基于云原生架构的超大文件处理存储优化研究
2024-10-09李庄庄
关键词:超大文件;云原生;文件切片;文件一致性校验;纠删码
中图分类号:TP302.7;TP392 文献标识码:A
0 引言
随着信息技术的发展和数字化建设的深入,企业在日常管理和生产运营中会使用大量的软件系统,这些系统在运行中也会产生大量数据。根据相关预测,到2027 年,全球非结构化数据可能将占到数据总量的86.8% [1]。部分非结构化数据文件已经属于超大文件,单文件大小达到数百GB 级甚至TB 级,这些文件包括工程数据文件、数据库文件、虚拟机快照文件、日志存储文件以及用于数据分析的数据包文件等。相较于结构化数据,非结构化超大文件在采集上传、处理存储和调用共享等多个应用场景中都有其特殊性,使用传统架构和技术会存在效率、性能以及易用性等方面的不足。因此,需要借助新的架构和技术解决超大文件在处理存储方面的问题,以应对数字经济时代带来的技术挑战。
1 超大文件处理存储的问题与解决方向
1.1 文件采集上传效率低
超大文件一般是以独立文件的方式存储在磁盘、磁带和光盘等存储介质上,在使用时需要将文件采集上传到服务器、云主机或者专业软件中,以进行后续处理。由于网络条件的限制,采集上传文件的过程会长时间(通常需要几十分钟甚至数小时)占用网络带宽资源,以及对磁盘进行大量读写,这不仅效率低,而且容易出现因系统卡顿和误操作导致的上传失败,并且无法断点续传。
本文针对超大文件采集上传的问题,提出切片、多线程上传、断点续传、切片合并校验等解决方向,可大幅提升上传效率。
1.2 文件存储可靠性不足
超大文件的离线存储方式包括磁盘、磁带和光盘等,该方式会因为硬件损坏或系统故障导致文件丢失或损坏,可靠性较差。超大文件的在线存储方式包括数据库二进制大对象(binary large object,BLOB)字段存储、分布式文件存储和对象存储等方式。BLOB 类型的关系数据库可以存储二进制数据,适合存储大文件,但文件大小有限制(如MySQL 限制为1 GB),读写性能和查询性能都较差,外部访问较为复杂,数据备份和迁移的效率低,无法实现文件的及时共享。分布式文件存储是一种将数据分散存储在多台独立设备上的技术,具备高容错性,单节点故障不会导致数据丢失,适合存储大数据量的文件,但分布式文件存储技术不适用于存储数量较多的小容量文件,因为在多副本策略下磁盘利用率较低,横向扩容和纵向扩容复杂,管理和运维的难度较高。
通过对超大文件采集存储场景下的文件大小、文件类型、文件格式和应用场景进行分析,本文提出采用对象存储技术来解决文件存储问题。对象存储技术的单文件大小可以覆盖kB 至TB 级别,能够灵活应对超大文件的切片存储需求,解决分布式文件存储技术由于文件大小固定导致的资源利用率低的问题。该技术利用纠删码提升磁盘利用率,支持顺序、随机高性能并发读写,并且通过数据分布、数据缓存等方式提供更好的访问性能,适用于超大文件存储的场景需求。
1.3 文件调用共享不便利
超大文件由于管控技术和手段不足,导致对超大文件的调用和共享存在不便利的情况,难以进行高效检索和共享利用,无法充分体现数据的价值。针对以上问题,本文提出搭建文件查询共享平台,通过统一的标准、入口和规范化的流程,实现超大文件的高效检索和共享利用。
2 基于云原生架构的平台整体设计
为更有效地解决超大文件在采集存储方面的性能、效率和易用性等问题,采用云原生架构进行整体平台设计和构建。
2.1 云原生架构与特点
云原生架构是一种在云环境下设计和构建应用程序的方法和理念,强调微服务架构、容器化部署、弹性伸缩、自动化运维以及敏捷开发与持续交付。通过微服务架构,应用程序被拆分为独立的服务单元,实现灵活的开发和部署;容器化部署使应用程序具备高度的可移植性和隔离性;弹性伸缩实现了系统根据需求自动调整资源和容量;自动化运维提高了系统的可靠性和稳定性;敏捷开发与持续交付实现了快速响应市场和用户需求[2]。
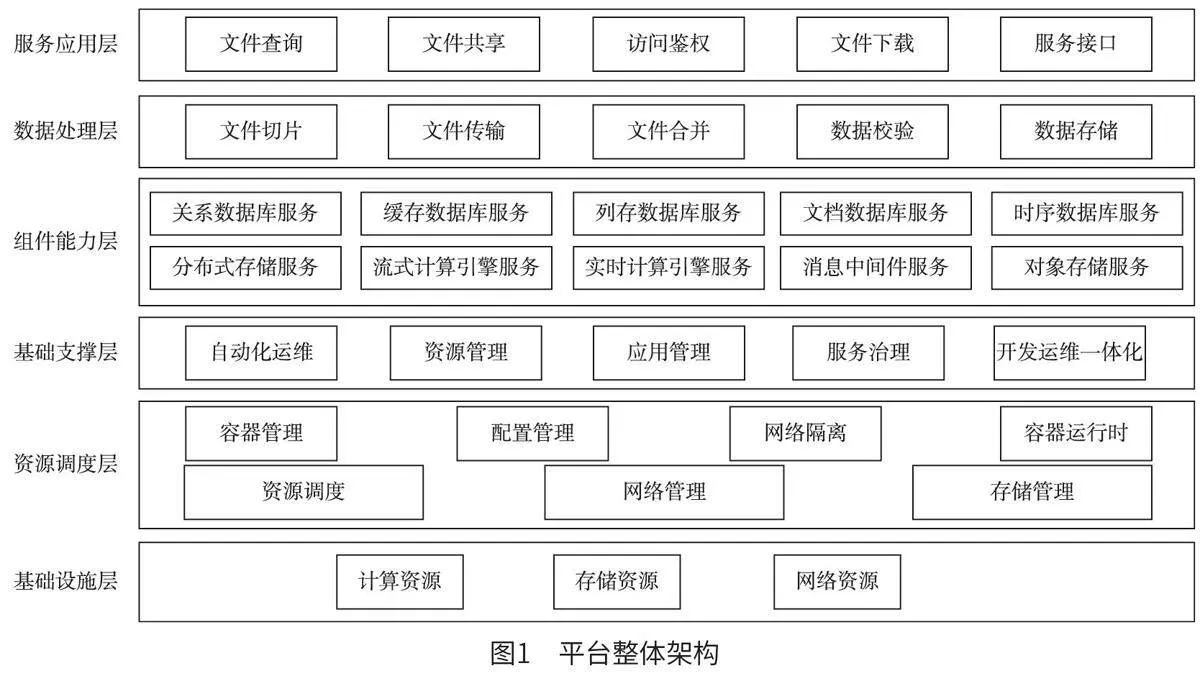
2.2 平台整体架构设计
平台整体架构如图1 所示。在基础设施层的基础上搭建云原生底座平台,平台可分为资源调度层、基础支撑层和组件能力层3 个层级。其中,资源调度层负责硬件资源接入,实现软、硬件解耦和计算资源的统一调度;基础支撑层负责满足云环境的共性技术需求,实现自动化运维、资源管理、应用管理、服务治理和开发运维一体化等功能;组件能力层负责根据超大文件采集存储和管理的要求,提供各类标准化能力组件的快速交付,其具有数据库服务、计算服务、存储服务、消息服务等能力。
云原生底座平台的上一层级为数据处理层,部署超大文件处理存储的相关功能应用,包括文件切片、文件传输、文件合并、数据校验和数据存储等。平台可以对应用运行中所需要的算力、标准化能力组件以及数据进行动态使用和调度。通过标准服务交付、统一资源管理和统一集群调度,实现超大文件处理存储应用的高可靠性、高性能和弹性扩展。
数据处理层的上一层级为面向用户的服务应用层,包括文件查询、文件共享、访问鉴权、文件下载和服务接口等,通过统一门户实现超大文件调用共享的一站式服务。
3 超大文件处理存储优化技术研究
3.1 基于文件切片合并的采集上传优化
超大文件采集上传优化的基本思路为将大文件切分成多个小文件,再进行上传和合并。基于浏览器的网络应用程序编程接口(Web applicationprogramming interface,Web API)规范,可以利用文件接口(file API)和网络工作线程接口(Webworkers API),将超大文件在客户端本地进行多线程切片处理。首先,利用文件读取器(FileReader)接口异步读取存储在用户计算机(或原始数据缓冲区)的文件内容,使用 file 或 BLOB 对象指定要读取的文件或数据。按照预设的切片大小,将文件切分成固定大小的切片。为避免输入/ 输出(input/output,I/O)密集型任务阻塞或拖慢主线程,可以利用 Web workers API 在后台独立线程中执行耗时的任务。
切片在一定程度上会影响上传性能,若切片太小,则需要频繁建立file API 连接和启动Webworkers 后台多线程,此时建立连接和启动线程的时间明显多于数据传输的时间;若切片太大,则单任务运行时间过长,网络应用程序内存占用过高,不利于程序的并发运行。多次实验测试数据显示,100 GB 的文件在网速为1 000 Mb/s(上传速度约为120 MB/s)时,切片为10 MB 的上传总时间是切片为200 MB 的2 ~ 3 倍。
切片的操作过程如下:将超大文件分割成小块,多线程上传,形成多个并行的上传任务,以实现文件的分片上传。在分片上传中实现断点续传,将上传任务划分为多个部分,如果因网络故障造成传输中断,可以快速跳过已上传的部分继续上传,无须重新开始,从而提高文件采集的效率。
切片的合并是指在所有切片上传完成后,将所有切片合并成一个整体的文件。具体操作为客户端浏览器将所有切片上传完毕后,发送最后一个上传完成的指令,同步调用后端API 将所有切片进行合并。但当文件大小为数百GB、单文件切片数量达到上千甚至上万级别时,后端文件合并时长达到几十分钟甚至1 h 以上,并且近万个切片的合并是消耗中央处理器(central processing unit,CPU)和I/O 处理任务,服务器压力在合并过程中持续过大。由于客户端调用是同步API,整个合并过程客户端虽然已经上传完所有切片,但是系统仍然处于等待状态,这容易造成浏览器假死的错觉。优化方案有两种:一种是基于简单存储服务(simplestorage service,S3)的分段上传功能来实现对象的上传和复制[3],切片上传和切片合并的任务分别由分段上传启动接口、分段上传接口、分段上传完成接口完成,此优化方案主要取决于S3 API 的处理能力,切片合并过程不可见。另一种优化方案是利用Linux C++ 库函数fseek()以及 Java 随机文件读取技术。在切片上传之前,初始化一个固定大小的空文件,在切片并发上传的过程中,任何一个有序切片在最终整体文件的位置都是固定的,当单个切片上传完成时,将切片插入空文件的指定位置即可。此优化方案的上传过程完全自主可控,切片上传完成即表示整个上传过程完成,避免文件切片上传后需要客户端长时间等待的情况。该优化方案可以在上传过程中实现服务器负载的持续稳定,避免出现较大的波动。
3.2 基于多哈希采样消息摘要算法的文件一致性校验优化
超大文件在采集上传中需要进行切片、传输、合并等操作,为避免由于网络丢包等原因导致的数据缺失,需要对文件一致性进行校验。一致性校验采用常见的消息摘要算法,如用于防篡改场景的MD5 消息摘要算法和用于防偷窥场景的SHA-256 安全散列算法(secure Hash algorithm,SHA)。MD5是一种被广泛使用的密码散列函数,用于生成128 位(16 字节) 的散列值。SHA-256 为SHA-2家族中的一员,是一种加密散列算法标准,可以将任意长度的消息转化为固定长度为256 位的哈希值,也称为消息摘要。
在普通配置的客户端上,计算数百GB 文件的MD5 值需要约1 h,采用SHA-256 算法则需要约2 h,这会大大影响文件采集上传的效率,造成软件体验感的下降。因此,本文采用可预设规则的多哈希采样消息摘要算法对超大文件进行一致性校验。
首先预设文件大小的阈值(4 GB),若超过阈值,则进行多哈希采样。程序采用可变预设规则,其可以预设采样位置、采样块大小:多哈希采样默认选取文件首、中、尾3 个采样位置,因为这3 个采样位置的信息最具代表性,能显著提升计算准确性;多哈希采样默认选取1 GB 的连续数据作为采样块大小,采样块大小要适宜,过小的采样块会损失样本代表性,而过大的采样块会导致计算时长增加,造成资源浪费。采用多哈希样本匹配方案,可以有效避免哈希碰撞[4]。为进一步提升数据的准确性,可以在服务端单独启动完整消息摘要算法校验任务,利用多哈希采样与后台服务器校验任务相结合的方法,可以有效提升消息摘要算法的计算效率和数据准确性。在数据采集上传的过程中,通过该优化方案,可将采集上传速度提升数十倍,实现超大文件高效、安全、完整上传。
3.3 基于纠删码技术的文件存储优化
超大文件的存储由云原生底座平台提供支撑,采用分布式文件存储技术,保障文件在不同机架、不同服务器中保存多个副本,任意一个副本损坏不影响文件的正常使用。
多副本技术是将数据的多个冗余副本分布在不同机器上,当存储节点发生故障时,自动将服务切换到其他副本,从而保证数据的高可靠性和高可用性。然而,随着数据量的持续增长,大型数据中心采用的多副本技术的存储开销越来越多。面对这种情况,纠删码技术因其低存储开销的特点受到越来越多的关注。其中,RS 编码( Reed-Solomon code)是目前被广泛使用的纠删码方案, 它将k 个数据块按照一定的编码规则,生成m 个校验块,对于这k+m 个编码块,其编码性质能够保证选取任意的k个编码块均能重建所有数据。以RS(4,2)编码为例,它只需占用1.5 倍的存储空间,就具有与三副本技术相同的容错能力[5]。
通过研究分析,评估磁盘阵列、副本存储以及纠删码技术的优缺点,在多副本冗余存储的情况下,采用纠删码技术,可以最大限度地提升磁盘空间利用率。通过研究测试,采用不同纠删码编码方案,结合服务器CPU、内存等压力情况变化,综合磁盘利用率、硬件加速、服务器状况等性能指标,可以通过设置服务器个数、磁盘个数和校验块个数,从而控制磁盘利用率、实现对象级别的逐文件修复、实现超大文件的存储优化。同时,基于纠删码的对象存储可以支持横向节点缩扩容;轻松管理百亿数量的PB 级别文件;统一访问方式和授权加密存储;可应对大文件、小文件的顺序以及随机高性能并发读写需求,为I/O 密集型工作负载提供高带宽、低延时性能支持,读写速度最高可达每秒几百GB。
通过研发测试发现,对于存储集群中文件大小的不同区间分布,服务器个数、单服务器磁盘个数、校验块个数将影响整体存储集群的吞吐率。例如,在集群中文件平均大小为200 MB 的情况下,相较于服务器个数为4、单服务器磁盘个数为1、校验块个数为2 时,服务器个数为4、单服务器磁盘个数为4、校验块个数为4 时的集群吞吐率提升30%。但是,在集群中文件平均大小为20 MB 的情况下,相较于服务器个数为4、单服务器磁盘个数为1、校验块个数为2 时,服务器个数为4、单服务器磁盘个数为4、校验块个数为4 时的集群吞吐率下降20%。此外,在不同纠删码算法下,单文件被切分成不同大小的数据块和校验块,平均存储在磁盘中。例如,当服务器个数为4、单服务器磁盘个数为4、校验块个数为4 时,文件被切割成1.2MB 的数据块和校验块;而当服务器个数为4,单服务器磁盘个数为1,校验块个数为2 时,文件被切割成8.1 MB 的数据块和校验块。这证明存储的数据块和校验块的大小和数量会进一步影响集群的整体吞吐率。因此,针对不同存储集群,需要采用合适的纠删码算法,确定最佳的存储拓扑结构。
3.4 基于统一入口的一站式文件调用共享
针对超大文件调用共享缺乏有效数字化管理手段的问题,本文建立一套覆盖文件查询、文件共享、访问鉴权、文件下载以及服务接口的统一平台,用户可以通过统一入口实现超大文件调用共享的一站式服务。
3.4.1 文件查询
将超大文件资源按照资源目录的形式进行编目,配置其资源基本信息和数据项信息。用户可以根据资源目录、资源名称、发布状态、资源类型等进行分页查询,以列表的方式展示。列表中简要展示编制资源的名称、目录位置、提供方、发布状态和编制人等信息。编制资源的详细信息在资源详情中查看,列表提供资源详情的查看入口。
3.4.2 文件共享
对于需要的文件资源,用户可以申请文件下载服务,管理员或者资源提供方可以查看申请方申请的服务情况,并进行审批。文件下载服务申请通过后,可以在线预览文件列表。
3.4.3 访问鉴权
根据文件内容与业务规则分类,通过描述文件的多维度特征和内容敏感程度,制定文件资源的开放和共享策略,并且只有拥有相关权限的用户才能访问该文件。
3.4.4 文件下载
基于平台提供的文件压缩、加密、分片写入技术对文件进行处理,再提供下载接口,用户可以通过接口同时读取多个分片文件,完成文件的下载。
3.4.5 服务接口
文件资源以数据接口的方式对外提供服务,可以与其他业务软件进行接口集成,提供超大文件调用共享的能力输出,使系统具有文件发布、下架、测试、检索等管理功能。
4 结语
本文针对超大文件在处理存储中的若干问题,基于云原生架构设计整体平台,研究了超大文件的高效切片合并,提出了多种优化方案;研究了基于多哈希采样消息摘要算法的文件一致性校验,提升了文件校验的效率;研究了基于纠删码技术的文件存储,大幅提升了磁盘空间利用率,并提出了针对不同存储集群的最优纠删码算法;最后设计了一站式文件调用共享平台的主要功能。该研究成果对于数字化建设中的软件开发工作具有较好的参考价值。
