电力标准的自动结构化技术研究
2024-10-21胡维刘晗刘勇
摘 要:电力标准规范是电力行业知识和信息的主要载体,也是丰富的知识宝库。对标准的有效处理与深度挖掘对于电力知识管理和决策支持具有至关重要的作用。为了顺应标准数字化的潮流,对于电力行业标准进行结构化的技术研究势在必行。另一方面,电力行业标准文档具有结构明确、内容清晰,用语简介等特点,适合进行结构化加工、信息抽取和知识工程的加工处理。因此,本文面对行业标准特征和电力业务的具体需求,提出了电力行业标准规范的自动结构化加工的技术,并针对网络安全领域进行结构化加工的训练和验证。
关键词:技术标准,结构化加工
0 引 言
文档结构化技术是指通过对文档内容进行分析和处理,将无结构的文档转化为结构化数据的一种技术。它可帮助我们更好地理解文档的内容和关系,提供更高效、准确的信息检索和管理功能。对于电力标准文档而言,文档的结构化指的是通过对标准的PDF文件进行识别、抽取、标注等信息加工,生成分类明确、结构清晰、索引规范的结构化信息。
相比于非结构化文本,结构化后的信息具有两个主要优势:增强人类阅读理解和实现机器可读。对读者来说,结构化可以降低理解难度,简化检索过程,增进阅读效率;对机器来说,通过对各种信息的分类、标注和抽取,来实现各种模型于数据的对接;同时,结构化也使得进一步的利用加工成为可能,包括但不限于文本处理、机器学习,以及大模型训练和知识图谱构建。
电力领域的专用工具缺失是目前电力行业业界面临的主要问题,通用的结构化工具并不能满足电力行业对结构化加工的具体需求。另一方面,为了数据安全和技术独立,应减少对“黑盒”网络服务平台和相关API的依赖,开发自研的、可以本地离线运行、可以独立部署的结构化工具。因此本文提出了针对电力行业标准的结构化加工实现方案。
1 研究现状
结构化知识抽取研究主要包括实体识别、版式识别。
版式识别方面,比较常见的有基于连通域的版面分割算法、游程码平滑分割算法、基于图像背景的分割算法、纹理分析算法[1-4]。
实体识别方面Zhang 等人[5]首先提出了一种名为Lattice-LSTM 的结构用于中文命名实体识别任务,该模型对 LSTM 进行了改进,将单一字符匹配的词语编码为有向无环图,利用了词汇信息,在各个数据集上取得了较为不错的结果;Ma 等人[6]借鉴了 Lattice-LSTM 中结合词汇的思想,在嵌入层引入词汇集合,融合了词级信息,减少信息损失,进一步提升了结果;Li 等人[7]将 Transformer 结构应用于中文命名实体识别任务中,利用其位置编码重构 Lattice 结构,因此融合词汇信息的 Transformer结构既能凭借全连接自注意力结构捕捉上下文中的长距离依赖信息,又能借助全新的位置编码方式更高效地定位实体边界。随着以 BERT[8]为代表的预训练语言模型的发布,其已在诸多下游任务中取得了极佳的结果。
2 系统设计
2.1 总体思路
本文结合版式识别、模式识别与语义标注技术,通过将标准文档的结构化过程视为对文档内容组件的识别与标注任务,构建了电力专业标准结构化加工模型。该模型以电力行业标准的pdf文档为输入,通过对文档的内容识别与标注,形成结构化、语义化信息,并最终以XML、JSON、Markdown等形式输出。
2.2 系统框架设计
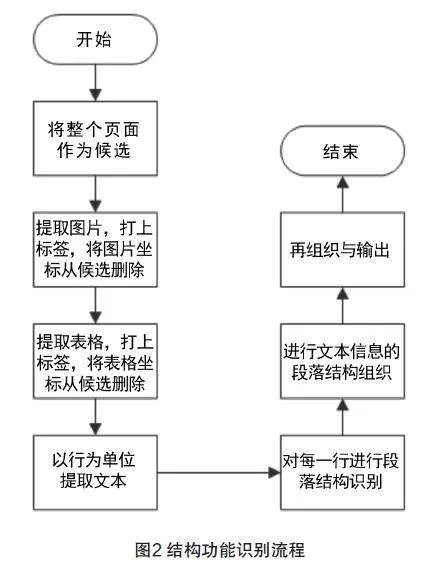
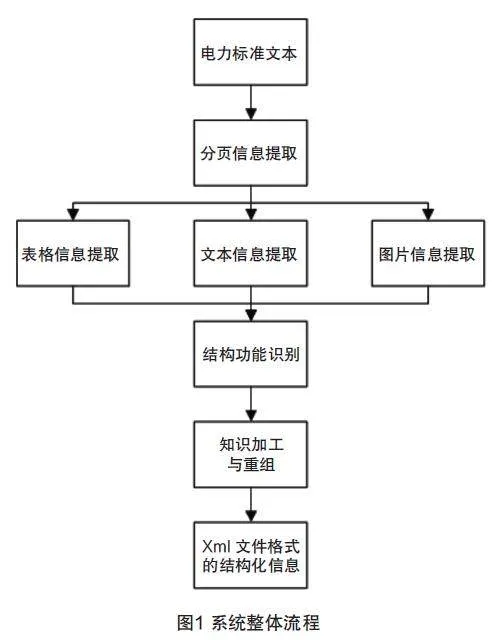
本文设计的结构化加工工具主要流程包括以下几个部分:(1)PDF文档信息提取,(2)文本信息处理,(3)多模态信息的提取和处理:包括图片信息和表格信息,(4)对不同元素的结构功能识别,(5)知识加工与信息再组织,(6)以XML为例的结构化信息输出。系统整体流程如图1所示。
2.3 系统关键技术
2.3.1 文本信息处理
本文设计的文本信息处理方法主要包括3个部分,段落结构识别、标题识别、标题与正文的对应关系识别。
(1)段落结构识别
在PDF文件中,每个单独的字都被视为一个独立单元,因此,文本信息加工的第一步是将独立单元的文字根据位置信息组成“行”,再组成“段”。
1)行结构判定
本文中行结构判定的实现逻辑为,针对相邻的一组字符元素,进行“一组文字是否给构成一行”的判别任务。通过基于规则或机器学习的方式,判断一组文字的排列方式(表现为每个文字的横坐标和纵坐标的特征)是否满足篇章排版中作为一行文字的判断标准。本文中使用的判断规则为:①文字的上边界和下边界分别在相同的横坐标上(误差不超过3dpi)。② 纵坐标的差值统一且小于某一阈值。
2)段落结构判别
本文采用了基于规则的判别方法,即针对每一行文字,判断该文字是否具有首行、末行以及中间行特征,并根据首行、末行以及中间行的判定组成段落结构。具体规则为:①是否由首行的4字符长度的缩进;②是否由句号或分号结尾;③行右端是否达到了页面排版范围的边界。
(2)标题识别
本文的采用了基于内容的判断方式。
1)通过目录页抽取一级标题,形成一级标题列表,并逐项进行比对。
2)二级及以上的标题通过内容的正则表达进行判断:即是否由【数字-点-数字】(如3.3)的形式开头,且该行结尾没有标点。
3)通过【数字-点】的数量判断标题等级。
(3)标题与正文的对应关系识别
本文中标题与正文的对应关系识别通过被识别为标题的段落块的坐标信息与被识别为正文的段落块信息之间的相对位置关系进行对应关系识别。即,纵坐标在第一个标题下,和第二个标题之上的段落块被认定为第一个标题下的正文内容。
2.3.2 表格信息提取
在本文中表格信息提取分为表格识别和表头识别。
(1)表格识别
本文使用pdfplumber和tabula工具进行表格信息的抽取。抽取的逻辑是:对于任何给定的PDF页面,找到(a)明确定义和/或(b)由页面上的单词对齐所暗示的行。然后找到合并重叠或几乎重叠的线,并求出所有这些直线的交点。再根据交点找到使用这些交点作为顶点的最细粒度的矩形集合(即单元格),最后将连续的单元格分组到表中。
(2)表头识别
对表格前后的文本进行正则判断:利用表头的特殊格式,即“表+编号+空格”,以及特殊格式(居中)进行抽取。同时考虑了跨页处理。
(3)表格内容识别
分块识别表格内的文字并统一输出成表格型数据进行储存。
2.3.3 图片信息提取
本文设计的图片提取方法包括图片提取和图片名称提取两个部分。
(1)图片提取
本文使用spire.pdf和pymupdf工具进行提取。通过对每一页应用图片提取算法,按顺序抽取出pdf的图片及其坐标。
(2)图片采用类似表头识别的判定方法,对与表格相距最近的段落块进行判定。
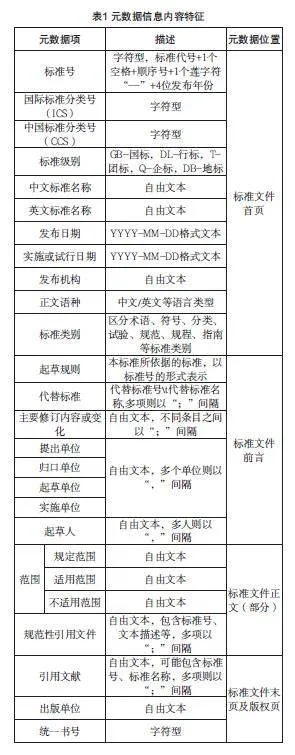
2.3.4 元数据识别
本文根据各类元数据信息的内容特征、位置信息和字体格式信息进行综合判断及抽取。表1所示是封面、前言涉及到的元数据信息的内容特征。
2.3.5 结构功能识别
对每一页中的每一个元素进行结构功能识别的各项判定,根据不同的信息在文档中的位置信息和内容特征、以及抽取的字体信息,进行“学习”的方式,判定其结构功能,并通过标签的形式,将该元素/信息单元在篇章结构中的版式功能进行标注。在完成所有页的所有元素的结构功能识别后,再根据各元素的标签进行整理和再组织。具体如图2所示。
2.4 系统验证和应用
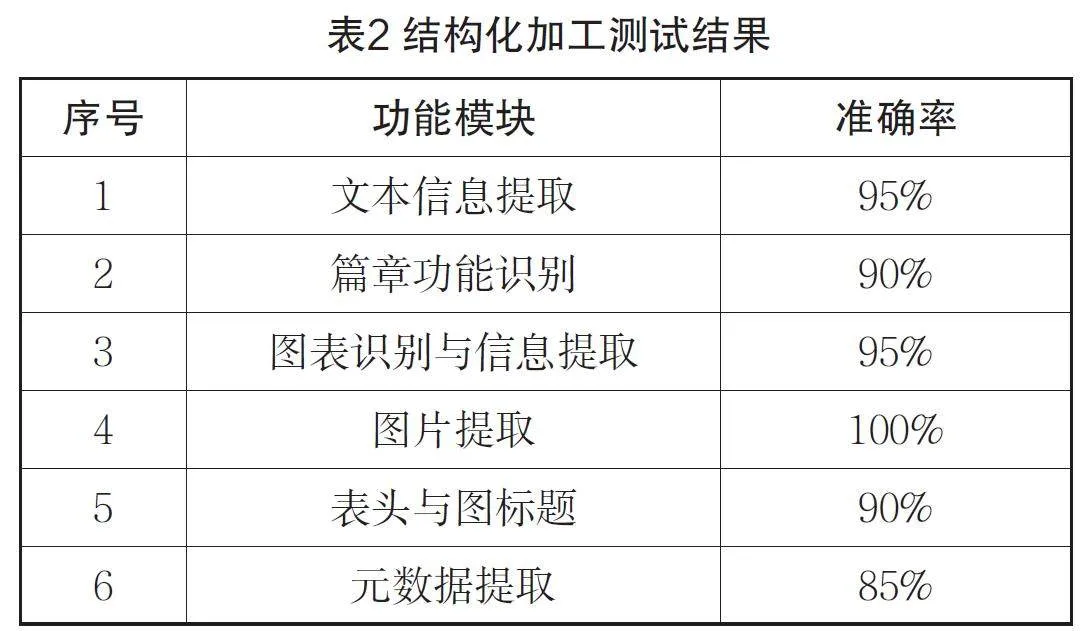
本文选取了网络安全领域的4个标准PDF文档进行加工实验:Q/GDW 10597-2022《应用软件系统通用安全技术要求及测试规范》、Q/GDW11445-2022《管理信息系统安全基线要求》、Q/GDW 10929.5-2018《信息系统应用安全 第5部分:代码安全检测》和Q/EPRI 075-2016《国家电网公司移动应用软件安全技术要求及测试方法》。具体测试结果如表2所示。
从实验结果可以看出,在结构化加工各功能模块的准确率均在85%以上,其中图片提取准确率达到100%。
3 总 结
标准文本数据是标准数字化研究的样本基础,有了详实有效的数据才能更好地开展标准数字化研究,本文根据电力技术标准的特点设计了一种结构化加工工具,该工具为后续标准数字化的研究提供了有效的标准文本数据支撑。
参考文献
参考文献
[1]Mi n g Y U,Q ia n G , D on g z hu a n g W, et a l . I mpr ove d connectivity-based layout segmentation method[J ].Computer Engineering&Applications,2013.
[2]O Mccallister W,Hung C C.Image segmentation using dynamic run-length coding technique[J].2003.
[3]Yong Z,Jianzheng Y,Hongzhe L,et al. GrabCut image segmentation algorithm based on structure tensor[J].The Joournal of China Universitites of Posts and Telecommunic ations,2017(02):42-51.
[4]Argenti F,Alparone L .Benelli G.Fast algorithms for texture analysis using co-occurrence matrices[J].IEE Processing,1990,137(6):443
[5]Zhang Y, Yang J. Chinese NER Using Lattice LSTM[C].Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).2018:1554-1564.
[6]Ma R, Peng M, Zhang Q, et al. Simplify the Usage of Lexicon in Chinese NER[C].Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.2020: 5951-5960.
[7]Li X, Yan H, Qiu X, et al. FLAT: Chinese NER Using Flat-Lattice Transformer[C].Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.2020: 6836-6842.
[8]Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirect iona l Tra nsfor mer s for L a ng ua ge Understanding[C]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,Volume 1 (Long and Short Papers). 2019: 4171-4186.
基金项目:本文是国家电网有限公司指南项目“标准文本资源及关键要素统一构建技术研究”(项目编码5216A624000B)研究成果。
