融合文本、语音和表情的多模态情绪识别
2024-11-11谢星宇丁彩琴王宪伦潘东杰








文章编号: 1006-9798(2024)03-0020-11; DOI: 10.13306/j.1006-9798.2024.03.004
摘要:针对情绪识别中信息不全面、易受噪声干扰等问题,基于Transformer网络构建了一种融合文本、视觉和听觉等信息的多模态情感识别网络模型(Bidirectional Encoder Representations from Transformers and Residual Neural Network and Connectionist Temporal Classification and Transformer,BRCTN)。引入人物特征信息辅助情绪识别,提高模型提取关键特征的能力;将单模态情绪识别的输出向量通过模态对齐重组为统一格式;将3个模态和人物特征映射到高维度全局向量空间,学习不同模态特征之间的潜在联系。该模型在IEMOCAP数据集上进行验证,结果表明,与其他方法相比,BRCTN的准确率达87%,识别性能最好。
关键词: Transformer; IEMOCAP; 多模态融合; 情绪识别
中图分类号: TP391.4文献标识码: A
随着GPT和大模型相继出现,多模态情绪识别[1]在人机交互过程中应用,在家庭护理领域中,机器人可以更好地理解情绪,有助于帮助人类缓解压力、解决生活琐事。多模态融合技术可以提供比单一模态更准确细致的情绪识别结果[2]。近年来,研究者尝试使用多种模态信息进行情感分析及判断。辛等[3]使用长短期记忆网络(Long ShortTerm Memory, LSTM)、残差网络(Residual Network , ResNet)等获得了文本与图像的模态表示,通过注意力机制优化了模型的特征融合。范等[4]利用卷积神经网络(Recurrent Neural Network, CNN)和预先训练好的面部表情模型提取相应的声音和视觉特征并进行信息融合和压缩,建立了LSTMRNN (Long ShortTerm Memory and Recurrent Neural Network,长短期记忆网络和循环神经网络)框架对融合后的视觉和听觉特征进行情感识别分析。徐等[5]使用BiLSTMAttention (Bidirectional Long ShortTerm Memory and Attention, 添加注意力机制的双向长短期记忆网络)学习全局和局部情感特征并结合TransformerESIM解决了模型的长距离限制问题。目前模态融合已取得一定进展,但仍存在特征信息提取不全面、模态融合中部分特征信息易丢失等问题。为此,本文在Transformer网络基础上构建了一种多模态情绪识别网络,(Bidirectional Encoder Representations from Transformers and Residual Neural Network and Connectionist Temporal Classification and Transformer)BRCTN网络模型。引入人脸关键点识别模块,利用人物的特征信息辅助情绪识别,提高了模型提取关键特征的能力,弥补了词嵌入对同一词不同含义识别的缺点,解决了识别过程中信号输入不连续导致识别准确度低的问题;为了进一步学习不同模态特征之间的潜在联系,提出了一种多模态向量结构,通过嵌入方式形成融合向量,将不同的情绪特征映射到高维多模态向量空间中,实现了复杂情绪模态输入数据之间的空间与时间建模。
1多模态情绪识别网络框架
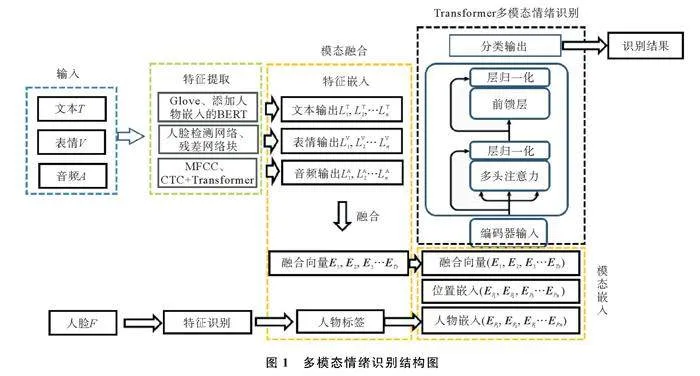
多模态情绪识别网络由特征提取、模态融合和基于Transformer的多模态情绪特征识别组成,框架如图1。在获得情绪特征后,按输出时间不同,标记为向量矩阵L1,L2,…Ln,将三个在连续的时间TS内依次获得的输出依照结果融合为新的融合向量的元素E1,E2,E3…ETS。在Transformer多模态输入前置嵌入部分中,融合向量的每一个元素再与位置、人物进行模态嵌入融合,然后输入Transformer结构中进行特征识别,最终输出情绪识别结果。
1.1特征提取
1.1.1文本特征
由于IEMOCAP[6]数据集中存在大量“a”、“the”等不包含语义的高频词汇,将其剔除以提高运算速度,同时统计单词出现的频率,将出现次数小于5的单词删除,减少不必要的向量建模。确定数据集后,使用Glove进行无监督训练,提取文本特征。定义跳元模型,嵌入层数量设置为20,隐藏层数量设置为4,定义损失函数sigmoid表达式为
f(x)=11+e-x (1)
将网络导入训练模块,学习率设置为0.002,共训练50轮。完成模型训练后,依次输出“快乐”、“悲伤”、“愤怒”、“厌恶”四种典型情绪词云图,如图2。结果表明,四种情绪对应的词云图中出现的近义单词和现实经验相吻合,说明训练获得的Glove 嵌入模型能对情绪词汇之间的联系进行有效建模。
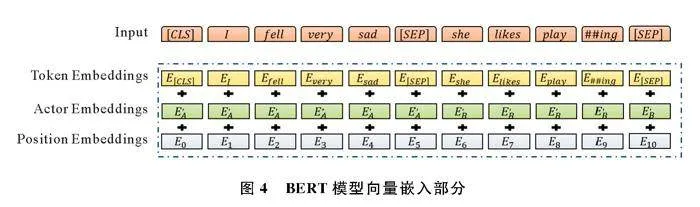
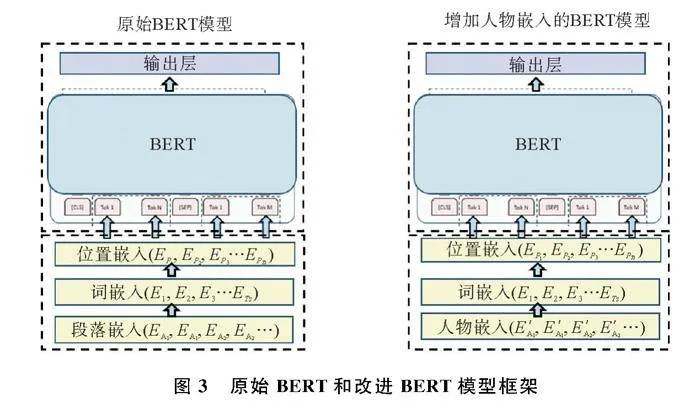
由于一个词在不同的上下文中多次出现,可能有不同的含义,但词嵌入将它视为相同的词。BERT(Bidirectional Encoder Representations from Transformers,双向编码器表征法)通过为同一个词生成多个不同的向量来区分和捕捉不同的语义含义,故在词嵌入后使用BERT提取上下文信息。
人类在自然状态下进行语言表达时常以停顿作为表达的结束,且OCR(语音转文字)识别的结果通常会以零散、断断续续的输入形式传递到下一层,相同文本一次性输入BERT和分批送入BERT的输出结果并不一致。为此,本文模型引入人物嵌入,并按时序综合成人物向量,多条句子组成的人物语言表达在即时场景中不以段落作为分隔,而是取决于对话双方在倾听和讲述中的轮流表达,改进前后的模型框架如图3。文字片段送入Glove中进行编码与词嵌入后通过BERT对相同的词生成不同的向量,便于区分和捕捉不同的语义信息。输出词向量ET会暂存在系统中,当Ts时间段内没有任何输入时,判定识别对象的表达结束,并向存储在系统中的部分发出信号,将内部存储的完整句子输入到下一模块。模型向量嵌入部分如图4,输入向量表示由三个不同的向量求和。
1.1.2视觉特征
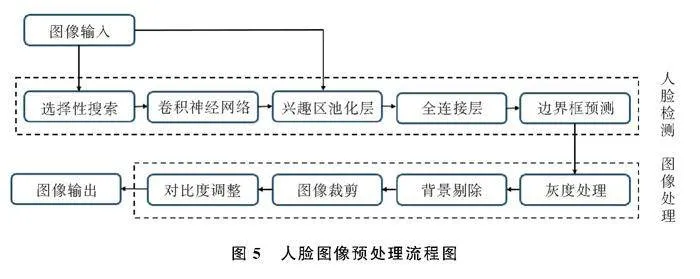
通过设备获取的人脸原始图像存在冗杂像素点、杂物、无关物品等干扰,降低了人脸识别的效率,需要先进行图像预处理,消除图像中的噪声和背景干扰,提取出人脸区域,预处理流程如图5。
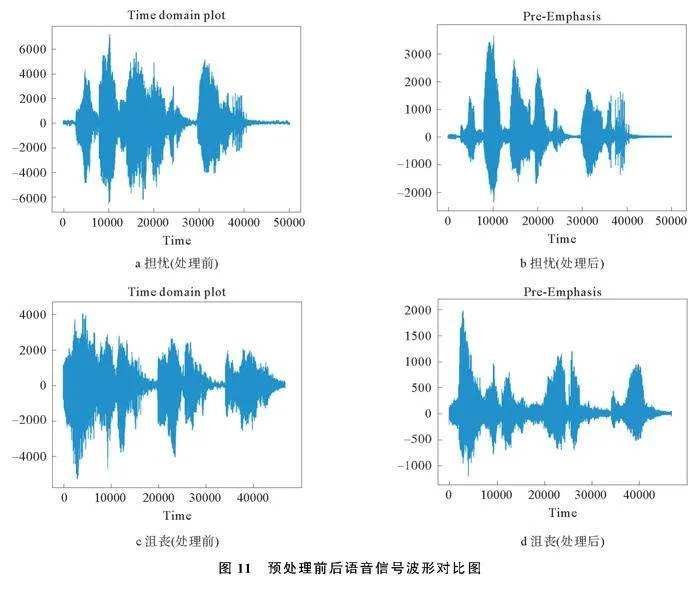
在选择性搜索中,人脸检测算法通过锚框机制从包含人脸的输入部分中提取一定数量的候选区,初步标注这些区域的类别和边界框。本文采用单发多框检测,预测多目标位置类别并在每个预测位置生成多个边界框,多个卷积层预测不同尺度和长宽比的边界框,通过非极大值抑制获得人脸检测的最终结果,如图6。
人脸检测网络由基础层、3个特征层、输出层组成,主要检测是否存在人脸并从原始图像中提取人脸。基础层从输入图像中提取特征,大小为3的输入通道在基础层中处理为16个特征图,逐步翻倍,最终在3层卷积后增加到128,应用最大池化层实现结果输出。3个多尺度特征层均由类别预测、边界框预测和特征块组成。在类别预测层上存在人脸和非人脸两类输出,边界框预测层为矩形框图预测4个边界的偏移量,每个特征块生成的人脸特征图用于生成锚框和预测锚框的类别和偏移量。输出层采用卷积层输出,有效降低模型复杂度,减小计算量。
人脸检测模型的训练数据来自FDDB (Face Detection Data Set and Benchmark)数据集,共包含2 845张图片,内含彩色以及 灰度图,其中的人脸总数达到5 171个,人脸所呈现的状态多样,包括遮挡、罕见姿态、低分辨率以及失焦的情况[7],使用lable_image对其中的人脸进行标注,获得边界框的数据作为人脸检测模型的训练数据。检测结果说明模型能够在复杂和强干扰的环境中准确捕捉到人脸(图7)。
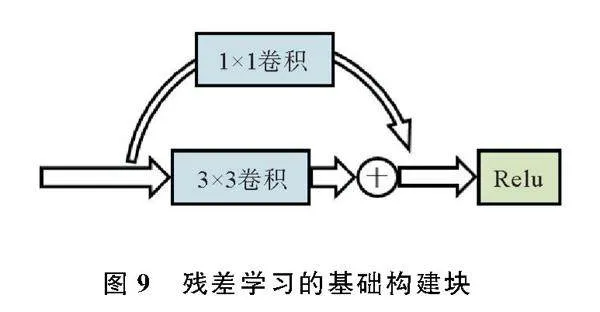
人脸图像预处理常用方法有人脸的搜索与定位、数据增强和人脸归一化等。运用降噪和对比度调整等手段后的效果图(图8)说明预处理后的图像中人脸的微表情和细化特征变得更加明显。预处理后的图像通过现有残差网络中卷积网络进行多层次的特征提取,在输出层输出特征向量,残差块(Residual block)如图9。
1.1.3听觉特征
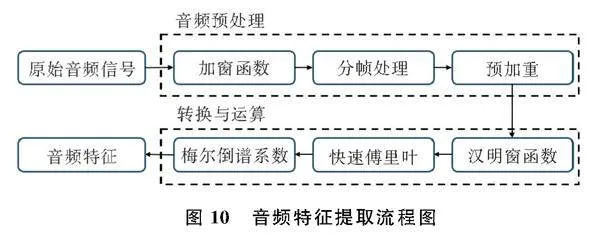
音频录制过程中存在环境杂音、设备等干扰因素,需对原始音频信号进行预加重、分帧、去除空白帧等预处理后,通过快速傅里叶变换和梅尔倒谱系数获得时域、谱域、倒谱域特征等音频特征数据[8],特征提取流程图如图10。
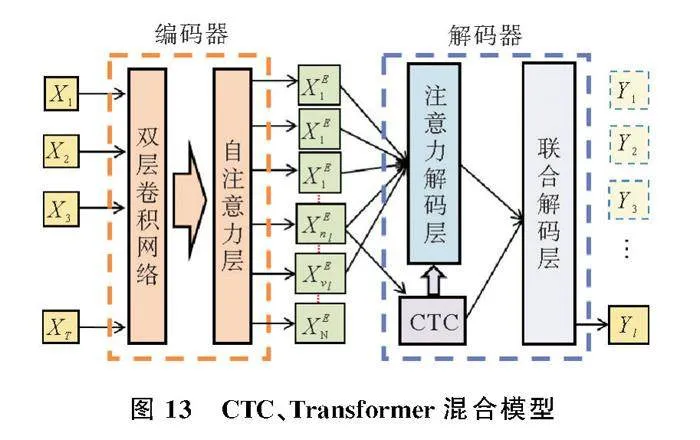
从IEMOCAP数据集中取出担忧、沮丧所对应的一组原始数据,并将音频波形进行可视化处理,结果如图11(a)、(c)。预加重滤波器是通过一阶FIR高通数字滤波器实现的,如式(2)。
H(z)=1-az-1 (2)
通过音频信号的乘法运算,可实现限长的窗函数的平移或转换,加窗后的信号为
sw(n)=s(n)*w(n) (3)
为了最大程度有效保留语音信号变化过程中的信息内容,使用滑动窗,加窗后形成的语音采样序列为
w(n)×s(n)→sw(n)|n=0,1,…,N-1 (4)
经过预处理后的图像信号变得更加平整光滑,清除了噪声和杂乱声波,特征更加突出,如图11(b)、(d)。
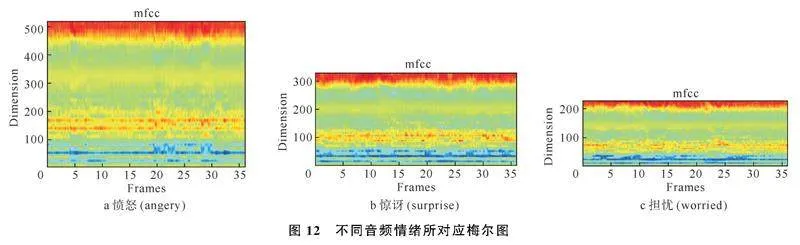
预处理后的音频波形图通过梅尔倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)提取音频情绪对应的梅尔图[9],如图12。不同音频的短时平均能量的差异能够有效区分不同情绪,适合神经网络进行学习、训练与分类的情绪特征类别。
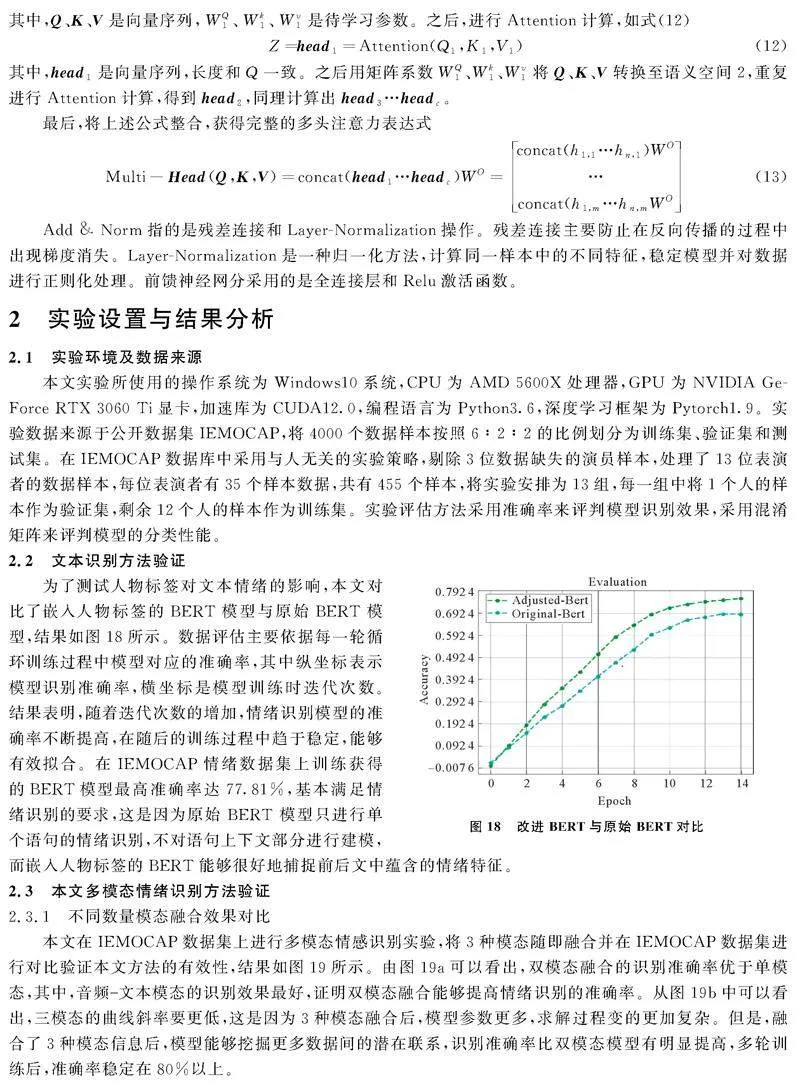
为了更好地获得音频信号前后之间的情绪关联,将Transformer+CTC混合模型实现长距离音频特征的建模,解决输入序列长度不一、难以对齐的问题,模型框架如图13。将获得的波形图和梅尔图归一化,对音频进行二次采样以减少序列长度,然后通过卷积网络处理梅尔图,使用CTC算法实现序列对齐,最终转换为维度为512的嵌入样本。
1.1.4人物特征
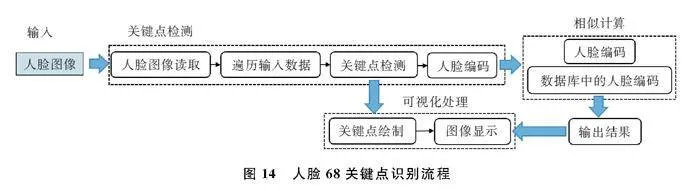
采用基于局部二值模式的人脸识别算法(Local Binary PatternsHistograms, LBPH)[10]对人脸识别中的人脸图像进行关键点识别,识别到的人脸关键点编码后组成的矩阵存储到数据库中,流程图如图14。
该模型识别出不同的人员后,按时间顺序输出包含人物标签的被检测对象人物序列,能够在向量结合时嵌入其中,当再次检测到相似人脸对应的编码后,从数据库中输出对应的人物信息,使情绪识别网络能够更精准地区分识别对象,检测效果如图15。
1.2模态融合
模态融合分为特征嵌入与模态嵌入。在特征嵌入部分,文本、表情和语音特征提取网络的输出部分融合为包含情绪识别结果的多模态特征向量矩阵。在模态嵌入部分,融合向量进一步与位置、人物特征向量融合,最后输入Transformer网络进行识别。
1.2.1特征嵌入
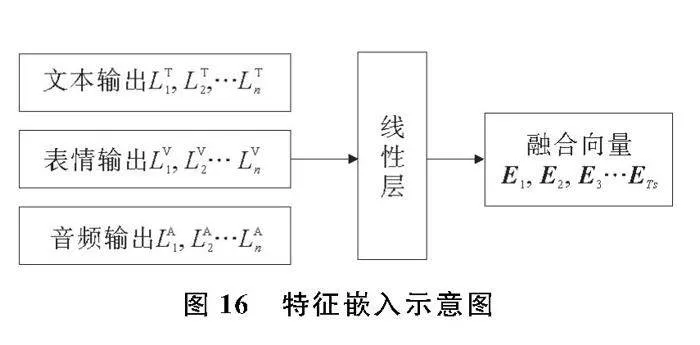
为了充分利用模态之间的跨模态信息和时间关系,将3个模态的信息进行嵌入处理,对于每个模态而言,多个源于单模态的向量融合形成1个多模态向量的过程相当于向量的联合特征表示,如图16。
假设共有来自N个模态的信息,对于每一个单模态信息都使用对应的特征提取方法,经过特征提取网络后,其模态信息转化为输出L1,L2,…Ln。将文本、表情、音频3个模态向1个线性层映射所有的单模态特征,即输出向量维度dn转换为高维度dmodle,最终将3个模态的特征向量都映射到全局特征空间R中。图16中的线性层共有N个,与3个模态的向量相对应,用来转换N个模态的特征向量。
1.2.2模态嵌入
为了从每个模态都能得到一个唯一的embedding,仿照BERT的向量嵌入,将单个模态所有信息进行嵌入处理,称为Eagg。融合特征向量会接收该模态的所有信息,对于每个模态的融合特征向量,首先需要将该部分所有特征做最大池化处理,并将该模态所有突出的特征作为该融合特征的初始值
Eagg=maxpool({E}Kk=1) (5)
融合特征向量的输入特征的序列为
EToken=[E1,E1,…,E1,…,EN,EN,…,EN] (6)
为了有效处理跨模态信息,在模态嵌入部分需要对每一个模态进行位置编码,对模态之间的关系进行有效建模。在位置嵌入部分,通过模态编码的方式,让输入的特征序列具有不同模态之间的区分度。对于N种模态,学习N个位置模态编码{E1,E2,…,EN}来区分不同模态,每个模态位置编码的维度都为dmodle。融合向量的位置模态编码EPosition序列为
EPosition=[E1agg,E11,…,E1K1,…,ENagg,EN1,…,ENKN ;] (7)
与位置嵌入的方式类似,人物嵌入的结构取决于系统在识别时域Ts内捕捉到的不同识别对象,人物嵌入向量编码的维度也为dmodle,在时间范围[t,t+1)上的特征编码为Tt+1。另外,本文设置了两种额外的时间嵌入EAagg和Eunk,分别编码聚合模态特征和未知人物信息特征。人物嵌入结构为:
EActor=[EAagg,EA1,…,EAD,…,EAagg,EA1,…,EAD] (8)
1.2.3多模态特征表示
多模态情感特征融合模型遵循Transformer编码器部分的体系结构,由堆叠的自注意力层和全连接层组成,用来计算多模态特征表示,其输入为一组embedding,均是属于同一维度的特征向量。每一个模态的特征向量都嵌入了特征的语义信息、模态信息以及在视频中提取特征时所对应的时间信息。因此,多模态情感特征Ω(v)被定义为特征嵌入、模态嵌入、时序嵌入的三者之和:
Ωv=EToken+EPosition+EActor=[ω1agg,ω11,…,ω1K1,…,ωNagg,ωN1,…,ωNKN] (9)
1.3多模态情绪识别
多模态情感特征融合模型基于Transformer编码器部分的结构,由自注意力模块(SelfAttention)、前馈神经网络模块两部分组成,结构如图17所示。
编码器负责把自然语言序列输入X映射成为隐藏层C,即含有自然语言序列的数学表达。解码器把隐藏层再映射为自然语言序列Y,从而使语义模型可以解决各种问题。解码器定义了给定上下文编码序列条件下目标序列的条件概率分布,根据贝叶斯法则,在给定上下文编码序列和每个目标变量的所有前驱目标向量的条件下,可将上述分布分解为每个目标向量的条件分布的乘积
pθdec(Y1:m|X-1:n)=∏mi=1pθdec(yi|Y0:i-1,X-1:n) (10)
由于自注意力无法针对多维输入向量进行有效建模,故需要推导出多维注意力机制。由矩阵系数WQ1、Wk1、Wv1替代Q1,K1,V1三个输入向量,并将其映射到语义空间1,如式(11)
Q1=QWQ1=q1WQ1…qmWQ1,K1=KWK1=q1WK1…qmWK1,V1=VWV1=q1WV1…qmWV1 (11)
其中,Q、K、V是向量序列,WQ1、Wk1、Wv1是待学习参数。之后,进行Attention计算,如式(12)
Z=head1=Attention(Q1,K1,V1) (12)
其中,head1是向量序列,长度和Q一致。之后用矩阵系数WQ1、Wk1、Wv1将Q、K、V转换至语义空间2,重复进行Attention计算,得到head2,同理计算出head3…headc。
最后,将上述公式整合,获得完整的多头注意力表达式
Multi-Head(Q,K,V)=concat(head1…headc)WO=concat(h1,1…hn,1)WO…concat(h1,m…hn,mWO (13)
Add & Norm指的是残差连接和LayerNormalization操作。残差连接主要防止在反向传播的过程中出现梯度消失。LayerNormalization是一种归一化方法,计算同一样本中的不同特征,稳定模型并对数据进行正则化处理。前馈神经网分采用的是全连接层和Relu激活函数。
2实验设置与结果分析
2.1实验环境及数据来源
本文实验所使用的操作系统为Windows10系统,CPU为AMD 5600X处理器,GPU为NVIDIA GeForce RTX 3060 Ti显卡,加速库为CUDA12.0,编程语言为Python3.6,深度学习框架为Pytorch1.9。实验数据来源于公开数据集IEMOCAP,将4000个数据样本按照6∶2∶2的比例划分为训练集、验证集和测试集。在IEMOCAP数据库中采用与人无关的实验策略,剔除3位数据缺失的演员样本,处理了13位表演者的数据样本,每位表演者有35个样本数据,共有455个样本,将实验安排为13组,每一组中将1个人的样本作为验证集,剩余12个人的样本作为训练集。实验评估方法采用准确率来评判模型识别效果,采用混淆矩阵来评判模型的分类性能。
2.2文本识别方法验证
为了测试人物标签对文本情绪的影响,本文对比了嵌入人物标签的BERT模型与原始BERT模型,结果如图18所示。数据评估主要依据每一轮循环训练过程中模型对应的准确率,其中纵坐标表示模型识别准确率,横坐标是模型训练时迭代次数。结果表明,随着迭代次数的增加,情绪识别模型的准确率不断提高,在随后的训练过程中趋于稳定,能够有效拟合。在IEMOCAP情绪数据集上训练获得的BERT模型最高准确率达77.81%,基本满足情绪识别的要求,这是因为原始 BERT 模型只进行单个语句的情绪识别,不对语句上下文部分进行建模,而嵌入人物标签的BERT能够很好地捕捉前后文中蕴含的情绪特征。
2.3本文多模态情绪识别方法验证
2.3.1不同数量模态融合效果对比
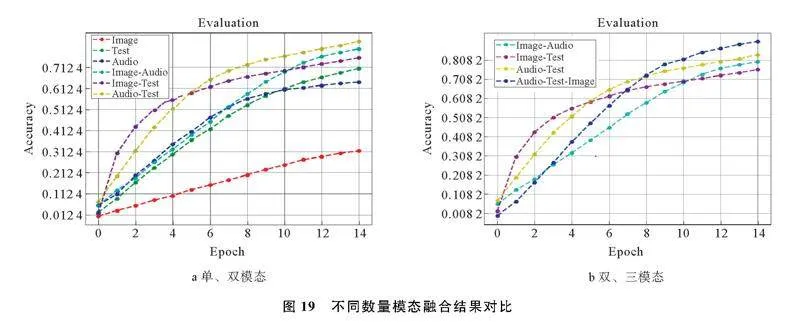
本文在IEMOCAP数据集上进行多模态情感识别实验,将3种模态随即融合并在IEMOCAP数据集进行对比验证本文方法的有效性,结果如图19所示。由图19a可以看出,双模态融合的识别准确率优于单模态,其中,音频-文本模态的识别效果最好,证明双模态融合能够提高情绪识别的准确率。从图19b中可以看出,三模态的曲线斜率要更低,这是因为3种模态融合后,模型参数更多,求解过程变的更加复杂。但是,融合了3种模态信息后,模型能够挖掘更多数据间的潜在联系,识别准确率比双模态模型有明显提高,多轮训练后,准确率稳定在80%以上。
2.3.2与其他方法对比
6种多模态情绪识别方法使用文本、听觉及视觉中2种或3种模态融合,在IEMOCAP数据集上进行验证且所使用数据集标签一致,结果如表1。前5种方法使用“Angry”、“Happy”、“Sad”、“Neutral”4类情感标签,进行了4种常见情绪的实验验证。本文在上述4类常见情绪情感标签基础上增加了“Frustrated”、“Excited”情感标签,共6类情感标签进行验证。由表1可以看出,相较于其他模态识别方法,BRCTN网络模型在IEMOCAP数据集上的识别性能更好,准确率达到87%。
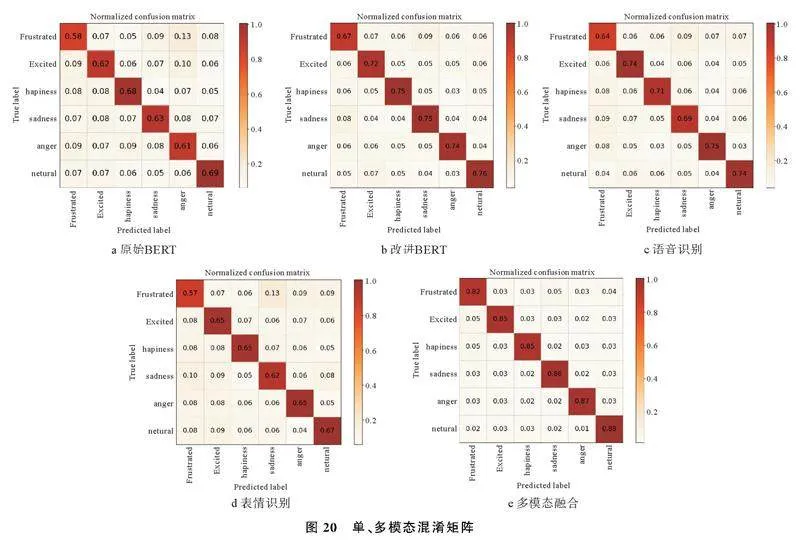
2.3.3消融实验
为进一步验证本文方法的性能,设计了消融实验,通过混淆矩阵展示了6种情绪识别结果,如图20。通过图20 a、b可以看出,改进BERT在IEMOCAP数据集上识别效果相较于原始BERT有明显提高,其中“angry”准确率,提升了13%。从整体来看,使用单模态进行情绪识别效果均不理想,其中表情识别的准确率最差,在70%以下,这是因为基于残差网络的情绪识别结果相互独立,IEMOCAP数据集视频帧内存在的干扰会对识别结果造成较大影响,导致输出的人脸表情识别结果在识别时域Ts内出现波动,致使准确率大幅下降。而BRCTN模型引入了人物特征信息,且在每个模态的特征向量都嵌入了特征的语义信息、模态信息以及在视频中提取特征时所对应的时间信息,能够较精准的识别出各个情绪之间的差别,其准确率达到87%。实验证明了基于融合特征向量和联合损失的改进能够实现对复杂情绪特征之间进行有效建模,提取深层次的情绪特征。
3结论
本文搭建了一种基于Transformer的多模态情绪识别网络模型(BRCTN)。通过引入LBPH的人脸关键点识别模块构造了人物特征识别网络,将人物特征与文本特征结合,提高了模型提取关键特征的能力,解决了识别过程中信号输入不连续导致识别准确度低的问题。使用全新的多模态向量结构,将三个模态和人物特征映射到高维度全局向量空间,进一步学习不同模态特征之间的潜在联系。最后在IEMOCAP数据集上进行验证,结果表明,与目前先进方法相比,BRCTN网络模型准确率有明显提高,具有更好的识别效果。
参考文献
[1]KUMAR P, MALIK S, RAMAN B. Interpretable multimodal emotion recognition using hybrid fusion of speech and image data[J]. Multimedia Tools and Applications, 2024, 83(10): 28373-28394.
[2]吴晓, 牟璇, 刘银华, 等. 一种基于语音、文本和表情的多模态情感识别算法[J]. 西北大学学报(自然科学版), 2024, 54 (2): 177-187.
[3]辛创业. 基于音视频的情绪识别研究[D]. 北京: 北方工业大学, 2020.
[4]范习健, 杨绪兵, 张礼, 等. 一种融合视觉和听觉信息的双模态情感识别算法[J]. 南京大学学报(自然科学), 2021, 57 (2): 309-317.
[5]徐志京, 高姗. 基于TransformerESIM注意力机制的多模态情绪识别[J]. 计算机工程与应用, 2022, 58 (10): 132-138.
[6]BUSSO C, BULUT M, LEE CC, et al. IEMOCAP: Interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42: 335-359.
[7]JAIN V, LEARNEDMILLER E. Fddb: A benchmark for face detection in unconstrained settings[R]. UMass Amherst technical report, 2010.
[8]张强. 网络音频数据分类标注与前处理系统构建[D]. 哈尔滨: 哈尔滨工业大学, 2012.
[9]SIDHU M S, LATIB NA A, SIDHU K K. MFCC in audio signal processing for voice disorder: a review[J]. Multimedia Tools and Applications, 2024: 1-21.
[10]DEEBA F, MEMON H, DHAREJO F A, et al. LBPHbased enhanced realtime face recognition[J]. International Journal of Advanced Computer Science and Applications, 2019, 10(5): 274-280.
[11]MITTAL T, BHATTACHARYA U, CHANDRA R, et al. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues[C]∥AAAI conference on artificial intelligence. 2020, 34(2): 1359-1367.
[12]LE H D, LEE G S, KIM S H, et al. Multilabel multimodal emotion recognition with transformerbased fusion and emotionlevel representation learQXP8NfgyyNReOjdpLK/FW0gKIyvgOdS0uyJ/d82imYU=ning[J]. IEEE Access, 2023, 11: 14742-14751.
[13]MAMIEVA D, ABDUSALOMOV A B, KUTLIMURATOV A, et al. Multimodal emotion detection via attentionbased fusion of extracted facial and speech features[J]. Sensors, 2023, 23(12): 5475.
[14]KHAN M, GUEAIEB W, EL SADDIK A, et al. MSER: Multimodal speech emotion recognition using crossattention with deep fusion[J]. Expert Systems with Applications, 2024, 245: 122946.
[15]HOSSEINI S S, YAMAGHANI M R, POORZAKER ARABANI S. Multimodal modelling of human emotion using sound, image and text fusion[J]. Signal, Image and Video Processing, 2024, 18(1): 71-79.
Multimodal Emotion Recognition Based on Text、Speech and Expression
XIE Xingyu1, DING Caiqin1, WANG Xianlun1,2, PAN Dongjie1
(1. College of Mechanical and Electrical Engineering, Qingdao University of Science and Technology, Qingdao 266061, China;
2. Qingdao Anjie Medical Technology Co., Ltd, Qingdao 266100, China)
Abstract:
To address the issues of incomplete information and susceptibility to noise in emotion recognition, a multimodal emotion recognition network model (Bidirectional Encoder Representations from Transformers, Residual Neural Network and Connectionist Temporal Classification and Transformer, BRCTN) is constructed based on the Transformer network, integrating information from text, visual, and auditory modalities. The model incorporates character feature information to assist emotion recognition, enhancing the model′s ability to extract key features. The output vectors from singlemodal emotion recognition are restructured into a unified format through modality alignment. The three modalities and character features are mapped into a highdimensional global vector space to learn the potential relationships between different modal features. The model was validated on the IEMOCAP dataset, and results showed that, compared to other methods, BRCTN achieved an accuracy of 87%, demonstrating the best recognition performance.
Keywords: Transformer; IEMOCAP; multimodal fusion; emotion recognition
收稿日期: 2024-05-06; 修回日期: 2024-07-20
基金项目: 山东省自然科学基金资助项目(ZR2020MF023)
第一作者: 谢星宇(1997-),男,硕士,主要研究方向为机器人及智能制造技术。
通信作者: 王宪伦(1978-),男,博士,副教授,主要研究方向为机器人及智能制造技术、机械系统智能化设计及虚拟设计、机械加工过程的计算机控制。Email: xlwang@126.com
