基于特征和语义的电网设备技术标准差异分析方法研究
2024-10-21王瑞杰王倩王军袁葆玄鑫郑倩
摘 要:针对电网设备技术标准条款内容存在差异问题,提出了一种基于特征和语义的电网设备技术标准差异分析方法。该方法通过条款特征提取、特征语义分析、特征权重评定和条款差异分析4个环节,有效解决传统文本相似度计算方法适用性不足的问题。进一步对电网设备技术标准条款结构化,分析挖掘条款间存在的差异情况。通过真实标准条款进行实验,将本文方法同其他算法比较,结果表明本文所提方法在相似度计算方面优于其他参与比较算法,并能指出条款的差异情况。
关键词:电网设备,技术标准,相似度,差异分析
0 引 言
标准被定义为可用于通过提供特性、指南、规范或要求来确保产品、流程、服务和材料适合其目的的文件(国际标准化组织,2017)。目前,电网设备技术标准条款内容存在差异,利用NLP(Natural Language Processing,自然语言处理)等处理电力行业的标准差异条款问题尚不成熟,NLP是将人类间交流沟通转化为机器语言,目的是实现人机交互[1-2]。基于词嵌入、深度学习和无监督学习与迁移学习和语言模型与机制等关键技术,自然语言处理实现了中文分析、语义分析和命名实体识别、构建知识图谱和信息检索等功能。目前,国家越发重视自然语言处理、大模型等人工智能技术,因此,对自然语言处理进行深入研究具有重要作用。
语义相似度指的是词义之间的相似程度,由语义距离和语义相关性决定。影响语义相似度的因素有语义关系、语义距离、调节参数和节点深度。近年来,语义相似度已经成为自然语言处理中的重要研究方向,并且在众多场景如智能问答、实体消歧[3]、舆情分析、情感分析[4]都应用广泛。文本相似度是通过其内容属性及非内容属性确定相似程度[5]。文本相似度计算是通过将文本转化为特征向量,通过对比两个文本的向量值来判断其相似度[6]。文本相似度计算应用于文本查重、文本分类检索[7],智能推荐系统[8]等多方面,同时,在电力智能交互平台上,系统可以根据用户提问,通过自然语言处理快速检索,将结果反馈给用户[9]。
1 文本相似度
文本相似度从文本的长短程度可以分为长文本相似度和短文本相似度。早期对文本相似度的研究主要是通过关键词匹配来实现,而忽略了语义的重要性。文本相似度对于文本分类、词义消歧、关系抽取等方面具有至关重要的作用。随着大模型等人工智能技术的发展,目前,主要有两种主要的文本相似度研究方向。
基于词频的文本相似度算法是通过比较文本中词语的相似性来判断其相似程度,如:TF-IDF(Term Frequency-Inverse Document Frequency)[9],它通过词频来区分与其他文档的特征。最长公共子序列(LCS)算法[10]是通过查找文本间的最长公共序列来计算文本相似度。SimHash[11]提出了一种新的局部敏感哈希算法,通过哈希函数将文本转化为向量,进而通过计算两个向量之间的余弦来评估相似度。俞婷婷提出一种基于改进的Jaccard系数文档相似度计算方法,该方法主要考虑词在文档中所占比例来计算文本相似度[12]。
基于深度学习的文本相似度算法研究主要有无监督学习和有监督学习两种方法。google在2013年提出word2vec,通过windows窗口的移动来获取词的上下文关系,从而将词转化为向量。Huang[13]等提出一种深度学习模型,该模型将高纬度向量转到低维度向量,然后通过两个低纬度向量的余弦值来计算短文本相似度,同时,还使用了单词哈希的技术扩大了深度语义模型,以便于处理大规模的数据。Shen等人[14]提出了CLSM(Convolutional LatentSemantic Model),该模型从每个词开始通过卷积层来获取上下文关系以降低维度,用于搜索查询和Web文档的语义向量表示。ReimersN等人[15]提出了S-BERT模型,该模型基于BERT模型,通过两个编码解码的双塔网络来实现文本相似度的计算。卢美情[16]提出一种基于SBERT的文本匹配改进模型SBMAA。该模型首先利用SBERT实现文本的向量化表示,同时,引入多头注意力的对齐,增加句向量交互,并通过拼接融合层来获取交互信息的能力。实验表明,提出的SBMAA模型能够有效提升文本匹配的效果,且具有一定的鲁棒性。目前,针对电网设备技术标准条款内容存在差异问题,本文提出一种基于特征和语义的电网设备技术标准条款差异分析方法。
2 基于特征和语义的标准条款差异分析方法
基于特征和语义的电网设备技术标准条款差异分析方法包含4方面内容:条款特征提取、特征语义分析、特征权重评定、条款差异分析。
2.1 条款特征提取
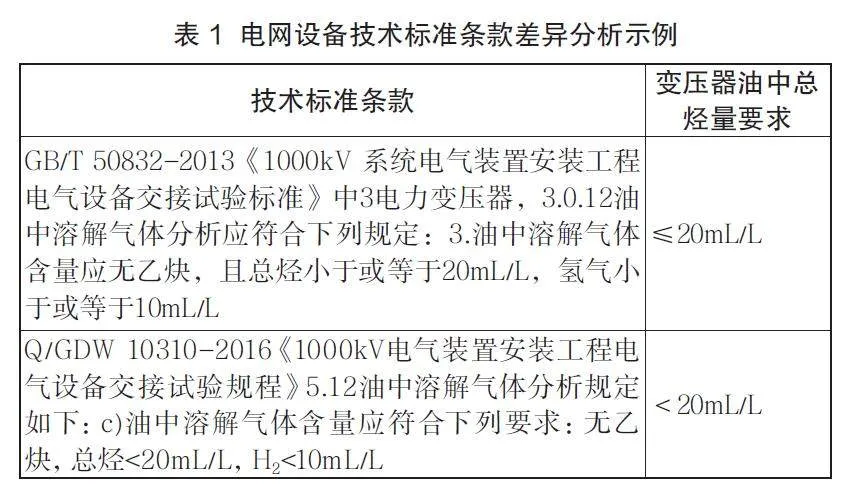
在电力行业技术标准条款中,实体词语和语义是选择特征词的两个主要依据。传统通过词频、语义等方法选择文本关键词,容易遗漏数量较少的核心关键词。在此,以电网设备技术标准条款为例来说明此问题,“GB/T 50832-2013《1000kV 系统电气装置安装工程电气设备交接试验标准》中3电力变压器,3.0.12 油中溶解气体分析应符合下列规定:3.油中溶解气体含量应无乙炔,且总烃小于或等于20mL/L,氢气小于或等于10mL/L。”“电力变压器”作为核心关键词,在本条条款中仅出现1次。因此,本文方法基于HanLP中文分词、命名实体识别和电网设备专业词库从条款文本中提取特征词。
从电网设备技术标准中拆解的条款记作c,第i个条款记作ci。从标准条款ci中提取的实体、属性等内容作为特征词fj(j=1,2,…,l),形成特征词集合Ai,即Ai={f1,f2,…,fl}。例如:示例条款提取的特征词集合A={电力变压器,油,溶解气体,乙炔,氧气…}。
2.2 特征语义分析
为了解决特征词一义多词问题,确定实体、属性和属性值之间的关系,采用语义理解技术开展特征词标准化处理和条款内容深入分析。
特征词标准化处理。本方法采用电网设备专业词库与欧氏距离结合的方式开展特征词标准化处理,若在电网设备专业词库中明确指出该特征词不是标准词语,则以词库中的标准化特征词进行替换;若在电网设备专业词库中未找到类似词语,则将该特征词作为标准词语,并补充进专业词库。
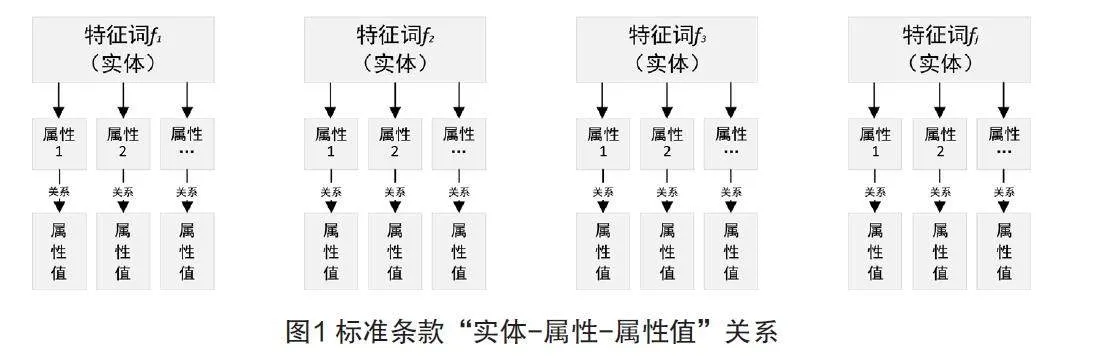
标准条款内容深入分析。基于HanLP词性标注对标准条款内容进行深入分析,挖掘条款中存在的“实体-属性-属性值”关系,如图1所示。
2.3 特征权重评定
本文方法结合电网设备图谱网络拓扑和特征词位置计算特征词权重。
定义1 特征词fj在电网设备网络拓扑中距离根节点的最短距离记作Dfj。
定义2 特征词fj在标准条款中的位置记作Pfj。若特征词fj从技术标准的标题中提取,则Pfj=1;若特征词i从技术标准的非标题中提取,则Pfj=2。
根据定义1、定义2,特征词 的权重按式(1)计算:
ωi=α×Dfj+β×Pfj(1)
其中,α和β为常数,分别表示Dfj和Pfj的占比;特征词i的权重值ωi越小,代表特征词越重要。
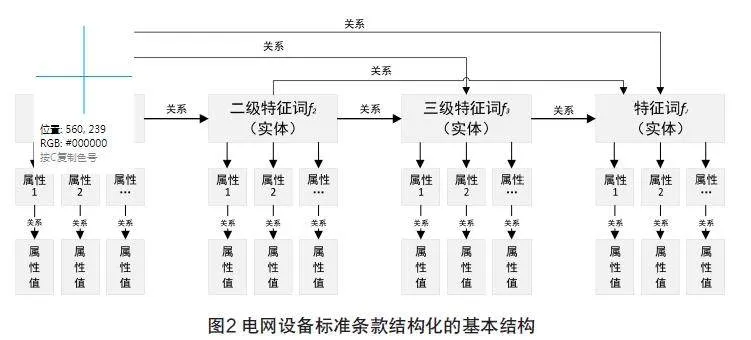
按照权重值自小向大调整特征词顺序,形成电网设备技术标准条款结构化的基本结构,如图2所示。
2.4 条款差异分析
在分析标准条款cm和 cn的差异情况时,首先提取两个条款的特征向量集合Am={ f1,f2,… ,fp}和An={ f1,f2,… ,fq};其次,通过特征语义分析和特征权重评定两个环节,对特征词标准化处理、“实体-属性-属性值”关系挖掘和特征词顺序调整;再次,比较两个条款的相应特征词内容,按式(2)计算两个条款的相似度Simmn;最后,通过比较对应特征词的属性和属性值,分析标准条款cm和cn的差异性,尤其是属性值的差异情况。
Sim mn=t/min(p,q)(2)
其中,p为标准条款cm提取出的特征词数量,q为标准条款cn提取出的特征词数量,min(p,q)为p和q中的最小值,t为标准条款cm和cn中相同特征词的数量。
3 实验与分析
3.1 实验环境
本文实验硬件的CPU为Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz 1.80 GHz,内存为16GB,操作系统为Windows 10(64bit)。算法研发语言为python(Python 3.11),研发平台为PyCharm。
3.2 实验数据
从《电网设备技术标准差异条款统一意见》中随机抽取10组存在差异的条款内容。为了实验方便,条款内容统一按照文本方式编排。
3.3 实验结果
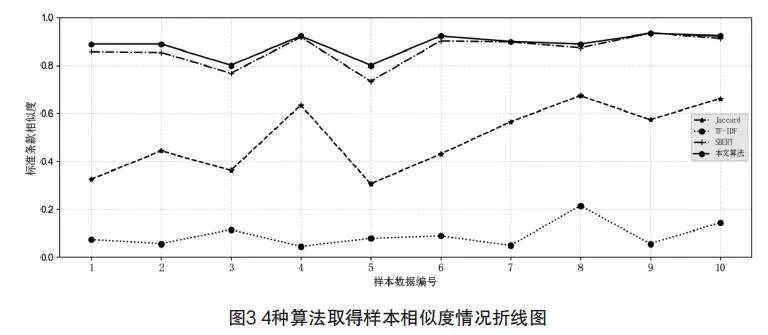
在本文算法实验中,3.4节所提供两个条款相似度Simmn计算公式中α和β分别为0.6和0.4。同时,选取Jaccard、TF-IDF、SBERT等3个算法进行实验,并对实验结果进行比较。为了使实验结果更直观,将4种算法计算10组样本相似度情况绘制折线图,如图3所示。
3.4 结果分析
从图3中可以看出,在计算电网设备技术标准条款相似度方面,Jaccard和TF-IDF 算法计算结果不理想,本文算法和SBERT算法远优于其他两种算法,本文在相似度上又有所提升,有利于发现相似条款内容。同时,本文算法可准确发现条款间存在的差异性,例如可准确发现变压器油中总烃量要求存在的差异性,如表1所示。
4 结 语
本文提出的基于特征和语义的标准条款差异分析方法,从条款特征提取、特征语义分析、特征权重评定、条款差异分析4个方面开展相关工作。通过真实电网设备技术标准条款进行实验,结果表明本文方法在标准条款相似度计算和条款差异情况分析方面优于Jaccard、TF-IDF、SBERT算法。但是,本文方法未考虑到标准中表格数据,仍需进一步优化完善。
参考文献
[1]赵京胜,宋梦雪,高祥.自然语言处理发展及应用综述[J].信息技术与信息化,2019(07):142-145.
[2]高源.自然语言处理发展与应用概述[ J ] .中国新通信,2019,21(02):117-118.
[3]Attardi G , Rossi S D , Simi M .TANL-1: coreference resolutionby parse analysis and similarity clustering[J].proceedings ofinternational workshop on semantic evaluation, 2010.
[4]蒋昊达, 赵春蕾, 陈瀚, 等. 基于改进T F - I D F 与B E R T 的领域情感词典构建方法[ J ] . 计算机科学,2024,51(S1):162-170.
[5]Wang J , Dong Y .Measurement of Text Similarity: ASurvey[J].Information (Switzerland), 2020, 11(9):421.DOI:10.3390/info11090421.
[6]胡泽文,王效岳,白如江.国内外文本分类研究计量分析与综述[J].图书情报工作,2011,55(06):78-81+142.
[7]张娜娜.基于机器学习的智能推荐系统设计与优化研究[J].家电维修,2024(01):37-39.
[8]荆江平,智明,杨飞,等. 基于数据分析的新型电力系统电力智能交互平台的短文本相似性研究与应用[J/OL].电测与仪表,1-7[2 0 2 4 - 0 8-16 ].ht t ps: // knscnki-net.webvpn.ncepu.edu.cn/kcms/detail/23.1202.TH.20240429.1847.005.html.
[9]Ramos J .Using TF-IDF to Determine Word Relevance in Document Queries[J]. 2003.DOI:doi:http://dx.doi.org/.
[10]Ch vát a l , Va c láv, S a n k o f f D . L o n g e s t c o m m o nsubsequences of two random sequences[J].Journal ofApplied Probability, 1975, 12(02):306-315.DOI:10.1017/s0021900200047999.
[11]Charikar, Moses S .Similarity estimation techniquesfrom rounding algorithms[C]//Applied and ComputationalH a r m o n i c A n a l y s i s . A C M , 2 0 0 2 : 3 8 0 - 3 8 8 .DOI:10.1145/509907.509965.
[12]俞婷婷,徐彭娜,江育娥,等.基于改进的Jaccard系数文档相似度计算方法[J].计算机系统应用,2017,26(12):137-142.DOI:10.15888/j.cnki.csa.006123.
[13]Huang P S , He X , Gao J ,et al.Learning deep structured semantic models for web search using clickthroughdata[C]//Conference on Information and Knowledge GjRsYOnVBa/br+cqwUEtoArBW0JOzw5CjOXpRe37SRs=;Management.ACM, 2013.DOI:10.1145/2505515.2505665.
[14]Shen Y , He X , Gao J ,et al.A Latent Semantic Modelwith Convolutional-Pooling Structure for InformationRetrieval[C]//Conference on Information and KnowledgeManagement.ACM, 2014.DOI:10.1145/2661829.2661935.
[15]Reimers N , Gurevych I .Sentence-BERT: SentenceEmbeddings using S iamese B ERT-Networks[J]. 2019.DOI:10.18653/v1/D19-1410.
[16]卢美情,申妍燕.一种基于孪生网络预训练语言模型的文本匹配方法研究[J].集成技术,2023,12(02):53-63.
