算机系统应用,2022,31(11):60-67.
WANG Wenjie,XU Yun.Code clone detection based on Token semantics[J].Computer Systems amp; Applications,2022,31(11):60-67.
[8]" 沈元,严寒冰,夏春和,等.一种基于深度学习的恶意代码克隆检测技术[J].北京航空航天大学学报,2022,48(2):282-290.
SHEN Yuan,YAN Hanbing,XIA Chunhe,et al.Malicious code clone detection technology based on deep learning[J].Journal of Beijing University of Aeronautics and Astronautics,2022,48(2):282-290.
[9]" 刘复星,魏金津,任女尔.基于深度学习的代码克隆检测技术研究[J].电脑知识与技术,2018,14(18):178-179.
[10]贲可荣,杨佳辉,张献,等.基于Transformer和卷积神经网络的代码克隆检测[J].郑州大学学报(工学版),2023,44(6):12-18.
BEN Kerong,YANG Jiahui,ZHANG Xian,et al.Code clone detection based on Transformer and convolutional neural network[J].Journal of Zhengzhou University(Engineering Science),2023,44(6):12-18.
[11]张杨,东春浩,刘辉,等.基于预训练模型和多层次信息的代码坏味检测方法[J].软件学报,2022,33(5):1551-1568.
ZHANG Yang,DONG Chunhao,LIU Hui,et al.Code smell detection approach based on pre-training model and multi-level information[J].Journal of Software,2022,33(5):1551-1568.
[12]卜依凡,刘辉,李光杰.一种基于深度学习的上帝类检测方法[J].软件学报,2019,30(5):1359-1374.
BU Yifan,LIU Hui,LI Guangjie.God class detection approach based on deep learning[J].Journal of Software,2019,30(5):1359-1374.
[13]王曙燕,张一权,孙家泽.基于BP神经网络的代码坏味检测[J].计算机工程,2020,46(10):216-222.
WANG Shuyan,ZHANG Yiquan,SUN Jiaze.Detection of bad smell in code based on BP neural network[J].Computer Engineering,2020,46(10):216-222.
[14]苏珊,张杨,张冬雯.基于深度学习的耦合度相关代码坏味检测方法[J].计算机应用,2022,42(6):1702-1707.
SU Shan,ZHANG Yang,ZHANG Dongwen.Coupling related code smell detection method based on deep learning[J].Journal of Computer Applications,2022,42(6):1702-1707.
[15]张玉臣,李亮辉,马辰阳,等.一种融合变量的日志异常检测方法[J].信息网络安全,2023,23(10):16-20.
ZHANG Yuchen,LI Lianghui,MA Chenyang,et al.A log anomaly detection method with variables[J].Netinfo Security,2023,23(10):16-20.
[16]尹春勇,张杨春.基于CNN和Bi-LSTM的无监督日志异常检测模型[J].计算机应用,2023,43(11):3510-3516.
YIN Chunyong,ZHANG Yangchun.Unsupervised log anomaly detection model based on CNN and Bi-LSTM[J].Journal of Computer Applications,2023,43(11):3510-3516.
[17]顾兆军,潘兰兰,刘春波,等.基于Venn-Abers预测器的系统日志异常检测方法[J].计算机应用与软件,2023,40(10):307-313.
GU Zhaojun,PAN Lanlan,LIU Chunbo,et al.An anomaly detection method for system logs based on Venn-Abers predictors[J].Computer Applications and Software,2023,40(10):307-313.
[18]陈丽琼,王璨,宋士龙.一种即时软件缺陷预测模型及其可解释性研究[J].小型微型计算机系统,2022,43(4):865-871.
CHEN Liqiong,WANG Can,SONG Shilong.Just-in-time software defect prediction model and its interpretability research[J].Journal of Chinese Computer Systems,2022,43(4):865-871.
[19]蔡亮,范元瑞,鄢萌,等.即时软件缺陷预测研究进展[J].软件学报,2019,30(5):1288-1307.
CAI Liang,FAN Yuanrui,YAN Meng,et al.Just-in-time software defect prediction:Literature review[J].Journal of Software,2019,30(5):1288-1307.
[20]KRASNIQI R,CLELAND-HUANG J.Enhancing source code refactoring detection with explanations from commit messages[C]//2020 IEEE 27th International Conference on Software Analysis,Evolution and Reengineering(SANER).London:IEEE,2020:512-516.
[21]TAN Liang,BOCKISCH C.Diff feature matching network in refactoring detection[C]//2022 29th Asia-Pacific Software Engineering Conference(APSEC).[S.l.]:IEEE,2022:199-208.
[22]SAGAR P S,ALOMAR E A,MKAOUER M W,et al.Comparing commit messages and source code metrics for the prediction refactoring activities[J].Algorithms,2021. DOI:10.3390/A14100289.
[23]MARMOLEJOS L,ALOMAR E A,MKAOUER M W,et al.On the use of textual feature extraction techniques to support the automated detection of refactoring documentation[J].Innovations in Systems and Software Engineering,2021,18:233-249.
[24]MURPHY H E,PARNIN C,BLACK A P.How we refactor,and how we know it[J].IEEE Transactions on Software Engineering,2012,38(1):5-18.
[25]FENG Zhangyin,GUO Daya,TANG Duyu,et al.CodeBERT:A pre-trained model for programming and natural languages[C/OL]//In Findings of the Association for Computational Linguistics:EMNLP 2020.[S.l.]:ACL,2020:1536-1547.
[26]YU Dongjin,WANG Lin,CHEN Xin,et al.Using BiLSTM with attention mechanism to automatically detect self-admitted technical debt[J].Frontiers of Computer Science,2021. DOI:10.1007/S11704-020-9281-Z.
[27]ANICHE M,MAZIERO E,DURELLI R,et al.The effectiveness of supervised machine learning algorithms in predicting software refactoring[J].IEEE Transactions on Software Engineering,2022,48(4):1432-1450.
[28]DILHARA M.Discovering repetitive code changes in ML systems[C]//Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.Athens:ACM,2021:1683-1685.
[29]SPADINI D,ANICHE M,BACCHELLI A.PyDriller:Python framework for mining software repositories[C]//proceedings of the Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.Lake Buena Vista:ACM,2018:908-911.
[30]ATWI H,LIN B,TSANTALIS N,et al.PYREF:Refactoring detection in python projects[C]//2021 IEEE 21st International Working Conference on Source Code Analysis and Manipulation (SCAM).Luxembourg:IEEE,2021:136-141.
[31]YIN P,NEUBIG G,ALLAMANIS M,et al.Learning to represent edits[DB/OL].(2019-02-22)[2023-12-01].https://arxiv.org/abs/1810.13337.
[32]PRAVILOV M,BOGOMOLOV E,GOLUBEV Y,et al.Unsupervised learning of general-purpose embeddings for code changes[C]//Proceedings of the Proceedings of the 5th International Workshop on Machine Learning Techniques for Software Quality Evolution.Athens:Association for Computing Machinery,2021:7-12.
[33]BEHARA K N S,BHASKAR A,CHUNG E.A novel approach for the structural comparison of origin-destination matrices:Levenshtein distance[J].Transportation Research Part C:Emerging Technologies,2020,111:513-530.
[34]PISNER D A,SCHNYER D M. Machine Learning:Methods and Applications to Brain Disorders[M].London:Elsevier,2020:101-121.
[35]SCHONLAU M,ZOU R Y.The random forest algorithm for statistical learning[J].The Stata Journal,2020,20(1):3-29.
[36]CHEN Shenglei,WEBB G I,LIU Linyuan,et al.A novel selective nave Bayes algorithm[J].Knowledge-Based Systems,2020. DOI:10.1016/j.knosys.2019.105361.
[37]CHARBUTY B,ABDULAZEEZ A.Classification based on decision tree algorithm for machine learning[J].Journal of Applied Science and Technology Trends,2021,2(1):20-28.
[38]ZOU Xiaonan,HU Yong,TIAN Zhewen,et al.Logistic regression model optimization and case analysis[C]//2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT).Dalian:IEEE,2019:135-139.
[39]WANG Chen,DENG Chengyuan,WANG Suzhen.Imbalance-XGBoost:Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost[J].Pattern Recognition Letters,2020,136:190-197.
[40]ALSHUBAILY I.Textcnn with attention for text classification[DB/OL].(2021-08-04)[2023-12-01].https://arxiv.org/abs/2108.01921.
[41]GUO Zixian,ZHU Ligu,HAN Lu.Research on short text classification based on RoBERTa-TextRCNN[C]//2021 International Conference on Computer Information Science and Artificial Intelligence (CISAI).Kunming:IEEE,2021:845-849.
[42]DEVLIN J,CHANG Mingwei,LEE K.Bert:Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Minneapolis:ACL,2019:4171-4186.
[43]GUO Daya,LU Shuai,DUAN Nan,et al.Unixcoder:Unified cross-modal pre-training for code representation[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.Dublin:ACL,2022:7212-7225.
[44]WANG Yue,LE Hong,AKHILESH G,et al.Codet5+:Open code large language models for code understanding and generation[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing.Singapore:ACL,2023:1069-1088.
