YOLOv5改进综述
2024-11-29李睿鑫张应迁吴嘉懿陈飞宇

摘要:YOLO系列算法在目标检测领域迅速崭露头角,其中YOLOv5被认为是当前的佼佼者。YOLOv5提供了四种不同规模的模型(s、m、l、x) ,以满足不同的应用需求。这些模型的网络结构主要由Backbone和Neck两部分组成,共同实现对目标的精确检测。YOLOv5在多个方面进行了改进,包括Mosaic-8数据增强、特征提取器、损失函数和目标框回归等。在全球范围内,研究人员持续对YOLOv5进行改进研究。随着YOLO算法的不断演进,目标检测领域预示的行业变革将是颠覆性的,但必须建立在社会责任和伦理标准之上。
关键词:YOLO;YOLOv5;算法改进
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)27-0019-04
0 引言
在目标检测领域,实时性和精确性之间的平衡对于算法的实用性是至关重要的,而YOLO(You OnlyLook Once) [1]。算法因其快速的目标检测能力和仅需要一次前向传播的特点而受到广泛关注,并迅速发展如图1,成为该领域的热门研究方向。自Redmon等人最初提出YOLO算法以来,其快速检测的特点就在业界赢得了广泛赞誉。然而,尽管YOLO在检测速度方面取得了显著的成就,但在准确性方面,尤其是对于小目标的识别和定位精度,仍然有提升的潜力。
为了克服这些挑战,研究人员已经尝试了多种创新方法来提升YOLO的性能,包括深化网络架构、优化锚点机制、实施多尺度训练以及精心设计损失函数等策略。这些改进旨在提高YOLO在保持实时检测速度的同时,增强其在复杂场景中的检测精度和鲁棒性。
本文的目标是整理和评述基于YOLOv5的改进目标检测算法研究,并探讨针对YOLOv5算法提出的主要改进方法,同时对未来YOLO相关研究的发展方向进行展望。
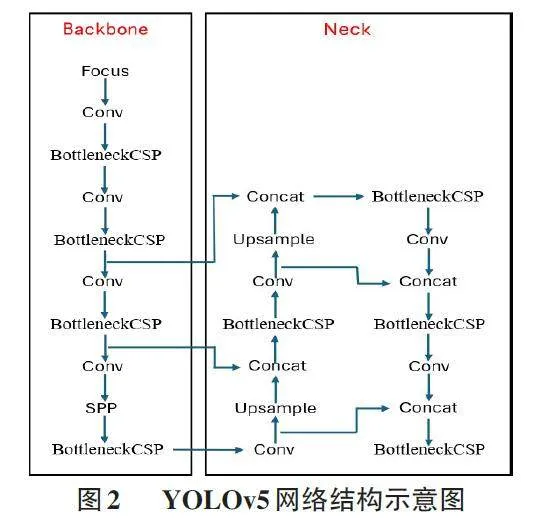
1 YOLOv5 网络结构
YOLOv5算法采用全图输入方式,一次性生成全部检测信息。该算法包括s、m、l、x四种规模递增的模型,一般来说,YOLOv5的网络结构通常包括Backbone 和Neck两个主要部分(如图2) 。Backbone部分通过Focus 结构进行下采样,利用经过优化的CSP(CrossStage Partial networks) [2] 结构和SPP(Spatial PyramidPooling) [3]金字塔结构来提取图像特征。接着,Neck部分运用FPN(Feature Pyramid Network) [4]结合PAN(PathAggregation Network) [5]的特征金字塔结构,以处理不同尺寸目标的特征信息,从而解决多尺度检测问题。
1.1 Backbone
在YOLOv5的结构中,Backbone网络主要由一系列的CBS(Convolutional-BatchNorm-SiLU) 模块和C3(CSPNet-inspired Bottleneck) 模块构成,并以一个SPPF(Spatial Pyramid Pooling Free) 模块作为结束。CBS模块为特征提取提供了重要的支持,优化了C3模块的性能。SPPF模块则在骨干网络的末端增强了特征的表达能力。而C3模块是YOLOv5骨干网络的关键部分,其设计受到了CSPNet[2] (Cross-Stage PartialNetworks) 的启发。它不仅提升了网络的特征提取能力,还有效减少了梯度信息在网络中的重复。这种设计使得YOLOv5能够平衡特征学习的深度和广度,同时控制计算资源的消耗,确保了算法的效率和精度。这种设计使得YOLOv5能够平衡特征学习的深度和广度,同时控制计算资源的消耗,确保了算法的效率和精度。
1.2 Neck
在YOLOv5的Neck结构中,FPN和PAN被巧妙地结合起来。FPN的主要思想是通过对深层卷积网络产生的不同层次的特征图(如C3、C4和C5) 进行上采样处理,从而生成一系列新的多尺度特征图。这些特征图用于检测图像中不同尺寸的目标对象。
通过这种方式,YOLOv5能够有效地结合来自网络深层的详细特征和浅层的语义信息,提高模型对各种大小目标的检测能力。同时,引入PAN进一步强化了特征融合过程,确保了丰富的上下文信息在多层特征图之间的有效流通,为精确的目标定位和分类提供了有力支持。
2 YOLOv5 算法的改进
目前,各研究人员对YOLOv5算法的改进主要有四个方面:
2.1 Mosaic 技术
YOLOv5模型在其基础的数据增强策略上,采用了Mosaic技术。这种技术通过计算机生成的多样化变体,如图像缩放、平移、旋转和调整色彩等手段,不仅增加了数据集的规模,还通过引入有益的噪声,增强了模型对未知数据的处理能力,它将四张图片随机裁剪、缩放并拼接在一起,不仅增加了数据集的多样性,而且特别增强了对小型目标的训练效果,从而加快了网络的学习速度。在图片归一化环节中,四张图片的统计数据被统一计算,这进一步节约了计算资源。
2.2 特征提取器
在YOLOv5的核心网络设计中,通过利用三种不同尺度的特征提取器,实现了在保持性能的同时减少对内存资源的依赖。这一策略包括将输入图像进行不同程度的下采样—8倍、16倍和32倍—以产生一系列不同尺寸的特征图,这些特征图随后被送入一个受特征金字塔网络(FPN) 启发的融合网络中。FPN结构通过自上而下的路径传递丰富的高级语义信息,同时自下而上的路径保留了精确的空间信息。这种设计使得网络在保持语义丰富性的同时,也能够精确地定位目标,尤其对于小目标检测来说至关重要。
卷积神经网络中的不同层级产生的特征图捕捉了不同的目标信息。浅层特征图具有较高的空间分辨率,能够精确地定位目标,但缺乏足够的语义信息;而深层特征图虽然富含语义信息,却在多次卷积过程中丢失了部分空间精度。因此,将浅层和深层特征图结合起来,不仅有助于简单目标的识别,也能够更好地区分复杂目标。此外,将特征金字塔网络与路径聚合网络(PAN) 相结合。PAN通过自底向上的路径传递空间信息,而FPN则通过自顶向下的路径传递语义信息。这种双向融合机制使得模型能够更全面地学习特征,尤其是提高了对小目标的检测灵敏度。
2.3 损失函数
在YOLOv5的损失函数设计中,主要包含了三个要素:定位损失、置信度损失和类别损失。对于置信度损失和类别损失的计算,采用了二元交叉熵损失函数,而对于定位损失,YOLOv5 最初采用了GIoU[6]方法,这是一个比传统的IoU(Intersection over Union) 更为高级的指标。GIoU不仅关注真实框与预测框的重叠区域,还考虑了非重叠区域,从而更准确地衡量两者的匹配程度。然而,尽管GIoU提供了对重叠区域的更全面评估,但它主要基于重叠率,这可能不足以全面描述目标框的回归问题。特别是当预测框完全位于真实框内且大小相同时,GIoU退化为IoU,无法区分预测框之间的相对位置关系。
为了提高定位精度,可以采用了CIoU作为定位损失的计算方式。CIoU在IoU的基础上进一步考虑了边界框之间的中心点距离和宽高比,这些因素的综合考量使得目标框回归过程更加稳定,并提高了收敛精度。通过引入CIoU后,在目标检测的准确性和鲁棒性方面取得了显著进步。这种改进使得模型能够更精确地定位目标,特别是在处理具有挑战性的小目标或密集目标的场景时。
2.4 目标框回归
目标框回归是对象检测任务中的一个关键环节,它的目的是建立一个高效的转换机制,使得候选框能够尽可能地对齐至真实目标框。在YOLOv5中,这种转换通常通过相对位置回归来实现,模型预测的是候选框相对于网格单元左上角的偏移量,而非绝对坐标。这种方法使网络能够学习到细微的位置调整,从而更准确地锚定图像中的目标。
为了实现这一目标,模型会输出一系列的偏移参数,包括中心点坐标的x 和y 轴偏移、宽度和高度的缩放比例,以及一个表征目标存在概率的置信度得分。这些参数共同构成了一个回归向量,指导候选框从其初始位置向真实目标位置的移动和缩放。在训练过程中,模型通过最小化候选框与真实框之间的差异量(如IoU或GIoU) 来优化其回归性能。
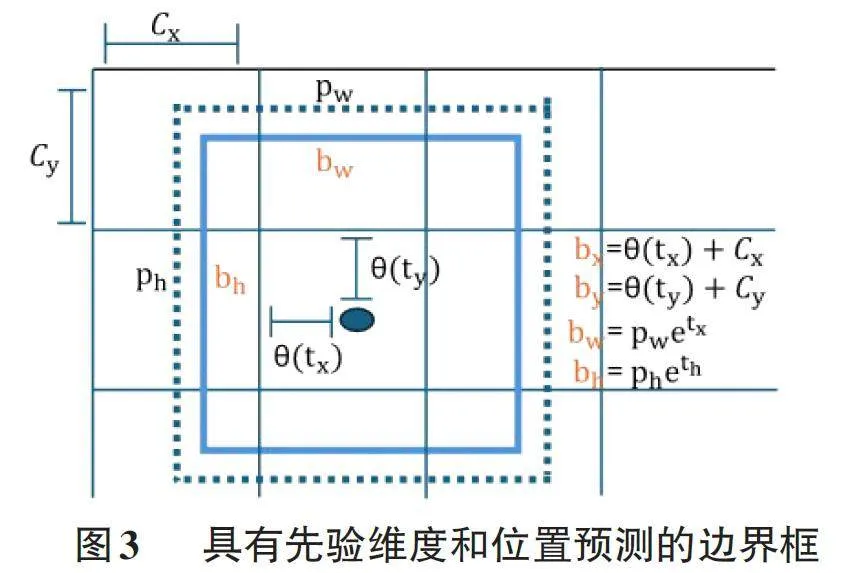
为了提升YOLOv5的目标框回归能力,可以采用了更为进阶的损失函数CIoU,它不仅考量了重叠区域的面积,还综合了边界框之间的中心点距离和宽高比,以进一步细化定位精度,如图3所示。此外,通过融合特征金字塔网络(FPN) 和路径聚合网络(PAN) ,模型能够更有效地捕捉多尺度特征,从而增强了对小型目标和邻近目标的检测能力。目标框回归的改进显著提升了检测模型的定位精确度,尤其在处理不同规模和形状的目标时,确保了更高的检测准确率和更强的泛化能力。
3 YOLOv5 改进研究现状度
为了提高在复杂环境中检测不完整或小尺寸物体的准确率,孙秋红、张晓天、李玉佳和王静阳提出了一种改进的垃圾检测模型YOLOv5-OCDS[7]。在这个新模型中,研究人员采用了ODConv[8]来替代颈部的一部分卷积,以自适应调整通道间的交互和重要性,从而提取更具区分性的特征。他们还提出了C3DCN模块,用以取代颈部的C3结构,以更准确地对目标进行采样,避免信息的丢失并提高对不同类别的识别能力。同时,使用软NMS代替普通NMS,降低了在消除过程中小目标检测框的置信度,有助于保留这些小目标的检测结果,从而提高模型的准确性。
相比于原始YOLOv5s,YOLOv5-OCDS 在mAP@50 上提高了5.3%,在mAP@50:95 上提高了12.3%。与Faster R-CNN[9]相比,YOLOv5-OCDS在mAP@50上提高了12.4%。这个新模型能够更准确地定位和识别目标,具有更好的检测能力和鲁棒性。在较高的IoU 阈值范围内,模型能够更好地适应不同目标形状和大小的变化。虽然该模型在改进mAP的同时,也增加了参数和GFLOP的数量,但Soft-NMS[10]的引入降低了大量重叠物体的置信度分数,可能会在检测堆叠严重的物体时出现漏检情况。YOLOv5-OCDS模型通过使用ODConv替代颈部一部分普通卷积,并在卷积操作中引入对感知场和形状的自适应调整,使卷积操作更加灵活和适应性强,增加了对小目标物体和形状变化较大的物体的适应能力。C3DCN结构的引入可帮助模型更好地捕获和识别各种形状和大小的对象。
王鹏飞、黄汉明和王梦琪等研究人员对小目标检测技术进行了研究,特别是在骑手头盔佩戴检测领域[11]。针对小目标检测中定位准确性的要求及小目标聚集问题,研究团队在YOLOv5s网络基础上进行了改良,尝试将CBAM(Convolutional Block Attention Mod⁃ule) [12]注意力模块集成进网络的不同部分,并通过多次实验确定最优位置。在网络的颈部C3结构之后和检测头部之前插入CBAM模块可以有效提升定位精确度,减少小目标聚集现象,从而提高检测精度。此外,为了优化网络性能,他们提出使用GhostBottle⁃neck[13]结构替代YOLOv5s 网络中的Bottleneck 结构。评估结果显示,这种替换能有效减小模型体积,降低参数数量及计算量。从对新提出的YOLOv5s-FCG网络检测模型进行的实验可知,该网络模型在小目标数据集上的检测准确度得到了显著提升。
为了提升YOLOv5目标检测器对小尺寸目标的检测性能,研究者Aduen Benjumea, Izzeddin Teeti, FabioCuzzolin和Andrew Bradley进行了深入的架构和模型分析[14]。他们开发了YOLO-Z 系列模型,该模型在mAP指标上表现出近6%的性能提升,推理时间仅增加约3毫秒,这对自动驾驶汽车的感知系统是一个重要的进步。研究团队使用了一套专门为自动驾驶赛车设计的带注释锥体数据集。这个数据集包含黄色、蓝色、橙色和大橙色锥体的图像[15],覆盖了多种天气条件下的场景。数据集中的锥体边界框的位置、宽度和高度显示出由于透视效应而略微拉长的形状,在很大程度上解决了其他流行数据集(如MS COCO[16]) 中缺少小物体的问题。
Mohammad Hossein Hamzenejadi和Hadis Mohseni 对YOLOv5模型进行了改进,以优化无人机在飞行中捕捉的车辆图像的检测性能[17]。研究人员在三个不同的无人机图像数据集上测试了改进后的模型。此改进版本包括以下关键调整:(1) 引入新的检测头部来准确识别极小尺寸的物体,并重新设计网络的颈部结构以增强特征图之间的联系;(2) 在网络的主干部分加入SE注意力机制[18]提升其对重要特征的识别能力;(3) 采用了一种自适应的损失函数来取代原有的边界框回归损失函数,旨在提高模型预测的精准度;(4) 调整模型的深度与宽度以实现更优的性能平衡;(5) 在颈部结构中使用轻量化卷积技术,既减少了模型复杂度,又加速了推理过程。这些优化措施增强了模型对小目标的检测精度,加快了处理速度,并降低了整体计算复杂性。新模型在精度、召回率、mAP@0.5和mAP@0.95等指标上均实现显著提升,同时在体积和GFLOPS消耗方面更为经济,FPS(每秒帧数)比YOLOv5X高出207.15%。与面向实时应用的轻量级模型YOLOv5M相比,新模型不仅体积和计算消耗更小,而且精度上显著提高。研究结果显示,该改进让YOLOv5网络更接近实际应用需求,为未来可能实现的在无人机上实时运行的YOLOv5网络带来了希望。
4 未来的研究与发展方向
在应用方面,YOLO算法有望进一步整合进自动驾驶、智慧安防和工业检测等核心领域,并拓展至医疗诊断、增强现实等前沿技术中。这些应用领域对算法的精确性、响应速度和稳定性提出了更高的要求,同时也带来了广阔的市场潜力和社会价值。随着算法应用的不断深化,保护隐私和伦理问题将受到更多关注。如何在保障个人隐私的同时充分利用数据资源,将是YOLO 算法未来改进必须考虑的问题。此外,在移动和边缘设备的应用中,算法的能效优化也是一个关键的挑战,YOLO算法的持续进化将为多个行业带来创新的变革。
5 结论
作为目标检测领域的重要里程碑,YOLO算法未来的优化和研究将集中在性能提升和应用范围的扩大上。为了克服在小目标检测、实时处理以及模型普适性方面的挑战,研究人员可以在Mosaic-8数据增强、特征提取器、损失函数和目标框回归等多个方面对YOLOv5进行改进,并着力于探索更加深入的特征融合方法、设计更轻巧的网络架构,开发出适应性更强的学习策略。随着技术的不断进步,也可以采用最新版本并结合更先进技术的YOLO系列来提高检测精度和速度,为各种目标检测任务提供更加高效的解决方案。
参考文献:
[1] REDMON J, DIVVALA S, GIRSHICK R, et al. You only lookonce: Unified, real-time object detection[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition(CVPR). June 27-30, 2016. Las Vegas, NV, USA. IEEE, 2016:779-788.
[2] WANG C-Y. CSPNet: A new backbone that can enhance learn⁃ing capability of CNN[EB/OL]. [2023-12-20]. arXiv preprintarXiv: 1911.11929, 2019. Available at: http://arxiv. org/abs/1911.11929.
[3] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid poolingin deep convolutional networks for visual recognition[M].Lec⁃ture Notes in Computer Science.Cham:Springer InternationalPublishing,2014:346-361.
[4] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature PyramidNetworks for Object Detection[J]. IEEE Conference on Com⁃puter Vision and Pattern Recognition (CVPR), 2017: 2117-2125.
[5] LIU S, QI L, QIN H, et al. Path Aggregation Network for In⁃stance Segmentation[C]//Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2018:8759-8768.
[6] REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized In⁃tersection over Union: A Metric and A Loss for Bounding BoxRegression[EB/OL]. [2023-12-20]. arXiv preprint arXiv:1902.09630, 2019.
[7] SUN Q, ZHANG X, LI Y, et al. YOLOv5-OCDS: An ImprovedGarbage Detection Model Based on YOLOv5[J]. Electronics,2023,12(16):3403.
[8] LI C, ZHOU A, YAO A. Omni-Dimensional Dynamic Convolu⁃tion[EB/OL].[2023-12-20].arXiv preprint arXiv:2209.07947.
[9] LIU B, ZHAO W, SUN Q. Study of object detection based onFaster R-CNN[C]//2017 Chinese Automation Congress (CAC).IEEE, 2017: 6233-6236.
[10] BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS --Improving object detection with one line of code[C]//Proceed⁃ings of the IEEE International Conference on Computer Vi⁃sion, 2017: 5561-5569.
[11] WANG P, HUANG H, WANG M, et al. YOLOv5s-FCG: Animproved YOLOv5 method for inspecting riders′ helmet wear⁃ing[J]. Journal of Physics: Conference Series, 2021, 2024(1):012059.
[12] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional blockattention module[C]//Proceedings of the European Conferenceon Computer Vision (ECCV). 2018: 3-19.
[13] HAN K, WANG Y, TIAN Q, et al. GhostNet: More featuresfrom cheap operations[C]//Proceedings of the IEEE/CVF Con⁃ference on Computer Vision and Pattern Recognition. 2020:1580-1589.
[14] BENJUMEA A, TEETI I, CUZZOLIN F, et al. YOLO-Z: Im⁃proving small object detection in YOLOv5 for autonomous ve⁃hicles[EB/OL].[2023-12-20].arXiv preprint arXiv:2112. 11798.
[15] MUSAT V, KHALIQ A, LEONTE C, et al. Multi-weather city:Adverse weather stacking for autonomous driving[C]//Proceed⁃ings of the IEEE/CVF International Conference on ComputerVision Workshops, 2021: 2906-2915.
[16] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO:Common objects in context[C]//European Conference on Com⁃puter Vision. Springer, Cham, 2014: 740-755.
[17] HAMZENEJADI M H, MOHSENI H. Fine-tuned YOLOv5 forreal-time vehicle detection in UAV imagery: Architectural im⁃provements and performance boost[J]. Expert Systems withApplications, 2023(231): 120247.
[18] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision andPattern Recognition, 2018: 7132-7141.
【通联编辑:唐一东】
