基于Python语言的计算机专业招聘信息的爬取及分析
2024-11-05王彩玲许欣黎












摘 要:文章对计算机专业的招聘信息进行了研究,通过使用Python爬虫定向抓取拉勾网中的各种招聘资料和信息数据,结合职业要求、学历要求等相关基础条件,合理分析某一具体职业的具体状况,并将所得的分析数据结果进行可视化展示。报告了计算机相关专业就业现状,帮助计算机专业学生对未来的就业岗位和对应岗位所需要的专业知识有一个基本的认知,帮助他们有针对性地提高自身的专业能力和综合素养,以培养既懂技术又具备工作能力的复合型计算机人才。
关键词:Python语言;网络爬虫;可视化;招聘信息处理;人才培养
中图分类号:TP311.1;TP312 文献标识码:A 文章编号:2096-4706(2024)16-0088-06
Crawling and Analysis of Recruitment Information of Computer Majors Based on Python Language
Abstract: This paper studies the recruitment information of computer majors, uses Python crawlers to capture various recruitment materials and information data in Lagou.com, and reasonably analyzes the specific situation of a specific occupation in combination with relevant basic conditions such as occupational requirements and educational requirements, and visualizes and displays the results of the analysis data. This paper reports the employment status of computer-related majors, helps students of computer majors have a basic understanding of future employment positions and professional knowledge required for corresponding positions, and helps them improve their professional ability and comprehensive literacy in a targeted manner, so as to cultivate compound computer talents who understand technology and have the ability to work.
Keywords: Python language; Web crawler; visualization; processing of recruitment information; talent development
0 引 言
近几年毕业生人数逐年递增和疫情时期的人才堆积等因素使得我们国家的网络招聘行业高速发展。在这个信息大爆炸的时代,招聘网站各式各样,分类众多,网站上的招聘信息也琳琅满目,如何高效、快速地找到和自身专业对口以及和自身实uukyjKhuubN7Ur/s3ONienxDy+e38LOnCiuH5IJoUxA=力相符合的岗位是一个难题。为了帮助毕业生在众多招聘信息中快速找到自己满意的工作,本文通过Python爬虫爬取招聘网站中的招聘信息并且予以分析。通过对爬取到的招聘信息的整理分析,可以了解行业的岗位信息和职位要求,取得更多有价值的招聘信息。通过对相关信息的对比分析,也可以帮助求职者了解最新的就业情况和整体待遇,从而为求职者提供便利,帮助求职者找到自己心仪的工作。
在早期网络环境下,人们主要通过手动的方式获取所需要的信息,但是这种方式需要耗费大量的人工成本且效率低下,只适用于少量数据的获取。随着网络技术的发展,渐渐出现了一些基于规则的自动化爬虫工具。之后网站技术不断发展和升级,基于规则的自动化爬虫已经无法满足实际的需要。于是出现了一些基于爬虫框架的自动化爬虫工具,这种方式可以更加灵活地处理网站结构的变化,并且还提供了更多的扩展功能。随着机器学习技术的迅速发展,出现了一些基于机器学习的智能爬虫工具,能更加智能化地实现数据的获取和处理。
本文使用Python语言编写程序,在Jupyter Lab平台搭建项目,采用Selenium爬虫框架处理反爬虫,将爬取到的数据进行预处理后保存为csv格式,最后利用Pandas做数据分析与可视化,将工作经验和工资的关系、学历和工资的关系进行分析和图形呈现并给出相关结论,在最后基于所得到的结论得到一些计算机专业人才培养的启示。
1 相关理论和技术介绍
本系统使用Python语言编写程序,在Jupyter Lab平台搭建项目,采用Selenium爬虫框架处理反爬虫,最后利用Pandas做数据分析与可视化,通过直观的图形展示得到的结果。
1.1 爬虫技术
爬虫技术可以按照一定的规则自动地浏览网络中的信息,主要功能是从万维网上下载网页数据并进行分析。爬取到的信息会被爬虫程序保存在本地的数据库中,供之后分析时使用[1],基本步骤如图1所示。
具体分为以下几步:
1)发起请求。爬虫首先需要向目标网站发送HTTP请求,获取网页的内容,可以使用Python中的库,如urllib或request来发送请求。
2)解析网页。获取到网页内容后,爬虫需要解析网页,提取出所需要的数据[2]。可以使用Python中的库,如BeautifulSoup或lxml,来解析HTML或XML格式的网页。
3)数据提取。根据需要,爬虫可以通过选择器或正则表达式等方式,从解析后的网页中提取所需要的数据。可以使用Python中的库XPath来进行数据提取[3]。
4)数据存储。爬虫可以将提取到的数据存储到本地文件或数据库中,以便后续的处理和分析[4]。可以使用Python中的库,如csv或MySQLdb,来进行数据存储。
1.2 常见的反爬虫策略
反爬虫是网站采用的一种技术,用于响应网络爬虫,防止他人批量获取自己网站的信息,保护内容不被他人抓取。本项目跟踪的所有网站均涉及反跟踪技术。常见的反跟踪策略是:
1)请求头校验。反爬虫中最常见,最简单的就是请求头校验。往往Python之类的关键字会在Python库自动生成的请求头中的‘user-agent’包含着。网站会直接拒绝非人工操作的正常用户网站的访问和请求。请求头中的‘referer’等属性也会被一些网站特别注意,所以在创建爬虫时,请求头进行伪装是很有必要的,尤其是“user agent”属性。
2)cookie校验。一些网站会专门检查在访问期间的传输的cookie。上级网页的cookie如果没有被携带,而是直接发起连接到特定的URL,这种情况将会被拒绝访问。
3)IP校验和设备ID校验。当在一定时间内多次使用一个相同的IP访问某个网站时,往往反爬虫机制就会启动,每个设备都提供一个唯一的设备ID,有些网站的反爬虫是会通过验证访问的设备ID来进行的。当遇到这样的网站时,需要伪装设备ID。
4)通过网页动态加载提高爬取门槛。静态网站上所有的信息可以通过一个简单请求就得到,爬虫工程师会花费更多的精力在动态页面加载的页面分析上。爬取网站的时候有难易之分,许多网站都会隐藏信息在通过登录的时候来提高爬取的难度,并且仅对登录的用户可见。
5)反爬虫算法。网站会使用一些反爬虫算法,如动态生成的隐藏字段、加密数据、异步加载等,来增加爬虫程序获取信息的难度。
1.3 Selenium爬虫框架
Selenium是一个用于自动化浏览器操作的开源框架,可以实现模拟用户在浏览器中的操作,比如点击、填写表单、滚动页面等[5]。它可以用于多种用途,包括自动化测试、数据爬取和网页内容提取等。Selenium爬虫框架就是利用Selenium进行网页内容抓取的一种方法,通过模拟浏览器操作获取网页数据,并进一步处理和提取所需内容。在浏览器中Selenium可直接运行测试,模拟人工操作,它支持Safari,Google Chrome等浏览器,对Web应用程序系统而言是完整的,还可以获取浏览器当前呈现的页面源码,解决动态渲染网页的数据抓取,做到可见及可爬,爬虫中主要用来解决JavaScript渲染问题[6-7]。
1.4 Pandas
Pandas是一个Python数据分析包,最开始是作为金融数据分析工具开发的。Pandas是一个基于NumPy的工具,方便解决数据分析。Pandas融合了大量的库和一些标准的数据模型,提供了操作大型数据集需要的工具以及大量地处理数据的函数和方法[8-9]。Pandas是使Python强大而高效的数据分析的重要因素之一。
Pandas填补了用Python进行数据分析和建模的空白,让开发者可以用Python执行整个数据分析工作流程。Pandas库在数据分析中的应用主要包括两个步骤:第一步是读取文件,第二步是数据清洗和编辑工作。我们经常需要使用numpy数组来处理数据。
Pandas的主要特点包括:
1)数据结构灵活。Pandas的数据结构能够适应多种数据类型,并允许灵活的数据操作[10]。
2)数据清洗和预处理。Pandas提供了丰富的功能来处理缺失值、重复值和异常值,以便进行数据清洗和预处理。
3)数据合并和连接。Pandas能够方便地将不同来源的数据进行合并和连接,支持多种数据结构的组合操作。
4)数据分析和统计。Pandas提供了丰富的数据分析和统计功能,包括描述统计、分组聚合、时间序列分析等。
1.5 可视化技术
数据可视化(Data Visualization)是指通过图形、图表、地图等形式将数据以视觉化的方式呈现出来,以便更好地理解和分析数据[11-12]。数据可视化可以直观地发现数据中隐藏的规律,察觉到变量之间的互动关系,可以帮助更好地解释现象,做到一图胜千文的说明效果。常见的数据可视化库如下:
1)Matplotlib是最常见的二维库,可以算作可视化的必备技能库,由于Matplotlib是比较底层的库,api很多,代码学起来不太容易。
2)Seaborn是建构于Matplotlib基础上,能满足绝大多数可视化需求。更特殊的需求还是需要学习Matplotlib。
3)PyEcharts上面的两个库都是静态的可视化库,而PyEcharts有很好的Web兼容性,可以做到可视化的动态效果。
4)Plotly是一个用于创建交互式数据可视化的库,可生成优秀的图表和仪表板。
2 系统的详细设计与实现
对拉勾网网站进行爬取,爬取的数据包括工作职位、工作地点与时间、工作薪酬与要求、公司简介、工作内容、工作经验、学历要求、公司名字、公司类型、技能要求。此外还对项目的爬虫业务、数据存储等功能模块实现用到的算法进行介绍。
2.1 数据结构的实现
在爬取数据之前我们需要定义要爬取的数据字段。根据网页显示的招聘信息,明确该爬虫项目所要爬取的信息职位、地点与时间、薪酬与要求、公司、公司简介、工作内容。Pandas DataFrame是带有标签轴(行和列)的二维大小可变的,可能是异构的表格数据结构。算术运算在行和列标签上对齐,这是Pandas的主要数据结构,Columns的列标签定义如下:
columns = ['职位','地点-时间','薪酬-要求','公司','公司简介','工作内容','工作待遇'] 定义临时保存的列名(csv格式数据),后面数据分析(Pandas)再做对应数据预处理。
2.2 爬虫业务的实现
爬虫项目要做的事有两件:定义抓取招聘网站的动作和分析爬取下来的网页[13]。在爬虫项目中,抓取网站的链接配置、抓取逻辑、解析逻辑的相关代码如下:
3 数据分析及可视化
对爬取到的招聘信息分析与可视化,首先导入所需模块,直接利用Pandas中的可视化模块进行可视化,接着进行数据预处理,最后将数据进行可视化展示,将工作地点与平均工资的关系、学历与平均工资的关系进行图标展示,最后将公司类型和技能标签利用词云图来进行可视化展示。
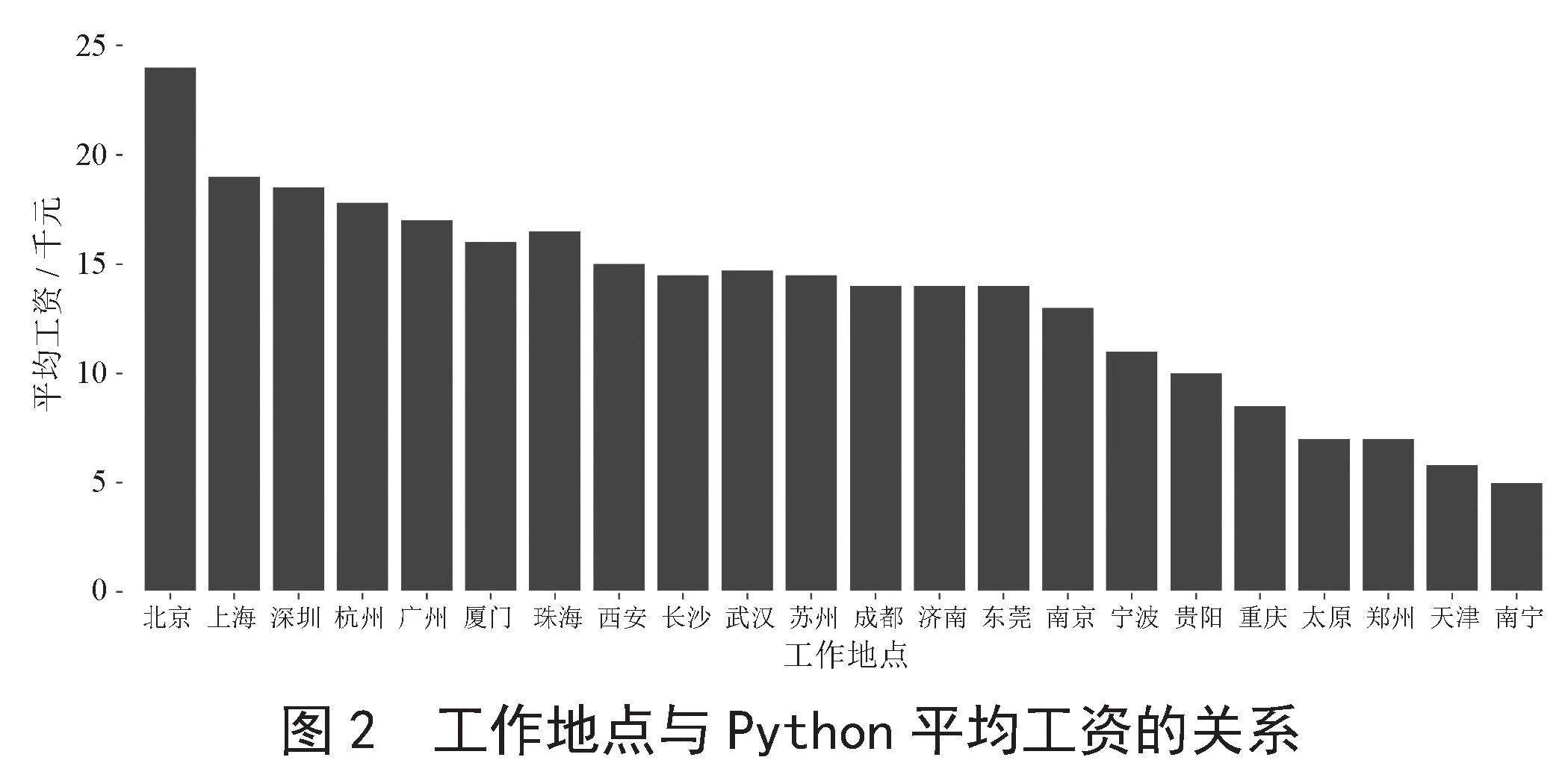
3.1 工作地点与平均工资的关系可视化
相关代码实现如下:
如图2所示,可以看出Python的平均工资普遍不低,如果想寻找有关Python高工资的工作可以去北京、上海、深圳、杭州和广州这些城市,工资都在一万五千元以上。
3.2 学历与平均工资的关系可视化
相关代码实现如下:
如图3所示,可以看出学历越高,Python职位的平均工资也随之越高,故学历越高,薪资的起点就越高。
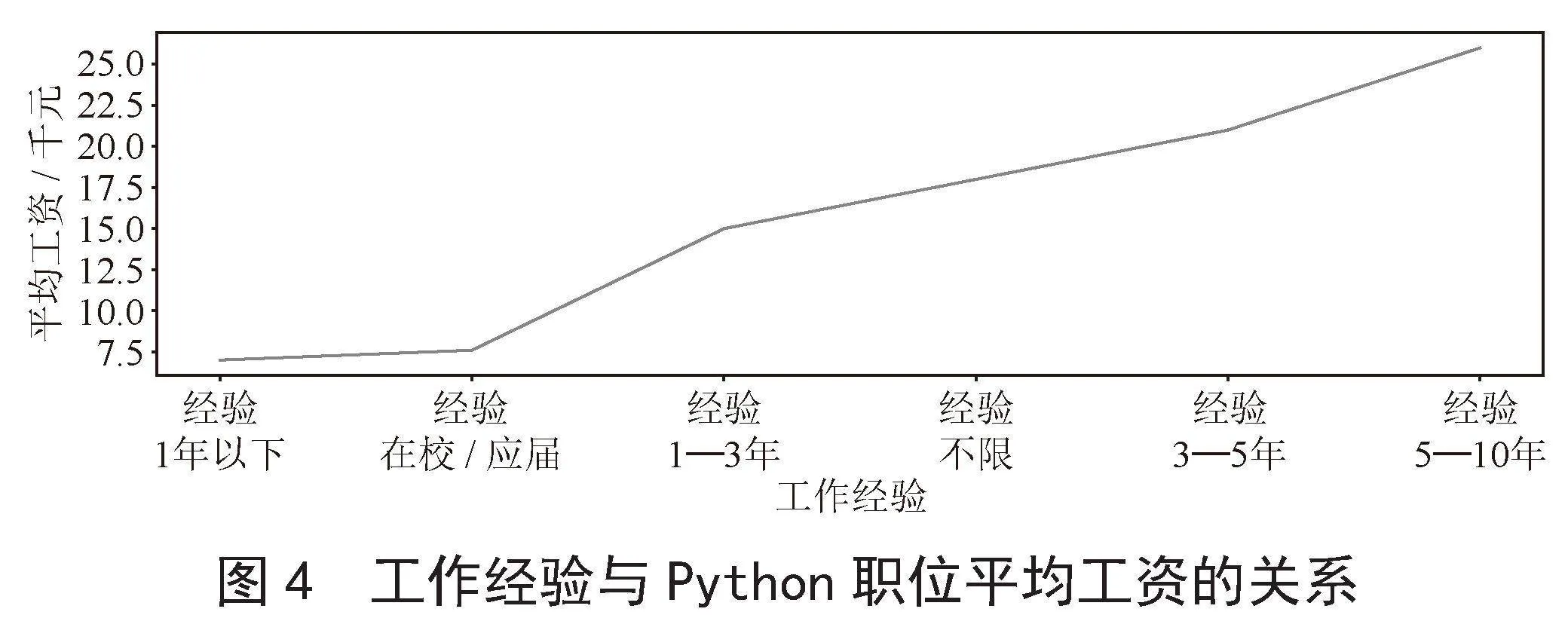
3.3 工作经验与平均工资的关系可视化
相关代码实现如下:
如图4所示,随着工作经验的增加,Python职位的平均工资也在逐年增加。
3.4 词云图
词云图是文本挖掘中用来表征词频的数据可视化图像,通过它可以很直观地展现文本数据中地高频词。
相关代码实现如下:
如图5所示,可以看出虽然Python涉及的公司类型非常丰富,但主要还是以计算机行业为主,其次就是教育和信息咨询行业。rRMpftAZiHKWWshIy4dkhg==
相关代码实现如下:
如图6所示,分析得出与Python有关的技能大多为数据结构、人工智能、数据库和爬虫这些技术。
4 计算机专业人才培养的启示
随着数字经济的发展,社会对计算机专业人才的需求越来越大[14]。针对计算机专业的人才培养,学生不仅需要了解专业知识,还需要对就业形势和就业岗位薪资等信息有一定的了解。
4.1 引入行业导向课程
在专业课程设置上,学校可以添加数据结构、数据库和Linux等课程,这些课程可以帮助培养综合性但具有针对性的计算机专业人才,满足计算机岗位不同职业的需求,掌握这些技术在寻找相关工作时会比较有竞争优势。学校还应定期组织计算机专业的行业研讨会,邀请行业内的专家学者和从业人员来分享最新的技术发展、行业趋势、典型案例等内容,帮助学生了解行业动态。
4.2 加强社会实践
大部分与Python有关的岗位都需要具备相关的开发经验,大部分学校都会组织学生到相关单位和部门进行参观和学习。通过这种方式,学生可以将课堂中学到的知识应用到实际工作中,提高计算机专业学生的实际操作能力和解决问题的能力。参加社会实践还可以帮助学生建立职业素养,培养学生的团队合作能力,在社会实践过程中,学生可以接触到真正的工作环境和项目需求,能更加清晰地了解行业的发展趋势、技术要求和就业前景,有助于调整学习方向和个人发展规划[15]。
5 结 论
本文研究的内容是基于Python语言的计算机相关专业招聘信息的爬取与分析和计算机专业的人才培养。在本篇论文中,对系统的各个功能模块进行了测试并结合可视化图标给出了数据的分析和总结,最终得出了相关结论,即计算机行业的工作地点主要集中在北京、上海、深圳这些发达城市,学历高低和工资高低成正相关等。在岗位需求对人才培养的启示方面,根据计算机专业的岗位需求对高校提出课程和社会实践方面的建议,以满足复合型的人才培养需求,推动社会信息化进程,促进经济和科技的创新发展。作为计算机专业的学生,需要建立扎实的基础知识,根据行业需求提高综合能力。
参考文献:
[1] 冯清.基于Python的基因表达数据网络爬虫研究与设计 [D].太原:山西医科大学,2017.
[2] 孙冰.基于Python的多线程网络爬虫的设计与实现 [J].网络安全技术与应用,2018(4):38-39.
[3] 吴永聪.浅谈Python爬虫技术的网页数据抓取与分析 [J].计算机时代,2019(8):94-96.
[4] 李瑞科.基于自然语言处理的安全漏洞库的设计与实现 [D].西安:西安电子科技大学,2020.
[5] 文婉莹.基于爬虫技术的烟草行业网络舆情监控系统的设计与实现 [D].郑州:郑州大学,2018.
[6] 张隆涛.WEB注入漏洞检测方法的研究与实现 [D].西安:西安科技大学,2019.
[7] 韩进宾.面向应用商店的主题爬虫设计与实现 [D].南京:东南大学,2018.
