基于PCA降维的MNIST手写数字识别优化
2024-11-05田春婷

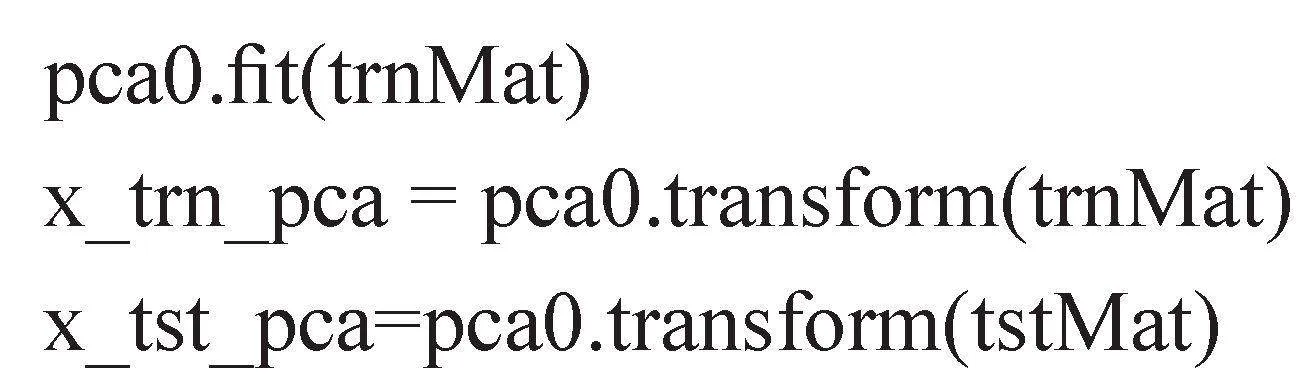



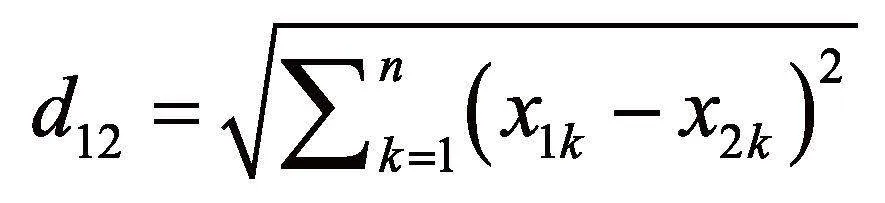
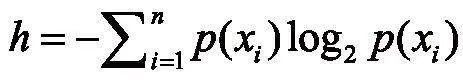



摘 要:PCA数据降维技术广泛应用于数据降维和数据的特征提取,可以很大程度上降低算法的计算复杂度,提升程序运行效率。文章将MNIST原始数据集和对原始数据集进行PCA降维处理之后的数据集作为样本,分别采用K-邻近算法、决策树ID3算法、SVC分类模型,以及选取不同分类算法作为基础分类器的集成学习方法,实现手写数字识别。在对MNIST数据集进行PCA降维前后,以及不同分类算法和模型执行结果的时间复杂度与预测准确率进行比对与分析,进一步强化与优化手写数字识别准确率等各项指标。
关键词:PCA降维;MNIST手写数字识别;K-邻近算法;决策树;SVC分类模型;集成学习
中图分类号:TP391.4;TP181 文献标识码:A 文章编号:2096-4706(2024)16-0064-05
Optimization of MNIST Handwritten Digit Recognition Based on PCA Dimensionality Reduction
Abstract: PCA data dimensionality reduction technology is widely used in data dimensionality reduction and feature extraction, which can greatly reduce the computational complexity of algorithms and improve program efficiency. This paper takes the MNIST original dataset and the dataset after PCA dimensionality reduction as samples, and uses K-Nearest Neighbor algorithm, Decision Tree ID3 algorithm, SVC classification model, as well aGA+K2yAEPOy2eiDF3uhRaA==s Ensemble Learning methods that select different classification algorithms as basic classifiers to achieve handwritten digit recognition. It compares and analyzes the time complexity and prediction accurLm6ZfPkSb1C60t9ylZPjEw==acy of different classification algorithms and models before and after PCA dimensionality reduction on the MNIST dataset, further enhances and optimizes various indicators such as handwritten digit recognition accuracy.
Keywords: PCA dimensionality reduction; MNIST handwritten digit recognition; K-Nearest Neighbor algorithm; Decision Tree; SVC classification model; Ensemble Learning
0 引 言
MNIST[1]经典手写数字数据集由训练集、测试集、训练结果集和测试结果集四个文件子集构成,四个子集存放在mnist.npz数组压缩文件中。该数据集的构建目标是让机器学习[2]运用其分类预测方法,达到识别手写数字[3]的目的;常用的机器学习分类算法有:K-邻近算法[4]、决策树ID3算法[5]、SVC分类模型[6]和集成学习[7]等方法;数据降维是一种将高维数据转换为地位数据的技术,同时尽量保留原始数据的重要信息及数据的变化,以期达到降低计算资源,提升算法效率的效果。主成分分析PCA降维技术[2]通过减少数据集维度,具有降低算法计算复杂度的优势,运用保留数据主要变化模式、去除噪声和不重要特征的数据处理工作原理。不仅高效地实现了数据降维,还能够保留数据集核心信息。本文以MNIST数据集和经过PCA降维的数据集为样本,分别采用机器学习的K-邻近算法、决策树、SVC分类模型等多种分类预测算法,实现手写数字识别,同时进行多种算法的计算复杂度和预测准确率比对。
1 数据预处理
mnist.npz数据集文件由6万个手写数字训练样本和1万个测试样本组成,1张28×28灰度图像构成1个样本,训练样本和测试样本分别对应的数字标签结果数据集也包含在内。为了简化数据,同时进一步降低算法计算量,需要对数据进行归一化处理和降维预处理。
1.1 归一化处理与数据格式转换
为了分类器能够识别输入数据集格式,将数据集进行归一化处理和格式转换。具体流程如下:
1)加载mnist.npz数据集压缩包。
2)提取压缩包中的数组、获取训练集、测试集以及分类数字标签。
3)将训练集、测试集数组非零元素归一化为1。
4)数据格式转换,将28×28矩阵转换成1×784列的矩阵。
处理结果如图1和图2所示。
1.2 数据降维
本文采用PCA降维技术[8]对mnist.npz数据集进行数据降维。PCA降维运用正交变化,将原始数据转化到一组线性不相关成份上的原理,对数据集进行降维。PCA降维技术能够显著降低分类训练和预测的计算量,但是会造成分类预测精度降低。
PCA降维技术有一个非常重要的降维参数n_components,是用来指定降维后的特征值,通常代表期望将原始数据压缩成的特征数。本文通过将降维参数n_components通过反复测试,确定将归一化和格式转换后的数据集采用PCA降维技术由784个特征值,降维到n_components值为36,来减少数据量,进而降低算法计算复杂度。手写数字数据训练集和测试集进行PCA降维代码如下:
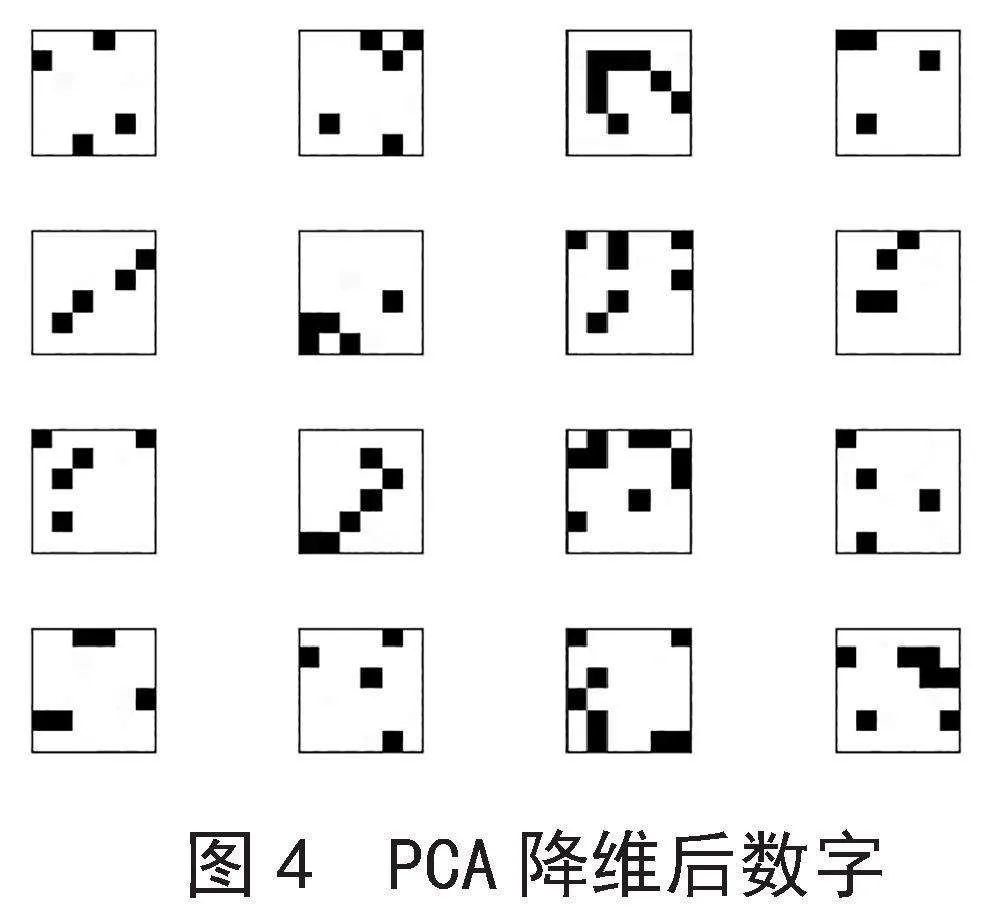
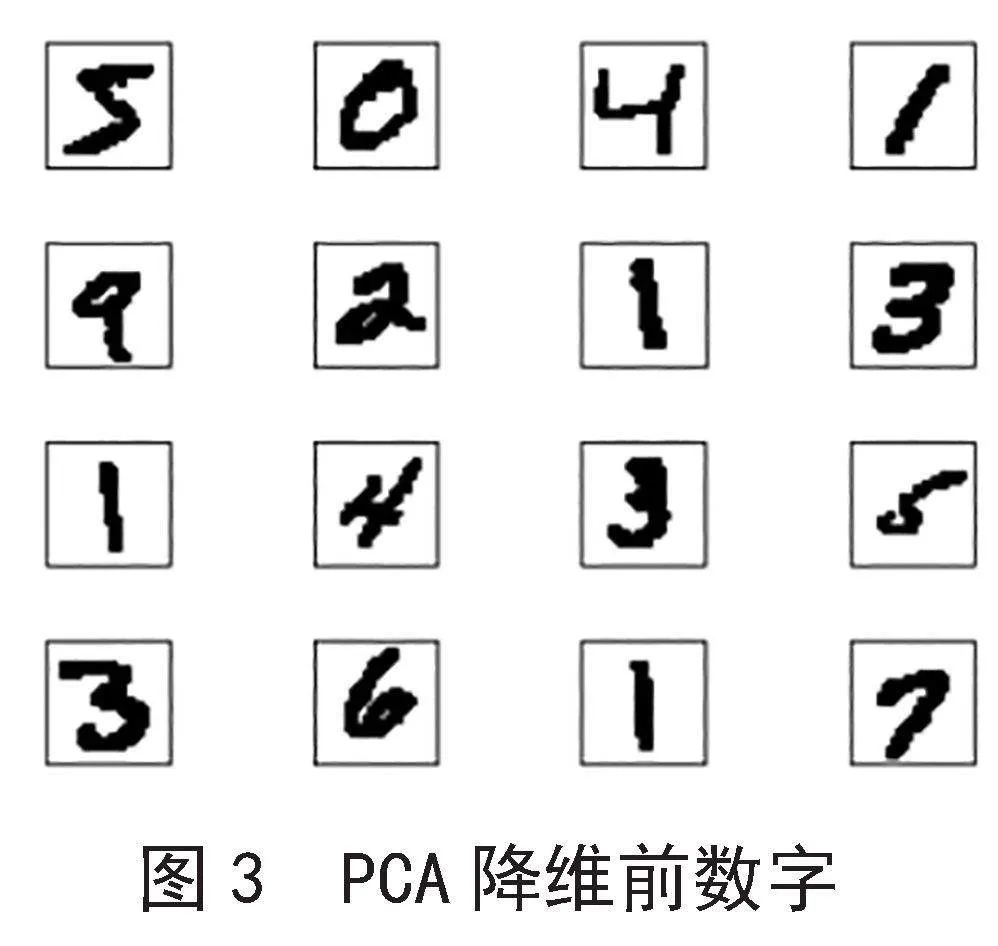
PCA降维之前,mnist.npz数据集中的手写数字是人眼可以识别的,通过PCA降维技术对mnist.npz训练集和测试集进行降维之后,手写数字为人眼不可以识别,部分手写数字降维之前和降维之后显示如图3和图4所示。
2 手写数字识别实现及分类预测
2.1 k-邻近算法实现手写数字识别
K-邻近算法[4]是一种易于掌握且十分有效的机器学习算法。采用测量不同特征值之间的距离进行分类。根据欧氏距离公式,计算两个向量点之间的距离。数据集特征值为n的两个向量a(x11,x12,…,x1n)和b(x21,x22,…,x2n)之间的欧氏距离为:
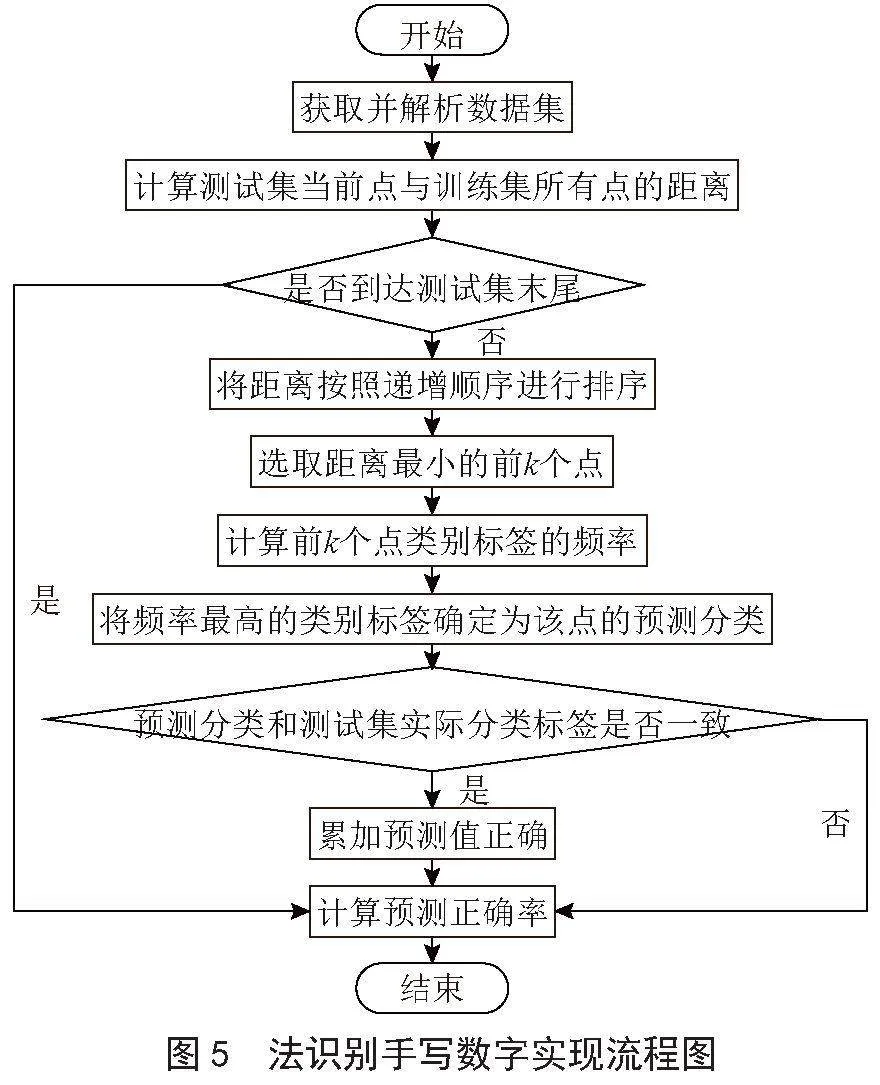
将各个点之间的距离计算完成之后,按照从小到大的顺序将所有距离排序,然后选取前k个最小距离,再求出前k个距离对应的每个分类标签,预测出的结果值是出现频率最高的分类标签。精度高、对异常值不敏感,以及空间复杂度较高是k-邻近算法的主要特点,该模型实现识别手写数字流程如下:
1)收集及解析数据集。
2)计算测试集中的每一个当前点与训练集中点的距离。
3)将距离按照递增顺序进行排序。
4)选取距离最小的前k个点。
5)计算前k个点类别标签的频率。
6)将频率最高的类别标签确定为该点的预测分类。
具体流程图如图5所示。
按照图5流程,采用K-邻近算法分类器对样本数据集的60 000个训练集向量和10 000个测试集向量进行距离计算和测试,原始数据集进行PCA降维前,每个距离计算包括784个维度浮点运算;采用PCA降维之后,每个距离计算包括36个维度浮点运算。运用PCA-K-邻近算法[8]进行测试,当k设置为3时,PCA降维前错误率为3.91%,准确率为96.09%,但是识别时长非常高,为10 876.904秒,执行效率并不高,但识别准确率较高;PCA降维后错误率降为3.57%,准确率为96.46%,识别时长大大降低,仅仅花费了238.77秒。相比较于降维前,PCA降维后的时间复杂度和识别准确率都有优化,尤其在时间复杂度方面,识别花费时长大大降低,PCA降维技术表现非常优异。
2.2 模型创建与代码实现手写数字识别
采用决策树ID3算法、SVC分类模型算法和集成学习技术,将mnist.npz数据集进行PCA降维前和PCA降维后,分别实现手写数字识别,将实验结果进行比对,给出最优方案。
2.2.1 决策树ID3算法构造决策树模型
决策树ID3算法[9]是一种其数据形式非常易于理解,计算复杂度较低。决策树算法常见的有二分法和ID3等算法。鉴于ID3算法的优势以及对数据集的规则要求,本文采用ID3算法实现手写数字识别。其数据结构满足ID3算法的数据结构要求。决策树ID3算法对数据集的每次划分会选取一个特征属性作为参考属性,这个参考属性的确定基于计算信息增益的原则,此度量方式称为熵,熵期望值的计算公式为:
其中n为分类的数目,p(xi)为选择该分类的概率。决策树ID3算法优势在于能够简单且快速遍历整个数据集,循环计算熵值和数据集子集的划分。
本文运用Python语言skleanrn库的tree模块提供的分类树DecisionTreeClassifier()方法,将mnist.npz文件中60 000个原始训练集或者降维后训练集作为样本训练集,采用分类器方法DecisionTreeClassifier()提供的fit()方法进行训练,构造手写数字识别决策树模型;运用决策树模型提供的score()方法分别对mnist.npz文件中10 000个原始测试集向量或者降维后测试集进行测试,分别得出识别时间复杂度和预测准确率。
构造决策树识别模型的具体方法如下:
1)调用Python语言sklean库的分类树tree.DecisionTreeClassifier()方法生成决策树分类器。
2)运用决策树分类器fit()方法对样本训练集进行训练,生成决策树识别模型。
3)调用决策树识别模型的score()方法对样本测试集进行测试。
4)求出预测准确率和时间复杂度。
2.2.2 SVC算法构建识别模型
SVC(Support Vector Classification)支持向量机分类[10]是一种二分类算法模型,在模式识别中表现优异,能够很好地解决二分类或者多分类问题。运用核函数,将低维数据映射到高维特征空间,在高维特征空间中寻找出超平面方法,将不同类别之间的间隔最大化,实现分类目的。
本文采用Python语言skleanrn库中svm模块提供的支持向量分类器函数svc()构造支持向量机;同样运用支持向量机svc()函数提供的fit()方法,将mnist.npz文件中60 000个原始训练集或者降维后训练集作为样本训练集,构造手写数字识别支持向量机模型;运用支持向量机模型提供的score()方法得到预测指标。
2.2.3 集成学习技术构建识别模型
集成学习[11](ensemble learning)是一个分类器集成器,将多个机器学习算法作为基础分类模型,之后采用投票法、学习法等构建策略,将选取的基础分类器结合起来,用以完成机器学习任务。本文的集成学习,将SVC分类模型和决策树ID3算法为基础分类器,以投票法作为构建策略实现手写数字识别,如图6所示。
2.2.4 流程与Python代码实现
分类模型识别手写数字实现流程如下:
1)数据集收集、归一化与格式转换处理。
2)对数据集进行PCA降维。
3)ID3算法构造决策树。
4)决策树对训练集(PCA降维前、降维后)进行训练。
5)SVC模式算法对训练集(PCA降维前、降维后)进行训练。
6)集成学习对训练集(PCA降维前、降维后)进行训练,以决策树与SVC分类模型为基础分类器。
7)分别预测测试集分类结果。
8)将预测分类结果与测试集实际分类标签进行比对,获得预测错误率。
部分Python核心代码如下:
上述代码中,采用决策树ID3算法对数据集PCA降维前后、数据集PCA降维之后采用SVC分类模式算法,以及以数据集PCA_决策树ID3算法和PCA_SVC分类算法作为基础分类器实现的集成学习技术,进行数据集训练;在集成学习代码中,权重的分配通过反复测试,采用PCA_决策树对PCA_SVC分类算法位1.8比1比例进行分配,以期得到最优识别效果。
2.3 结果分析与比对
图7为通过K-邻近算法PCA降维前后手写数字识别结果和运行结果。
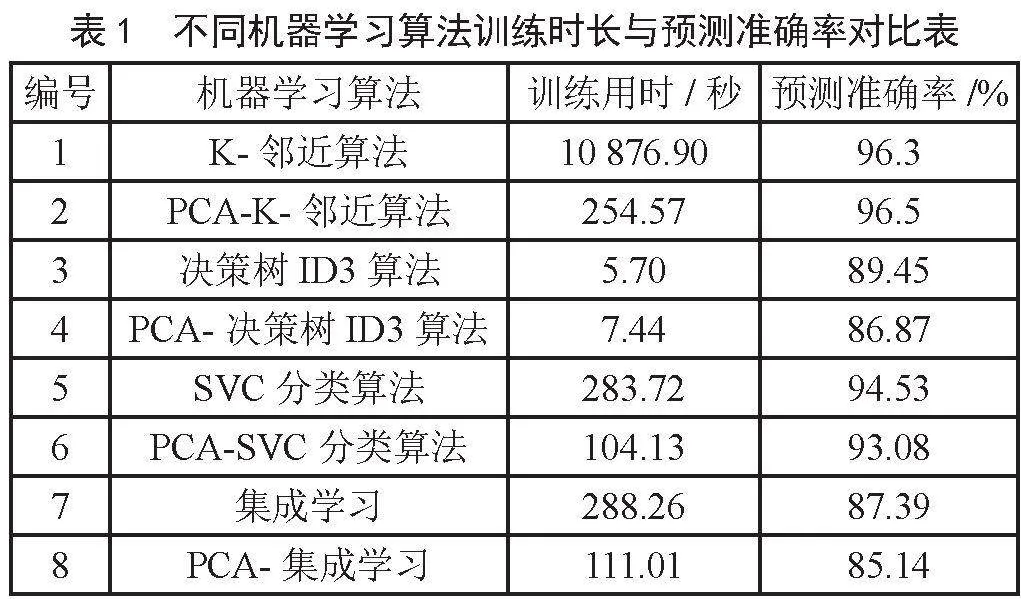
总结不同算法所用训练时长和预测准确率如表1所示。
表1给出了8种不同机器学习分类算法识别手写数字的运行结果,从表1可以看出,K-邻近算法降维前训练时长为10 876.90秒,是其余算法训练时长的42倍左右,将耗费大量资源,因此将其作为异常值在剔除,绘制不同算法识别手写数字运行结果对比图,如图8所示。
表1和图8中,K-邻近算法PCA降维前后的预测准率最高,分别达到了96.3%和96.5%,但是降维前训练时长远远超出预期,将K-邻近算法排除;而PCA-K-邻近算法预测结果不仅在预测准确率上保持了降维前的高预测率,而且在算法时间复杂度上得到大幅度降低;通常,SVC分类模型在中小型数据集上的表现和神经网络一样突出,从表1和图8可以看出,SVC算法降维前后在时间复杂度和预测准确率都有较好的预期结果值,PCA-SVC算法相对于SVC算法在预测准确率方面不分上下,在时间复杂度上表现更为优异;降维前后的决策树ID3算法对数据集进行降维之后,并没有提升预测准确率,反而降低了预测效率,但是两者时间复杂度相对于其他算法大幅度降低,执行效率非常高,训练时间均在10秒以内;数据显示,集成学习预测准确率在降维前后的表现没有特别优势,表现一般。
3 结 论
本文分别采用K-邻近算法、SVC分类模型、决策树ID3算法以及集成学习算法将mnist.npz原始数据集进行归一化、矩阵转换等处理结果作为样本,实现手写数字识别;然后以采用PCA算法对其进行降维处理之后的数据集作为样本,再次分别运用上述四种机器学习分类方法实现识别。对各种算法执行结果的时间复杂度和预测准确率进行对比,筛选相对较优算法。从实验数据可以看出,其中PCA-K-邻近算法和SVC分类模型PCA降维前后在预测准确率表现非常优异,均达到93%以上,K-邻近算法在预测准确率方面甚至高达96%以上;在执行效率方面,决策树ID3算法表现非常优异,训练时长相对于其他算法降低了大约38倍到57倍之间,而且预测准确率也接近90%。从运行结果的比对可以看出,不同算法各有优势,程序运行结果数据具有较高参考价值。
参考文献:
[1] 张贯航.基于MNIST数据集的激活函数比较研究 [J].软件,2023(9):165-168.
[2] Peter Harrington.机器学习实战 [M].李锐,李鹏,曲亚东,王斌,译.北京:人民邮电出版社,2013.
[3] 黄明春,田秀云,谢玉萍,等.基于人工智能的手写数字识别方法研究 [J].机电工程技术,2023(4):185-189.
[4] 辛英.基于k-邻近算法的手写识别系统的研究与实现 [J].电子设计工程,2018(7):27-30.
[5] 赵力衡.基于决策树的手写数字识别的应用研究 [J].软件,2018(3):90-94.
[6] 曹啼.C-SVC、ν-SVC与LSSVC三种支持向量分类机的对比研究 [D].上海:华东师范大学,2019.
[7] 王衡军.机器学习 [M].北京:清华大学出版社,2020.
[8] 杨济萍.基于主成分降维模型的手写数字识别研究 [J].网络安全技术与应用,2021(3):31-32.
[9] 张桂杰,王小灿,邢维康,等.基于决策树分类算法的心理测评模型研究 [J].吉林师范大学学报,2023(4):123-130.
[10] 李雅琴.SVM在手写数字识别中的应用研究 [D].武汉:华中师范大学.
[11] 符新伟,王舒可.基于集成机器学习的手写数字识别技术研究 [J].中阿科技论坛:中英文,2022(11):124-128.
