一种基于冷扩散模型的复杂反应流场建模方法
2024-11-04陈俊宏程辉胡贵华


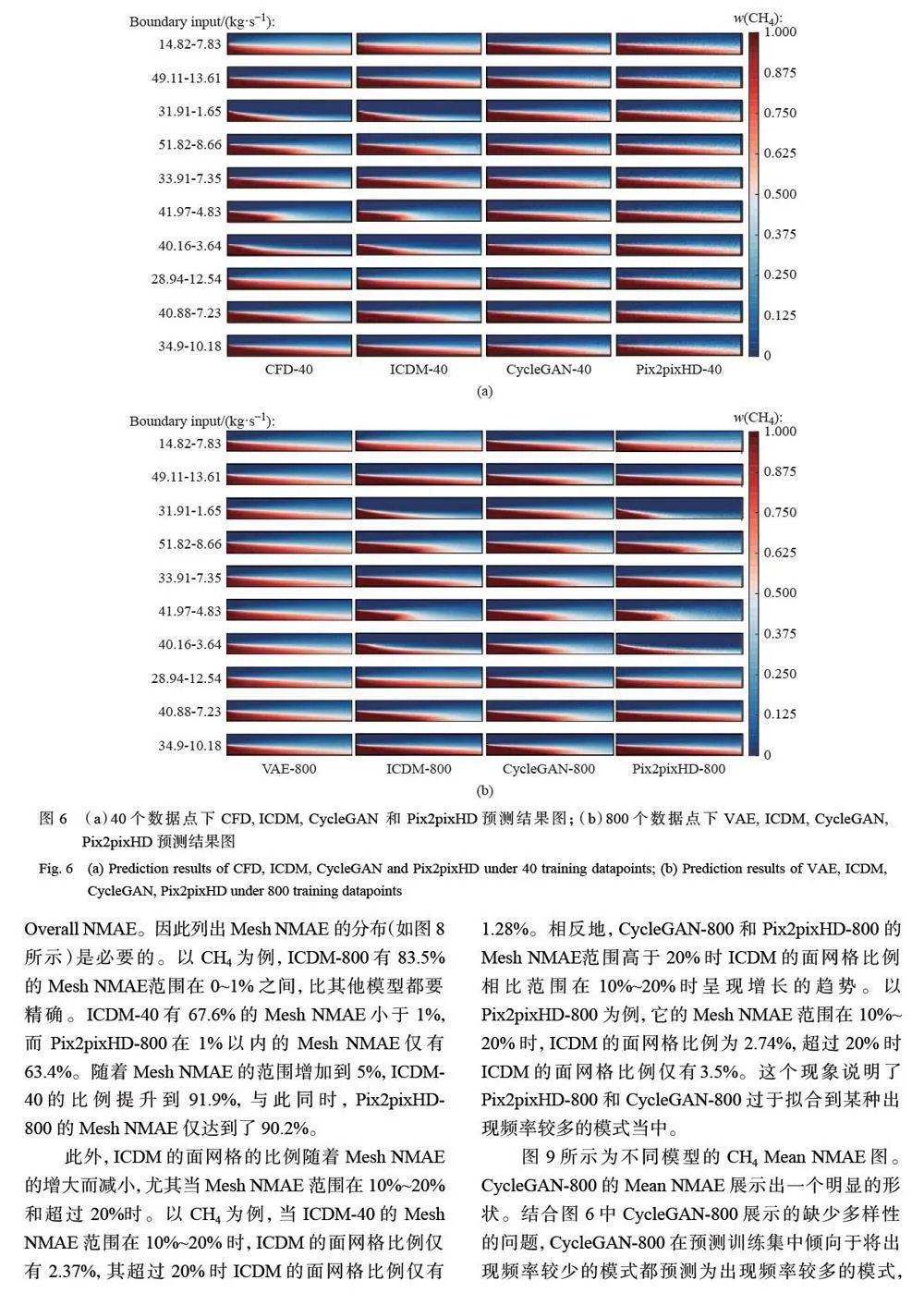


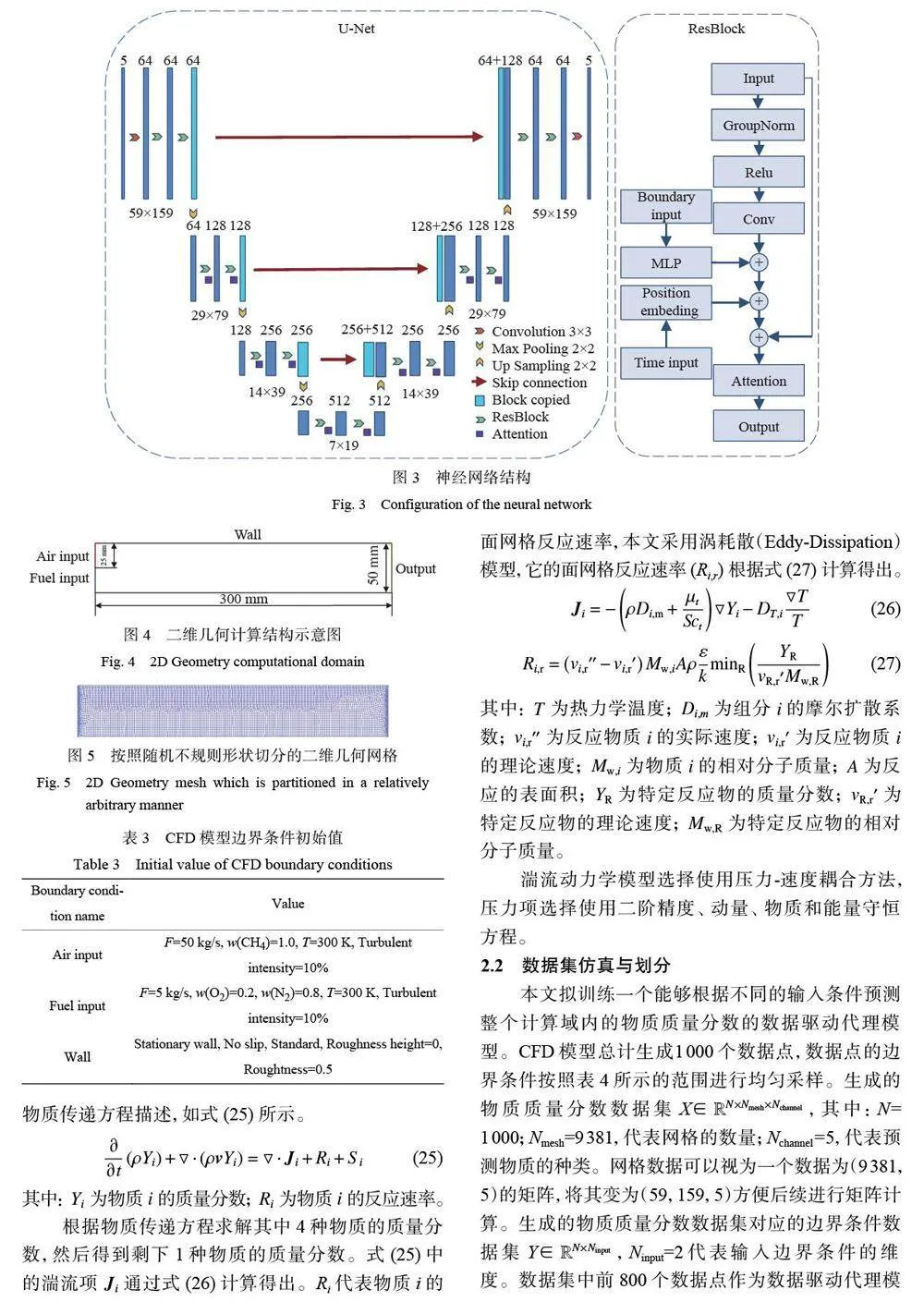
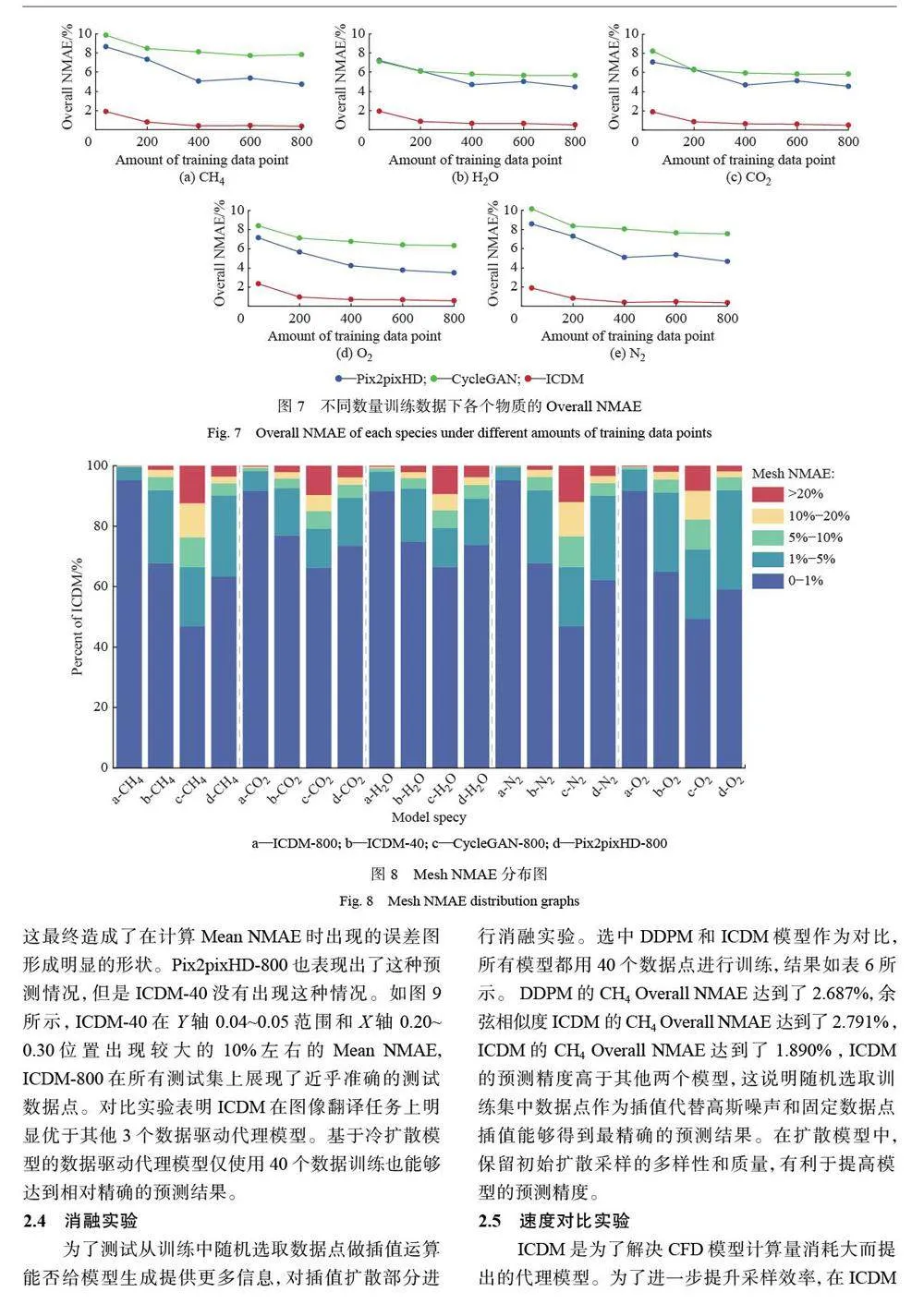



摘要:仿真复杂湍流反应流场的计算消耗巨大,为了缓解计算负担,许多研究基于深度学习方法构建数据驱动代理模型,但获取该代理模型所需要的数据仍存在一定困难。为了解决上述问题,本文提出一种基于冷扩散模型(Cold Diffusion Model,CDM)的代理模型。与去噪扩散概率模型( Denoising Diffusion Probabilistic Model,DDPM)不同,插值冷扩散模型在扩散过程中采用逐步插值替代加入随机高斯噪声,为复原过程引入更多信息。二维甲烷燃烧仿真实验结果表明,相比其他代理模型,插值冷扩散模型能够利用有限的数据,学习到更多的信息,减少训练所需的计算数据量,从而缓解计算负担。
关键词:湍流反应流;计算流体力学(CFD);代理模型;扩散模型;图像翻译
中图分类号:TQ038.4 文献标志码:A
仿真湍流反应流场是一个过程极其复杂的多学科问题,其中包含化学反应、燃烧过程、湍流运动。在计算流体力学(Computational Fluid Dynamics,CFD)中主要有3 种数值求解方法用于湍流反应流场的仿真,分别是直接数值模拟(Direct Numerical Simulation,DNS) [1],大涡模拟( Large Eddy Simulation, LES) [2-3],以及雷诺平均方法(Reynolds Averaged Navier-Stokes,RANS)[4]。RANS 方法的计算消耗在3 种数值求解方法中相对较低,因此被广泛应用于仿真湍流反应流场。杨梦如等[5] 应用基于RANS 的Realizablek-ε 湍流模型求解不同稀释剂条件下的甲烷燃烧场,陈佳豪等[6] 基于RANS Standard k-ε 湍流模型分析不同结构下的旋塞阀流场。但即使是RANS 方法,仍需要求解大量描述湍流运动和反应机理的偏微分方程。计算消耗巨大仍然是实现快速仿真湍流反应流场不得不解决的问题。
代理模型是指能够近似代替原来精确并且计算消耗大的目标函数的模型,采用数据驱动的代理模型是解决仿真湍流反应流场计算消耗巨大问题的一个重要方法。数据驱动代理模型的类型有很多,可以分为基于非深度学习方法的数据驱动代理模型与基于深度学习方法数据驱动代理模型。有许多非深度学习的机器学习方法应用于湍流反应流场仿真中,Edeling 等[7] 使用贝叶斯估计改进RANS 方法,通过估计k-ε 湍流模型系数的变化,增强流量预测的精度。Chung 等[8] 提出了一种基于随机森林的数据驱动代理模型,他们整合了包含有限速率反应模型等几个不同的燃烧模型,将燃烧过程中6 个关键热物性参数作为输入参数,优化模型标签降低模型的误差,最终实验结果表明,基于随机森林分类器的数据驱动代理模型相比单个燃烧模型,实验精度更高,计算消耗降低了20%。Perini 等[9] 使用K-means聚类算法,对温度、物质质量分数等高维度的流场数据进行聚类,确定最优聚类参数,在仿真计算过程中,对每个时间步上的计算网格进行聚类,减少系统集成所需要的计算时间,在计算速度上有3~4 倍的提升。Zhao 等[10] 在CFD 计算过程中加入一个用来评估的损失函数,利用基因表达编程的方法优化RANS 方法在计算过程中的损失函数,该损失函数可以基于CFD 中任何流动特征来定义,因此具有极强的适用性。
