基于PaddleOCR与Style-Text的金融票据手写体文本识别
2024-11-05张辉煌鸿硕



摘 要:该文提出一种基于 PaddleOCR 框架的金融票据手写体文本识别方法,通过引入基于生成对抗网络(GAN)的数据合成工具 Style-Text,增强模型对不同背景文本的识别能力。在真实的金融票据数据集上进行的实验表明,该方法在处理复杂文本和低质量图像方面表现出显著的优势,证明其在金融票据手写体文本识别中的有效性和实用性。
关键词:金融票据识别;PaddleOCR;数据合成;手写体;文本识别
中图分类号:TP391.4 文献标志码:A 文章编号:2095-2945(2024)30-0068-04
Abstract: This paper proposes a handwritten text recognition method for financial bills based on the PaddleOCR framework. By introducing Style-Text, a data synthesis tool based on GeYBXDgfRg+BmoO/I0YMqg5A==nerative Adversarial Network (GAN), it enhances the model's ability to recognize texts in different backgrounds. Experiments on real financial bill datasets show that this method has significant advantages in processing complex texts and low-quality images, proving its effectiveness and practicality in handwritten text recognition of financial bills.
Keywords: financial instrument recognition; PaddleOCR; data synthesis; handwriting; text recognition
金融票据作为金融交易和记录的基础凭证,其数字化处理对于提升业务效率、降低操作风险以及增强客户体验至关重要。手写体文本识别技术在这一过程中扮演着核心角色,尤其是在处理支票、银行汇票、信用卡账单等涉及手写信息的金融票据时。然而,手写体文本的高度变异性、不规则书写风格以及复杂的背景噪声,使得自动化识别任务充满挑战。尽管光学字符识别(OCR)技术已取得显著进展,但针对金融票据中的手写体文本识别,仍需解决准确率和鲁棒性的问题。所以,开发一种高效、准确的手写体文本识别算法,对于金融行业的现代化和数字化转型具有重要的战略意义。
1 本研究的贡献和创新点
本研究聚焦于金融票据手写体文本识别的难题,提出了一种基于PaddleOCR框架[1]的识别方案,并通过引入Style-Text数据合成工具[2],显著提升了模型对不同背景文本的识别能力。具体贡献和创新点如下。
第一,提出了基于PaddleOCR的金融票据手写体文本识别方案:结合金融票据的特殊性,采用了深度学习技术和GAN生成的数据集,显著提高了手写体文本识别的准确性和效率。
第二,引入GAN生成的数据集:使用Style-Text工具生成的数据集,提高了模型在不同背景和字体下的识别能力,增强了模型的泛化能力和鲁棒性。
本研究在理论和实践为金融行业的数字化转型提供了有力的技术支持,并在2022年广东省农村信用社联合社金融科技校园挑战赛中获得总决赛三等奖,充分证明了其在金融票据手写体文本识别中的有效性和实用性。
2 相关工作
2.1 手写体文本识别技术发展
手写体文本识别(Handwritten Text Recognition,HTR)技术的发展经历了从早期基于规则的方法到现代的基于机器学习,尤其是深度学习的方法的转变。在早期,手写体文本识别主要依赖于特征工程和传统机器学习算法,如支持向量机(SVM)和隐马尔科夫模型(HMM)。这些方法通常需要专家设计复杂的特征提取过程,并且在处理多样化的手写风格时存在局限性。
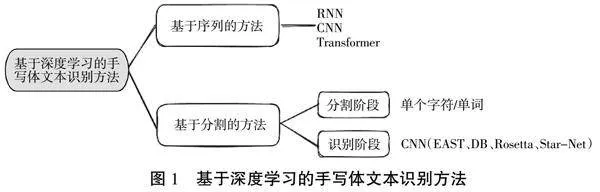
随着深度学习技术的发展,基于深度学习方法在手写体文本识别领域取得了重大进展。这些方法主要可以分为2类(如图1所示):基于序列和基于分割。
基于序列的方法主要基于循环神经网络(Recurrent Neural Networks,RNN)和卷积神经网络(Convolutional Neural Networks,CNN)。其中,RNN方法主要通过建立字符级别的序列模型来捕捉上下文信息,包括基于CTC(Connectionist Temporal Classification)[3]的方法和基于Attention机制的方法[4]。CNN方法主要基于卷积神经网络来捕捉特征,并结合CTC和Attention机制进行识别[5]。最近,基于Transformer模型的序列模型也开始应用于手写文本识别领域。
基于分割的方法则主要基于分割和识别2个阶段,分割阶段将手写文本分割为单个字符或单词,而识别阶段则主要使用CNN等模型对分割出的字符或单词进行识别。代表性方法包括EAST、DB、Rosetta、Start-Net等。
由上可见,手写体文本识别技术从依赖手工特征到利用深度学习自动学习特征转变,技术逐渐趋于成熟。尽管如此,针对特定应用场景的优化和改进仍然是研究的热点,随着深度学习技术的进一步发展和优化,手写文本识别的性能将会进一步提升。
2.2 数据集
本研究使用了4种数据集,简单介绍如下。
1)CASIA-HWDB数据集[6](如图2所示):该数据集由中国科学院自动化研究所在2007—2010年间收集,它包含1 020人书写的脱机(联机)手写中文文本,使用Anoto笔在点针纸上书写后扫描、分割得到,数据集包含数千个手写文本文档,由多种书写方式和多个手写者书写,覆盖了各种字体、字号和倾斜角度等情况。利用该数据集可以提高OCR系统在长文本识别方面的准确性。
2)HCL2000单字数据集[7](如图3所示):该数据集包含1 000人手写的3 755个常用汉字字符集,共有3 000多万个图像数据。
3)由“科创金融,趣码未来”广东省农信联社2022年金融科技校园挑战赛主办方提供的真实业务场景下金融票据图像切片数据集,该数据集包括3 148张图像,分为4类,分别涉及银行名称、地址信息、金额、用途。图像中存在一定量的干扰信息,通过图像二值化运算,可以消除部分背景干扰(如图4所示)。
4)基于GAN的数据合成工具Style-Text合成的数据集[2]:该工具可以生成各种样式的手写体文本图像,包括不同的字体、颜色、形状和倾斜角度等,使用该工具可以扩充数据集,从而提高OCR系统的鲁棒性和准确性。
2.3 图像预处理
在金融场景下,票据图像质量可能会受到多种因素的影响,例如光照不足、图像模糊、扭曲变形等,这些因素会直接影响手写体文本识别的准确性。因此,本研究采取了以下预处理步骤来提高图像质量。
1)图像增强:使用直方图均衡化技术对图像进行增强,提高图像对比度。
2)图像去噪:使用基于小波变换的去噪算法对图像进行降噪处理,去除图像中的噪声干扰。
3)图像二值化:使用基于Otsu阈值法的二值化方法将图像转换为二值图像,便于后续的文字分割和识别。
4)图像切割:使用基于连通域分析的切割算法对图像进行文字切割,将每个字符分离出来,便于后续的识别。
5)文本检测预处理:对输入图像进行文本检测预处理,例如缩放、裁剪、旋转等操作,以确保输入图像适合文本检测模型。
6)文本识别预处理:对检测到的文本区域进行预处理,例如调整大小、去除噪声、二值化等操作,以提高文本识别的准确性。
2.4 模型选择
2.4.1 文本检测模型
根据PaddleOCR文档展示的在公开数据集上不同文本检测算法的效果比较,可以看出不同的文本检测模型在不同的骨干网络和数据集上的性能表现有所不同。在ICDAR2015数据集上,骨干网络为ResNet50_vd的SAST模型表现最好,其次是骨干网络为ResNet50的DB++模型。在Total-text数据集上,骨干网络为ResNet50_vd的SAST模型表现最好。目前PaddleOCR仅支持2种骨干网络,分别是MobileNetV3、ResNet_vd系列,因此我们选择骨干网络为ResNet50_vd的SAST模型作为文本检测模型。
2.4.2 文本识别模型
根据PaddleOCR文档展示的在公开数据集上不同文本识别算法的效果比较,可以看出SVTR的平均精度(Avg Accuracy)最高,达到了89.25%,其次是ABINet和VisionLAN,因此我们选择骨干网络为SVTR-Tiny的SVTR模型作为文本识别模型。
3 算法验证与实验结果分析
3.1 实验设置
为了验证基于PaddleOCR框架和Style-Text数据合成的金融票据手写体文本识别方法的有效性,本研究设计了一系列实验。以下是实验设置的详细描述。
1)数据集准备:实验主要使用了前述4个不同的数据集。所有数据集在输入模型之前都经过了严格的预处理,包括图像增强、去噪、二值化和切割,以提高后续识别任务的准确性。
2)模型配置:根据PaddleOCR文档展示的在公开数据集上不同文本检测算法和不同文本识别算法的效果比较,本研究采用了SAST模型作为文本检测模型,选择了基于SVTR-Tiny的SVTR模型作为文本识别模型。所有模型均在金融票据数据集上进行了进一步的训练和微调。
3)训练过程:模型训练采用了端到端的训练策略,其中包括文本检测和识别2个阶段。在文本检测阶段,模型通过学习区分文本区域和非文本区域来定位文本。在文本识别阶段,模型则学习将检测到的文本区域映射到正确的文本序列。模型训练使用了基于PaddlePaddle的优化算法,并设置了适当的学习率(为0.001)和批次大小(为16)。
4)模型评估:我们选择了多种评估指标,包括精确率(Precision)、召回率(Recall)、HMean(即F1值)和每张图像的处理帧率(FPS)。准确率和召回率用于衡量模型在文本识别任务上的表现,HMean则是两者的调和平均,提供了一个综合的性能度量。FPS指标则用于衡量模型在实际应用中的处理速度。
通过上述实验设置,本研究旨在全面评估所提方法在金融票据手写体文本识别任务中的性能,并探讨其在金融业务中的应用潜力。
3.2 实验结果
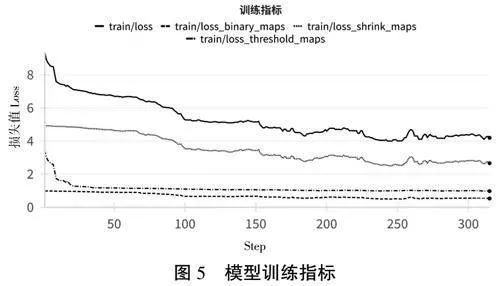
3.2.1 模型训练指标
模型训练过程的评价采用了Loss、Loss_threshold_maps、Loss_shrink_maps、Loss_binary_maps等指标(如图5所示)。这些指标可以用来评估模型在训练过程中的表现和学习进度,也能反映模型在不同阶段的表现和学习效果。在训练过程中,训练集和验证集上的损失都逐渐下降,收敛于较小的值,没有出现过拟合。Loss_shrink_maps 和Loss_threshold_maps指标在训练中的稳定性和低损失值表明了模型在此任务上的有效性。
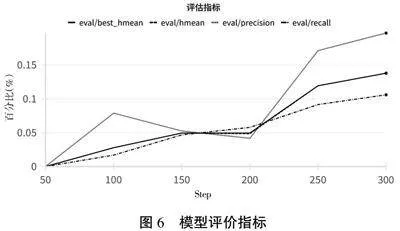
3.2.2 模型评估指标
模型在测试集上的评估指标包括HMean、Precision、Recall、Best_HMean等(如图6所示)。
从实验评估指标展示结果中可以看出,模型在金融票据手写体文本识别中取得了较好的性能,模型在不同阈值下的表现差异较小,说明模型具有较好的鲁棒性。但是,模型在某些情况下仍然存在错误识别的情况,需要进一步优化模型的准确率。
3.2.3 模型部署和推理
本研究将训练所得的模型部署在移动端APP上,进行性能实测。在实际测试中,该模型可以快速处理各种形状、大小、颜色的金融票据,并将该文本准确地提取出来。模型在移动端的最大处理效率约为每秒5帧,满足金融票据识别的性能要求。
3.3 结果分析
本研究通过一系列实验全面评估了基于PaddleOCR框架和Style-Text数据合成工具的金融票据手写体文本识别方法。以下是对实验结果的深入分析和讨论。
1)模型性能:实验结果显示,模型在金融票据手写体文本识别任务上取得了显著的性能提升。特别是在处理复杂背景和低质量图像时,模型展现出了较高的准确率和召回率。这一结果验证了PaddleOCR框架和Style-Text数据合成工具在提高模型泛化能力和鲁棒性方面的有效性。
2)鲁棒性:模型在不同阈值下的表现差异较小,表明了其在各种条件下的鲁棒性。这一点在金融票据识别中尤为重要,因为票据的质量和背景条件可能存在很大差异。
3)处理速度:模型的FPS指标表明,我们的识别系统不仅准确,而且高效。这对于需要快速处理大量票据的金融业务场景至关重要。
+dbeZHwzFPJwisVbnjx4wg==4 结论
本研究中通过一系列实验全面评估了基于PaddleOCR框架和Style-Text数据合成工具的金融票据手写体文本识别方法。实验结果显示,改后模型框架在金融票据手写体文本识别任务上取得了显著的性能提升。特别是在处理复杂背景和低质量图像时,模型展现出了较高的准确率和召回率。同时,模型在不同环境下的鲁棒性和处理速度得到了很大的提升。
本研究推动了金融票据识别技术的自动化和智能化,为相关领域的OCR应用提供了宝贵的经验和技术支持。然而,研究仍存在局限性,如长文本背景风格的单一性和形近字识别难题,未来研究仍需探索更多样化的数据合成技术和精细的识别策略,提高对复杂背景和模糊手写文本的识别能力,并探索更高效、智能的金融票据处理流程。
参考文献:
[1] LI C, LIU W, GUO R, et al. PP-OCRv3: More attempts for the improvement of ultra lightweight OCR system[J]. arXiv preprint arXiv:2206.03001,2022.
[2] WU L, ZHANG C, LIU J, et al. Editing text in the wild[C]// Proceedings of the 27th ACM international conference on multimedia, 2019:1500-1508.
[3] GRAVES A, GRAVES A. Connectionist temporal classification[J]. Supervised sequence labelling with recurrent neural networks, 2012:61-93.
[4] FUKUI H, HIRAKAWA T, YAMASHITA T, et al. Attention branch network: Learning of attention mechanism for visual explanation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019:10705-10714.
[5] SHI B, BAI X, YAO C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2016,39(11):2298-2304.
[6] LIU C L, YIN F, WANG D H, et al. CASIA online and offline Chinese handwriting databases[C]//2011 international conference on document analysis and recognition. IEEE, 2011:37-41.
[7] ZHANG H, GUO J, CHEN G, et al. HCL2000-A large-scale handwritten Chinese character database for handwritten character recognition[C]//2009 10th International Conference on Document Analysis and Recognition. IEEE, 2009:286-290.
基金项目:广东省科技创新战略专项资金立项项目(pdjh2022b0720)
第一作者简介:张辉煌(1999-),男,大模型产品经理。研究方向为大语言模型在实际业务场景的应用。
