基于数据挖掘的中医特色治疗绩效考核指标研究
2024-11-05陈思萱刘莉莉



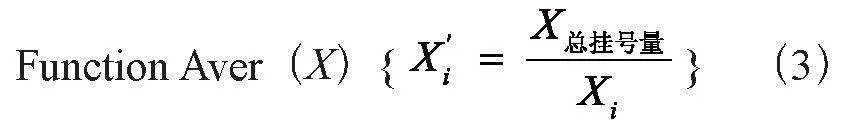
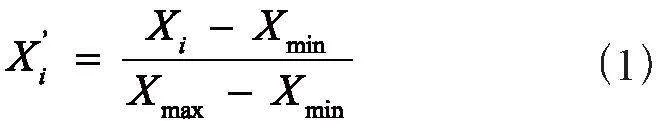
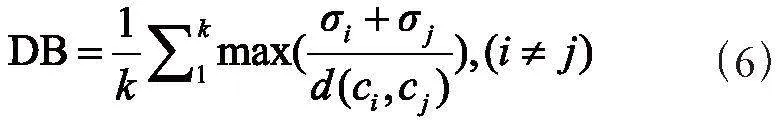

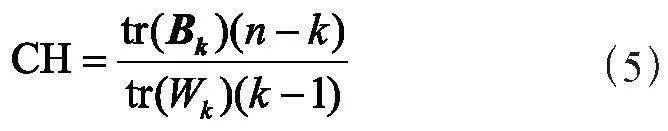

摘 要:基于现行三级公立中医医院绩效考核办法,使用数据挖掘技术对中医特色治疗相关指标进行深入分析。采用无监督学习算法,将中医特色治疗项目数据进行分类,实现对科室绩效考核目标的多维度评价。该研究通过构建CK-means聚类模型,使用三种特征工程方法对中医特色治疗相关指标进行预处理,然后使用优化后的CK-means模型进行无监督的聚类训练。改变传统科室考核划分模式,将全院科室分为5类。根据分类结果,制定并优化更具有中医特色的科室考核方法,为三级中医医院的良好发展提供支持与保障。
关键词:精细化运营;中医特色;聚类算法;绩效考核
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)16-0118-05
Research on Performance Appraisal Indicators of Traditional Chinese Medicine Characteristic Treatment Based on Data Mining
Abstract: Based on the current performance appraisal method for tertiary public Traditional Chinese Medicine hospitals,this paper uses data mining technology to analyze the related indicators of TCM characteristic treatment. In order to achieve multi-dimensional evaluation of department performance appraisal goals, the Unsupervised Learning algorithm is used to classify data on the TCM characteristic treatment projects. The research uses three feature engineering methods to preprocess TCM characteristic treatment related indicators through constructing CK-means clustering model, then uses the improved CK-means model for unsupervised clustering training. It changes the traditional division mode of department assessment and divides the entire departments of the hospital into 5 clusters. Based on the classification results, department assessment methods with more TCM characteristics can be developed and optimized to provide support and guarantee for the good development of tertiary TCM hospitals.
Keywords: refine operation; Traditional Chinese Medicine characteristic treatment; clustering algorithm; performance appraisal
0 引 言
随着我国医疗改革的不断推进,优化和完善医院的绩效考核成为医院管理者着重面对和跟进的工作之一[1]。2019年,国家卫健委组织开展首次全国三级公立医院绩效考核工作,以达到提升三级公立医院总体管理水平和服务质量的目的,进而为人民群众提供更加高效、优质的医疗卫生服务[2]。随后,国家中医药管理局根据《国务院办公厅印发关于加快中医药特色发展若干政策措施的通知》《国务院办公厅关于推动公立医院高质量发展的意见》等政策文件印发《国家三级公立中医医院绩效考核操作手册》[3],旨在通过绩效考核的引导,促进三级公立中医医院临床诊疗和服务能力全面提升,在一定程度上转变三级公立中医医院在医院资源配置、优势学科发展和人才培养等方面的模式,积极为广大人民群众提供优质高效的医疗服务[4]。
目前我国从三级公立中医医院绩效评价66项指标中选取34项监测指标进行分析评价,由医疗质量、运营效率、持续发展、满意度评价4个方面的指标构成[5]。其中包括门诊中药处方比例、门诊散装中药饮片和小包装中药饮片处方比例、门诊患者中药饮片使用率、出院患者中药饮片使用率、门诊患者使用中医非药物疗法比例等独具中医特色的绩效考核指标。本研究使用数据挖掘技术将中医特色治疗考核指标作为变量进行无监督学习训练,得到以中医特色治疗指标为基础的科室划分结果,为医院管理者在科室目标管理决策和绩效考核方面提供参考,制定并优化更具有中医特色的科室考核方法,为三级中医医院的良好发展提供支持与保障。
1 研究方法
随着我国医疗改革的深入推进和医疗信息化建设的快速发展,公立医院的运营压力不断增大,机器学习等人工智能技术被逐渐运用到医院管理决策工作中。
1.1 研究思路框架
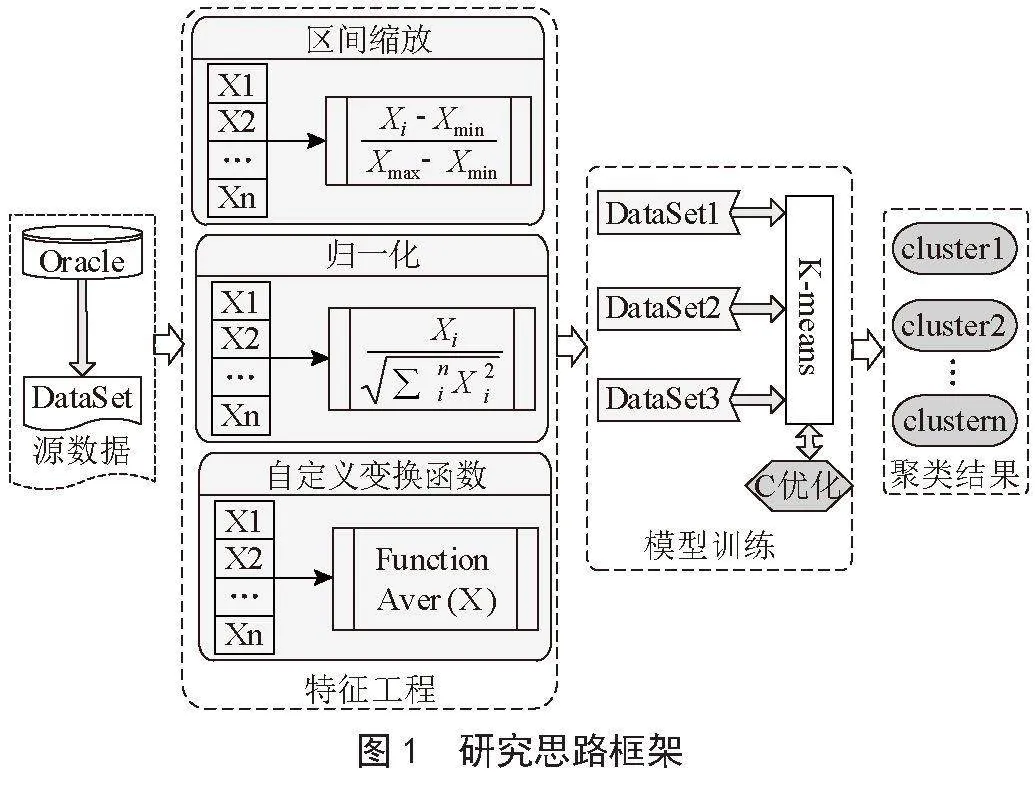
本文首先从HIS抽取中医特色治疗相关数据,然后使用区间缩放、归一化和单变元函数变换三种特征工程方法进行特征处理,最后进行CK-means模型的构建与训练,最终得到最优的科室聚类结果。研究思路框架如图1所示。
1.2 特征工程
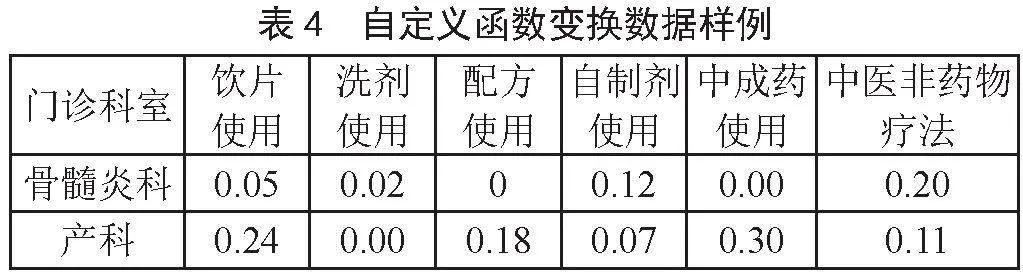
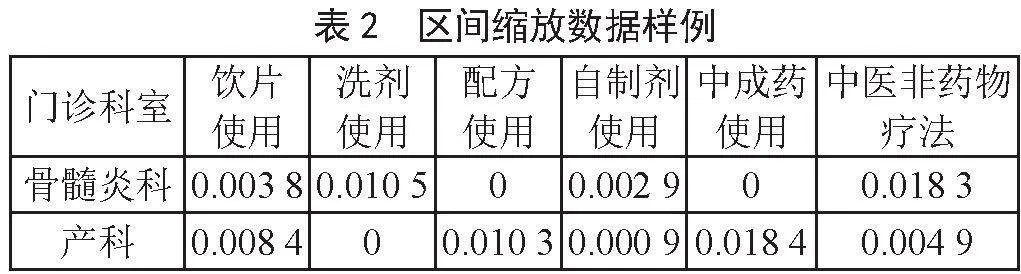
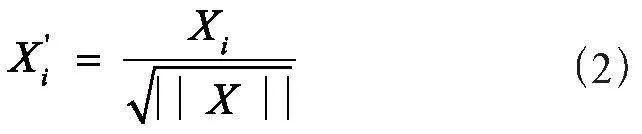
特征工程具体包括:数据清洗、特征选择、特征构造、特征预处理等[6]。由于本文所用到的数据特征已经根据《国家三级公立中医医院绩效考核操作手册》中的中医特色治疗类指标进行选取,同时从HIS中抽取的数据无缺失值,因此本文的特征工程主要研究工作落在特征的无量纲化处理[7],即使用区间缩放[8]、归一化[9]和自定义变换函数进行预处理,计算公式如式(1)至式(3)所示:
其中,Xi为数据特征项,Xmin为该列特征项中的最小值,Xmax为该列最大值。
本文的源数据是依据门诊科室就诊情况进行统计的,每项特征都与科室挂号总量息息相关,因此本文拟在特征工程阶段将源数据进行比重转换。
1.3 模型选择
聚类算法是一种无监督学习的方法,其目的是将数据划分成有意义或有用的簇。它是一种迭代求解的聚类分析算法,与监督学习最大的区别是不需要预先标注好的训练集,通过不断地更新数据到簇中心的距离,得到簇内相似性最大和簇间差异性最大的聚类结果,常见的距离计算方法包括曼哈顿距离[10]、余弦相似性距离[11]、欧氏距离[12]等。K均值(K-means)是聚类算法中最流行的算法模型之一[13],它将数据划分为K簇,直观上看,簇是一组一组聚集在一起测数据,而簇中所有数据的均值被称为该簇的质心。在K-means算法中,核心任务就是根据设定好的簇心k,找出最优的质心,并将离这些质心最近的数据分配到该质心所代表的簇,本文提出的CK-means模型能自动选择最优的超参数,使聚类结果最优。
1.4 模型评估
选取轮廓系数[14]、CH分数[15]和戴维森堡丁指数[16]三项聚类算法常用的模型评估指标对本文CK-means聚类模型进行评估。计算公式如式(4)至式(6)所示:
其中,a(i)计算簇内不相似度,为每个样本到同簇内其他样本点的平均距离,体现凝聚度,b(i)计算簇间不相似度,为每个样本到其他簇平均距离的最小值,体现分离度。
其中,Bk为簇间协方差矩阵,Wk为簇内协方差,tr为矩阵的迹,k为质心个数,n为样本数量。
其中,k为簇的个数,ci为第i个簇的质心,σi为簇i中所有样本到质心的平均距离,cj为第j个簇的质心,σj为簇j中所有样本到质心的平均距离,d(ci,cj)为质心ci和cj质心之间的距离。
2 实验过程分析
2.1 数据描述
本文使用甘肃省某三级甲等中医院2023年1月,95个门诊科室的中医特色治疗数据作为源数据集,使用3种方法对数据进行特征工程处理和模型的训练。源数据包括6个特征,具体特征描述如表1所示。
2.2 特征处理
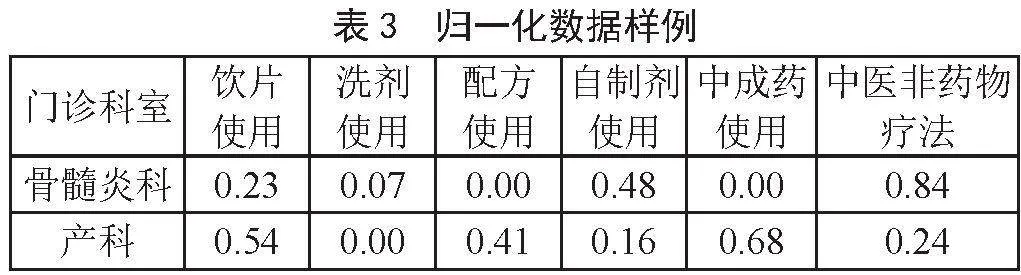
本文在训练模型之前,希望通过特征工程技术,将源数据进行处理,使得处理后的数据集在输入到模型后,使得模型能得到更好的聚类效果。因此使用了1.2小节提出的3种特征工程方法对数据进行预处理,最终得到处理后的部分数据样例如表2至表4所示。
2.3 模型训练及优化
为使本研究基础模型K-means尽可能达到相对理想的训练结果,本文使用优化函数C同步进行模型的训练及优化,使模型能自动得到不同质心下的模型聚类结果,进而得到最优的中医特色治疗科室聚类结果。模型关键步骤如算法1。
算法1:CK-means算法
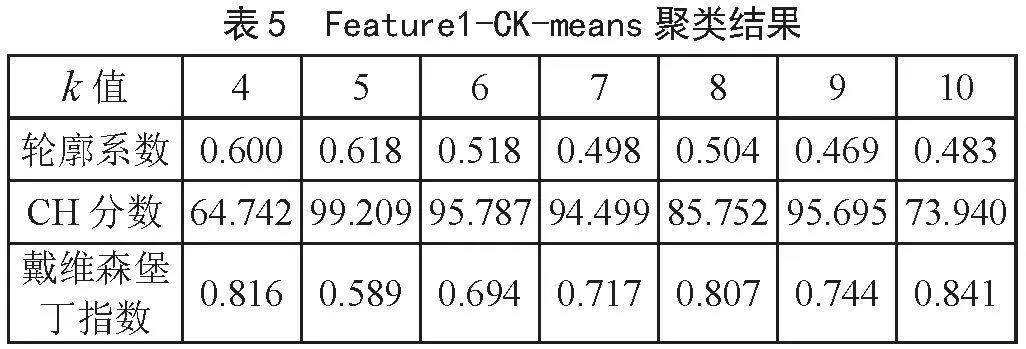
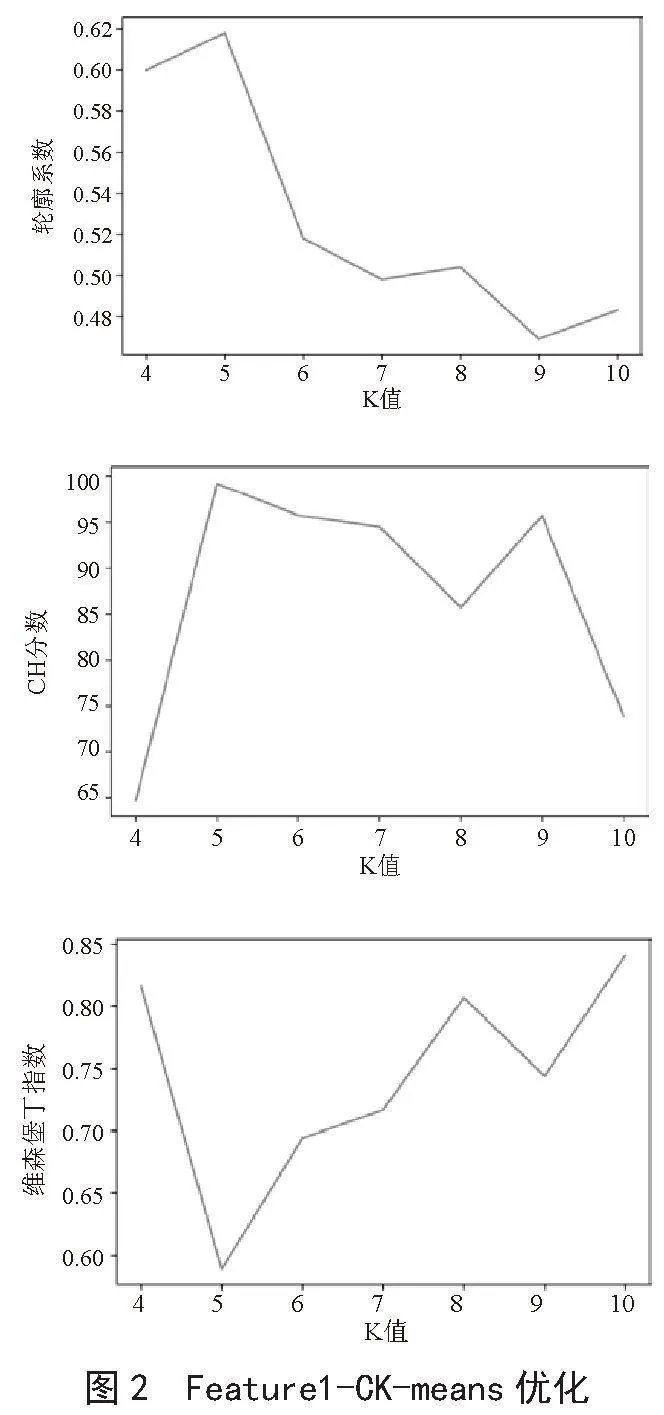
本文使用CK-means算法模型对区间缩放法得到的特征集(Feature1)、归一化得到特征集(Feature2)和自定义函数变换得到的特征集(Feature3)进行训练。训练结果发现特征集(Feature2)在质心k=4时,CK-means模型的轮廓系数和CH分数最大,而在k=9时,戴维森堡丁指数最小。特征集(Feature3)在质心k=4时,CK- means模型的轮廓系数和CH分数最大,而在k=6时,戴维森堡丁指数最小。特征集(Feature1)在质心k=5时,区间缩放法得到的CK-means模型的轮廓系数和CH分数最大,同时戴维森堡丁指数最小,故模型得到最优的聚类结果,最优模型训练结果如图2所示。
由模型优化训练结果可知,在质心k=4时,归一化得到CK-means模型的轮廓系数和CH分数最大,而在k=9时,戴维森堡丁指数最小,因此先保留质心k=4和k=9时构建的模型;在质心k=4时,自定义函数变换得到CK-means模型的轮廓系数和CH分数最大,而在k=6时,戴维森堡丁指数最小,因此先保留质心k=4和k=6时构建的模型进行进一步实验。
3 实验结果
实验一:针对三种特征工程方法,当选取不同的质心时,对模型评价指标进行对比。
实验二:对比三种特征工程方法下CK-means模型的聚类结果,选取每个特征工程方法下的最优质心和最佳的CK-means模型。
3.1 实验一模型对比
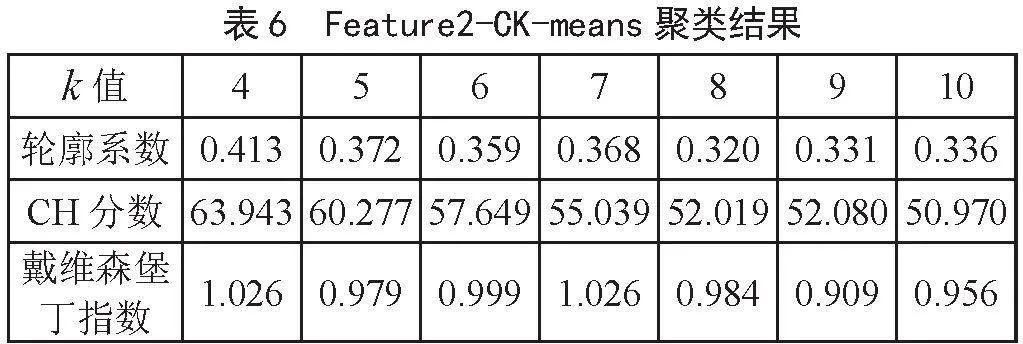
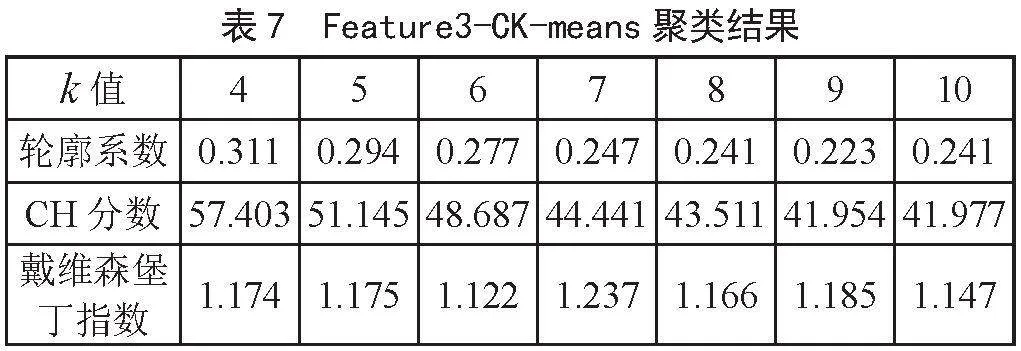
使用三种特征工程方法,依次记录CK-means模型中质心取值在k∈[4,10]时,模型的评价指标,详细内容如表5、表6、表7所示。
由表5可知,当k=5时,CK-means模型轮廓系数为0.618,有较好的聚类结果。由表6知,当k=4时,CK-means模型轮廓系数为0.413,CH分数最大至63.943,有较好的聚类效果。戴维森堡丁指数是在k=9时达到最小值0.909。由表7可知,当k=4时,CK-means模型轮廓系数为0.311,CH分数最大至57.403,戴维森堡丁指数在k=6时呈现最小值1.122。
3.2 实验二模型对比
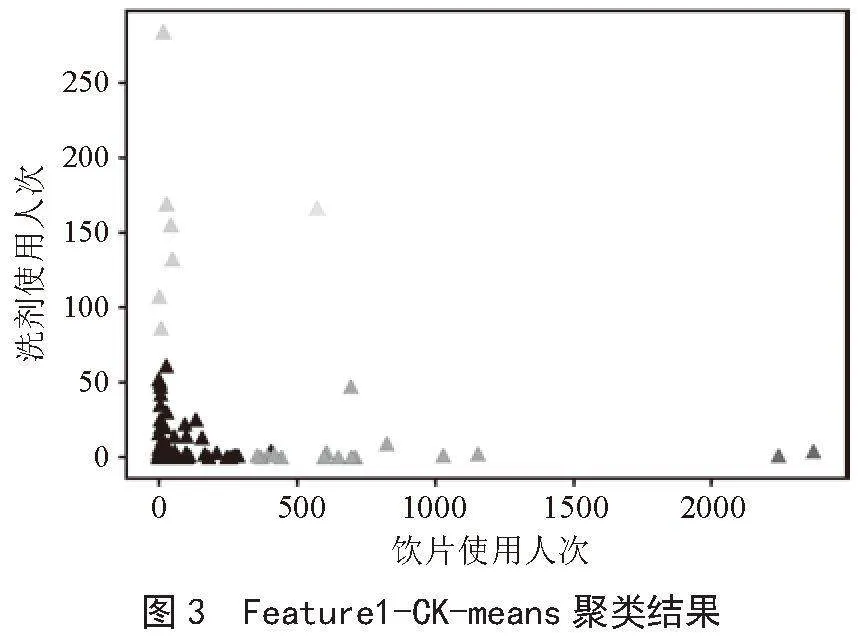
在将区间缩放法得到的数据作为特征集进行模型优化训练时,选取质心k=5时,CK-means优化模型的聚类效果最优,模型聚类结果如图3所以。
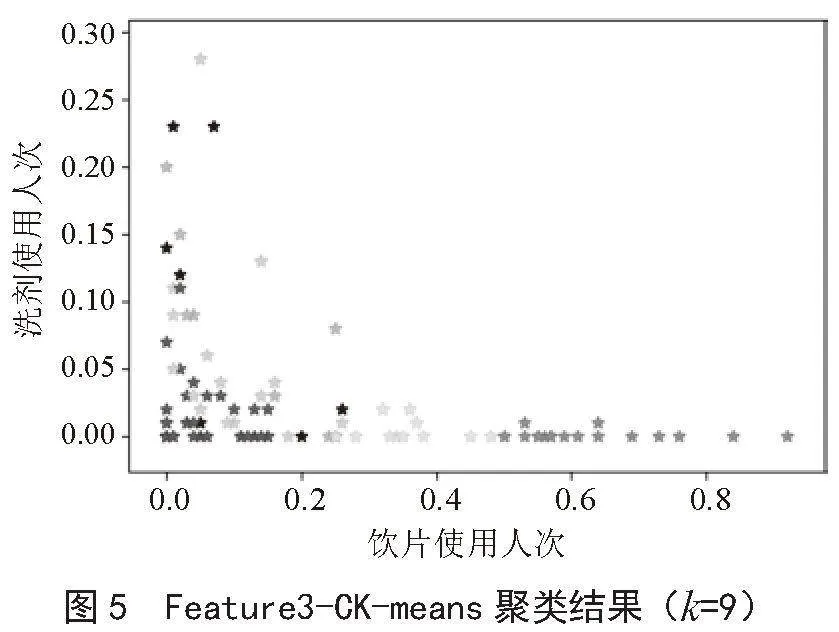
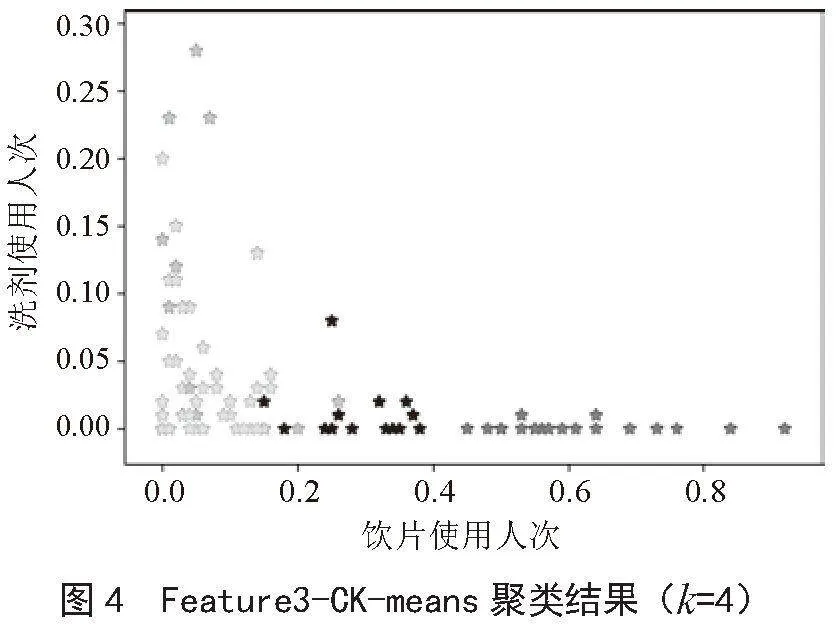
在将归一化方法得到的数据作为特征集进行模型优化训练时,根据2.2小节优化结果,分别将k=4和k=9作为质心进行模型聚类训练,发现当k=4和k=9时模型的聚类结果在散点图中的分布效果均不理想。在将自定义函数方法得到的数据作为特征集进行模型优化训练时,根据2.2小节优化结果,分别将k=4和k=6作为质心进行聚类,结果发现质心k=4时CK-means模型的聚类效果比k=6时的聚类效果好。效果图如图4、图5所示。
综合对比三种方法及不同质心下的模型聚类结果发现,使用区间缩放法作为特征集进行CK-means聚类模型训练时,模型得到的聚类效果是最优。本文研究得到的科室划分结果示例如表8所示。
4 结 论
在本研究中,使用CK-means聚类模型得到最优的科室聚类结果,在医院原有4类科室分类:内科、外科、骨科和其他科室的体系模式下,提出基于中医特色治疗角度的科室划分,将95个科室划分为5类,在医院现行考核管理制度下,给医院管理决策者提供多维度且适用于中医医院的科室分类考核办法,客观的评价科室目标,促进三级公立中医医院绩效考核工作的规范化、标准化和同质化。
数据挖掘技术在中医医院绩效考核方面的应用可以带来广泛的影响和改变,数据挖掘在这一领域的潜在贡献主要包括:
1)定量化和客观化指标:数据挖掘可用于发现和验证客观的绩效考核指标,减少人为因素影响,提高考核的公平性和准确性。
2)预测分析:利用历史数据,数据挖掘可以预测未来的绩效趋势,帮助医院及时调整管理策略,改善服务质量和运营效率。
3)揭示隐性知识:通过分析大量复杂的医疗数据,可以揭示医疗服务、运营管理等方面的深层次规律和关联性,为决策提供科学依据。
4)个性化评估:数据挖掘可以帮助制定更加个性化的绩效考核指标,根据不同科室特点、医生专长等因素调整评估标准。
5)优化资源配置:数据挖掘可用于分析医院资源利用情况,帮助医院更有效地分配人力、物资和财力资源,提高资源使用效率。
6)支持政策制定:数据挖掘分析结果可以用于支持中医医院的政策制定,包括人才培养、科研方向选择、服务项目开发等。
总体而言,数据挖掘的应用能够使中医医院在绩效考核方面实现更加精细化的管理,实现数据驱动的决策支持,为提升整体医疗服务和管理水平提供强有力的支撑。
参考文献:
[1] 段志祥.浅析国家三级公立中医医院的绩效考核 [J].新疆中医药,2022,40(3):91-93.
[2] 国务院办公厅关于加强三级公立医院绩效考核工作的意见 [J].中华人民共和国国务院公报,2019(5):22-30.
[3] 国家中医药管理局.国家中医药管理局综合司关于印发国家三级公立中医医院绩效考核操作手册(2023版)的通知 [EB/OL].[2024-01-08].https://www.huangshan.gov.cn/zwgk/public/6615714/11508466.html.
[4] 吴凌放.改革中的我国医院绩效管理:现况、困境与出路 [J].同济大学学报:社会科学版,2018,29(2):118-124.
[5] 朱静.三级公立中医医院绩效考核背景下病案首页质量控制系统研究与实现 [D].长沙:湖南中医药大学,2022.
[6] 毛德磊.基于特征工程的协同过滤算法研究 [D].重庆:西南大学,2019.
[7] 李兴奇,高晓红.无量纲化方法的有效性评价 [J].统计与决策,2021,37(15):24-28.
[8] 石逸.区间型数据多维标度分析方法研究及应用 [D].厦门:厦门大学,2021.
[9] YU L J,GAO X S. Improve Robustness and Accuracy of Deep Neural Network with L2, Normalization [J].Journal of Systems Science &Complexity,2023,36(1):3-28.
[10] 陶维青,李雪婷,华玉婷,等.基于曼哈顿平均距离和余弦相似度的配网单相接地故障定位 [J].电力工程技术,2023,42(2):130-138.
[11] 郝少璞,刘全,徐平安,等.基于余弦相似度的多模态模仿学习方法 [J].计算机研究与发展,2023,60(6):1358-1372.
[12] 陈奕延,李晔,李存金.一种基于密度峰值的针对模糊混合数据的聚类算法 [J].计算机工程与科学, 2020,42(2):317-324.
[13] 张继孔,刘艳.基于数据挖掘中聚类算法研究与应用 [J].网络安全技术与应用, 2023(12):39-41.
[14] KHALEDIAN E,PANDEY S,KUNDU P,et al. Real-Time Synchrophasor Data Anomaly Detection and Classification Using Isolation Forest, KMeans,and LoOP [J].IEEE Transactions on Smart Grid,2021,12(3):2378-2388.
[15] 邹臣嵩,段桂芹.基于改进K-medoids的聚类质量评价指标研究 [J].计算机系统应用,2019,28(6):235-242.
[16] 黄晓辉,王成,熊李艳,等.一种集成簇内和簇间距离的加权k-means聚类方法 [J].计算机学报,2019,42(12):2836-2848.
