基于机器学习的膀胱癌患者生存预测模型研究
2024-11-05方昱衡李泽伟许迎盈李功利李科
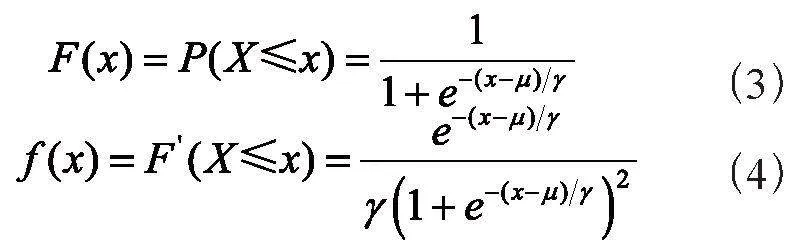
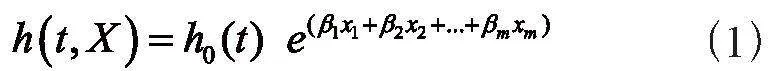
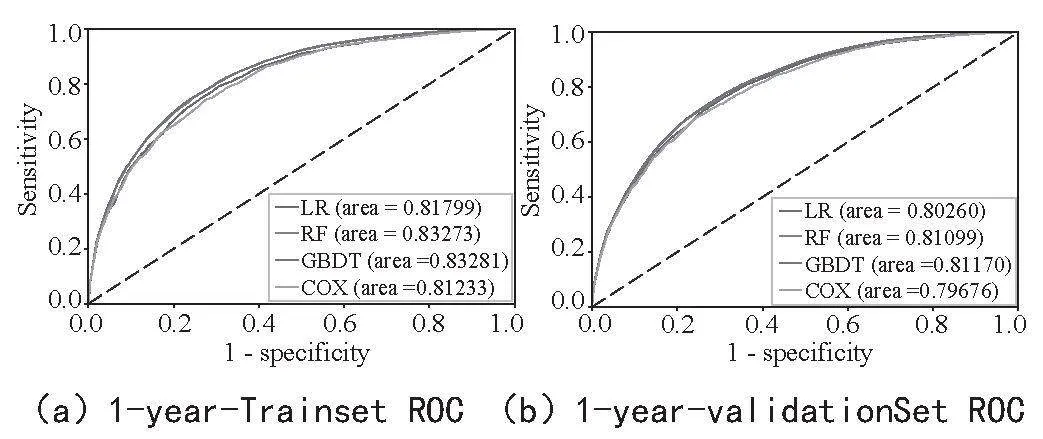
摘 要:该研究旨在构建基于机器学习的生存预测模型,预测膀胱癌(BC)1、3和5年生存率,帮助医生准确识别预后较差的患者,并辅助临床预后方案制定。从监测、流行病学和最终结果(SEER)数据库中获取患者数据,基于逻辑回归(LR)、随机森林(RF)和梯度提升决策树(GBDT)和Cox比例风险模型(Cox proportional hazards)构建生存预测模型,通过在训练集和验证集中使用受试者工作特征曲线和校准度曲线评估模型性能。实验结果表明,GBDT在BC患者1、3和5年生存率预测方面具有较高的区分度和校准度。
关键词:膀胱癌;生存预测;机器学习;COX回归
中图分类号:TP181;TP391.41 文献标识码:A 文章编号:2096-4706(2024)16-0083-05
Research on Survival Prediction Model of Bladder Cancer Patients Based on Machine Learning
Abstract: This research focuses on constructing a survival prediction model based on Machine Learning to predict the 1-year, 3-year, and 5-year survival rates for patients with Bladder Cancer, aid clinicians in accurately identifying patients with poor prognosis and assist in formulating clinical prognosis plans. Patient data is obtained from the Surveillance, Epidemiology, and End Results (SEER) database. The survival prediction model is constructed based on Logistic Regression (LR), Random Forest (RF), Gradient Boosting Decision Tree (GBDT), and the Cox proportional hazards model. The performance of the model is evaluated using the receiver operating characteristic curve and calibration curve on the training and validation sets. The experimental results demonstrate that GBDT exhibits high discrimination and good calibration in predicting the 1-year, 3-year, and 5-year survival rates for BC patients.
Keywords: bladder cancer; survival prediction; Machine Learning; COX regression
0 引 言
在全球范围内,膀胱癌是第十大常见癌症和第13大癌症相关死亡原因[1],每年有近54.9万例新发病例和20万例死亡。尽管有多种治疗方式,BC患者的生存率仍然很低。因此,建立准确的BC患者总生存期的预后模型非常重要[2]。
BC患者生存预测的传统方法基于临床指标和社会人口学因子,使用Cox比例风险回归分析方法构建列线图[2-4]。基于树的机器学习预测方法,如决策树和随机森林,具有易用性、可解释性和防止过拟合的特性[5],可用于医学预测模型开发。
因此,本研究旨在构建基于机器学习的生存预测模型,预测膀胱癌1、3和5年生存率,分析最优临床预测模型方法,帮助医生准确识别预后较差的患者。
1 数据与特征
1.1 数据预处理
我们回顾性地从监测、流行病学和最终结果(Surveillance,Epidemiology, and End Results, SEER)数据库中获取数据,收集了2004年至2015年间诊断的200 216例原发性BC患者,使用了SEER*Stat(版本8.4.1)提取数据、选择案例和定义变量。
分析变量的编码方案如下,年龄分为<60岁、60~69岁、70~79岁、80+岁;种族分为黑人、白人及其他人种;肿瘤分级分为G1、G2、G3、G4;T分期为T1/Ta/Tis、T2、T3、T4;婚姻状况分为已婚、未婚和SDW(分居、离异、寡妇)。性别、组织学(根据ICD-0-3形态学编码,分为膀胱移行细胞乳头状瘤/癌或膀胱非移行性),N分期(N0,N1/N2/N3),M分期,放疗和化疗被编码为二元变量。
在本研究中,数据被随机分成两组,其中70%的数据集用于开发预测模型(训练集),30%用于评估模型性能(验证集)。训练集的目的是拟合模型,而验证集用于评估最终模型的性能。
1.2 特征筛选
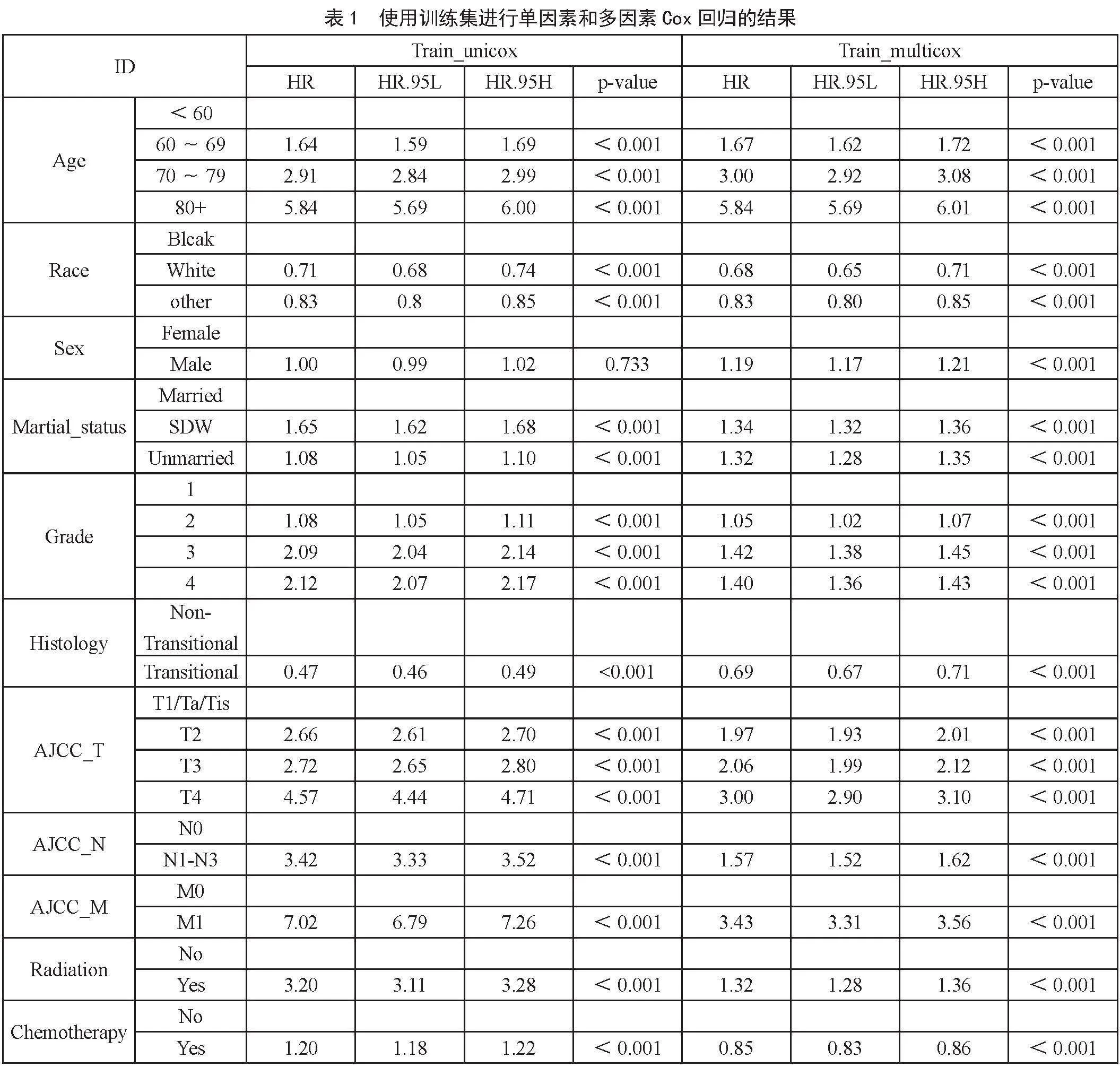
利用训练集进行单因素和多因素Cox回归分析,如表1所示。P0.05被认为具有统计学差异。结果显示,年龄、种族、性别、婚姻状况、组织学、基于AJCC第7版的TNM分期、放疗和化疗10个变量被纳入作为模型特征。
2 原理与方法
临床预测问题具有复杂性、不确定性、动态性、高风险性和伦理隐私性等特点,在处理这类问题时,需要采用科学的方法,结合医生的临床经验和专业知识,以提高预测的准确性和可靠性。逻辑回归(Logistic Regression, LR)和Cox比例风险模型是临床预测领域的经典方法,逻辑回归以其简单高效和可解释性强的特点,在二分类问题中表现出色;而Cox比例风险模型则以其处理时间相关事件和评估多种因素对生存时间影响的独特能力,成为生存分析的重要工具。随机森林(Random Forest, RF)具有缺失值容忍度高,降低过拟合风险,可提供特征重要性评分,且运行快、可解释性强的特点,而梯度增强决策树(Gradient Boosting Decision Tree, GBDT)方法学习具有非线性关系,对异常值鲁棒,性能高,通过优化残差精细拟合数据。
因此,本研究分别采用了逻辑回归、随机森林和梯度提升决策树和Cox比例风险模型四种机器学习方法构建BC患者的生存预测模型,四种算法的原理如下:
2.1 COX回归模型
COX回归模型以生存结局和生存时间为因变量,可同时分析众多因素对生存期的影响,能分析带有截尾生存时间的资料,且不要求估计资料的生存分布类型[6]。
其基本形式为:
式子中β1,β2,…,βm为自变量的偏回归系数。
对上式做对数变换可得:
因此,Cox回归模型与一般的回归分析不同,协变量对生存时间的影响是通过风险函数和基准风险函数的比值反映的,其中的风险函数和基准风险函数是未知的。在完成参数估计的情况下,可对基准风险函数和风险函数做出估计,并可计算每一个时刻的生存率。
2.2 逻辑回归模型
逻辑回归模型是用于二分类的机器学习算法,通过逻辑函数将线性回归输出映射为(0,1)间的概率。它基于最大似然估计求解参数,用梯度下降法优化对数似然损失函数。该算法因其简单高效且可输出概率值在实际应用中广泛使用[7]。
LR分布是一种连续型的概率分布,其分布函数和密度函数分别为:
2.3 随机森林
随机森林是基于决策树的集成学习算法,通过自助采样生成多个子数据集,并对每个子数据集构建决策树。在构建过程中,它随机选择特征进行分裂,增加模型多样性。多棵决策树集成后,通过投票或平均得出最终预测结果,提高了模型的泛化能力和鲁棒性。随机森林能处理高维、非线性数据,对缺失值和异常值具有鲁棒性,在分类、回归等任务中广泛应用[8]。
2.4 梯度提升决策树
梯度提升决策树是一种基于决策树的集成学习算法,旨在通过逐步优化残差来提升模型性能。GBDT的核心思想是利用梯度下降的方向来拟合当前模型的残差,即预测值与真实值之间的差异。在每一步迭代中,GBDT训练一个新的决策树来拟合前一步的残差,然后将这个新的决策树加入模型中。通过多次迭代,GBDT逐步减小模型的残差,从而提高预测精度。由于GBDT能够自动处理特征间的复杂关系,并且对于异常值和噪声具有一定的鲁棒性,因此在实际应用中取得了良好的效果。同时,GBDT还支持特征重要性评估,有助于特征选择和模型解释[9]。
3 实验结果与分析
3.1 机器学习模型建模过程
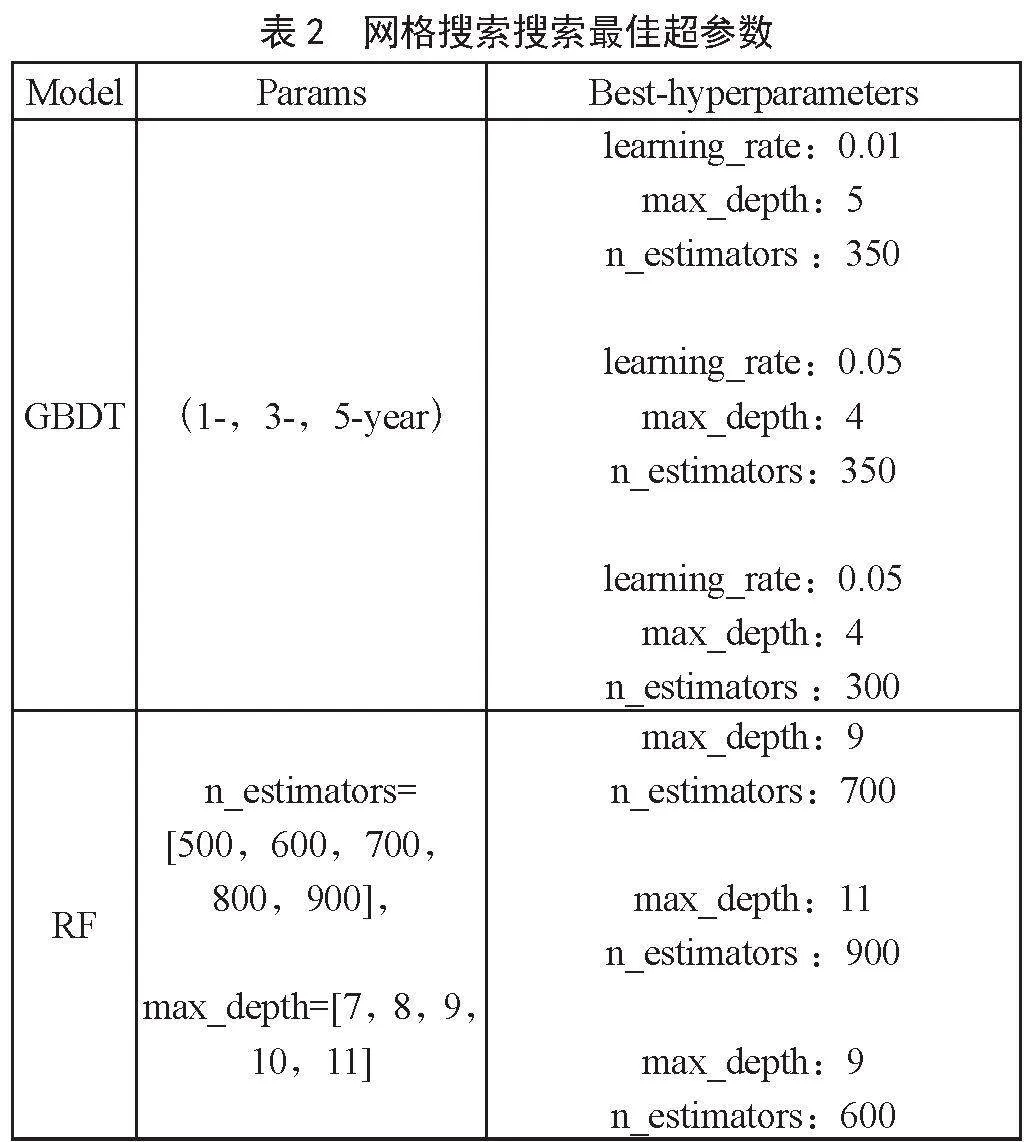
本研究使用网格搜索机器学习模型的最优超参数,通过5 折交叉验证来最大化准确性。GBDT和RF模型的最佳超参数如表2所示。
本研究对GDBT和RF机器学习模型进行训练时使用Sklearn库中train_test_split函数把数据集分成两个部分。其中,测试数据集占比为30%,数据集拆分之后,对数据集进行拟合操作,并且对数据集吻合度进行评估,最后采用十折交叉验证方法评估模型的性能。
3.2 模型评估结果分析
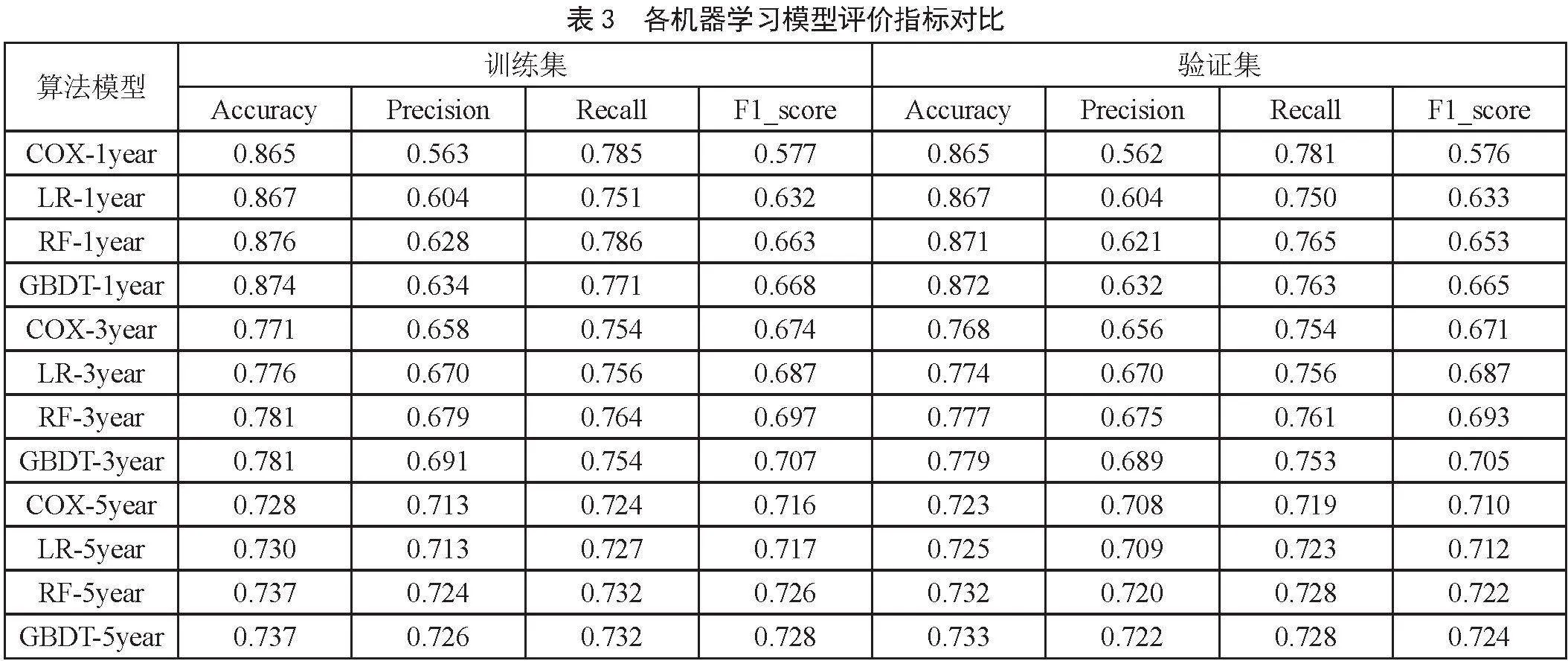
本研究选择Cox回归方法、logistic回归方法、随机森林(RF)和梯度增强决策树(GBDT)预测模型进行对比分析,以期找到BC患者生存预测上的最佳机器学习模型。
四种机器学习算法先在训练集和测试集上进行运行,并获取各算法的准确率(Accuracy)、精确度(Precision)、召回率(Recall)、F1得分(F1_score)等指标进行对比评价,指标取值范围[0,1]。精确度(Precision)是指预测为正且实际为正的样本占所有预测为正的样本的比例,召回率(Recall)是指预测为正且实际为正的样本占所有实际为正的样本的比例,F1得分是精确度和召回率的调和平均数,用于综合评价模型的性能,特别是在两者之间需要取得平衡时。分析结果如表3所示。
从表中可以看出GBDT再各类指标上表现最佳,如其在5年生存率预测上的准确率为 0.733,精确度为0.722。
从表中可以看出GBDT再各类指标上表现最佳,如其在5年生存率预测上的准确率为 0.733,精确度为0.722。
另外,我们还使用临床预测模型中广泛使用的曲线下面积(Area Under Curve, AUC)、Brier评分和校准度曲线三个评价指标对模型的区分度和校准度进行评价。
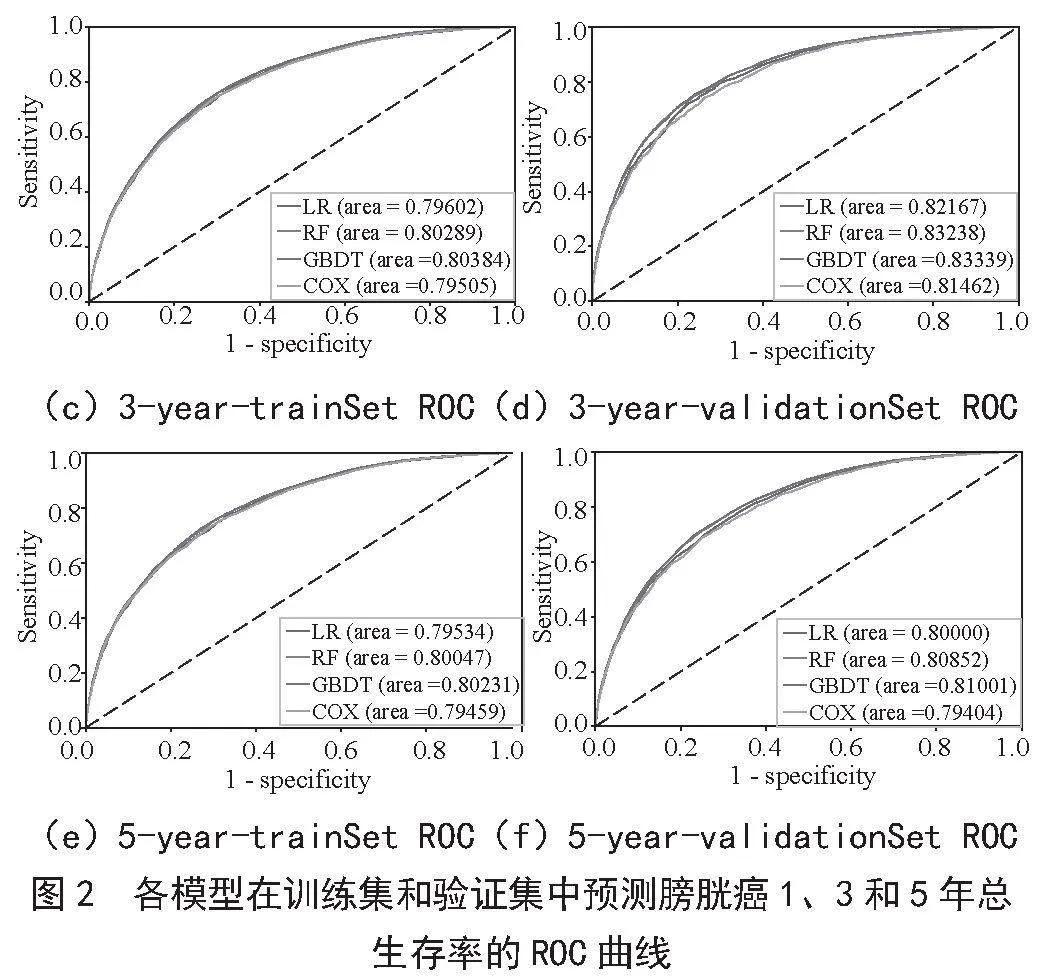
AUC是ROC曲线下的面积,用于衡量二分类模型的性能。它表示模型正确区分正负样本的能力,值越接近1说明模型性能越好。在训练集中,对于1年生存预测,Cox、LR、RF和GBDT的AUC值分别为0.812、0.818、0.833和0.833,在3年和5年生存队列中,GBDT的AUC值最高。在验证集中也得到了相同的结果,证明GBDT算法的稳定性。图2为每个模型的AUC值。
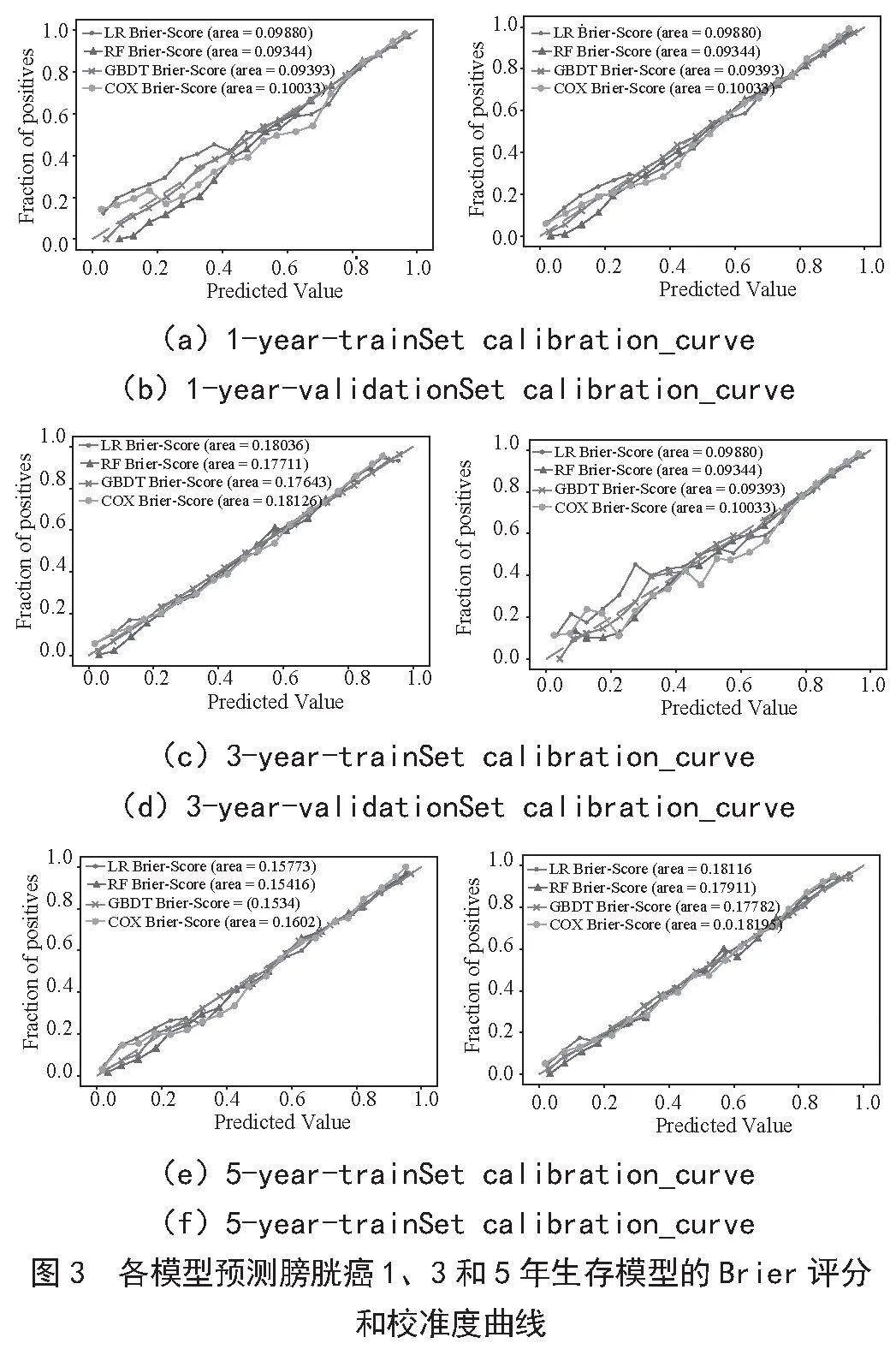
Brier评分是一种评估分类模型性能的指标,通过计算模型预测概率与实际标签之间的平均平方误差来衡量预测准确性,值越小表示模型预测越准确。而校准度(Calibration)评估模型预测概率的准确性,即模型给出的预测概率与实际结果的一致性。良好的校准度意味着模型预测的概率可信赖,有助于决策者根据预测结果制定合理策略。
如图3所示,在四种机器学习模型的三项性能指标对比中,GBDT模型仍然表现良好。
4 结 论
本论文研究创新性地研究基于机器学习的膀胱癌生存预测模型构建,使用大数据队列分析最优预测算法模型,构建的临床预测模型可帮助临床医生更好地评估患者病情,从而辅助完成膀胱癌患者个性化预后方案,以改善肿瘤预后效果。实验结果显示,GBDT在预测BC患者生存率上的各类指标均优于其他模型。
本研究也存在一些局限性,包括SEER数据库中缺乏如遗传信息、治疗时机等生存分析相关因素,以及缺乏独立的外部验证数据,可能会影响模型的临床直接应用效果。未来的研究方向包括通过增加预测因素的数量来开发更全面的模型,具有更好的预测性能,在外部数据集上验证模型。
参考文献:
[1] BRAY F,FERLAY J,SOERJOMATARAM I,et al. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries [J].CA: Cancer J Clin,2018,68(6):394–424.
[2] YANG Z,BAI Y,LIU M,et al. Development and Validation of a Prognostic Nomogram for Predicting Cancer-Specific Survival After Radical Cystectomy in Patients With Bladder Cancer: a Population-Based Study [J].Cancer Med,2020,9(24):9303-9314.
[3] ZHANG Y,HONG Y K,ZHUANG D W,et al. Bladder Cancer Survival Nomogram: Development and Validation of a Prediction Tool, Using the SEER and TCGA Databases [J].Medicine(Baltimore),2019,98(44):e17725[2024-01-26].http://dx.doi.org/10.1097/MD.0000000000017725.
[4] WEN P,WEN J,HUANG X,et al. Development and Validation of Nomograms Predicting the 5- and 8-Year Overall and Cancer-Specific Survival of Bladder Cancer Patients based on Seer Program [J].J Clin Med,2023,12(4):1314.
[5]孙明喆,毕瑶家,孙驰.改进随机森林算法综述[J].现代信息科技,2019,3(20):28-30.
[6] 王伟英,桑文文,焉双梅,等.急性缺血性脑卒中患者1年复发危险因素Cox回归分析 [J].中华老年心脑血管病杂志,2016,18(1):46-50.
[7] 朱燕波,王琦,吴承玉,等.18805例中国成年人中医体质类型与超重和肥胖关系的Logistic回归分析 [J].中西医结合学报,2010,8(11):1023-1028.
[8] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述 [J].统计与信息论坛,2011,26(3):32-38.
[9] 连克强.基于Boosting的集成树算法研究与分析 [D].北京:中国地质大学(北京),2018.
