基于距离损失和决策边界的开放意图检测方法
2024-12-03张盼盼华宇勾智楠池云仙高凯

文章编号:1008-1542(2024)06-0618-09
摘" 要:
针对开放意图检测任务中对特征分布处理不足有可能导致所得特征分布不够紧凑的问题,提出一种融合BERT、距离损失、决策边界的开放意图检测方法。首先,通过BERT模型捕获文本间的上下文特征;然后,通过距离损失令样本特征学习更为紧密;最后,进行决策边界学习,实现开放意图检测任务。结果表明,所提方法在公开数据集StackOverflow上具有较好的表现,在2种不同的已知意图比例设置下表现均为最好,准确率达到88.28%和84.43%,F1值达到87.51%和87.40%。研究结果补充了针对边界检测的特征表示再处理方法,
可为解决开放意图检测问题提供参考。
关键词:
自然语言处理;意图识别; 意图检测; 距离损失; 决策边界
中图分类号:TN391
文献标识码:A
DOI:10.7535/hbkd.2024yx06006
收稿日期:2024-01-04;修回日期:2024-09-15;责任编辑:冯民
基金项目:国家自然科学基金(61772075);
河北省自然科学基金(F202208006,F2023207003);河北省高等学校科学研究青年基金项目(QN2024196)
第一作者简介:
张盼盼(1998—)男,河北邯郸人,硕士研究生,主要从事自然语言处理及意图挖掘方面的研究。
通信作者:高凯,教授。E-mail:gaokai@hebust.edu.cn
池云仙,博士。E-mail:chiyunxian_hebtu@163.com
张盼盼,华宇,勾智楠,等.
基于距离损失和决策边界的开放意图检测方法
[J].河北科技大学学报,2024,45(6):618-626.
ZHANG Panpan, HUA Yu,GOU Zhinan,et al.
Open intent detection based on distance loss and decision boundary
[J].Journal of Hebei University of Science and Technology,2024,45(6):618-626.
Open intent detection based on distance loss and decision boundary
ZHANG Panpan1, HUA Yu1,GOU Zhinan2,CHI Yunxian1,GAO Kai1
(1.School of Information Science and Engineering, Hebei University of Science and Technology,
Shijiazhuang, Hebei 050018, China;
2.School of Management Science and Information Technology, Hebei University of Economics and Business,
Shijiazhuang, Hebei 050061, China)
Abstract:
In order to solve the problem that the feature distribution is not compact enough due to insufficient processing of feature distribution in open intent detection task, an open intent detection method integrating BERT, distance loss and decision boundary was proposed. Firstly, the context features between texts were captured by BERT model. Then, the learning of sample features was made more compact by distance loss. Finally, decision boundary learning was carried out to achieve the task of open intent detection. The results show that the proposed method has high performance on the public dataset StackOverflow, with the best performance under two different known intent ratio settings, achieving the accuracy of 88.28% and 84.43%, and the F1 values of 87.51% and 87.40%, respectively. The research results
complement the future representation reprocessing method for boundary detection,and can provide reference for open intent detection.
Keywords:
natural language processing; intent recognition; intent detection; distance loss; decision boundary
意图识别在自然语言理解中起着至关重要的作用。传统的意图识别任务属于封闭环境下的分类任务,而封闭环境下的意图类别均是模型在训练阶段接触过的,即后续的所有意图类别均会被识别为已知的意图类别。随着有监督分类方法的发展,传统的意图识别取得了很大的进展[1-2]。然而随着社交网络等新媒体的快速发展,不计其数的社交网络对话数据往往不再受限于封闭环境下的分类任务,传统封闭环境下的意图识别已经不能够满足任务需要[3],因此有必要进行开放意图检测。
开放意图检测是在保证封闭环境下已知意图识别质量的同时,还具备较好的开放意图检测能力。
最早的开放集问题是在计算机视觉任务中被探索[4],开放集识别的设置与开放意图检测任务最为接近,目的同样是识别已知类的同时拒绝未在训练集中出现的未知类,与之类似的还有开放领域适应任务[5]。然而开放集识别的设置可以使用未知类的数据进行参数调优。与之相比,开放意图检测任务中,
为贴近真实场景,在训练期间仅使用已知部分数据,对开放意图数据则完全不可见。依据已有工作[6-7],将开放的意图定义为第(n+1)类。该任务的目标是在将训练环境已知的n类意图准确识别的同时,能够检测出开放环境的第(n+1)类样本。
相关工作中,HENDRYCKS等[8]采用softmax概率作为置信度评分,通过设置统一的置信度分数阈值来进行开放类别检测,分数越低则越有可能超出开放边界;BENDALE等[9]对分类结果进行韦伯分布拟合,使用OpenMax层校准置信度分数;SHU等[10]使用多个sigmoid替代单个softmax作为分类函数,通过统计学计算得到各个类别的置信度阈值,但该方法经验性较强;LIN等[6]提出通过最大边距余弦损失学习深层次意图特征,使用局部离群因子方式来检测未知意图;ZHANG等[7]将意图特征表示看作高维空间坐标,通过自适应的球型决策边界为阈值,作为区分未知意图的依据;YAN等[11]和ZHANG等[12]
通过融合了类标签信息的高斯混合模型获取更合适的特征表示,采用局部离群因子方式来检测未知意图;ZHAN等[13]与CHENG等[14]通过数据增强的方式为(K+1)的分类器构造伪开放样本,在模型执行分类任务时将开放样本识别为开放类;ZHOU等[15]通过构造辅助模型存储历史样本,与新批次样本进行K近邻对比学习计算,提高同类别样本密度,通过离群因子检测方法检测开放样本;WU等[16]提出一种重新分配的对比学习方法和自适应的局部阈值机制来实现未知意图的检测。
虽然开放意图检测任务中已有部分优秀的工作,但针对已知意图训练表示的重视程度不足,大多仍为预训练搭配后处理方法进行未知意图检测,已知意图的类内凝聚程度不足以及类间样本接近容易出现混淆交叉等问题。受文献[6-7]启发,为了解决上述问题,本文提出基于距离损失和决策边界的开放意图检测算法(open intent detection based on distance loss and decision boundary, OID-DD)。首先,该方法在预训练结束后,通过采用类内平均距离损失的方式对已知意图特征分布进行再训练,使得类内样本向类心收缩,缩小封闭区域风险,进一步加强已知意图训练,得到特征表示的凝聚程度;其次,经过再训练后得到类内凝聚程度更高、类间混淆交叉较弱的特征分布后,通过对每个已知意图分布的边缘距离训练,将更为贴近已知意图边缘的类内距离决策边界作为阈值,以此来进行开放意图样本的检测,从而提升开放意图检测的效果。
1" 基于距离损失和决策边界的开放意图检测模型
1.1" 开放意图检测任务
任务定义:给定S=(s1,s2,…,sn)表示包含n个单词的源文本序列,其中si为文本的第i个单词。另外,Y=(y1,y2,…,ym)表示数据集共包含m个意图标签。开放意图检测任务过程中,根据预设的已知意图比例(known intent ratio, KIR)从m个意图标签中选出KIR×m个标签作为已知意图标签,并将对应样本作为训练样本,在训练结束后将所有标签对应数据集输入模型进行意图检测,即需要模型在对KIR×m个标签进行意图分类的同时,还需检测出模型训练阶段未曾见过的开放意图标签。
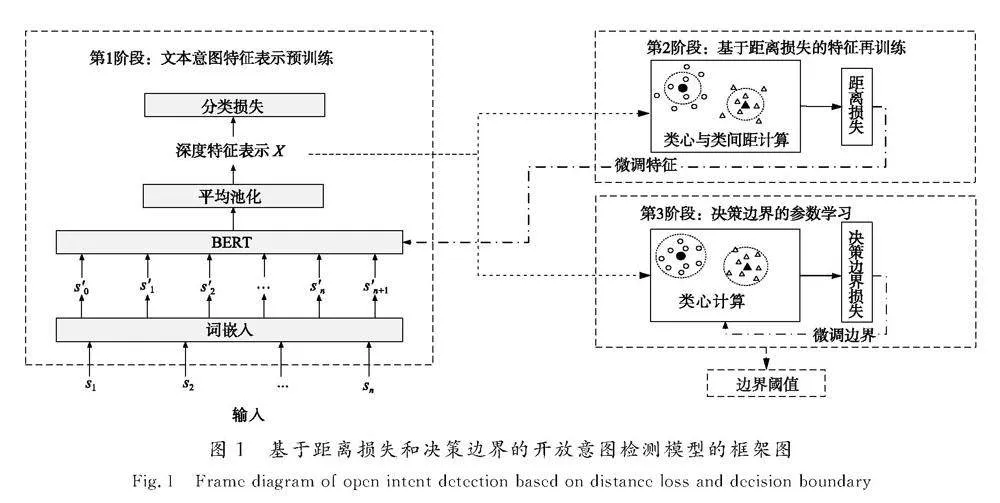
本文提出的OID-DD模型主要由文本意图特征表示预训练、基于距离损失的特征再训练、决策边界的参数学习3个阶段组成,如图1所示。第1阶段,文本意图特征表示预训练。利用文本编码器将每个文本S转换为一个文本表示S′,然后文本表示S′将由BERT模型[17]进行文本意图特征表示预训练,从而得到深度特征表示X。第2阶段,基于距离损失的特征再训练。将模型原本的分类层和预测层进行替换,转而使用每个意图标签的样本到类心的类
间距作为距离损失,进行文本特征表示二次训练,对深度特征表示X进行分布调整。第3阶段,决策边界的参数学习。固定文本编码器与BERT模型部分参数,转而对每个意图标签的距离边界进行训练学习,从而为每个意图标签得到最优的意图判断阈值,即决策边界。最后,固定模型所有参数,将所有样本输入模型,得到预测意图标签,并通过决策边界进行是否为已知意图的判断,从而完成开放意图检测任务。
1.2" 文本意图特征表示预训练
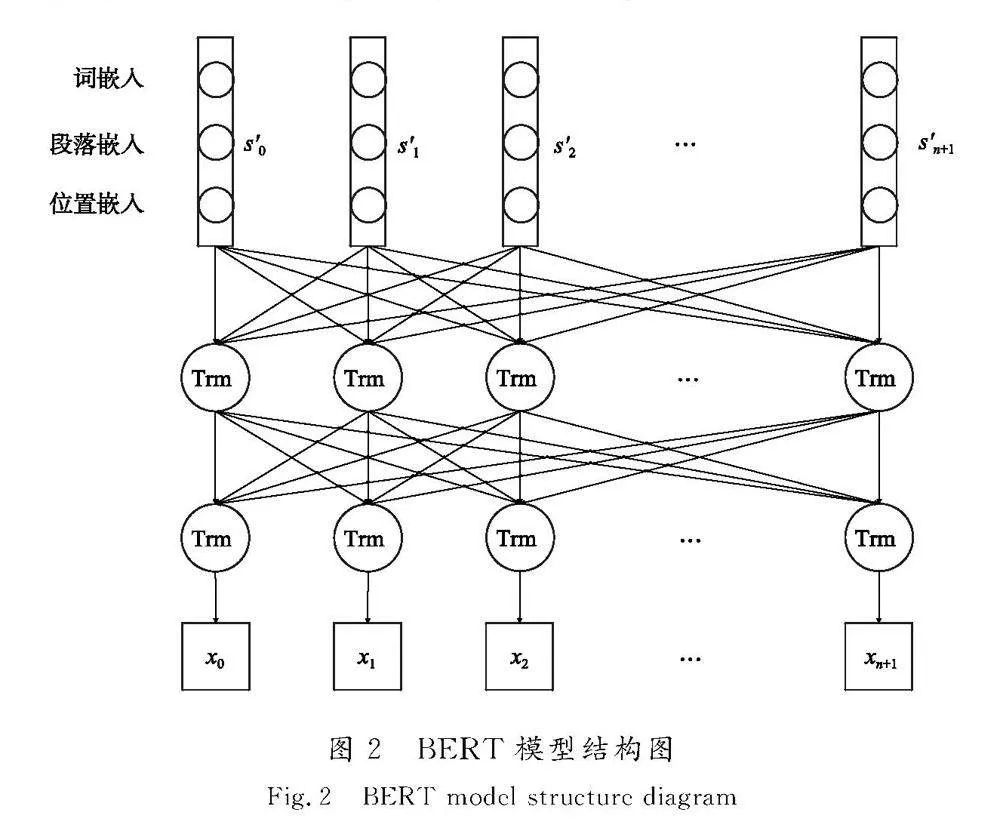
如图1所示,将BERT模型作为特征抽取器,将词嵌入表示输入BERT模型得到深度特征表示,采用交叉熵损失函数对模型进行预训练,BERT模型结构如图2所示。
给定S=(s1,s2,…,sn)表示长度为n的文本S,将S进行词嵌入处理后得到的文本表示S′=(s′0,s′1,s′2,…,s′n+1)用作BERT模型的输入,其中s′0和s′n+1分别代表文本开始字符[CLS]和结束字符[SEP],s′i由词嵌入、段落嵌入、位置嵌入构成。如图2所示,BERT模型的核心由12层Transformer Encoder组成。
X=(x0,x1,…,xn+1)为BERT编码层的输出,xi∈Rd是s′i的词特征向量,d是特征维度。经过池化、密集层操作后得到zi∈Rd,用作给定文本S的句特征向量。依据已有工作[7]的建议,池化阶段采用平均池化方法。
Z作为文本S的特征表示,经过线性分类器后得到分类结果Y′=(y1,y2,...,ym),其中yi(i=1,2,…,m)表示样本在对应类别上的置信度分数,m表示已知的意图种类数量。本阶段的损失函数LossCE如式(1)所示。
LossCE=-1N∑Ni=1iln yi ,(1)
式中:N为一批次的样本数量;yi为一批次中第i条样本对应的真实标签值;i为第i条样本的分类结果。
1.3" 基于距离损失的特征再训练
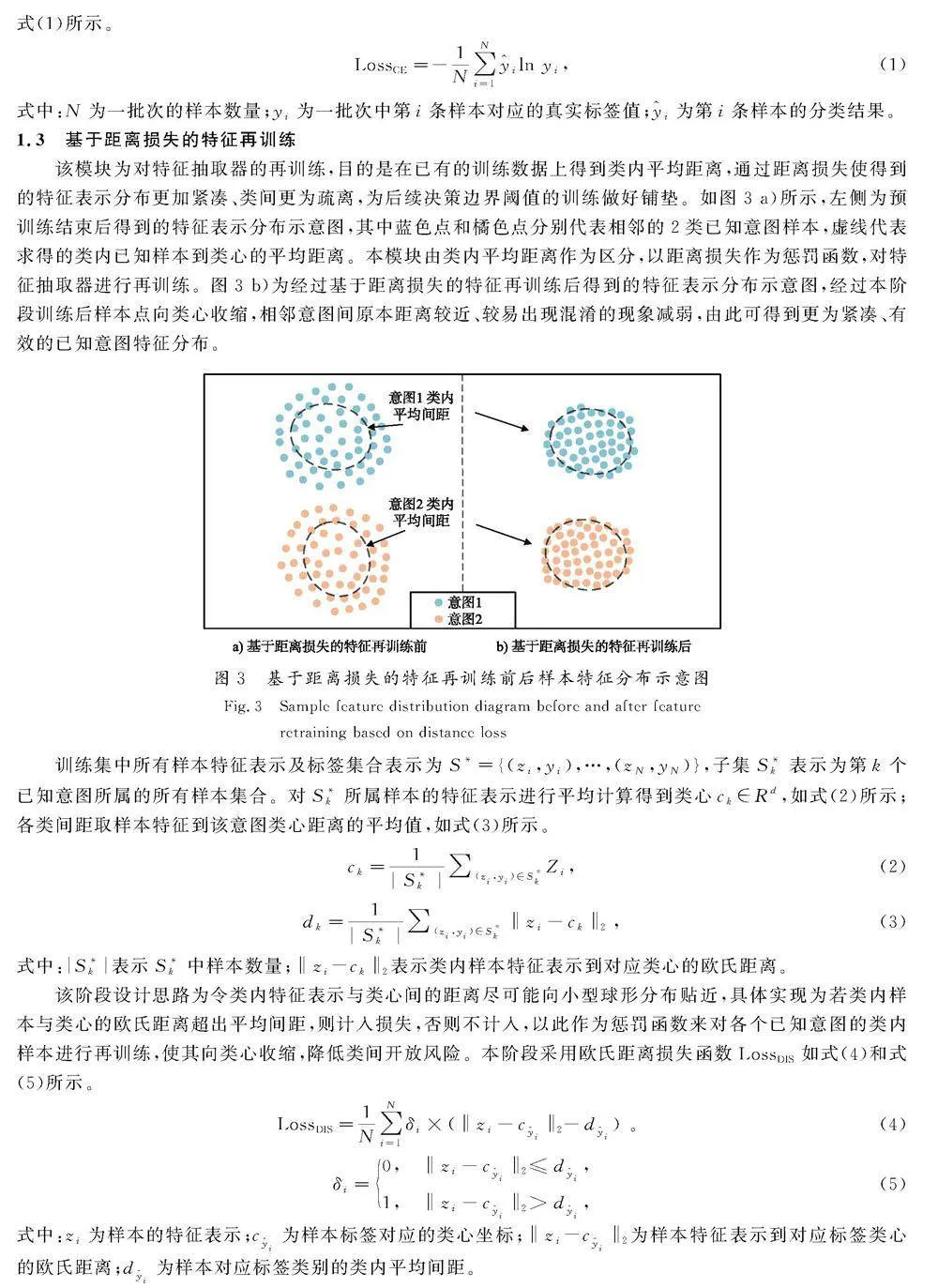
该模块为对特征抽取器的再训练,目的是在已有的训练数据上得到类内平均距离,通过距离损失使得到的特征表示分布更加紧凑、类间更为疏离,为后续决策边界阈值的训练做好铺垫。如图3 a)所示,左侧为预训练结束后得到的特征表示分布示意图,其中蓝色点和橘色点分别代表相邻的2类已知意图样本,虚线代表求得的类内已知样本到类心的平均距离。本模块由类内平均距离作为区分,以距离损失作为惩罚函数,对特征抽取器进行再训练。图3 b)为经过基于距离损失的特征再训练后得到的特征表示分布示意图,经过本阶段训练后样本点向类心收缩,相邻意图间原本距离较近、较易出现混淆的现象减弱,由此可得到更为紧凑、有效的已知意图特征分布。
训练集中所有样本特征表示及标签集合表示为S*={(zi,yi),…,(zN,yN)},子集S*k表示为第k个已知意图所属的所有样本集合。对S*k所属样本的特征表示进行平均计算得到类心ck∈Rd,如式(2)所示;各类间距取样本特征到该意图类心距离的平均值,如式(3)所示。
ck=1|S*k|∑(zi,yi)∈S*kZi ,(2)
dk=1|S*k|∑(zi,yi)∈S*k‖zi-ck‖2 ,(3)
式中:|S*k|表示S*k中样本数量;‖zi-ck‖2表示类内样本特征表示到对应类心的欧氏距离。
该阶段设计思路为令类内特征表示与类心间的距离尽可能向小型球形分布贴近,具体实现为若类内样本与类心的欧氏距离超出平均间距,则计入损失,否则不计入,以此作为惩罚函数来对各个已知意图的类内样本进行再训练,使其向类心收缩,降低类间开放风险。本阶段采用欧氏距离损失函数LossDIS如式(4)和式(5)所示。
LossDIS=1N∑Ni=1δi×(‖zi-ci‖2-di) 。(4)
δi=0," ‖zi-ci‖2≤di,
1," ‖zi-ci‖2gt;di,(5)
式中:zi为样本的特征表示;ci为样本标签对应的类心坐标;‖zi-ci‖2为样本特征表示到对应标签类心的欧氏距离;di为样本对应标签类别的类内平均间距。
1.4" 决策边界的参数学习
基于第2阶段的类间距过渡,对于第k个已知意图对应的样本集合S*k,定义约束边界Δk为第k个已知意图对应的决策边界,满足式(6)的约束。本阶段目的是针对每个已知的意图类别,得出合适的决策度量Δ。受文献[7]启发,本阶段采用度量损失函数LossBoundary,如式(7)所示。
Zi∈S*k," ‖zi-ck‖2≤Δk" ,(6)
LossBoundary=1N∑Ni=1[δi×(‖zi-ci‖2-Δi)+(1-δi)×(Δi-‖Zi-ci‖2)] ,(7)
式中Δi表示样本对应意图的决策距离。
1.5" 模型训练与使用
模型训练共分为3阶段:第1阶段为文本意图特征表示预训练,损失函数采用LossCE(见式(1)),该阶段目标为使加载的预训练模型在当前数据集上得到良好的分布;第2阶段为基于距离损失的特征再训练,损失函数采用LossDIS(见式(4)),该阶段目标为使特征抽取器得到的特征表示更加向类心聚集,使特征分布更加紧凑,便于第3阶段决策边界的参数学习;第3阶段为决策边界的参数学习,该阶段将类内距离参数化,损失函数采用LossBoundary(见式(7)),学习目标为合适的决策边界,以此来分割封闭区域与开放区域。OID-DD的训练流程如下。
输入:任务训练集Dk,Bert模型参数Pbert,样本类心参数Ck,距离参数Δ。
输出:Bert模型参数Pbert,样本类心参数Ck,距离参数Δ。
1:for i from 1 to epoch1 do
2: for" Xi∈Dk do
3: 通过交叉熵损失函数更新Bert模型参数Pbert ;
4: end for
5: end for
6: for i from 1 to epoch2 do
7: 初始化样本类心参数Ck、距离参数Δ;
8:for Xi∈Dk do
9: 通过距离损失函数更新Bert模型参数Pbert ;
10: end for
11: end for
12: 固定Bert模型参数Pbert;
13: for i from 1 to epoch3 do
14: for" Xi∈Dk do
15: 通过边界损失函数更新距离参数Δ;
16: end for
17: end for
18: return Pbert、Ck、Δ。
训练结束后,该方法使用每个已知意图类别的类心与学习到的决策边界对输入样本进行识别。对输入样本进行特征抽取后得到特征表示,将该特征表示与训练时得到的意图类心进行欧氏距离计算,取距离最近的为所属意图。此外,将得到的欧氏距离与学习得到的决策度量进行比较,若大于决策度量则当前样本将被识别为开放意图,如式(8)和式(9)所示。
ymin=argmink∈Y‖zi-ck‖2 ,(8)
ypred=
open," ‖zi-cymin‖2gt;Δymin,
ymin," ‖zi-cymin‖2≤Δymin,(9)
式中:ymin表示距离最近质心所属意图类别;ypred为模型最终预测结果。
2" 实验设计
2.1" 环境及参数设置
模型在一个GPU(NVIDIA GeForce RTX 3090, 24 GB)上训练。根据验证集上的评估选择结果最好的模型参数,并报告测试集上的结果。
参数方面,BERT模型使用BERT-Base的中文预训练模型进行实验。该模型有12层,隐藏层维度为768,注意力头数为12,包含110×106个参数,模型使用Adam作为优化器,epoch设置为100。训练过程中,前2阶段学习率设置为2×10-5,第3阶段学习率设置为0.02。
2.2" 实验测度
受已有研究[6-7]启发,本文将除已知意图外所有开放意图当作一个开放类,采用准确率(Accuracy)和F1值作为整体评价指标,并在已知意图和开放意图上分别计算F1值作为细粒度的性能指标,表示为F1-known和F1-open。
2.3" 基线模型
为了验证OID-DD模型在开放意图检测任务中的有效性,与以下经典的开放分类方法基线模型进行对比实验。
OpenMax[9]" 首先使用softmax损失在已知意图上训练分类器,然后对分类器的输出logits值进行Weibull分布拟合,最终使用OpenMax层校准置信度分数。
MSP[8]" 一个简单的基线模型,采用最大softmax值作为已知类的预测依据,并将0.5作为阈值来检测开放类。
DOC[10]" 通过高斯拟合计算每个已知类的不同概率阈值,以此识别开放类。
DeepUnk[6]" 首先利用边际损失学习深度特征,然后利用离群因子检测方法进行未知类检测。
ADB[7]" 基于已知的意图特征表示学习自适应决策边界,以此检测开放类。
KNNCL[16]" 利用K近邻的对比学习损失与交叉熵损失做权重加和得到总损失学习深度特征,使用离群因子检测方法进行未知类检测。
为统一验证模型效果,本文将所有基线方法的基础模型统一替换为BERT模型,其余部分保持不变。其中,计算机视觉的开放集检测方法OpenMax需要开放类样本对超参数进行校验,因此对于OpenMax方法本文采用默认超参数。
2.4" 主体实验
OID-DD模型中词嵌入与深度特征表示抽取为公共部分,3阶段中的前2阶段采用不同的损失函数进行训练,第3阶段固定公共部分模型参数,进行决策边界的阈值学习,模型训练完成后进行评测。
模型评估选用数据集StackOverflow。该数据集包含“oracle”、“matlab”、“spring”等20种类别,每种类别1 000个样本,共20 000个样本,其中训练集、验证集和测试集分别包含12 000、2 000和6 000个样本。
在OID-DD模型训练前对数据集StackOverflow重新进行划分,根据预设的已知意图比例KIR从m个意图标签中随机选出KIR×m个作为已知意图标签,并将对应样本作为训练样本,在训练结束后将所有标签对应的数据集输入模型进行意图检测,并利用准确率和F1值验证模型测试结果。
2.5" 对比验证实验
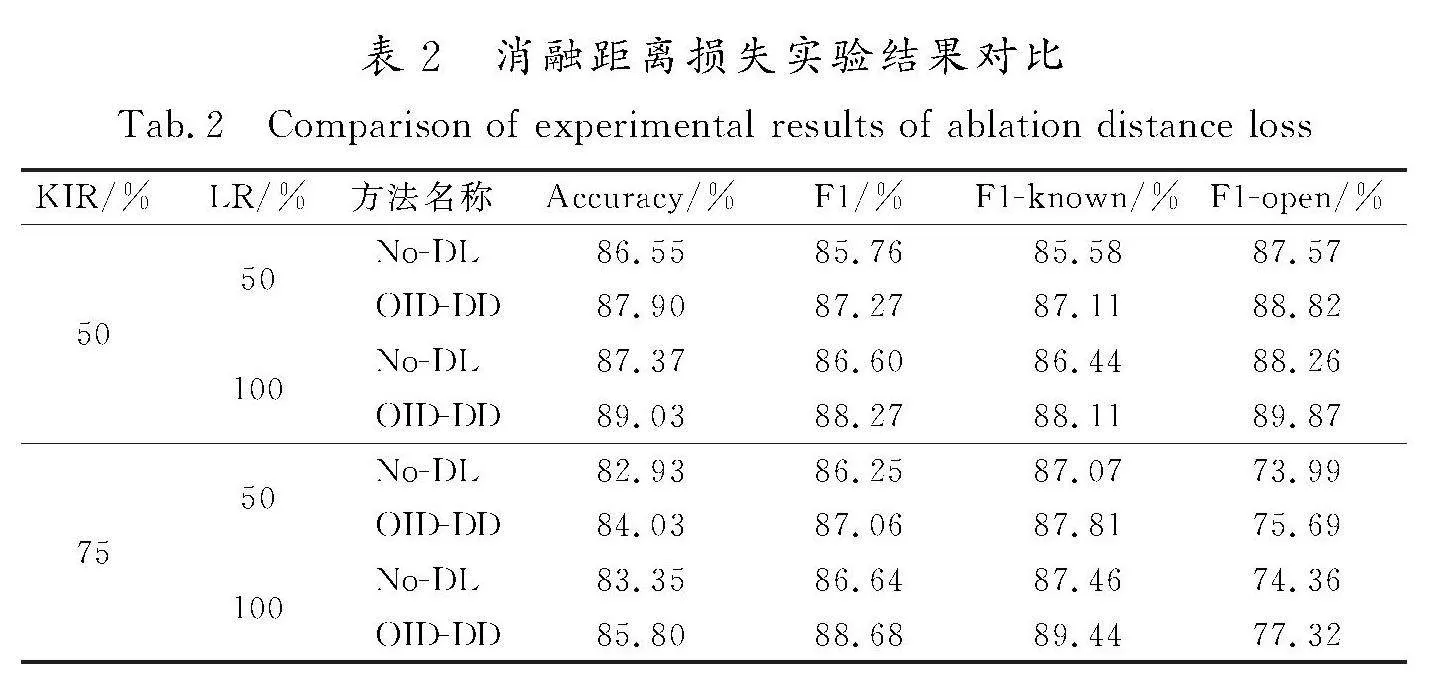
OID-DD模型采用3阶段方法,为证明其有效性,基于第1阶段文本特征表示预训练,在第2、第3阶段利用对比验证进行消融实验研究。
为验证距离损失特征再训练的影响,OID-DD模型先将第2阶段前后的特征表示进行降维处理,再利用二维图像进行显示,并给出有、无第2阶段参与的不同训练结果对比,加以验证。
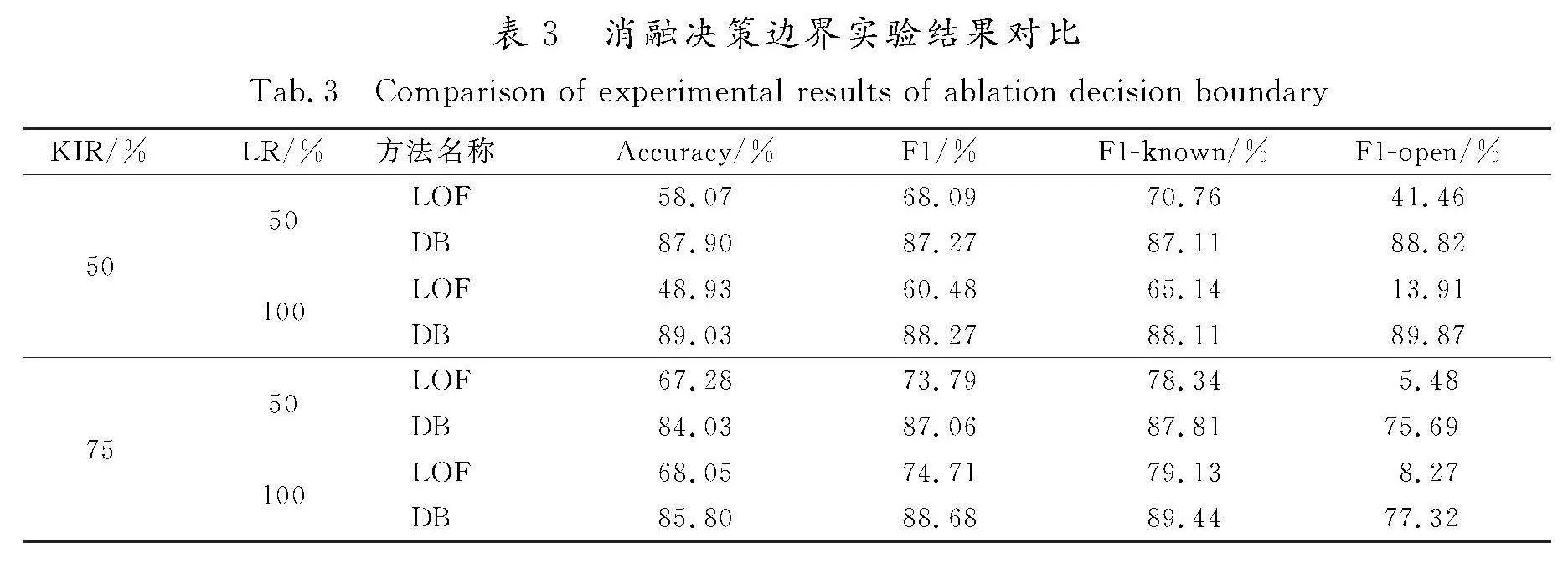
为验证决策边界方法的影响,OID-DD模型将第3阶段决策边界(decision boundary, DB)方法和局部离群因子检测(local outlier factor, LOF)方法进行比较,并整理结果,加以验证。
3" 实验结果与分析
3.1" 主体实验结果与分析
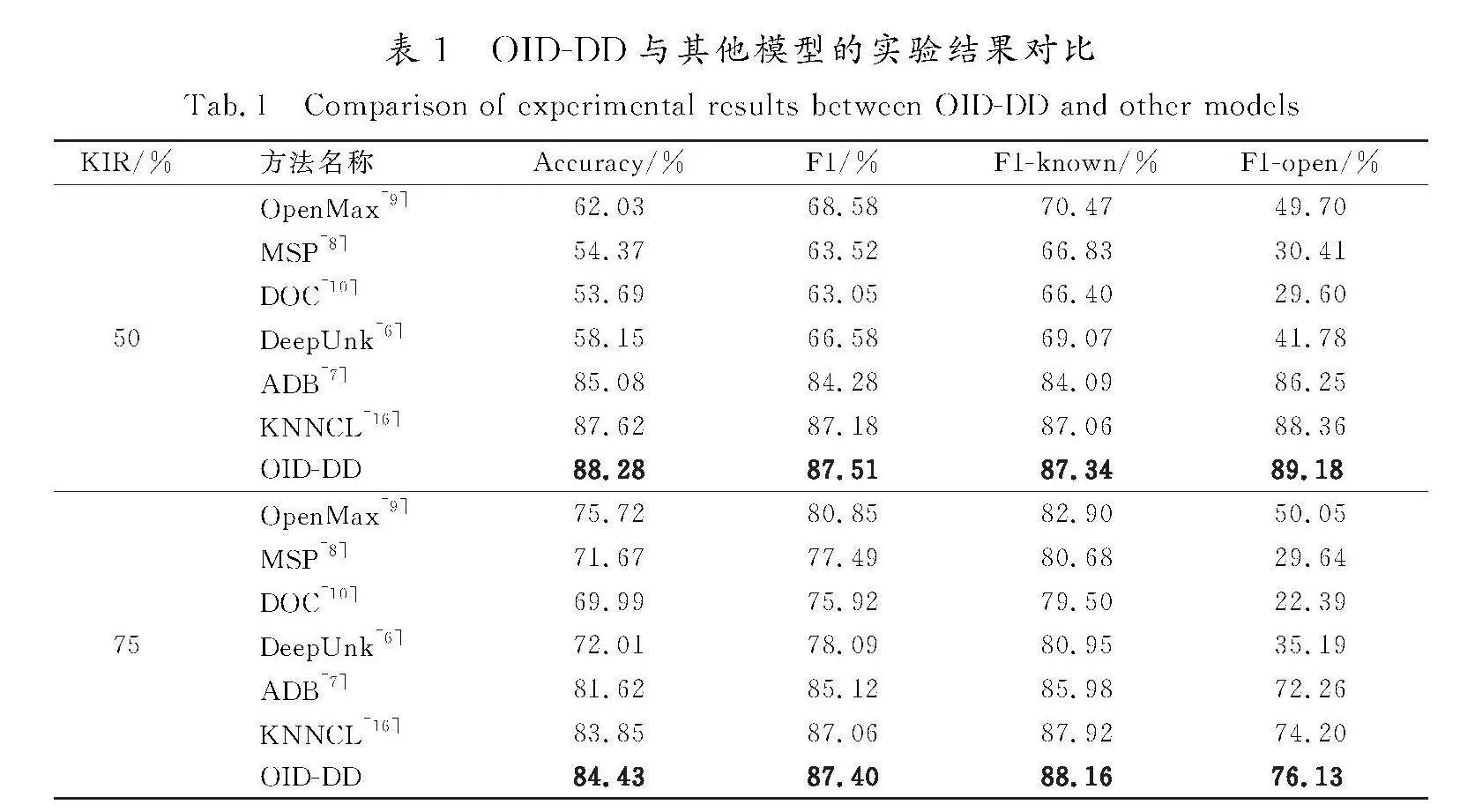
本文OID-DD模型与上述基线模型在StackOverflow数据集上进行实验对比。为全面对比模型效果,采用不同的已知意图比例(known intent ratio, KIR)设置进行实验,实验结果如表1所示。
由表1可以看出,本文提出的OID-DD在Accuracy、F1、F1-known以及F1-open 4个指标上的得分均明显优于其他模型。相对于已有模型ADB,KIR设置为50%时各项得分分别提升了3.20、3.23、3.25、2.93;KIR设置为75%时各项得分分别提升了2.81、2.28、2.18、3.87。而相对于KNNCL模型,KIR设置为50%时各项得分分别提升了0.66、0.33、0.28、0.82;KIR设置为75%时各项得分分别提升了0.58、0.34、0.24、1.93。本文方法相对于OpenMax、DeepUnk等方法,在各项评分上均有明显提升。以上结果表明本文所提方法能够有效地完成开放意图检测任务。
OID-DD模型在StackOverflow数据集上关于F1值和F1-known的分值提升较少,在Accuracy和F1-open上的得分提升较多。Accuracy表示模型的准确率,F1-open表示模型在未知意图检测上的综合表现,可以比较均衡地展现模型的精确率和召回率,Accuracy和F1-open分值越高,则代表模型的准确率、精确率和召回率越好,即表示模型在未知意图检测上综合表现更佳。而F1值和F1-known值相比较于已有模型虽然提升较少,但得分仍然高于已有模型,表示OID-DD模型在已知意图检测上的表现优于已有模型,证明本文所提方法在开放意图检测任务上的效果有整体提升。
3.2" 对比验证实验结果与分析
1)基于距离损失的特征再训练的影响
本文提出基于距离损失的意图特征再训练,目的是通过本文设计的距离损失令同一类别样本点向类心收缩,缩小类内样本间距,从而能够更好地进行意图识别,并且为开放意图样本的检测做好铺垫。
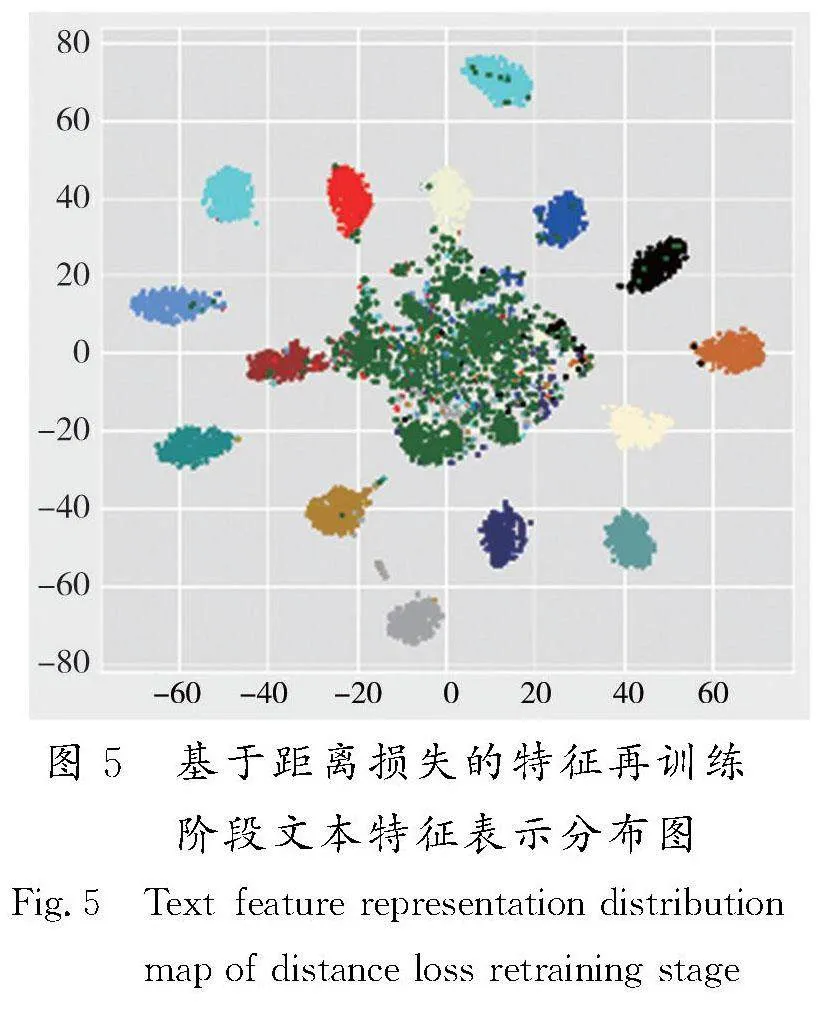
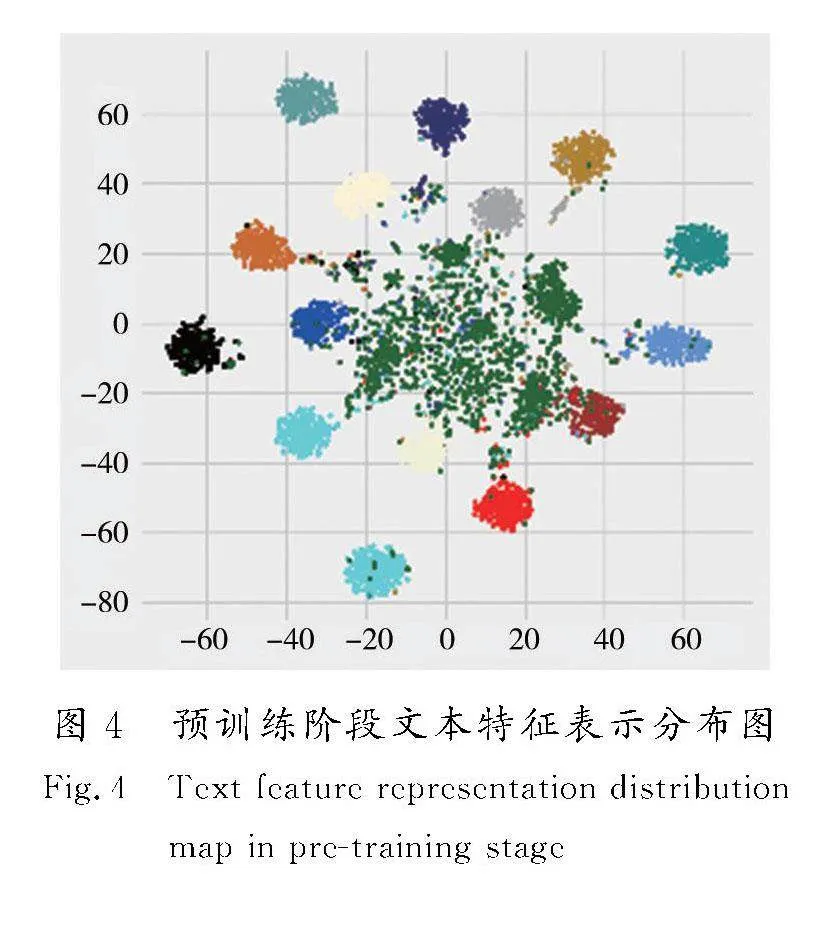
为了进一步验证基于距离损失的特征再训练模块的作用与影响,本文将第1阶段预训练结束后得到的文本意图特征表示分布与第2阶段基于距离损失的特征再训练后得到的高维特征表示分布进行降维显示,并给出有、无第2阶段参与的不同训练结果对比,加以验证。
第1阶段文本意图特征表示预训练后得到的特征表示如图4所示,图内特征不仅包含已知意图的表示,而且还有训练过程中没有接触过的未知意图表示,图内每一团簇即为一类已知意图,中心散点为未知意图表示。图内已知意图特征表示簇内收缩不够紧密,且部分已知意图与开放意图(中心绿色散点)分布距离较近,已经发生混淆。
图5为经过第2阶段基于距离损失的特征再训练后得到的特征表示分布,图内已知意图特征表示收缩较为紧密,且与开放意图(中心绿色散点)分布距离适中,混淆现象较弱。
对比实验采用不同的KIR和标注比例(labeled ratio, LR)设置进行实验,其中OID-DD表示有第2阶段参与,No-DL表示无第2阶段参与,随机种子值设置为0,实验结果如表2所示。
由图4、图5对比可知,经过基于距离损失的特征再训练后得到的已知意图特征表示类内更加紧密,经过再训练后得到的已知意图特征表示与未知意图特征表示区分度更高。
由表2对比可知,相较于无第2阶段基于距离损失的特征再训练的实验,OID-DD模型在4组不同的已知意图比例和标注比例下表现俱佳,拥有最优的Accuracy和F1值,说明OID-DD模型中基于距离损失的特征再训练模块提高了模型对已知意图和未知意图的分辨能力,有利于开放意图检测。
2) 决策边界方法的影响
为了验证决策边界方法的有效性,将第1阶段文本意图特征表示预训练与第2阶段基于距离损失的特征再训练后得到的高维特征表示作为基础特征,对比决策边界方法和局部离群因子检测方法,实验结果如表3所示。
由表3可知,与基于密度的局部离群因子检测方法相比,决策边界在4组不同的已知意图比例和标注比例下表现俱佳,拥有最优的Accuracy和F1值。
结合图5可知,中心区域未知的开放意图散点在经过第2阶段基于距离损失的特征再训练后得到的特征分布同样变得较为紧凑,密度较高,因此基于密度的局部离群因子检测方法在开放意图检测上效果不佳。
综上可得,OID-DD模型结构合理、效果突出,在开放意图检测任务上具有有效性。
4" 结" 语
通过预训练语言模型BERT提出样本特征表示;采用距离损失函数对特征表示进行强制收缩,使类内收缩更为紧密;固定特征表示对类内距离值进行训练学习,得到合适的决策边界距离阈值,减少类间样本出现混淆交叉现象,从而完成开放意图检测任务。本研究解决了开放意图检测任务中存在的意图表示类内凝聚程度不足以及类间样本接近容易出现混淆交叉等问题。
本文所提方法主要在意图表示处理中进行了研究,未来拟在更好的预训练语言模型方向进行探索,探究在少量样本情况下的开放意图检测方法。
参考文献/References:
[1]" QIN Libo,XIE Tianbao,CHE Wanxiang,et al.A survey on spoken language understanding:Recent advances and new frontiers[C]//Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence.[S.l.]: International Joint Conferences on Artificial Intelligence Organization, 2021:4577-4584.
[2]" WELD H,HUANG Xiaoqi,LONG Siqu,et al.A survey of joint intent detection and slot filling models in natural language understanding[J].ACM Computing Surveys,2023,55(8):1-38.
[3]" 陈晨,朱晴晴,严睿,等.基于深度学习的开放领域对话系统研究综述[J].计算机学报,2019,42(7):1439-1466.
CHEN Chen,ZHU Qingqing,YAN Rui,et al.Survey on deep learning based open domain dialogue system[J].Chinese Journal of Computers,2019,42(7):1439-1466.
[4]" GENG Chuanxing,HUANG Shengjun,CHEN Songcan.Recent advances in open set recognition: A survey[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021,43(10):3614-3631.
[5]" 刘星宏,周毅,周涛,等.基于自步学习的开放集领域自适应[J].计算机研究与发展,2023,60(8):1711-1726.
LIU Xinghong,ZHOU Yi,ZHOU Tao,et al.Self-paced learning for Open-Set domain adaptation[J].Journal of Computer Research and Development,2023,60(8):1711-1726.
[6]" LIN Tingen,XU Hua.Deep unknown intent detection with margin loss[C]//Proceedings of the 57th Conference of the Association for Computational Linguistics.Florence:Association for Computational Linguistics,2019:5491-5496.
[7]" ZHANG Hanlei,XU Hua,LIN Tingen.Deep open intent classification with adaptive decision boundary[C]//The Thirty-Fifth AAAI Conference on Artificial Intelligence.[S.l.]:[s.n.],2021:14374-14382.
[8]" HENDRYCKS D,GIMPEL K.A baseline for detecting misclassified and out-of-distribution examples in neural networks[EB/OL].(2016-10-07)[2024-06-10].https://arxiv.org/abs/1610.02136.
[9]" BENDALE A,BOULT T E.Towards open set deep networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas: IEEE Computer Society,2016:1563-1572.
[10]SHU Lei,XU Hu,LIU Bing.DOC:Deep open classification of text documents[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen:Association for Computational Linguistics,2017:2911-2916.
[11]YAN Guangfeng, FAN Lu, LI Qimai,et al.Unknown intent detection using gaussian mixture model with an application to zero-shot intent classification[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S.l.]:Association for Computational Linguistics,2020:1050-1060.
[12]ZHANG Jianguo,HASHIMOTO K,LIU Wenhao,et al.Discriminative nearest neighbor few-shot intent detection by transferring natural language inference[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. [S.l.]:Association for Computational Linguistics,2020:5064-5082.
[13]ZHAN Liming, LIANG Haowen, LIU Bo,et al.Out-of-scope intent detection with self-supervision and discriminative training[C]//Proceedings of the 59th Annual Meeting of the As-sociation for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S.l.]:Association for Computational Linguistics,2021:3521-3532.
[14]CHENG Zifeng, JIANG Zhiwei, YIN Yafeng,et al.Learning to classify open intent via Soft labeling and manifold mixup[J].IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022,30:635-645.
[15]ZHOU Yunhua, LIU Peiju, QIU Xipeng.KNN-contrastive learning for out-of-domain intent classification[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.Dublin:Association for Computational Linguistics,2022:5129-5141.
[16]WU Yanan, HE Keqing, YAN Yuanmeng,et al.Revisit overconfidence for OOD detection:Reassigned contrastive learning with adaptive class-dependent threshold[C]//Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Seattle:Association for Computational Linguistics,2022:4165-4179.
[17]DEVLIN J,CHANG M W,LEE K.BERT:Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Minneapolis:Association for Computational Linguistics,2019:4171-4186.
