基于深度强化学习的移动机器人路径规划研究
2024-11-05荣垂霆朱恒伟张宾刘聪
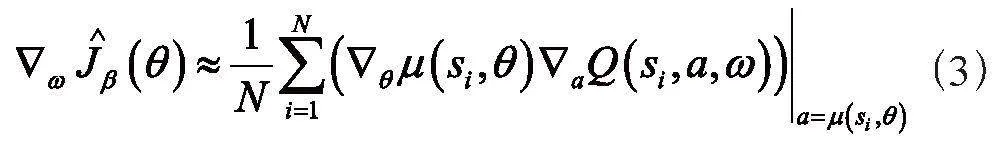




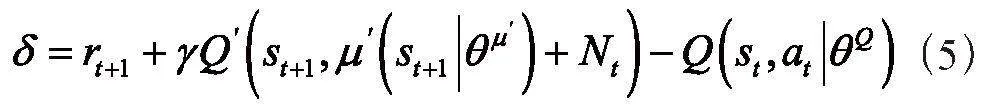
摘 要:鉴于采用深度强化学习算法进行移动机器人路径规划时存在收敛速度慢的问题,提出一种改进的算法。对经验回放机制中样本的学习潜力得分进行设计,根据学习潜力得分对样本进行优先级评分,并根据评分进行采样。将改进算法应用到机器人路径规划任务中,并进行奖励函数、避障参数及路径规划实验环境的设计。通过与对比算法进行实验比较,验证了改进算法的收敛速度及其在路径规划任务中的有效性。
关键词:深度强化学习;路径规划;移动机器人
中图分类号:TP242;TP18 文献标识码:A 文章编号:2096-4706(2024)16-0060-05
Research on Path Planning of Mobile Robots Based on Deep Reinforcement Learning
Abstract: Given the problem of slow convergence speed when using Deep Reinforcement Learning algorithms for mobile robot path planning, an improved algorithm is proposed. It designs the learning potential score of samples in the experience replay mechanism, prioritizes the samples based on the learning potential score, and samples them according to the score. It applies improved algorithms to robot path planning tasks and designs reward functions, obstacle avoidance parameters, and path planning experimental environments. Through experimental comparison with comparative algorithms, the convergence speed of the improved algorithm and its effectiveness in path planning tasks are verified.
Keywords: Deep Reinforcement Learning; path planning; mobile robot
0 引 言
移动机器人在医疗、交通、运输等日常生活中得到了广泛的运用,路径规划技术是其中非常重要的一环。在机器人路径规划任务中,精确避障以及快速到达目标点成为路径规划中至关重要的两个任务。常用的路径规划方法主要是群智能算法[1-4],但传统算法已无法满足实际应用中快速适应未知环境的需求。近年来,随着人工智能的快速发展,深度强化学习(DRL)逐渐成为解决未知环境下机器人路径规划的有效方法之一[5-7]。
本文针对DRL处理路径规划任务时存在收敛速度慢的问题,设计一种基于学习潜力的经验回放机制的强化学习算法。它是基于学习潜力指标对每个经验样本的得分进行评定,选取TD误差和立即奖励作为评定依据,并为其分配了权重,设计出经验数据重要性的公式,并依此进行样本选择,结合强化学习算法进行改进。将改进算法与路径规划任务相结合进行实验,设计合理的奖励函数、避障参数及路径规划环境模型,验证改进算法的有效性。
1 深度确定性策略梯度算法
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)[8]是一种结合了演员-评论家(Actor-Critic)框架和经验回放机制(Experience Replay, ER)[9]的强化学习算法,适于处理连续动作空间任务的问题。
DDPG采用ER来打破样本间的时间相关性,同时重复利用过去的经验。经验回放机制工作时首先是进行数据存储,在与环境交互的过程中将每一步的数据(st,at,rt,st+1)保存在经验回放缓冲区中。接下来再进行随机采样,从缓冲区中随机抽取小批量的样本来更新网络参数。
在DDPG算法中,需要对Critic网络中的目标Q值进行更新,更新参数计算式如式(1)和式(2)所示:
根据最大化目标函数来更新策略网络参数θ,如式(3)所示:
最后利用软更新目标网络,如式(4)所示:
2 改进的深度确定性策略梯度算法
DDPG算法的经验回放机制使用随机采样方式采样,这种采样方式并未考虑样本之间重要性的不同,会造成算法收敛速度低的问题。针对这一问题,本节在对ER中样本的重要性进行处理时设计一种基于学习潜力的经验回放机制(Learning Potential Experience Replay, LPER)。LPER是基于学习潜力指标对每个经验样本的得分进行评定,并结合DDPG算法进行改进,进而提高收敛速度。
2.1 基于学习潜力的经验回放机制
学习潜力指标是一种用来衡量每个经验样本对当前策略学习的潜在贡献程度的指标。学习潜力可以通过衡量经验数据能在多大程度上改变当前策略或价值函数来评估。由于经验数据的TD误差和奖励值对样本重要性具有非常重要的意义,本小节选取TD误差和奖励值作为经验样本数据对当前策略学习贡献的潜在影响因素:
1)TD误差。TD误差是强化学习中的一个重要概念,用来衡量当前估计的状态值或动作值与实际获得的奖励之间的差异[10]。TD误差表示当前状态的值函数或动作值函数的估计值与下一个状态的值函数或动作值函数的估计值之间的差异,加上实际获得的奖励。计算式如式(5)所示:
其中,rt+1表示智能体从环境中实际获得的奖励;γ表示折扣因子,用于衡量未来奖励的重要性;Q表示当前状态s的值函数或状态-动作对(s,a)的动作值函数的估计值;st+1表示下一个状态。
2)奖励值。奖励值表示智能体与环境交互时获得的反馈,用来表明智能体在某个状态下执行某个动作的好坏程度或者是对智能体行为的评价。奖励值是强化学习算法中一个重要输入,它直接影响智能体的学习和决策过程。
针对上述每个潜在的贡献因素,本小节设计一个函数来量化其对学习潜力的贡献值。由于TD误差因素的重要性比奖励值要高一些,在对线性函数的权重进行设计时,将TD误差的权重设为0.7,将奖励值的权重设为0.3。样本优先级计算式如式(6)所示:
其中,p表示样本的学习潜力得分;δ表示样本的TD误差;r表示样本的奖励值;b表示偏置项,它是一个很小的正数,偏置项的作用是使TD误差和奖励值均为零时,模型的学习潜力不为零,使得该样本可以被采样。
2.2 基于LPER的DDPG算法
本小节将2.1中改进的经验回放机制与DDPG相结合,设计出基于学习潜力的经验回放机制的深度确定性策略梯度算法(DDPG Algorithm Based on LPER, LPER-DDPG)。改进算法伪代码如算法1所示:
算法1 基于学习潜力的经验回放机制的深度确定性策略梯度算法
3 基于改进算法的移动机器人路径规划实验
为了验证改进算法的有效性,本文将改进算法与机器人路径规划任务相结合,通过改进算法与对比算法在机器人路径规划任务中的性能表现比较来验证改进算法的优势。在本节中,首先对奖励函数和避障参数进行设计;其次对路径规划环境进行设计;最后对强化学习与机器人路径规划任务的实现进行设计。
3.1 奖励函数设计
奖励函数会直接影响路径规划策略的性能和效果。设计一个合适的奖励函数需要考虑多个因素,包括路径长度、避障效果、到达目标点的速度等。在本论文中,我们提出一种综合考虑这些因素的奖励函数设计方案,包括到达目标点奖励、避障奖励、路径长度惩罚、速度奖励四种因素:
1)到达目标点奖励。当机器人成功到达目标点时,应该给予较大的正phgjwCVuNobFrjSd8C+DGQ==奖励,以鼓励机器人快速、高效地完成了路径规划任务。因此,当机器人处于目标点附近时,奖励函数应该输出一个较大的正值。
2)避障奖励。为了使机器人能够避开环境中的障碍物,我们引入了避障奖励机制。当机器人与障碍物距离较远或成功规避了障碍物时,应该给予一定的正奖励;相反,当机器人与障碍物距离较近或发生碰撞时,应该给予较大的负奖励,以惩罚机器人的不良行为。
3)路径长度惩罚。考虑到路径长度对于机器人移动的影响,我们引入了路径长度惩罚项。即使机器人成功到达目标点,如果其路径过长,应该给予一定的负奖励,以鞭策机器人寻找更短的路径。
4)速度奖励。为了鼓励机器人以较快的速度到达目标点,我们可以引入速度奖励项。当机器人在规划路径上以较快的速度前进时,应该给予一定的正奖励,以鼓励机器人的快速移动。
综合以上因素,本文设计如式(7)所示的奖励函数:
其中,Rgoal(s′)表示到达目标点的奖励函数,Robstacle(s,s′)表示避障奖励函数,Rlength(s,s′)表示路径长度惩罚函数,Rvelocity(s,a)表示速度奖励函数。
3.2 避障参数设计
在基于深度强化学习的机器人路径规划中,避障参数的设计至关重要,它直接影响着机器人的避障效果。我们针对机器人与障碍物之间的实时距离L、最大距离Lmax和最小距离Lmin进行参数设计,其中Lmax设为0.5 m,Lmin设为0.1 m,以确保机器人能够安全、高效地避开障碍物。
具体参数设计如下:
1)当机器人探测到的障碍物与机器人之间的距离L大于最大距离Lmax时,机器人可继续沿原定路径前进,因为障碍物远离机器人,不会对其造成影响。
2)当机器人探测到的障碍物与机器人之间的距离L小于最小距离Lmin时,机器人应立即采取避障措施,停止前进或选择绕过障碍物的路径,以避免发生碰撞。
3)当机器人探测到的障碍物与机器人之间的距离L处于最大距离Lmax和最小距离Lmin之间时,机器人需要根据具体情况采取相应的避障策略。可考虑调整机器人的速度或方向,以安全绕过动态障碍物。
3.3 路径规划环境设计
本文所使用的路径规划仿真环境是使用ROS和Gazebo构建的。在仿真环境中建立机器人模型,并在构建好的路径规划环境中添加静态障碍物。图1为机器人路径规划仿真环境。
图1为本实验所使用的机器人路径规划仿真环境,目标位置为左下角方形区域;右上角的圆形物体为构建的机器人模型,同时也表示路径规划任务的起始点;周围的墙壁和中间的六个木板代表路径规划环境中的障碍物。机器人从起始点出发,利用深度强化学习算法在环境中进行学习探索,对环境中的障碍物进行避障,通过不断的试错学习,最终规划出一条从起始点到目标点的最优路径。
3.4 仿真实现及结果分析
3.4.1 实验参数设置
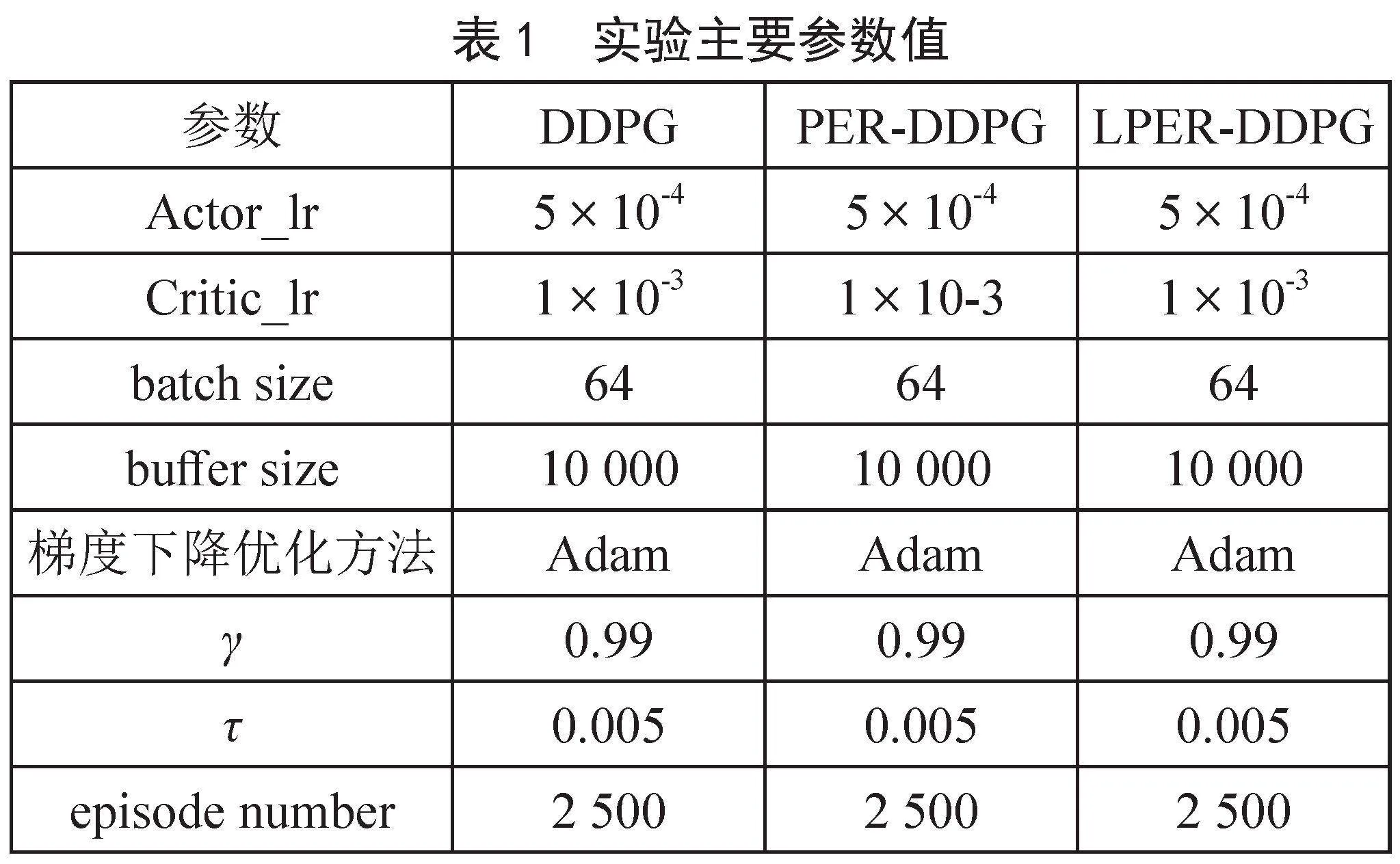
在进行机器人路径规划仿真实验时,为了保证实验的公平性,实验用的对比算法和改进算法均采用相同的奖励函数、避障参数等。表1为实验时的主要参数。
3.4.2 实验结果及分析
本实验选取DDPG和PER-DDPG两种算法作为比较算法。平均奖励、回合数和最短路径也是判定改进算法性能好坏的三种指标。以下是三种评价指标的评价原则:
1)达到稳定状态时,系统平均奖励值越高,表明该算法的性能更优。
2)达到稳定状态时,所经历的回合(episodes)数表示收敛时间,episodes越小表明该算法的收敛速度越快。
3)达到稳定状态后,稳定的路线长度越短,表明其性能越好。
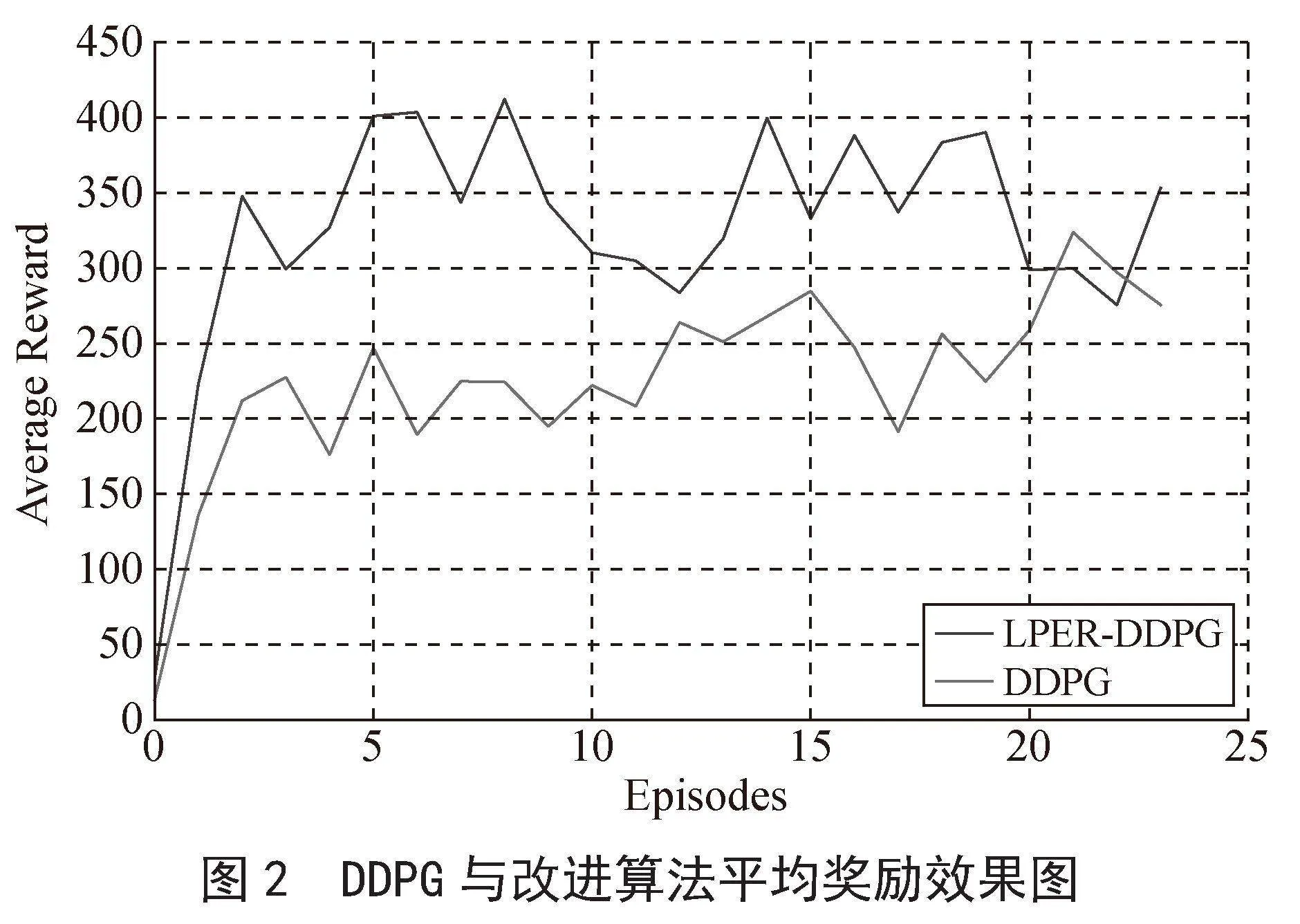
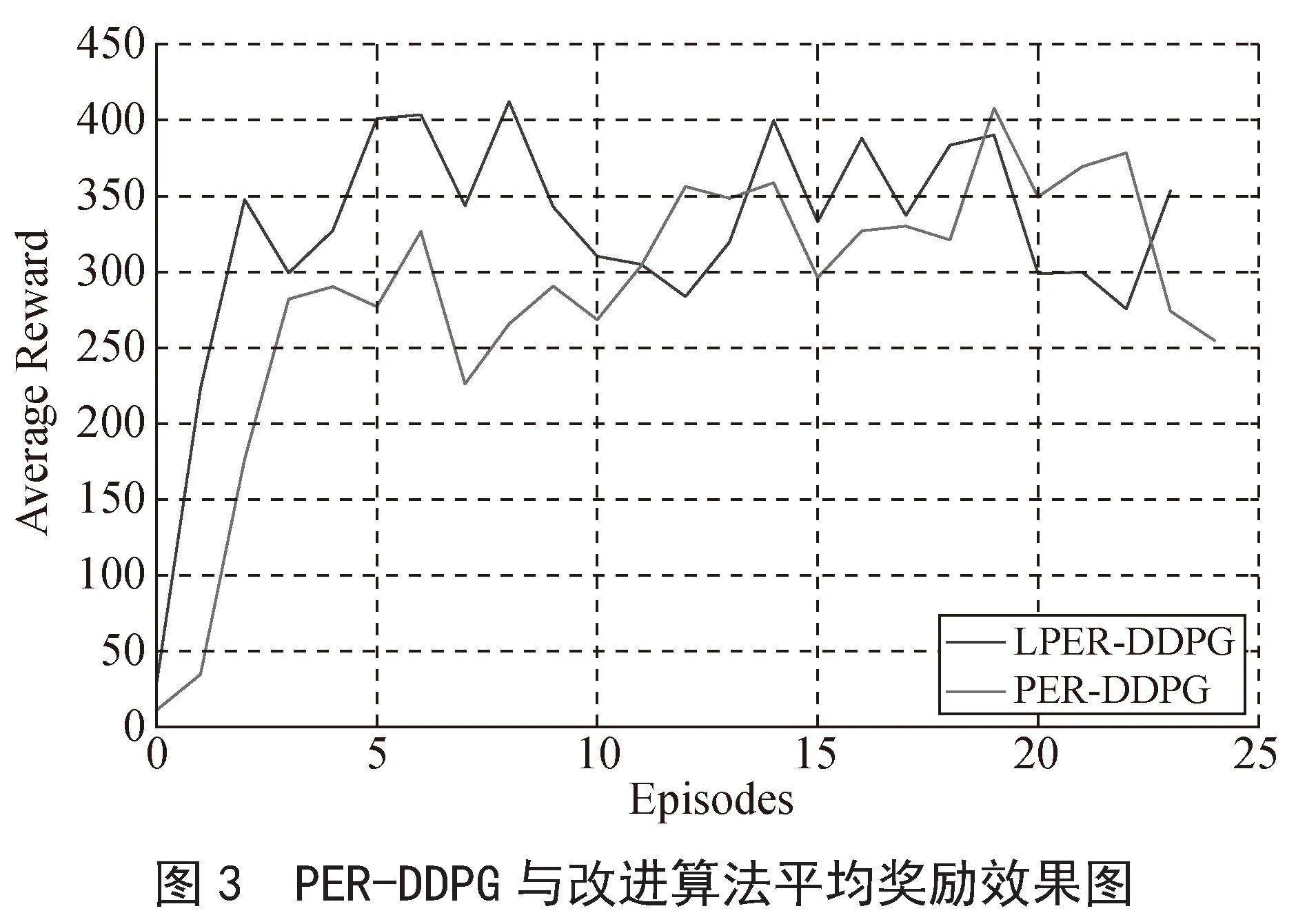
图2和图3为改进算法与机器人路径规划任务结合训练的平均奖励效果图,本实验设定的episodes数为2 500,为使本实验的效果图平滑,采用每100回合求其平均奖励值,绘制在效果图上面,并得出最终效果图。
如图2所示,改进算法在500回合处达到稳定奖励值340,DDPG算法在1 200回合处达到稳定奖励值240,两者相比,改进算法收敛速度提高了58.3%,reward增加了100,提高了41.7%,表明改进算法的收敛速度较快。如图3所示,PER-DDPG算法在1 100回合处达到稳定奖励值300,改进算法的收敛时间及奖励值和图2一样,两者相比,改进算法的收敛速度提高了54.5%,奖励值增加了40,提高了13.3%,收敛速度和奖励值均有所提升。综上分析可得,改进算法与两种对比算法相比,其收敛速度均有所提升。
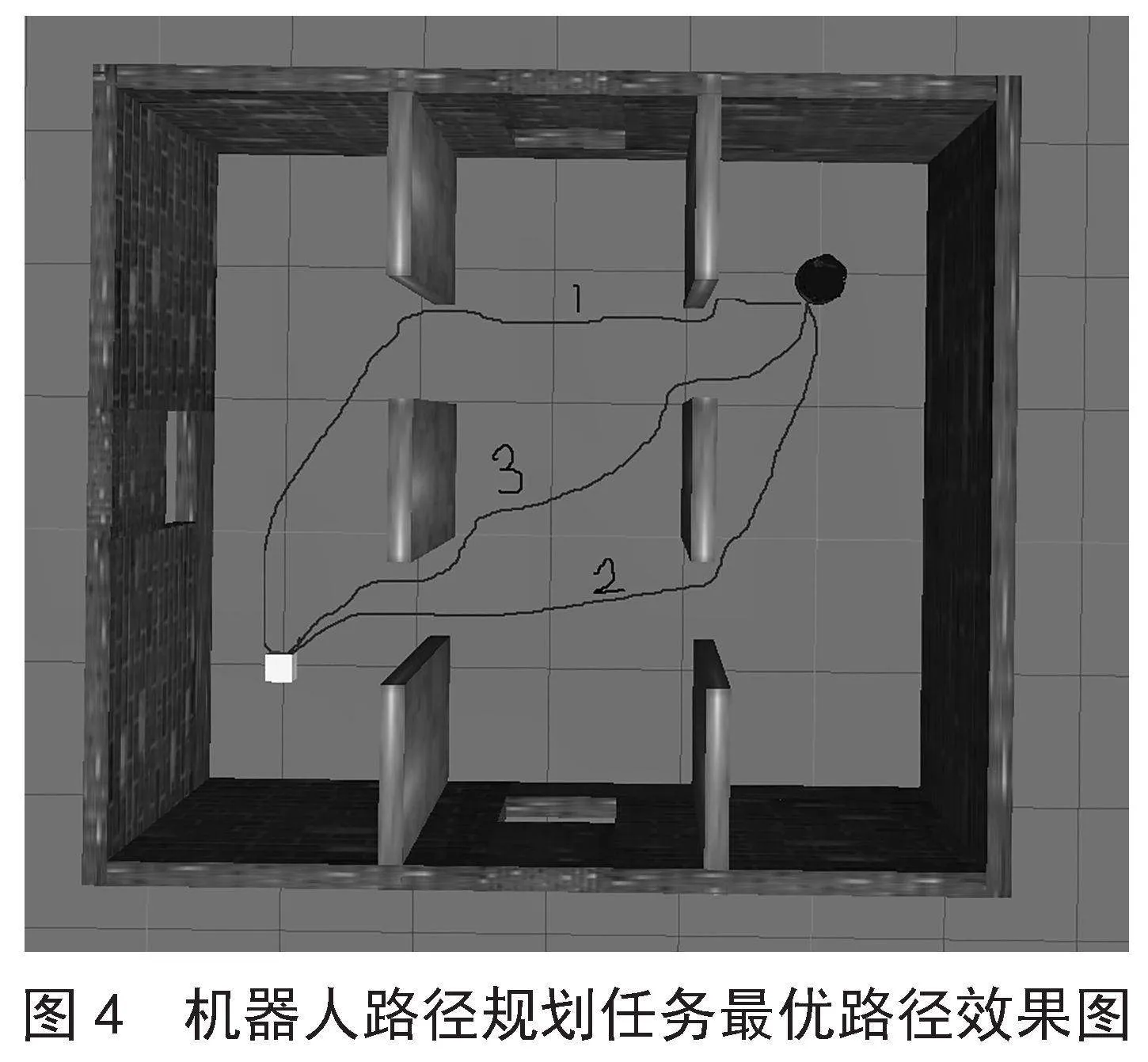
经实验得到三种算法的最优路径效果,如图4所示。
在图4中,1、2、3分别代表DDPG、PER-DDPG、LPER-DDPG经过机器人不断学习探索后得出的最优路径效果路线图。由图4可得出改进算法的路径是最优的,性能优于其他两种比较算法,由此可断定算法的改进方式是行之有效的。
4 结 论
本文提出一种基于学习潜力的经验回放机制的DDPG算法——LPER-DDPG。为了提高DDPG的收敛速度,首先提出一种全新的经验回放机制采样思想,利用TD误差和奖励值作为每个经验数据的学习潜力指标的评分标准;其次,综合考量两个因素的重要性,分别为它们赋予权重,得出评分依据;再次,将所设计的基于学习潜力的经验回放机制思想应用在DDPG中,形成改进算法LPER-DDPG;最后,为实现机器人路径规划任务而进行奖励函数和避障参数设计,构建机器人路径规划ROS环境等,将改进算法与机器人路径规划任务相结合,验证改进算法的有效性。实验结果表明,改进算法的收敛速度有了明显的提升。
参考文献:
[1] 张国胜,李彩虹,张耀玉,等.基于改进人工势场法的机器人局部路径规划 [J/OL].计算机工程,1-9[2024-02-15].https://doi.org/10.19678/j.issn.1000-3428.0068738.
[2] 刘建娟,刘忠璞,张会娟,等.基于模糊控制蚁群算法的移动机器人路径规划 [J].组合机床与自动化加工技术,2023(1):20-24.
[3] 冯舒,刘明.基于遗传算法改进的AGV路径规划研究 [J].现代电子技术,2024,47(4):123-127.
[4] 郭锦春,秦可,王超,等.基于优化Hopfield神经网络的海事飞机巡航路径规划 [J].航海,2023(5):28-31.
[5] 康振兴.基于路径规划和深度强化学习的机器人避障导航研究 [J].计算机应用与软件,2024,41(1):297-303.
[6] 李明,叶汪忠,燕洁华,等.基于深度强化学习的沙漠机器人路径规划 [J/OL].系统仿真学报,1-9[2024-02-15].https://doi.org/10.16182/j.issn1004731x.joss.23-1422.
[7] 张森,代强强.改进型深度确定性策略梯度的无人机路径规划 [J/OL].系统仿真学报,1-8[2024-02-15].https://doi.org/10.16182/j.issn1004731x.joss.23-1524.
[8] LILLICRAP T P,HUNT J J,PRITZEL A,et al. Continuous Control with Deep Reinforcement Learning [J/OL].arXiv:1509.02971v6 [cs.LG].[2024-02-19].https://arxiv.org/abs/1509.02971.
[9] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Human-level Control Through Deep Reinforcement Learning [J].Nature,2015,518(7540):529-533.
[10] 张龙飞,冯旸赫,梁星星,等.基于时间差分误差的离线强化学习采样策略 [J].工程科学学报,2023,45(12):2118-2128.
