基于改进YOLOv8的物流AGV精确识别与定位研究
2024-11-11杨振伟王钧符朝兴






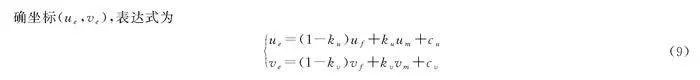
文章编号: 1006-9798(2024)03-0031-08; DOI: 10.13306/j.1006-9798.2024.03.005
摘要: 针对原始YOLOv8n算法在复杂环境中识别自动导引运输车(Automated Guided Vehicle, AGV)准确率低的问题,引入CBAM注意力机制,建立CBAMYOLOv8n网络模型,提高了模型提取关键特征的能力。建立数学模型矫正采集图像定位误差,提高AGV在图像坐标系中的定位精度。仿真结果表明,相对于原始YOLOv8n模型,CBAMYOLOv8n网络模型在AGV空载和负载的情况下,识别准确率分别提高1.4%和2.0%,综合识别率提高1.7%。图像误差矫正后,图像坐标在u轴和v轴方向的最大误差为1.3像素和4.3像素,平均误差为0.74像素和2.1像素。验证了AGV在图像坐标系中可以减小定位误差,提高定位精度。
关键词: YOLOv8; 自动导引运输车; 注意力机制; 误差矫正
中图分类号: TP242.2文献标识码: A
在工业生产、仓库管理和物流配送等领域,自动导引运输车(Automated Guided Vehicle, AGV)取代人工运输是提升生产效率、降低人工成本以及提高安全性的有效策略[1]。在AGV导航技术领域,传统的导航方法如激光导航和磁带导航存在较低的鲁棒性和维护难度较高等缺陷[2]。视觉导航技术因较高的灵活性和较低的成本效益,逐渐成为主流的AGV导航[3]。如采用视觉SLAM技术,通过整合特征点检测与光流估计技术,实现对AGV的精确位姿估计[4]。刘明兴提出了一种针对形状不变的AGV全局视觉定位算法,即利用卡尔曼滤波技术对基于YOLOv3目标检测模型的AGV定位过程进行优化,以提升定位精度和鲁棒性[5]。在工厂管理系统中,需要实时准确地监控AGV的位置坐标,以获取其精确的位置信息。目前,传统基于图像处理的目标检测方法包括图像分割[6]、特征提取[7]以及颜色分割[8]等技术。然而,在复杂环境中,这些方法容易受到目标遮挡、噪点和光照变化等因素的干扰,导致识别准确性下降、鲁棒性不足以及处理过程耗时较长,难以满足工程应用需求。随着基于深度学习的目标检测方法在工业领域中的广泛应用,图像目标检测与深度学习的结合有效地解决了传统目标检测方法存在的一系列问题。常用的方法有双阶段检测(twostage detector)和单阶段检测(onestage detector)两种类型的卷积神经网络模型[9]。双阶段检测中最具有代表性的是RCNN[10-11]系列算法,在网络训练中,减少了繁琐的人工特征选择,同时根据实际应用场景对模型持续优化,提高其识别精度。但模型规模庞大,检测时间长,难以满足实时检测需求。相较之下,单阶段检测具有更快的检测速度和更高的可扩展性,更适用于实际场景中的应用。单阶段检测模型中最具有代表性的是YOLO[12]系列目标检测算法。在YOLOv3的基础上改进的YOLOv4[13]算法将路径增强网络PANet与算法结合,实现更精确特征融合和目标检测。在YOLOv7的基础上提出的YOLOv8算法,相比之前的版本,处理速度与准确度都得到了极大的提升[14-15]。通过调整YOLOv8控制网络的深度和宽度,设置了YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l、YOLOv8x 5种模型来满足不同场景的需求,YOLOv8n具有模型规模小、计算快、识别准确度高、响应速度快等优点,可以作为训练模型。但是,在有遮挡光照条件不足等环境下,YOLOv8模型的识别准确率会降低。为了提高在复杂环境下AGV的识别准确率和定位精度,本文在YOLOv8n的基础上引入CBAM注意力机制,在自制的AGV数据集上,优化目标检测定位精度,分别基于原始YOLOv8n 和改进后的YOLOv8n 算法进行实验,与原始的YOLOv8n算法相比,CBAMYOLOv8n算法准确率有所提升,定位误差降低。
1目标检测算法
1.1YOLOv8目标检测算法
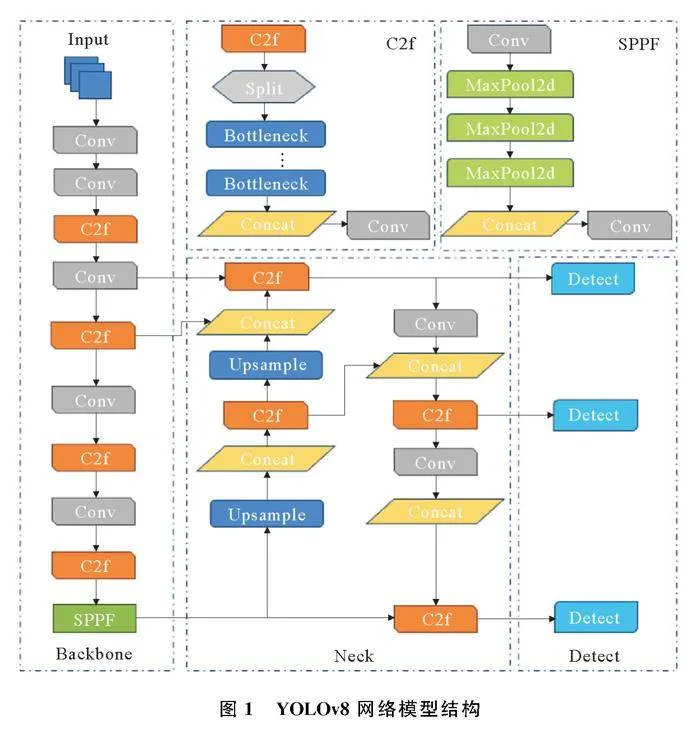
YOLO算法的核心是将图像划分为多个网格,对每个网格预测边界框和物体类别,并利用非极大值抑制方法消除重叠的边界框。YOLOv8网络模型由主干特征提取模块(Backbone)、特征加强模块(Neck)和检测模块(Detect)3个关键组成部分构成图1,主干部分采用C2f模块以增强梯度流,降低了计算复杂度,提高了计算速度和特征融合能力。特征加强模块采用PANet(Path Aggregation Network)结构,通过上采样和通道融合等技术将PANet的3个输出分支整合并传递至检测模块。检测模块采用解耦头结构进行目标检测,实现了回归分支和预测分支的分离,有效提升了模型的训练收敛速度。YOLOv8采用了无锚框(Anchor Free)方法,将目标检测转换为关键点检测,无需预先聚类训练数据集以确定长宽比和锚框数量等参数,从而增强了模型的泛化能力和网络框架的简洁性。
1.2YOLOv8算法改进
对于车间物流AGV所处的复杂环境,经常出现AGV被遮挡导致YOLOv8n网络模型检测AGV时精度低、漏检率高等问题,本文在原始YOLOv8n算法中引入注意力机制,提高模型对重要信息的关注度,增强模型性能和泛化能力。深度学习中的注意力机制(Attention Mechanism)可以使得神经网络具备关注局部信息,提取关键特征的能力,根据输入信息动态分配权重[16]。注意力机制抽象为
Attention=fgx,x(1)
式中,g(x)表示对输入特征进行处理并产生注意力的过程,f(g(x),x)表示结合注意力对输入特征进行处理的过程。
常见的注意力机制有通道域、空间域和混合域注意力3种。混合域注意力机制结合了通道域和空间域注意力的优势,形成一种更全面的特征注意力方法,代表模型有瓶颈注意力模型(Bottleneck Attention Module,BAM)和卷积注意力模型(Convolutional Block Attention Module,CBAM),以更强的灵活性、更好的鲁棒性和适应性而备受青睐[17]。在复杂场景下,BAM无法充分捕获通道和空间上的关键信息,且通道和空间注意力之间的交互有限,限制了其表达能力。CBAM包括通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM),输入的特征图先在CAM中学习通道注意力权重,后输入到SAM中学习空间注意力权重,最终获得输出加权特征图,流程如图2。因此,本文将CBAM注意力模块引入原始的YOLOv8n算法。
CAM学习通道处理流程如图3所示,特征图输入至池化层,得到两个特征通道向量;多层感知机(MultiLayer Perceptron,MLP)学习通道维度特征并对结果求和;Sigmoid函数将权重逐通道加权到原始输入特征图,得到最终的通道注意力特征图。
通道注意力计算公式为
McF=σMLPAvgPoolF+MLPMaxPoolF=σW1W0Fcavg+W1W0Fcmax(2)
式中,σ为sigmoid函数,AvgPool为平均池化操作,MaxPool为最大池化操作,Fcavg和Fcmax为平均池化和最大值池化特征,W0和W1为MLP权重,且W0∈RCr×C,W1∈RC×Cr。
SAM流程如图4,以CAM的输出特征图作为SAM的输入特征送入输入池化层中,拼接输出结果,以7×7卷积核将其卷积降维成一个通道,使用Sigmoid函数生成空间权重系数,与输入的特征图相乘,完成空间域上的特征提取,得到最终的特征图。
空间注意力子模块计算公式
MsF=σf7×7AvgPoolF;MaxPoolF=σf7×7Fsavg;Fsmax(3)
其中,f7×7是卷积核尺寸为7×7卷积运算。
1.3评价指标
在目标检测任务中,常用的评价指标有Pascal VOC和COCO评价指标,实验中采用更加严格、全面的COCO评价指标。
1)混淆矩阵。混淆矩阵是n×n的矩阵,展示分类模型的预测结果和实际结果之间的对应关系,见表1,矩阵的行代表真实值,列代表预测值,TP、FN、FP、TN分别代表正类预测为正类、正类预测为负类、负类预测为正类、负类预测为负类。
2)PR曲线。PR曲线(PrecisionRecall Curve)是用来描述模型综合性能的一种指标,通过设置不同的置信度阈值,计算不同阈值下的P值和R值,然后以横轴为Recall,纵轴为Precision绘制而成。精确度P(Precision)表示预测为正类且正确的数量(TP)在预测为正类(TP+FP)中的占比
P=TPTP+FP(4)
召回率R(recall)表示预测为正类且正确的数量(TP)在正类(TP+FN)中的占比
R=TPTP+FN(5)
3)平均精度。单类别的平均精度(Average Precision,AP)用来衡量单类别的模型的准确度
AP=∫10p(r)dx(6)
其中,p(r)为关于PR曲线的方程。
mAP表示所有类别的平均精度的均值
mAP=1k∑ki=1APi(7)
其中,k为类别数量。
2数据集与模型训练
2.1数据集采集与标注
为了训练目标检测模型,实现对物流AGV识别定位,需要采集图像数据建立数据集。为了模拟车间复杂的工作环境,保证物流AGV定位的准确性和鲁棒性,建立数据集需要考虑多种情况。
1)无遮挡情况。AGV在空旷的区域,没有被任何障碍物或者人员遮挡。
2)有遮挡情况。AGV被货物、人员或者机床等遮挡,摄像头仅能获取AGV的部分特征信息。
3)空载情况。AGV未搭载任何物品,无货物覆盖AGV。
4)负载情况。AGV正在运载物料,摄像头无法获取AGV全部特征信息。
5)光照情况。模拟车间白天和夜晚的光照情况,分别在光照良好和光照恶劣的环境下采集数据集。
以上述5种情况为基准,组合不同的工作环境,调整AGV位置和角度,共获取1 500张有效图像。为了保证数据集的多样性和全面性,使用图像处理工具包(Python Image Library,PIL)对图片旋转、反转、颜色抖动和添加高斯噪点,扩充数据集,提高模型的泛化能力,最终获得数据集8 000张。
模型训练前采用LabelImg软件对数据集图像进行标注,设定标注格式为PascalVOC,数据集标注示意图如图5。
2.2模型训练
1)实验环境。实验用计算机在满足硬件条件的基础上,搭配合适版本的软件,采用实验环境参数为:实验上位机操作系统使用Window10专业版、GPU型号为NVIDIA GeForce RTX 3070、CUDA版本为11.8、cuDNN版本为8.9.3、Pytorch版本为2.1.1+cu11.8。
2)模型训练。模型训练的结果直接影响AGV定位识别的准确性,将数据增强后的数据集作为模型训练数据集,按照4∶1的比例随机分配训练集和验证集,最终设置训练集6 400张图片,验证集1 600张图片。模型训练300次,图片分辨率为640×640,每次网络获取图片数量为16,工作线程数为2。
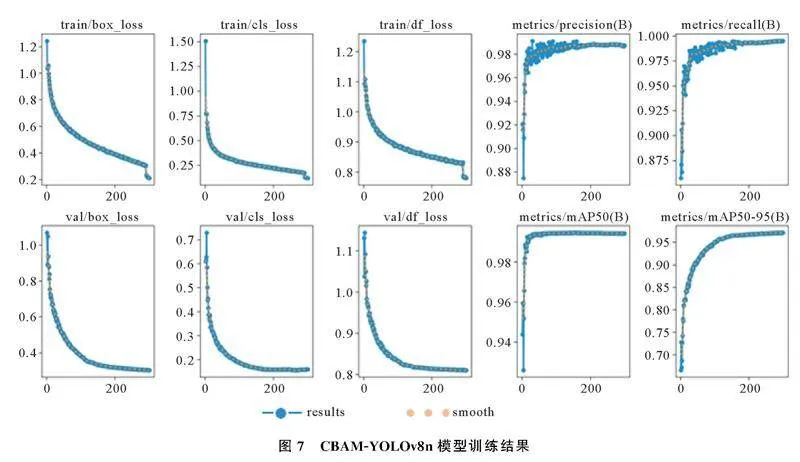
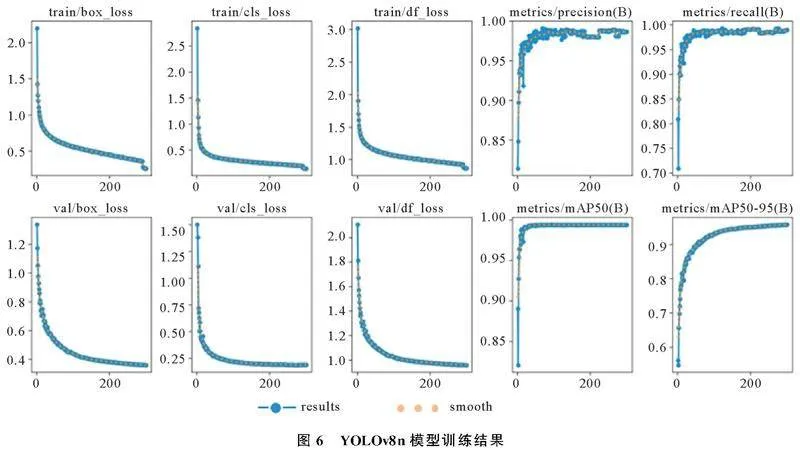
实验分别基于原始YOLOv8n算法和CBAMYOLOv8n算法训练AGV识别定位模型。数据集检测类型分为空载Empty_AGV和负载Load_AGV两种情况,数据集训练模型结果中所涉及评价指标见表2。
YOLOv8n和CBAMYOLOv8n均迭代训练300次,YOLOv8n模型训练结果如图6,CBAMYOLOv8n模型训练结果如图7。由图6和图7可以看出,CBAMYOLOv8n模型在各项准确性评价指标上的训练结果收敛性明显优于YOLOv8n模型。因此,初步推断在添加CBAM注意力机制后,模型的目标检测准确性得到了显著提升。
3目标检测定位精度优化
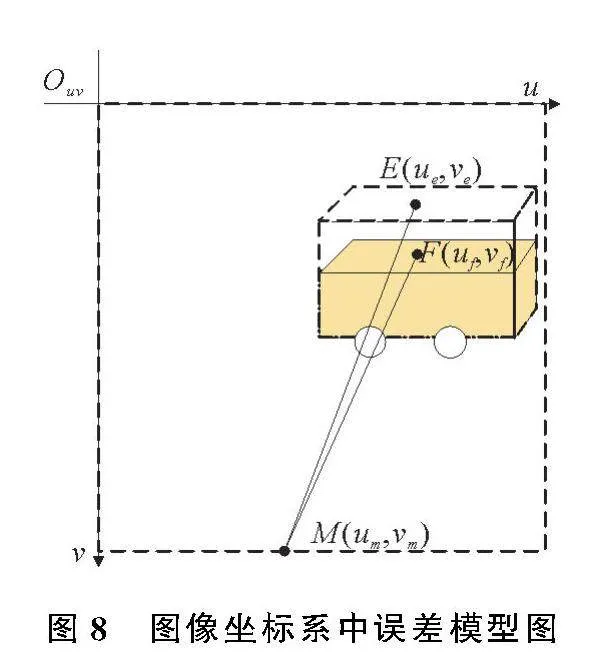
由于全局视觉摄像头以非垂直的方式进行安装,在对AGV进行目标检测时,会产生定位误差;AGV具有一定的高度,环境图像经过逆透视变换880c90f6f9754525a1d1e10f0478a9e9处理后,AGV在图像中被拉伸变形,也会产生定位误差,图像坐标系中误差模型图如图8。Ouv为图像坐标系,M为相机在图像坐标系中的坐标点,E为逆透视变换后目标检测算法实际坐标点,F为图像坐标矫正后的正确坐标点。
根据逆透视变换特性,AGV与摄像头距离越远,逆透视变换后,AGV因为高度形变产生的误差则越大,两者距离与误差之间存在线性关系
εu=kudu+cuεv=kvdv+cv(8)
其中,εu和εv表示在图像坐标系中u轴和v轴所产生的误差,k、c为待定系数,du和dv为采集AGV中心点到摄像头坐标在图像坐标系下u轴和v轴上的距离,正负符号表示方向。
根据实际坐标点(uf,vf)和相机坐标点(um,vm),由式(8)求出正确坐标(ue,ve),表达式为
ue=(1-ku)uf+kuum+cuve=(1-kv)vf+kvvm+cv(9)
4物流AGV识别与定位实验
4.1识别准确度对比实验
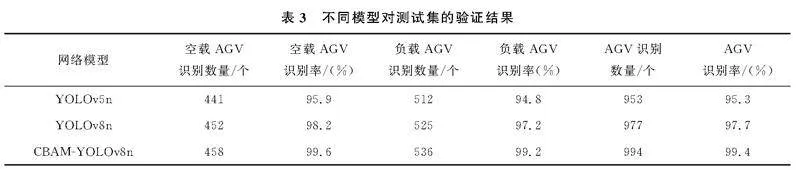
为了验证改进后YOLOv8n对AGV识别定位算法的准确性、鲁棒性,用同一数据集分别验证采用YOLOv5、YOLOv8n和CBAMYOLOv8n对AGV识别定位算法进行实验验证。以实验拍摄1 000张图片作为测试集,其中空载AGV图片为460张,负载AGV图片为540张。不同模型对同一测试集的验证结果见表3。
部分识别检测结果图片如图9。实验结果表明,相较于原始YOLOv8,CBAMYOLOv8,CBAMYOLOv8n模型的空载AGV识别准确率提高了1.4%,负载AGV识别准确率提高了2.0%,综合识别率提高了1.7%,定位识别准确率明显提高。因此,选择CBAMYOLOv8n模型作为AGV导航系统中识别定位算法。
4.2定位误差矫正实验
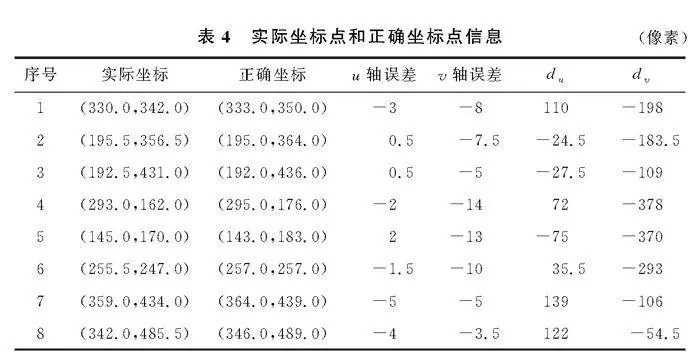
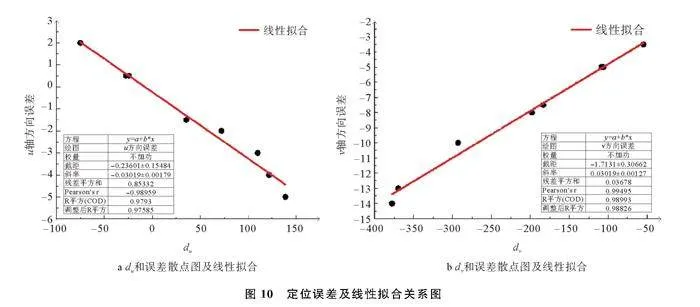
由于逆透视变换和摄像头投影关系的影响,AGV在图像中实际定位点和正确定位点存在误差。为了获取到实际定位点和正确定位点的误差关系,本文在行驶路径上任取8个点,拟合两者之间的关系式。摄像头在图像坐标系中位置为(220,540),采集的实际坐标点和测量的正确坐标点见表4。du和误差散点如图10a;dv和误差散点如图10b,拟合出散点的线性方程。
由图10可获得图像坐标系中AGV与摄像头距离和定位误差之间的线性方程
εu=-0.030 19du-0.2360 1εv=0.030 91dv-1.713 1(10)
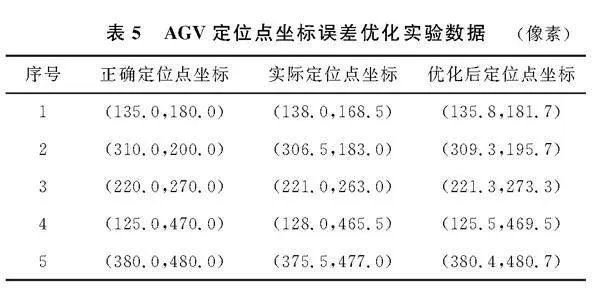
为了验证拟合结果的有效性,在图像中选5个点进行测试,表5记录了正确图像定位点坐标、目标检测获得的实际定位点坐标及误差优化后定位坐标。
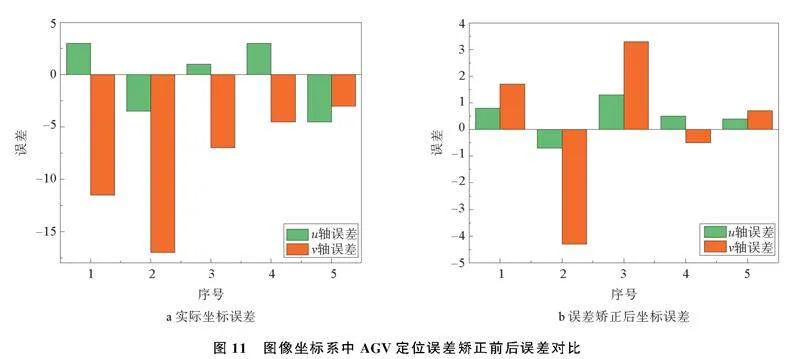
实际图像坐标在u轴方向和v轴方向产生的误差如图11a;误差优化后定位坐标在u轴方向和v轴方向产生的误差如图11b。
实验数据表明,使用目标检测算法获取到的AGV定位坐标在u和v方向的最大误差为3.5像素和17像素,平均误差为2.6像素和8.6像素。经过图像定位误差矫正后,定位坐标在u和v方向的最大误差值为1.3像素和4.3像素,平均误差值为0.74像素和2.1像素。可以看出,在图像坐标系Ouv中,AGV距离摄像头投影点距离越远,产生误差越大,距离越近则误差越小。对于误差较小的坐标点,误差矫正之后误差可能会增大,比如3号点,在u方向坐标与相机u方向坐标相等,误差仅为1像素,误差矫正之后误差为1.3像素,原因是求解误差的函数为近似拟合,线性方程的斜率和截距值均存在波动,所以求解的优化误差值ε也存在一定的波动,但波动范围较小,对结果影响不大。因此,实验证明了本文针对图像坐标系中定位误差矫正的有效性,提高了定位点精度。
5结束语
通过引入CBAM注意力机制对YOLOv8n算法进行改进,本文提出了一种基于YOLOv8n的AGV识别算法,CBAMYOLOv8n网络模型。以AGV是否负载、AGV是否被遮挡和环境光照优劣为条件采集数据集对CBAMYOLOv8n网络模型进行实验验证。验证结果表明,CBAMYOLOv8n网络模型在AGV空载和负载的情况下,识别准确率均有提高,具有更优的预测效果。通过目标检测定位精度优化,减小了AGV在坐标系中的定位误差,提高了定位精度。后续的工作考虑引入调度算法,对多台AGV同时识别定位,提高生产效率和运营灵活性。
参考文献:
[1]陈显宝, 金隼, 罗磊, 等. 基于视觉定位的AGV定位精度提高方法[J]. 机械设计与研究, 2021, 37(1): 36-40.
[2]阎欣怡. 基于激光雷达的AGV导航系统设计与实现[D]. 天津: 河北工业大学, 2022.
[3]徐晓倩. 基于视觉导引的AGV路径跟踪及避障策略研究[D]. 长春: 吉林大学, 2021.
[4]韩玉虎. AGV导航系统中视觉SLAM定位与建图方法的设计与实现[D]. 沈阳: 中国科学院大学(中国科学院沈阳计 算技术研究所), 2022.
[5]刘明兴. 基于全局视觉的车间AGV识别及定位研究[D]. 青岛: 青岛大学, 2021.
[6]SUN S, JIANG M, HE D J, et al. Recognition of green apples in an orchard environment by combining the GrabCut model and Ncut algorithm[J]. Biosystems Engineering, 2019, 187(C): 201-213.
[7]LU J, LEE W S, GAN H, et al. Immature citrus fruit detection based on local binary pattern feature and hierarchical contour analysis[J]. Biosystems Engineering, 2018, 171: 78-90.
[8]HAYASHI S, YAMAMOTO S, SAITO S, et al. Field operation of a movable strawberryharvesting robot using a travel platform[J]. Japan Agricultural Research Quarterly, 2014,48(3): 307-316.
[9]ALQAMAHS, YUNSOO C, JIA J, et al. A deep convolutional neural network model for improving WRF simulations[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 34(2): 750-760.
[10]代恒军. 基于改进的Faster RCNN图像目标检测方法研究[J]. 信息技术与信息化, 2023, (08): 91-94.
[11]QUAN L Z, FENG H, Lü Y, et al. Maize seedling detection under different growth stages and complex field environments based on an improved Faster RCNNI[J]. Biosystems Engineering, 2019, 184: 1-23.
[12]姚文清, 李盛, 王元阳. 基于深度学习的目标检测算法综述[J]. 科技资讯, 2023, 21(16): 185-188.
[13]YU H L, CHEN W L. Motion target detection and recognition based on YOLOv4 algorithm[C]∥3rd International Conference on Artificial Intelligence and Computer Science (AICS) . Beijing: AICS, 2021, 012053.
[14]TALAAT F M, ZAINELDIN H. An improved fire detection approach based on YOLOv8 for smart cities[J]. Neural Computing and Applications, 2023, 35(28): 20939-20954.
[15]CARVALHO R, MORGADO C A, GONALVES J, et al. Computeraided visual Inspection of glasscoated tableware ceramics for multiclass defect detection[J]. Applied Sciences,2023,13(21): 11708.
[16]王润正. 基于注意力机制的恶意代码同源性研究[D]. 北京: 中国人民公安大学, 2022.
[17]LI Z Y, LI B, NI H J, et al. An effective surface defect classification method based on RepVGG with CBAM attention mechanism (RepVGGCBAM) for aluminum profiles[J]. Metals, 2022, 12(11): 1809.
Research on Accurate Recognition and Positioning of Logistics AGV Based on Improved YOLOv8
YANG Zhenwei, WANG Jun, FU Chaoxing
(College of Mechanical and Electrical Engineering, Qingdao University, Qingdao 266071, China)
Abstract:
Aiming at the low accuracy of the original YOLOv8n0f2b60f8fb9845678348d5f5e4d185570f54d329e9cf7bcc3521c1f29f4b565f algorithm in the identification of Automated Guided Vehicle (AGV) in complex environment,the CBAM attention mechanism was incorporated to establish the CBAMYOLOV8N network model. The model network enhanced the model′s capacity to extract key features. A mathematical model was developed to rectify the positioning accuracy of AGV in the image coordinate system. The results showed that the improvement in recognition accuracy increased by 1.4% and 2.0% for AGV with no load and full load, the combined recognition rate exhibited a 1.7% enhancement. With the correction of image errors, the maximum error values for image coordinates in the uaxis and vaxis directions were 1.3 pixels and 4.3 pixels, the average error values were 0.74 pixels and 2.1 pixels. The localization error of AGV in the coordinate system was reduced, and the localization accuracy was improved.
Keywords:
YOLOv8; automated guided vehicle; attention mechanisms; error correction
收稿日期: 2024-06-05; 修回日期: 2024-07-31
第一作者: 杨振伟(2003-),男,硕士研究生,主要研究方向为图像处理与机器视觉。
通信作者: 符朝兴(1967-),男,博士,副教授,主要研究方向为人工智能和机械振动。Email: cx_f@163.com
