我国生猪产业知识图谱构建研究
2024-11-05周峰竹赵刚
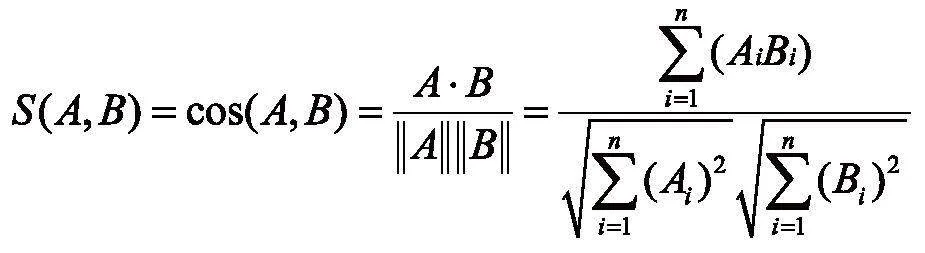





摘 要:针对中国生猪产业链各环节关联性弱、产业数据碎片化、数据类型复杂多样等问题,文章研究设计了基于知识图谱的生猪产业总体架构。通过分析生猪垂直产业领域、本体设计、数据采集、基于语义角色标注与依存句法分析的知识抽取和词典匹配与相似度匹配相结合的知识融合、基于Neo4j数据库的知识存储六个步骤,构建了生猪产业知识图谱,实现了产业链上各孤立环节的应用关联,为产业知识智能检索与智能辅助决策系统构建提供数据基础,助力中国生猪产业数字化建设。
关键词:生猪产业;知识图谱;本体构建;产业链;知识图谱构建
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)16-0136-06
Research on the Construction of Knowledge Graph for Chinese Pig Industry
Abstract: In view of the problems of weak correlation between various links in Chinese pig industry chain, fragmentation of industrial data, and complex and diverse data types, this paper researches and designs the overall architecture of the pig industry based on knowledge graph. Through the six steps of analyzing the vertical industry field of pigs, ontology design, data collection, knowledge extraction based on semantic role annotation and dependency syntax analysis, knowledge fusion combining dictionary matching and similarity matching, and kJLESmAXguEJvGin3ybeRyXCUkdQruMacK/AiWS6vaqI=nowledge storage based on Neo4j database, the knowledge graph of pig industry is constructed. It realizes the application correlation of isolated links in the industrial chain, provides a data basis for intelligent retrieval of industrial knowledge and the construction of intelligent auxiliary decision-making systems, and assists the digital construction of Chinese pig industry.
Keywords: pig industry; knowledge graph; ontology construction; industrial chain; knowledge graph construction
0 引 言
我国生猪产业是农业的重要支柱产业,也是关乎我国民生大计的一大产业,其在我国畜牧产业中长期处于主导地位。中国肉类消费结构以猪肉和鸡肉作为主要消费品种,牛羊肉作为补充品种,其中猪肉消费量占中国总体肉类需求的一半以上。放眼全球,中国是最大的生猪生产国,猪肉产量接近全球猪肉产量的一半,2022年,全球猪肉产量约为1.25亿吨,中国猪肉产量为5 541万吨,在全球猪肉产量中所占比重近一半,约为44.47%[1]。
总的来看,生猪产业链主要由上游饲料加工行业和动物保健行业、中游生猪养殖行业、屠宰加工行业以及下游肉制品加工行业组成。然而在产业链实际运作中涉及多个相互关联阶段的多层面内容,极具复杂性。从参与方角度来看,产业链上有多种不同类型的参与方,包括饲养企业、养殖户、兽医、监管部门、加工厂、运输公司、批发商、职业者等,这些参与方之间往往有着复杂的合作竞争关系。从数据多样性的角度来说,各单元环节数据独立,带来数据来源杂乱、数据结构不一致等问题。生猪产业数据包括养殖环境数据、饲料成分数据、疫苗记录、兽医检查结果、产品质量检测数据等,这些数据缺乏统一的数据库进行收集并整合分析[2]。从外部环境来看,生猪产业受到了许多政策法规的影响,涉及税收政策、贸易政策、环保政策等多个方面,各个环节都需要遵守相应的规定;在风险管理中涉及的因素也众多,包括疫情疫病、市场供需价格波动、质量安全问题、国际贸易政策等,这些因素将对产业链上的各个环节产生影响[3]。
知识图谱技术提供了一种对该产业数据进行结构化存储及智能化处理的方法,将同一领域内的知识进行关联整合,提供全面准确的信息支持。针对上述生猪产业链特点,构建生猪知识图谱将从信息协作共享、智能决策协助以及风险管理预警等方面推动产业转型升级,提出一条数字化赋能新型生猪产业经营体系的实施路径,为生猪产业数字化建设带来新的契机[4]。
1 知识图谱应用现状
知识图谱作为一种以图形化方式表示和组织知识的方法,本质上是一种语义网络,通俗地讲,就是把所有不同种类的信息连接在一起而得到的一个关系网络,其提供了从“关系”的角度去分析问题的能力。从另一个角度来说,它是一种基于图的数据结构,由节点(Point)、边(Edge)和属性(Property)组成。在知识图谱中,每个节点表示现实世界存在的“实体”,每条边为实体与实体之间的“关系”[5]。目前知识图谱主要分为两类,一种是通用型知识图谱,此类型面向通用领域的“结构化的百科知识库”,侧重构建行业常识性的知识,主要用于搜索引擎和推荐系统;另一种为特定领域知识图谱,即垂直知识图谱:面向某一特定领域,可看成是一个“基于语义技术的行业知识库”。通过构建不同行业、企业的知识图谱,对行业企业内部提供知识化服务。本文所要构建的属于领域知识图谱,因此接下来主要讨论后者。
在特定垂直领域深入发展的今天,以知识图谱为技术基础的知识服务颇受重视。王栋等人[6]从数据层、知识抽取、本体模式、知识融合以及知识应用五个层面设计构建以我国甜樱桃产业为主题的行业知识图谱。毛瑞彬等人[7]从产业链角度出发,着重介绍了产业链知识图谱的构建流程与本体设计,并提出了基于领域语言模型的知识分类、抽取和融合算法。丁浩宸[8]通过对基于油茶上中下游全产业链相关数据的收集、分类和整理加工构建了油茶知识图谱并开发了应用系统,实现了智能搜索、知识关联、知识问答等功能。陈恒等人[9]抽取了疾病名称、症状、就诊科室等六类疾病实体及六种相应关系与属性,结合医疗知识资源短缺的行业现状和知识图谱的特点构建了一个基于疾病医疗领域的知识图谱。而本体层作为核心顶层框架,为知识图谱的构建提供了一个清晰的结构和规范的语义。许多等[10]对农业时空进行知识建模,采用自顶向下的构建方法对水稻在施肥、营养失衡和作物农情方面的知识整理分析,构建了涵盖作物、地块、营养三方面,涉及农业领域27个类的精准施肥时空本体模型;Wang等人[11]采用半自动构建方法对柑橘生产知识进行整合,将技术报告和书籍中的文字、表格和图片形式的柑橘生产知识组织并转化为丘陵柑橘施肥和灌溉本体。基于本体,为重庆果农开发了施肥、养分失衡和灌溉排水三种柑橘决策服务。刘桂锋等人[12]依据本体原理,运用本体构建工具Protégé,以国家农业科学数据中心的“棉麻类作物病原真菌病害数据库”和“微生物农药数据库”中的数据为主要数据源,构建了棉花病害防治的知识本体。
2 生猪知识图谱构建设计
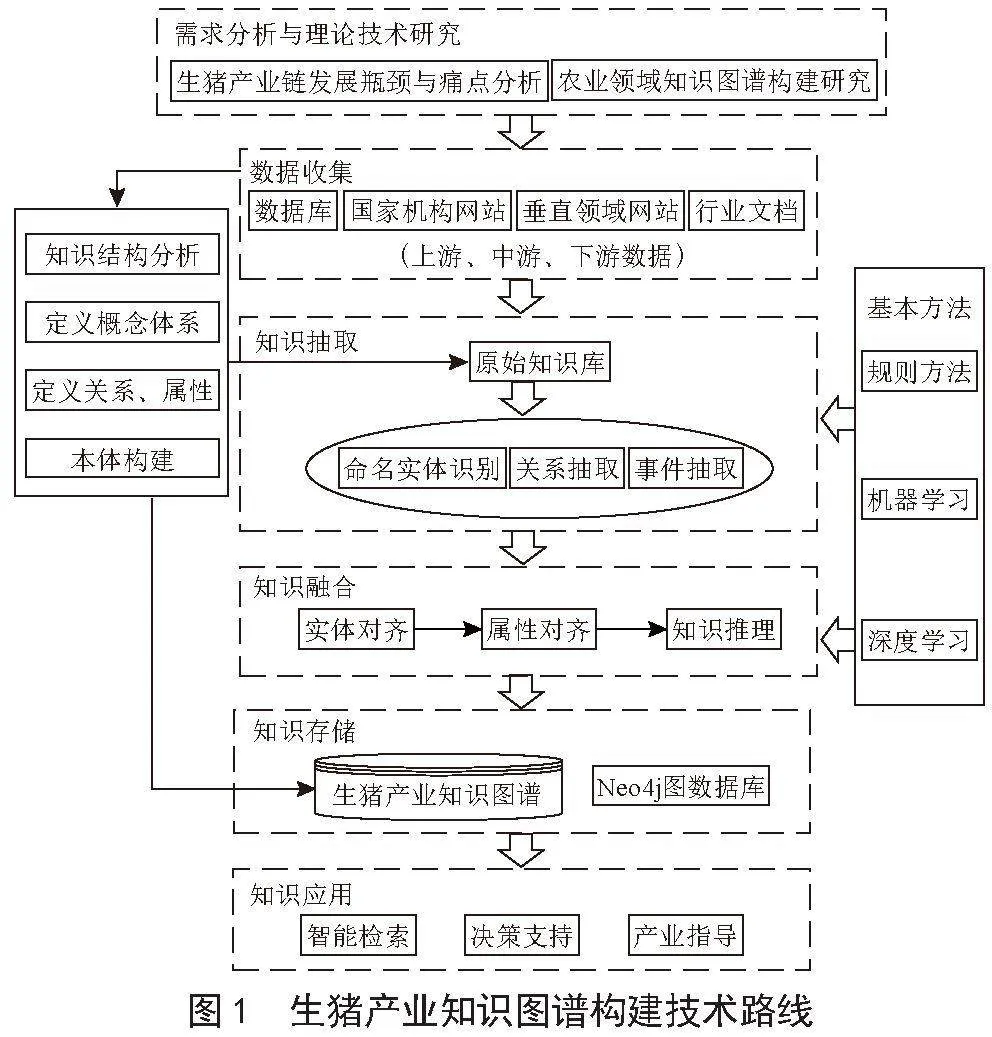
构建生猪知识图谱需综合考虑到全产业链条,包括产业链上游的饲料、动物保健产品、种猪行业,中游的养殖、屠宰加工行业以及下游的销售行业,涵盖环节较多且涉及大量不同来源的数据和知识。由于生猪产业链的多环节复杂性,要有效构建生猪知识图谱,需要获取、整合和清理大量的数据,并解决数据格式、质量和一致性等问题。其次,涉及不同领域的知识需要建立多个知识子图,如何对各个子图进行合理的结构设计和关联建模,保证知识的准确性、完整性和可用性是一大难点。本文选取灵活性较强的方法,自顶向下与自底向上相结合的方式进行构建[13]。一方面依据行业专家经验从最顶层的概念开始构建顶层本体,然后细化概念和关系,形成结构良好的概念层次树;另一方面从开放的多源数据中提取实体、关系、属性等要素,对已构建好的数据层进行概念抽象,进一步完善模式层设计,扩充概念。整体的架构设计如图1所示主要分为五个部分:数据采集层、知识抽取层、知识融合层、知识存储层以及图谱应用层。
2.1 本体构建
构成知识图谱内容的除具体的实例知识外,还包括了对知识数据的描述和定义,即对生猪产业领域知识的高度概括和抽象,通常用概念,概念属性以及概念之间的关系来描述。这部分对数据进行描述和定义的“元”数据被称为知识体系(Schema)或本体(Ontology)。对于采用自顶向下与自底向上相结合的构建方法,首先应构建一个轻量级的知识体系,然后在此基础上进行扩展。由于生猪产业图谱属于垂直特定领域的应用,对知识的精确性要求也较高,因此本文选择人工方式进行本体描述,包括产业链上、中、下游一类的事实性知识以及侧重于对生猪价格波动管理的经验性知识,如供需变化、养殖成本与生猪价格变化之间的关系。初步的生猪产业模式图设计详如图2所示,其中椭圆代表类别概念,矩形与菱形代表概念属性。
2.2 数据采集
根据上文本体层的思路结合对我国生猪产业的分析可知,所需相关数据大致可分为四大类:上游数据、中游数据、下游数据以及围绕“生猪价格”为主题的事件数据。其中,上中下游行业数据按照是否具有独特性可细分为两类,一类是通用的共性数据,如名称、法人、联系电话、办公地址等内容,另一类是各自行业特有的数据,如屠宰加工行业里的“定点屠宰证号”、动保行业中的“规格”“用途”等内容。上述产业数据可通过B2B平台,如“爱采购”“企查查”生猪行业门户网站如“猪易网”“中国生猪网”等渠道进行收集整理。
最后一类事件数据分为三部分,分别是有关管理部门与机构中的政策、文件报告等非结构化数据、诸如“22省市豆粕平均价”的结构化数据以及同样是文本类的非结构化数据:从产业相关论文、期刊以及行业研报中提取出来的与生猪价格波动有关的一系列现象,在本体层中这些现象抽象化分为“供给端现象”“需求端现象”和“其他现象”三大概念。这些事件型数据主要来源于国家统计局、国家发改委、农业农村部等国家相关部门发布的统计数据和文件报告,生猪产业研报、论文期刊以及Wind数据库。
2.3 知识抽取
在知识图谱的构建中,知识抽取是构建生猪产业知识图谱的关键步骤,通过对文本进行深度解析,我们可以提取出丰富的文本信息,以构建具有格式化形式的知识表示,即三元组[头实体,关系,尾实体]。对于中文文本语料语法复杂的情况,毛小丽等[14]提出了基于语义角色标注的知识抽取方法,相较于通过上下文构造特征向量的抽取方式效果有显著提升;郭喜跃等[15]提出了一种句法分析和语义特征相结合的抽取方法,融合了句法依存关系、语义角色标注等原理。本文基于对生猪产业语料的分析,采用语义角色标注与依存句法分析相融合的方式进行三元组抽取。
语义角色标注是一种浅层语义分析技术,该方法以句子为单位,分析句子的谓词-论元结构,不对句子所包含的语义信息进行深入分析。具体来说,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,针对句子中的(核心)谓词来确定其他论元以及其他论元的角色。该方法基于动作施事者A0、受事者A1、时间TMP、地点DOC等语义角色的划分,有效地捕捉到了句子中的主谓宾语。然而,在生猪产业研报中的文本中经常出现多谓词、多宾语的复杂句,为了更全面地获取实体间的关系,在此融合依存句法分析来弥补上述方法的不足。首先基于语义角色标注提取主语和核心谓词后,通过三种不同的句法关系进行事实三元组提取:1)如果存在主语(SBV)和动词的宾语(VOB)关系,那么将提取主谓宾关系的事实三元组;2)如果存在定语(ATT)关系和动宾(VOB)关系,将提取定语后置的事实三元组;3)如果同时存在主谓关系和动补关系(CMP),则提取含有介宾关系的主谓动补关系的事实三元组。
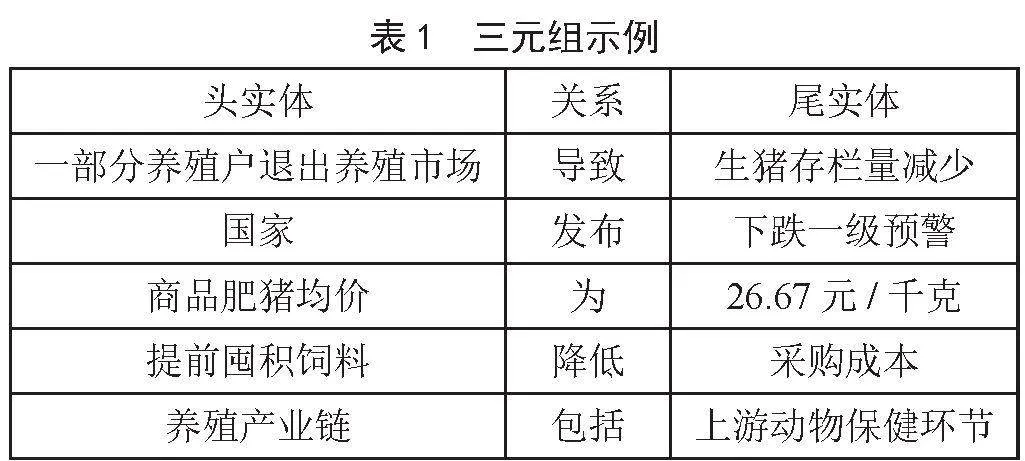
本文从生猪领域垂直网站中爬取得到143段资讯文本,采用哈工大LTP作为自然语言处理工具的核心引擎,通过调用LTP的API接口,将文本数据生成程序中进行处理,得到了句子的分词、词性标注、依存句法分析结果,以及语义角色的划分,最终得到若干条三元组,如表1所示。
另一方面,此方法也存在着一些缺陷,表2是抽取得到的存在错误、冗余信息以及完整性不足的三元组示例。
其中,第一条的原始文本语句是“工人们正快速地完成生猪放血、喷淋清洗、摘除内脏等工序,兽医……”。从这两个三元组可以看出,该方法缺少了对主语、宾语之间并列(COO)关系的依存关系分析。第二条的原始文本语句是“严格执行相关工作人员核酸一天一检,并突出做好检验检疫、消毒、无害化处理和应急管理等工作……”,出现了核心谓词的提取错误,导致三元组的语义紊乱。第三条的原始文本语句为“神农集团相关负责人表示:第三季度断奶仔猪成本是降低的。公司的养殖成本中,仔猪成本是3.82元/千克……”。此三元组的主语缺少完整性,理想情况下应为[神农集团仔猪成本,是,3.82元/千克]。
2.4 知识融合
对构建生猪知识图谱而言,数据来源大多基于海量的非结构化数据,即文本数据,通过知识抽取提取出三元组后获得了最基础的知识单元,但从上一环节获取的三元组由于数据多元化加之语料库重要来源之一的生猪产业研报中各产业分析师表述存在着差异化用词,仍然存在大量冗余、错误、不完整的信息,因此进行知识融合是完善图谱构建不可或缺的一个环节。实体对齐作为知识融合中最重要的子任务之一,在实体层面上从各方面整合数据,找出表示相同含义的实体,对错误信息进行处理从而保证图谱的质量[16]。
本文拟采用基于词典匹配与相似度匹配相结合的方法,首先进行输入实体类型判断,通过构建的命名实体词典进行匹配查询,如匹配成功则将实体名称替换为词典中主名称,否则进入匹配相似度计算。而基于字符串相似度的实体对齐即将字符串形式的文本进行相似度分析并基于此判断实体是否指向相同[17]。值得注意的是,对于数值类型的属性数据,如规格、有效期等需统一处理为描述+数值范围+单位。对剩余类型实体可采用余弦相似度算法,首先进行实体词汇级别的向量化表示[18],然后计算这些实体与同类型实体间的余弦相似度,用向量空间中两向量夹角的余弦值作为衡量两个实体之间差异大小的标准:
式中:A、B表示词向量,n表示向量维度,Ai与Bi表示词向量中的各个分量,余弦值S越接近1,表明两个向量的夹角越接近0度,则两个词向量越相似,两实体语义越接近。反之S越接近0,则两向量越不相似。在此基础上设定一个阈值,若超出此数值即成为融合对象,否则创建新的实体[19]。
2.5 知识存储
完成上述步骤后得到9 194条三元组数据,本文选择采用Neo4j数据库进行存储,具体操作如下[20]:将Excel中的三元组数据转换成CSV格式数据,文件主要为实例与关系两部分。实例文件中包括实体名称、地址、品名等属性,关系文件中包含第一事件和第二事件以及连接事件的具体关系词,如图3、图4所示。
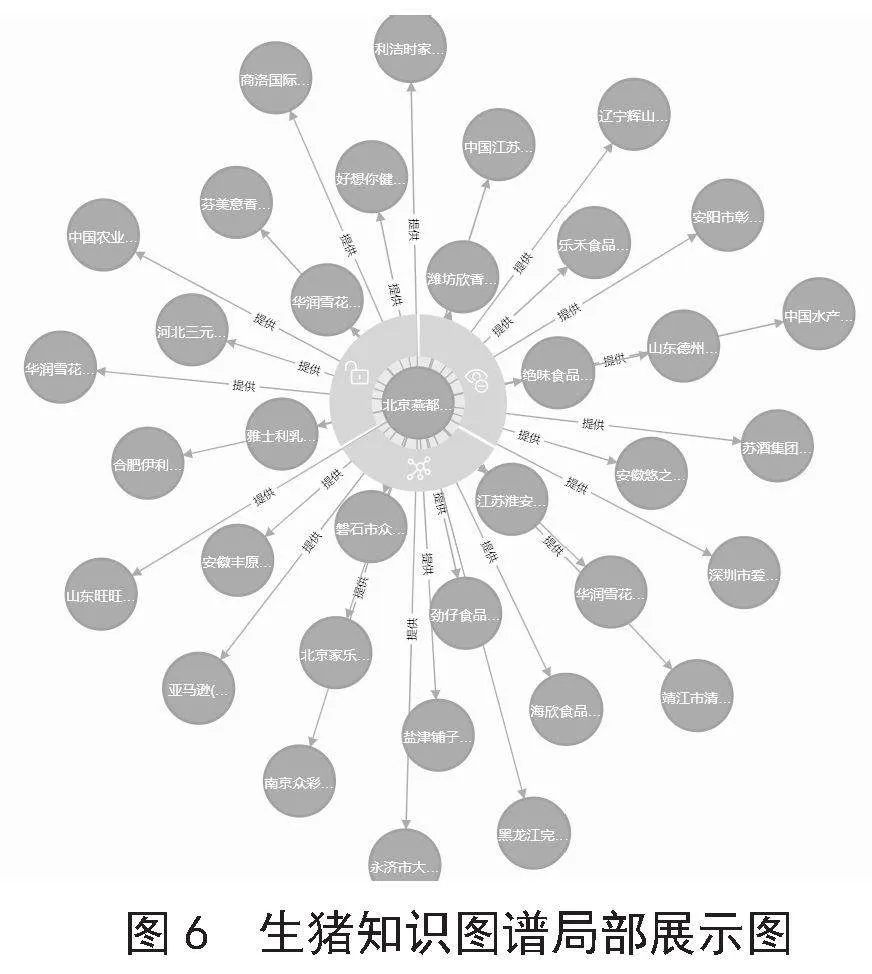
上述两类CSV文件放在Neo4j数据库目录import文件夹中,即可开始导入。如使用Cypher语言可以快速导入实例属性和关系,如图5所示。图6、图7分别为生猪知识图谱局部结构与节点标签展示。
3 结 论
本文通过剖析生猪产业中的问题,面向生猪垂直领域,提出了一套构建该产业知识图谱的方法。从产业发展的角度来看,生猪知识图谱通过行业专家的经验和知识,整合归纳大量产业知识,有助于统一行业认知,解决信息不对称的问题;知识图谱技术在该领域的应用,整合了行业现状、政策法规、市场需求等多方面信息,帮助发现潜在的知识联系和规律;此外,智能化、信息化程度的提高在应对各类产业突发事件时响应速度更快,能够为相关管理部门等提供决策支持,降低决策风险,了解行业现状和需求并发现问题和瓶颈,寻找解决方案和技术突破点,从而推动行业的可持续发展。与此同时,本文还有诸多不足之处,如模式层设计不完善等问题,在后续研究中需对这些问题进一步补充和完善。
参考文献:
[1] 中商情报网.2022年中国肉类产量及市场结构数据分析 [EB/OL].(2023-07-02).https://baijiahao.baidu.com/s?id=1770259179895391828&wfr=spider&for=pc.
[2] 韩智,周法国.基于知识图谱的高铁动车设备检测系统的本体框架构建与维护 [J].现代电子技术,2018,41(6):11-14.
[3] 辛翔飞,王祖力,刘晨阳,等.新阶段我国生猪产业发展形势、问题和对策 [J].农业经济问题,2023(8):4-16.
[4] 陈卫洪,王莹.数字化赋能新型农业经营体系构建研究——“智农通”的实践与启示 [J].农业经济问题,2022(9):86-99.
[5] 黄恒琪,于娟,廖晓,等.知识图谱研究综述 [J].计算机系统应用,2019,28(6):1-12.
[6] 王栋,周菲,李颖芳,等.我国甜樱桃产业知识图谱构建研究 [J].中国果树,2023(1):104-108.
[7] 毛瑞彬,朱菁,李爱文,等.基于自然语言处理的产业链知识图谱构建 [J].情报学报,2022,41(3):287-299.
[8] 丁浩宸.油茶知识图谱构建与应用 [D].北京:中国林业科学研究院,2020.
[9] 陈恒,方洁昊,李正光,等.基于医疗百科网络的疾病医疗知识图谱构建研究 [J].图书情报导刊,2023,8(4):58-65.
[10] 许多,鲁旺平,许瑞清,等.基于农业时空多模态知识图谱的水稻精准施肥决策方法 [J].华中农业大学学报,2023,42(3):281-292.
[11] WANG Y,WANG Y,WANG J,et al. An Ontology-based Approach to Integration of Hilly Citrus Production Knowledge [J].Computers and Electronics in Agriculture,2015,113:24-43.
[12] 刘桂锋,杨倩,刘琼.农业科学数据集的本体构建与可视化研究——以“棉花病害防治”领域为例 [J].情报杂志,2022,41(9):143-149+175.
[13] 刘峤,李杨,段宏,等.知识图谱构建技术综述 [J].计算机研究与发展,2016,53(3):582-600.
[14] 毛小丽,何中市,邢欣来,等.基于语义角色的实体关系抽取 [J].计算机工程,2011,37(17):143-145.
[15] 郭喜跃,何婷婷,胡小华,等.基于句法语义特征的中文实体关系抽取 [J].中文信息学报,2014,28(6):183-189.
[16] 翟娇娇.面向知识图谱构建的知识融合问题研究 [D].济南:齐鲁工业大学,2021.
[17] 杨媛.音乐领域知识图谱构建框架研究 [J].数字图书馆论坛,2022(2):40-46.
[18] 宿恺,潘晨辉.电商领域多模态商品知识图谱构建研究 [J].现代电子技术,2023,46(20):173-177.
[19] 辛辉,谢镇玺,李朋骏,等.面向食品贮藏领域的知识图谱构建方法研究 [J].计算机工程与应用,2023,59(22):329-342.
[20] 赵雪芹,杨一凡,于文静.基于Neo4j图数据库的工程档案知识图谱构建及应用 [J].档案与建设,2022(5):48-51.
