基于改进YOLOv5s的无人机航拍小目标检测算法研究
2024-09-26尹泉贺原素慧朱梦琳兰洁

摘 要:目前,无人机航拍目标检测技术在军事和民用领域得到广泛的应用,但复杂场景中小目标密集,易出现误检和漏检的情况。为此,文章提出一种基于改进YOLOv5s的无人机航拍小目标检测算法,用分组卷积取代两个普通卷积,用解耦检测头取代耦合检测头,去除了原始算法中的P5检测头,在PANet结构中增加一层新的P2检测头。仿真结果表明,改进算法具有较好的检测效果,mAP50较原始算法提高了9.3%,同时能够满足无人机实时性检测需求。
关键词:无人机航拍;小目标检测;空间池化金字塔;解耦检测头
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2024)14-0037-07
Research on Small Target Detection Algorithm for UAV Aerial Photography
Based on Improved YOLOv5s
YIN Quanhe, YUAN Suhui, ZHU Menglin, LAN Jie
(College of Information Engineering, North China University of Water Resources and Electric Power, Zhengzhou 450046, China)
Abstract: At present, UAV aerial photography target detection technology has been widely applied in military and civilian fields, but in complex scenes, small targets are dense and prone to false positives and missed detections. For this purpose, this paper proposes a small target detection algorithm for drone aerial photography based on improved YOLOv5s, which replaces two ordinary convolutions with grouped convolutions and decoupled detection heads instead of coupled detection heads. The P5 detection head in the original algorithm is removed, and a new P2 detection head is added to the PANet structure. The simulation results show that the improved algorithm has good detection performance, with mAP50 increased by 9.3% compared to the original algorithm, and can meet the real-time detection requirements of UAV.
Keywords: UAV aerial photography; small target detection; spatial pooling pyramid; decoupled detection head
DOI:10.19850/j.cnki.2096-4706.2024.14.008
0 引 言
目标检测是计算机视觉中的一个重要任务,旨在在图像中识别感兴趣的目标并确定其类别与位置。无人机作为一种成本低、易操作、较灵活的飞行器,在军事、商用和民用领域得到广泛的应用。近年来,将目标检测技术应用于无人机成为学者研究的焦点[1]。基于深度学习的目标检测算法分为两大类[2]:单阶段(One-Stage)和双阶段(Two-Stage)。单阶段方法无须生成候选区域,直接提取图像特征,简单高效,但精度相对较低,代表方法包括OverFeat、SSD和YOLO系列。双阶段方法需要生成候选区域,具有高精度、强稳定性和强可扩展性,但速度较慢且较为复杂,代表方法有R-CNN、FastR-CNN和FasterR-CNN。总体而言,单阶段方法速度快但精度偏低,而双阶段方法精度高但速度偏慢。
针对小目标检测,潘晓英等[3]梳理了国内外研究现状及成果,分析并归纳了小目标检测所面临的挑战与难点。杨慧剑等[4]解决了因成像距离远、高空拍摄图像模糊以及目标信息占比小而导致目标检测精度不高的问题,以YOLOv5为基础模型,在FPN结构中添加了新的检测头P2,用以实现更细粒度的目标检测。虽然降低了小目标漏检误检情况发生的概率,但却增加了训练过程中的计算量。另外还把原始算法的空间池化金字塔层(SPP)更改为空洞空间池化金字塔(ASPP),通过不同的空洞率构建不同感受野的卷积核,获取多尺度特征信息从而减轻池化操作对特征信息的影响。由于空洞卷积的特性,在扩大感受野和获取不同尺度特征的同时,采样并不密集,可能会丢失局部信息,所得到的卷积结果之间没有相关性。刘涛等[5]解决了因小目标图像分布密集和类别不均衡且特征不明显而导致漏检和误检的问题,以YOLOv5s为基础模型,改进了锚框聚类算法,更加精确地锁定检测区域,有效提升了针对小目标的捕捉能力。魏养养等[6]解决了小目标分布密集和重叠的问题,以YOLOv5s为基础模型,引入混合注意力模块来提高卷积神经网络对特征图的提取能力,使小目标检测效果有所提升,但提升幅度却不够大。
1 YOLOv5模型
YOLOv5是目标检测领域广泛部署的模型,具有结构简单、模型小巧、易于使用和精度较高等优点。模型的大小由宽度和深度决定,而宽度和深度则由配置文件中的缩放系数确定。通过调整缩放系数,YOLOv5可提供不同大小的模型,如YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,以适用于不同的任务。本文研究的主要目的是对YOLOv5s进行改进,该模型由以下4个部件组成。
1.1 输入端(Input)
这个部分采用了Mosaic数据增强,通过对数据集缩放、剪切和排布的方式进行图像拼接,增加数据集的数量,缓解模型过拟合并增强模型的泛化能力,对小目标的检测效果有所提升。此外还采用了自适应锚框计算,每次训练时自适应地计算不同训练集中的最佳锚框数值。添加了自适应缩放图片,缓解了因图片尺寸不同缩放图片而导致的图像形变,更有利于提取图片中的特征信息。
1.2 骨干端(Backone)
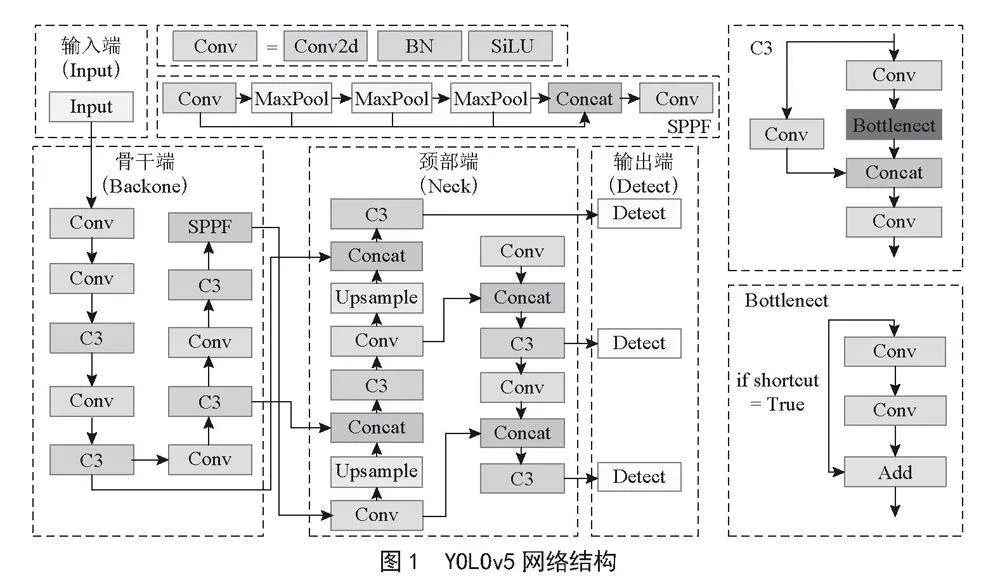
CSPDarknet53骨干网络包括C3、Conv和SPPF(Spatial Pyramid Pooling-Fast)模块。Conv模块由Conv2d、BatchNorm2d和SiLU激活函数组成,用于特征提取、下采样和通道数调整。C3网络将输入特征图传入两个分支(一个分支由多个Conv和Bottleneck模块组成,另一个分支仅有一个Conv模块),然后将两个分支的结果进行合并和融合。Bottleneck模块是一种特殊的残差结构,解决了深度网络致使梯度消失的问题。主干网络的最后一层是SPPF模块——空间池化金字塔层,能够处理任意大小的输入,有效提取和保留不同尺度下最显著的特征信息,减少冗余信息。
1.3 颈部端(Neck)
颈部端采用PANet [7]结构,将FPN [8](Feature Pyramid Networks)和PAN(Perceptual Adversarial Network)进行了有机结合。FPN是自底向上的特征金字塔,通过上采样传递深层特征图的明显语义特征,对整个金字塔进行语义信息增强。PAN是自顶向下的金字塔,通过下采样传递浅层特征图的定位信息,对整个金字塔进行定位信息增强。这样,颈部就实现了对特征图的有效融合,得到同时具有语义信息和定位信息的特征图。
1.4 输出端(Detect)
特征图通过耦合头对目标的类别与位置信息进行预测,最后输出目标类别与位置结果。YOLOv5的网络结构及各模块结构如图1所示。
2 改进的YOLOv5模型
由于小目标在图像中所占像素数的比重较小,分辨率相对较低,特征表达逊色于常规目标,所以小目标检测长期以来一直是目标检测研究的方向。而且当前的目标检测算法对小目标并不友好,主要体现在以下几个方面:
1)图像中物体大小差异较大。难以融合局部和全局特征,特征图的表达能力不够。
2)目标检测算法的设计问题。以YOLOv5为例,虽然对一般尺度目标的检测效果不错,但是对小尺度目标的检测效果欠佳。由于YOLOv5的耦合检测头的分类任务和回归任务是同时完成的,它们共享前一层的参数,这可能会导致一些信息的混淆,从而影响边界框回归的精度,忽视一些小目标的预测。
3)过大的感受野。在过大感受野特征图的一个点中,小目标占据的特征会更少,而背景占据的特征会更多,网络学习过多背景噪声会产生过拟合,从而降低网络的泛化能力。
本文以Ultralytics公司编写的6.1版YOLOv5s算法为基础模型进行改进,主要改进点有三个:
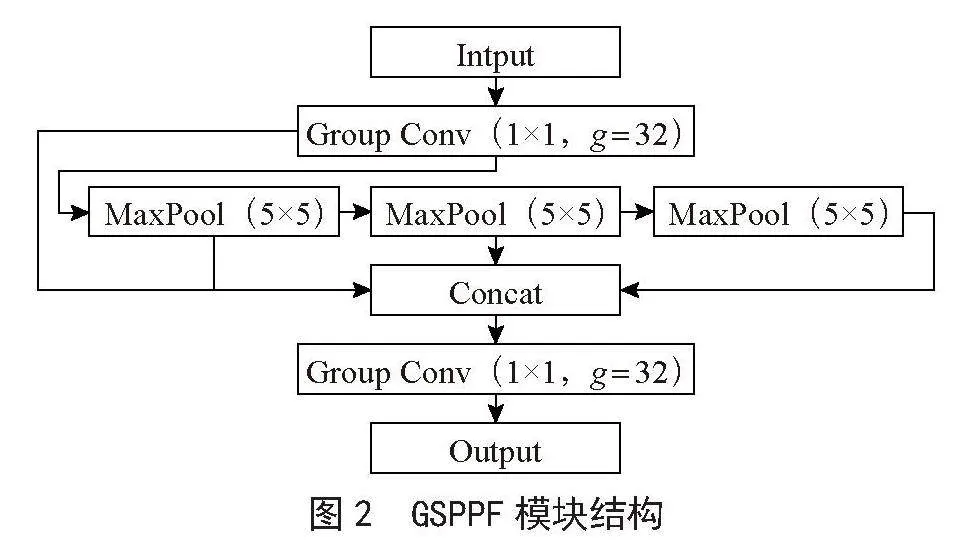
1)骨干端。为解决因图像中物体大小差异较大而难以融合局部和全局特征,导致特征图表达能力不够的问题,将原有的空间金字塔池化(SPPF)改进为本文提出的分组空间金字塔池化(GSPPF),在减少参数量和扩大感受野的同时提升了网络的特征信息提取能力和多尺度特征融合能力。
2)输出端。为缓解分类任务与回归任务冲突的问题,把原有的耦合检测头替换为解耦检测头,以此提升检测精度。
3)颈部端。为解决感受野过大的问题,本文添加了新的小目标检测层P2,缩小特征图的感受野,减少背景与噪音的影响,提升对小目标的捕捉能力并删除原有的检测层P5,减少参数量和计算量,加速网络训练速度。
2.1 空间池化金字塔的改进
在分组卷积[9]、SPP和SPPF的启发下,本文提出一种新模块GSPPF,该模块将原始算法SPPF模块中的两个普通卷积替换成分组卷积,并且将参数设为32。相较于普通卷积,分组卷积能够减少运算量和参数量,同时还能发挥类似正则化的作用,能够缓解过拟合的问题,增强网络的泛化能力,提高了检测精度。GSPPF模块结构如图2所示。
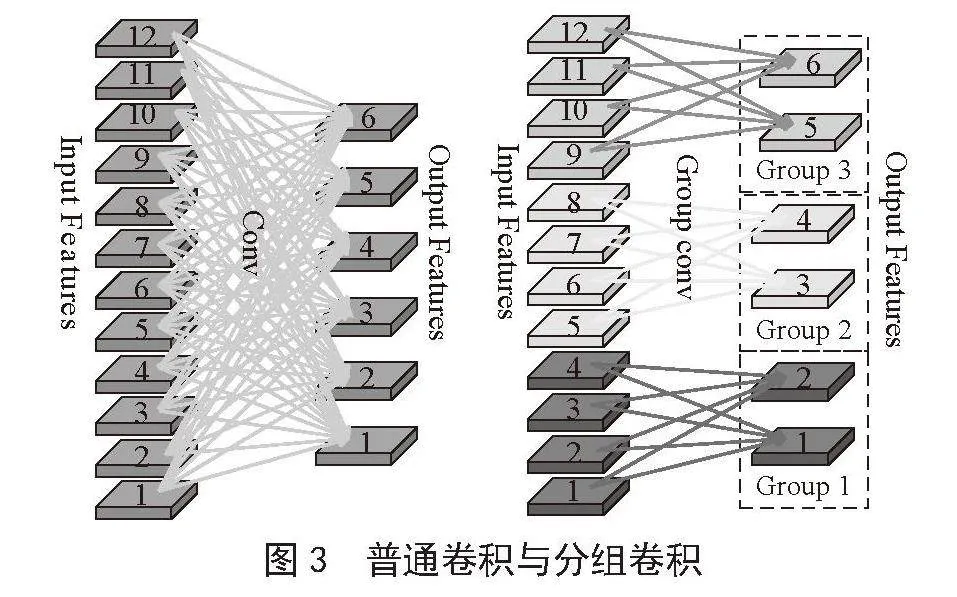
分组卷积将特征图和卷积核分成组,进行组内卷积,每组生成一张特征图,不改变特征映射的维度,但却减少了运算量和参数量。例如,输入特征图通道12、输出通道6,3×3卷积核,分组卷积参数设为3。普通卷积参数为12×3×3×6 = 648,分组卷积为4×3×3×6 = 216,分组卷积参数仅为普通卷积的1/3,显著减少了运算量和参数量。普通卷积与分组卷积区别如图3所示。
2.2 检测头的改进
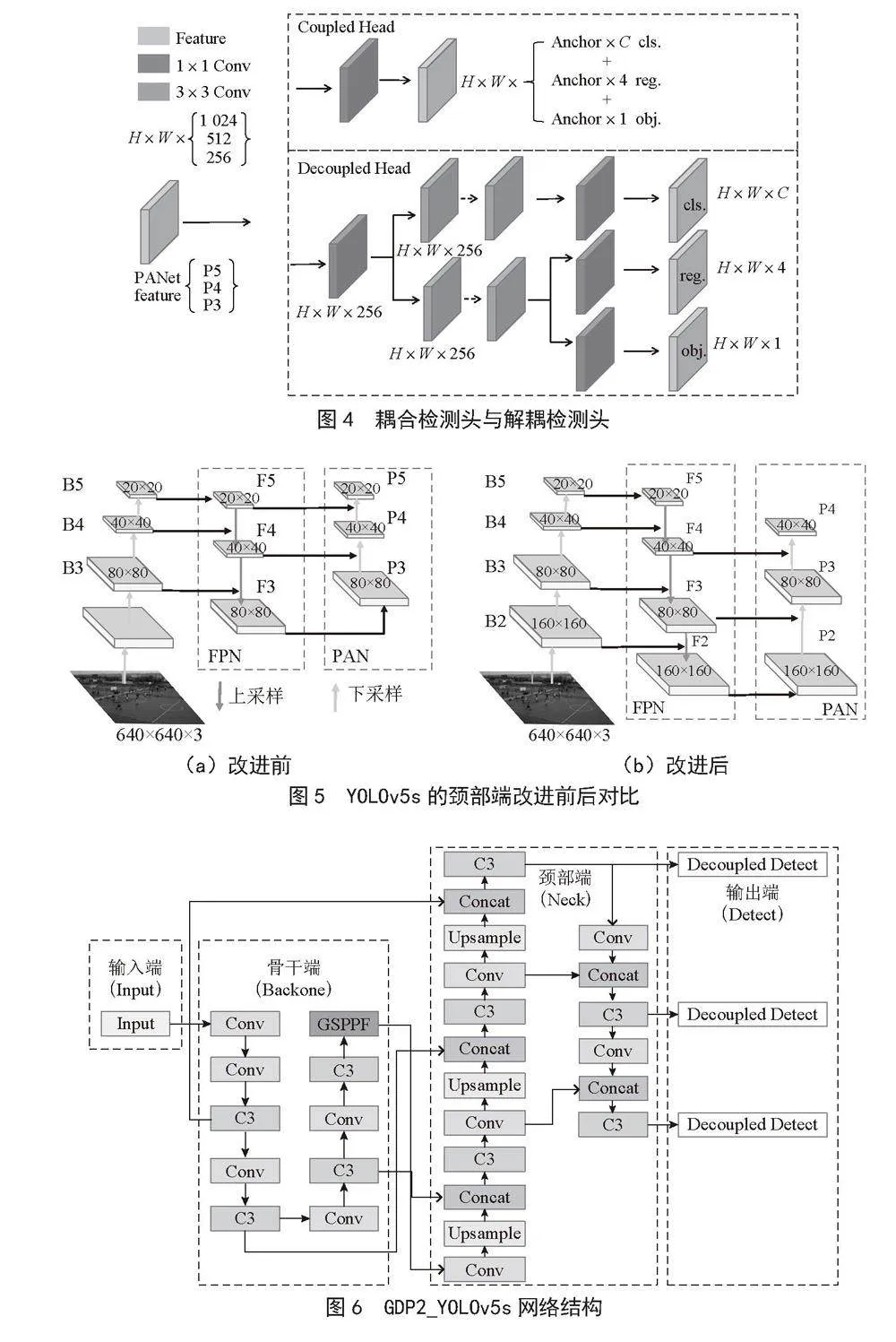
检测头从特征图中提取目标位置、置信度和类别信息。YOLOv5s中的检测头采用共享权重来处理分类和回归任务,这简化了设计但却带来参数、计算资源需求增大和容易出现过拟合的缺点,从而导致检测精度明显下降。
在目标检测中,分类任务与回归任务之间的冲突是一个众所周知的问题。将原始算法的耦合检测头替换成解耦检测头可以有效缓解这一问题,通过将目标分类和目标位置信息提取出来,再通过不同分支处理不同的任务,最后分别输出结果。Ge等[10]在耦合检测头与解耦检测头检测效果的实验中得出结论,耦合检测头可能会损害性能,而解耦检测头将分类任务与回归任务分开,使用独立的权重对特征图进行学习,缓解了分类任务与回归任务之间的冲突,使检测精度得以提升,网络拥有更好的泛化能力与鲁棒性。耦合检测头与解耦检测头结构如图4所示。
2.3 检测层的改进
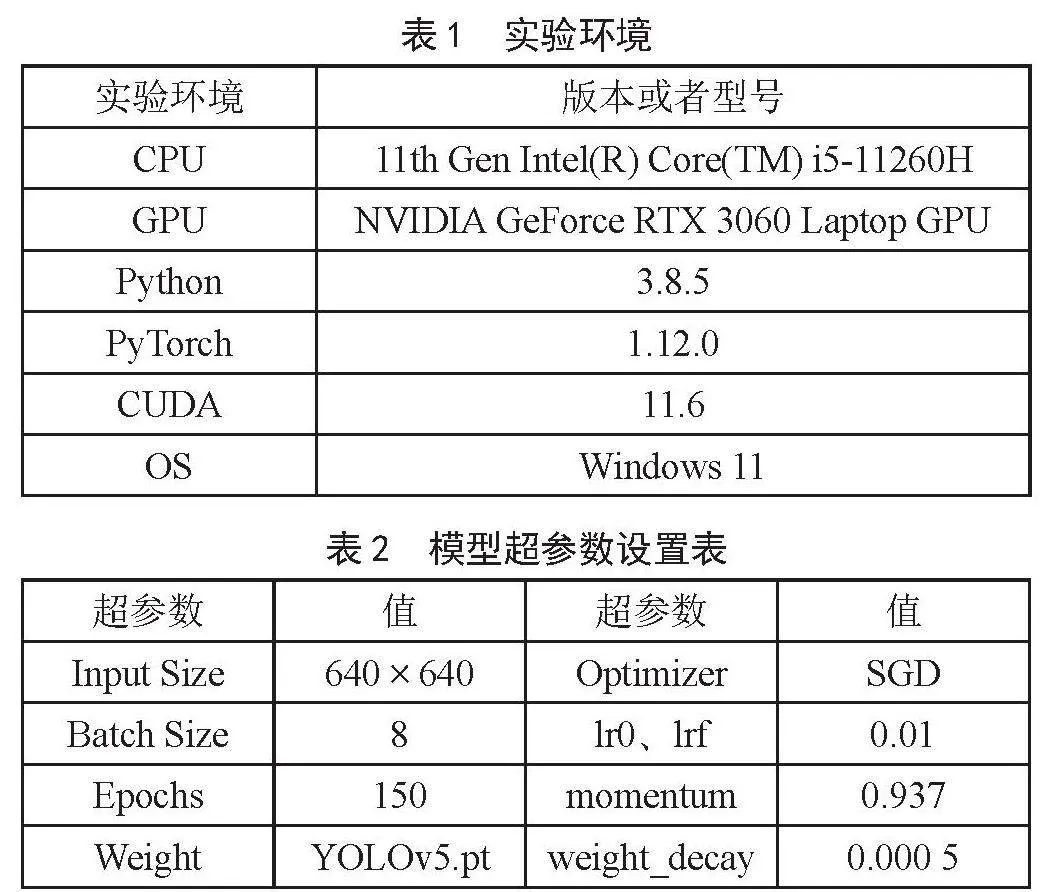
在原始YOLOv5s算法中,对640×640的输入图片进行8倍、16倍和32倍的下采样,得到80×80、40×40、20×20大小的特征图,用于检测小、中、大尺度目标。然而,小尺度目标在无人机视角下的相对尺度和绝对尺度都很小,导致特征信息有限,加上大感受野背景噪音的干扰,网络提取的有效特征十分有限。因此,选择合适的感受野来控制背景噪声等无用信息的影响,从而使辅助网络学习到小尺度目标的特征信息,以此缓解网络过拟合现象和提高网络的泛化能力,进而提升对小尺度目标的检测精度。添加160×160的小目标检测层P2,让感受野变小,保留更多小尺度目标的位置信息和细节信息,以在颈部端进行多尺度特征融合时提供更强的位置信息,使得进行预测的特征图拥有更全的上下文信息,有利于网络捕捉和学习小尺度目标的特征信息。考虑到无人机视角下的目标尺度普遍偏小,所以删除了原始算法中负责大尺度目标检测任务的检测层P5,以减少不必要的参数量和计算量,提升网络训练速度。后经实验证明,在新添加P2检测层的基础上,删除P5检测层后训练时间节省了38.34分钟。原始算法YOLOv5s的颈部端与改进YOLOv5s的颈部端如图5所示。改进后的GDP2_YOLOv5s网络结构如图6所示。
3 实验与结果分析
3.1 数据集、实验环境与参数配置
本文训练模型所使用的数据集是VisDrone2019_DET,该数据集包含十个类别,分别是0行人(pedestrian)、1人(people)、2自行车(bicycle)、3车(car)、4面包车(van)、5卡车(truck)、6三轮车(tricycle)、7遮阳棚-三轮车(awning-tricycle)、8巴士(bus)、9摩托车(motor),其中训练集静态图片6 471张、验证集静态图片548张、测试集静态图片1 610张,这些图片都是由无人机摄像头捕捉到的,小目标较多,具有分布密集的特点,因此是理想的小目标检测算法数据集。
为了确保实验的公平性,实验环境与训练时超参数配置情况如表1和表2所示,若没有特殊说明,下列实验均使用表中的实验环境与超参数配置,未提及的超参数配置均使用默认值。
3.2 评价指标
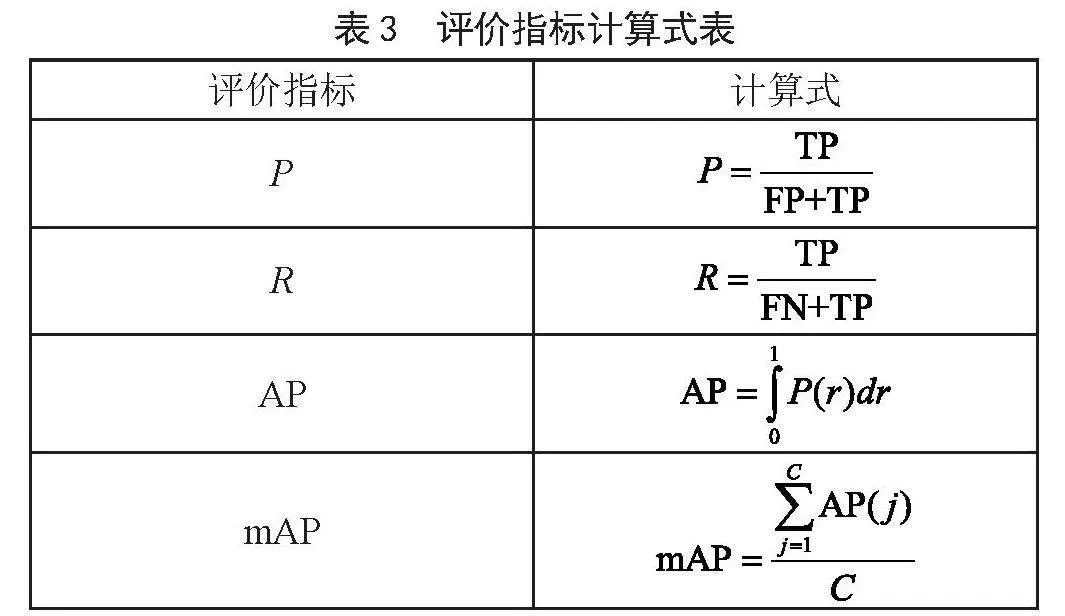
本文采用的四个评价指标分别是:准确率(P),分出类是正类的准确概率;召回率(R)找出所有正类的概率;AP(Average Rrecision),是不同召回率R下的精确度P的积分,表示算法性能的优劣;mAP50(Mean Average Rrecision),是所有类别的AP平均检测精度。四个评价指标如表3所示。
在表3式子中,TP表示样本正类被判断成正类,TN表示样本负类被判断成负类,FP表示样本负类被判断成正类,FN表示样本正类被判断成负类,而C则表示样本的类别数。
3.3 对比实验与消融实验
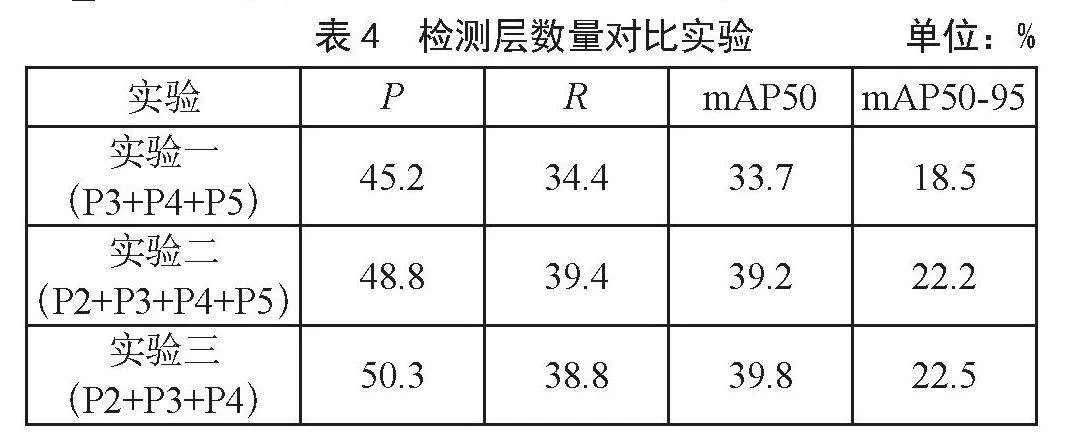
3.3.1 检测层数量对比实验
为解决原始算法对小目标的漏检和误检问题,本文添加了P2检测层,但是在原始算法中P5检测层是否保留的问题上,本文通过实验的方式来验证。实验一,采用原始算法做对比(P3+P4+P5);实验二,在原始算法颈部端添加P2检测层(P2+P3+P4+P5);实验三,在原始算法颈部端添加P2检测层,删除原有的P5检测层(P2+P3+P4),这也是本文所使用的P2_WP5方法,实验结果如表4所示。
从表4中可以看出,实验二对比实验一在评价指标P、R、mAP50和mAP50-95上都有较大的优势,分别提升了3.6%、5%、5.5%和3.7%。证明添加P2检测层后可捕捉到小目标的特征信息,能够缓解原始算法对小目标的漏检和误检问题。实验三对比实验二,虽然在召回率上有所下降,但在评价指标P、mAP50和mAP50-95上都有提升,分别提升了1.5%、0.6%和0.3%。证明了添加P2检测层和删除P5检测层能够让网络更加专注于小目标,从而提升了检测精度。
3.3.2 消融实验
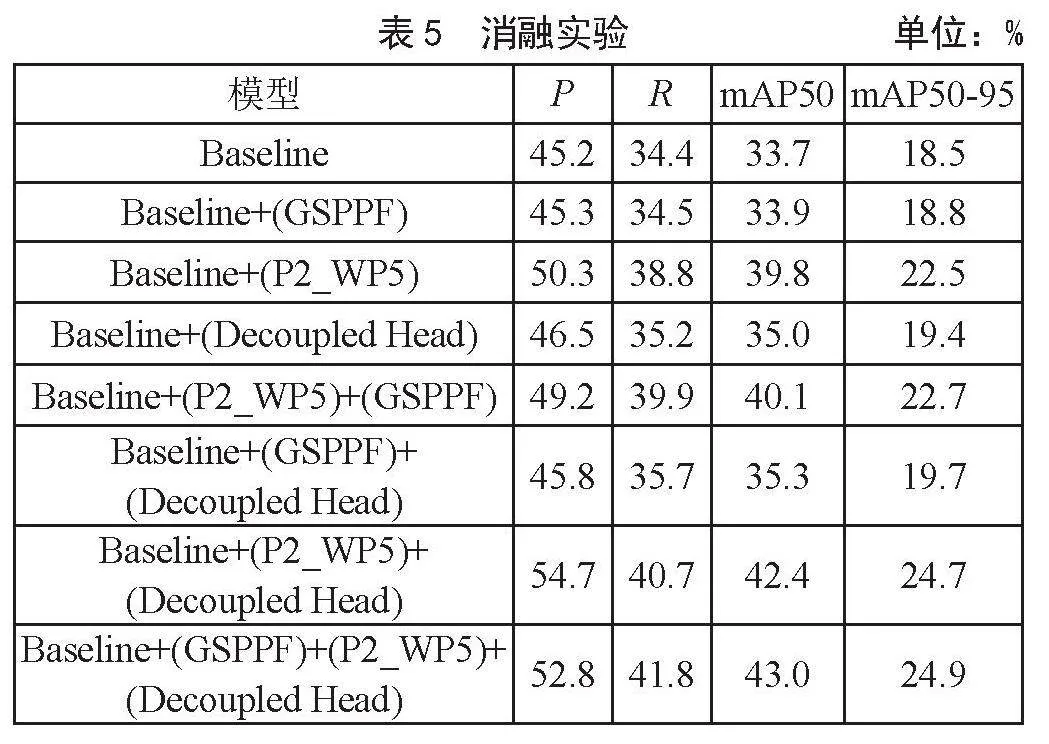
为了验证本文提出的每一个改进方法对原始算法YOLOv5s检测能力的提升程度,现就不同改进方法对原始算法YOLOv5s的效果提升做消融实验。实验结果如表5所示。
由表5可知,每个改进的方法对小目标检测的精度都有提升,证明了GSPPF可有效减少参数量与运算量,且提升了不同尺度特征的提取与融合能力,使得mAP50相比于Baseline上升了0.2%。检测层的改进方法(P2_WP5)在各个评价指标上的提升程度最大,在P、R、mAP50和mAP50-95上分别提升了5.1%、4.4%、6.1%和4%。使得该改进方法成为提升占比最大的部分,证明了在针对小目标检测的算法中,选择合适的感受野是解决漏检误检问题的重中之重。将耦合检测头替换为解耦检测头之后,使mAP50上升了1.3%,证明了解耦检测头能够有效缓解回归任务与分类任务的冲突,使检测精度明显上升。将GSPPF、P2_WP5和Decoupled Head等改进方法同时作用于Baseline,在P、R、mAP50和mAP50-95等评价指标上,分别提升了7.6%、7.4%、9.3%和6.4%。可以看出改进后YOLOv5s算法的检测精度明显优于改进之前,证明了本文方法可以有效提升小目标检测能力。
YOLOv5s算法与GDP2_YOLOv5s算法检测结果如图7所示,其中图7(a)为YOLOv5s检测结果,而图7(b)为GDP2_YOLOv5s检测结果。在图7(a)和图7(b)中分别用虚线粗框和实线粗框圈出YOLOv5s检测结果中漏检和误检的地方,以及在GDP2_YOLOv5s检测结果中缓解漏检和误检的地方。
3.3.3 综合对比实验
为了验证本文方法在小目标检测方面的性能提升,对本文算法与YOLOv3、YOLOv5n、GDP2_YOLOv5s、YOLOv5m、YOLOv5l和YOLOv8等算法进行对比实验。实验结果如表6所示。
从表6可以看出,本文基于YOLOv5s算法改进的针对小目标检测的GDP2_YOLOv5s算法在VisDrone2019_DET数据集上的mAP50值达到了43%,比其他的主流检测算法YOLOv3、YOLOv5n、YOLOv5m、YOLOv5l和YOLOv8分别高出了3.7%、16.1%、4.7%、2.3%和11%,证明了本文算法在缓解小目标漏检误检问题上的有效性,提升了模型对小目标的检测精度。
4 结 论
本文提出一种改进的无人机小目标检测算法GDP2_YOLOv5s,通过将原始算法中的SPPF替换为GSPPF,减少计算量和参数量,提高特征融合效率。采用解耦检测头替代原有的耦合检测头,缓解了分类与回归任务的冲突,提高了检测精度。在PANet结构中新增P2检测头,有效缓解了尺度方差的影响,对小目标更敏感和鲁棒。删除原算法中的P5检测头,减少计算量,更专注于小目标检测,降低误检和漏检。实验证明,GDP2_YOLOv5s相比原算法提高了9.3%的mAP_0.5,FPS达到29帧/秒,同时满足无人机实时检测要求。
参考文献:
[1] 冷佳旭,莫梦竟成,周应华,等.无人机视角下的目标检测研究进展 [J].中国图象图形学报,2023,28(9):2563-2586.
[2] 郭庆梅,刘宁波,王中训,等.基于深度学习的目标检测算法综述 [J].探测与控制学报,2023,45(6):10-20+26.
[3] 潘晓英,贾凝心,穆元震,等.小目标检测研究综述 [J].中国图象图形学报,2023,28(9):2587-2615.
[4] 杨慧剑,孟亮.基于改进的YOLOv5的航拍图像中小目标检测算法 [J].计算机工程与科学,2023,45(6):1063-1070.
[5] 刘涛,高一萌,柴蕊,等.改进YOLOv5s的无人机视角下小目标检测算法 [J].计算机工程与应用,2024,60(1):110-121.
[6] 魏养养,李本银,曹孟新.基于改进的YOLOv5s算法的水下小目标检测 [J].安徽工程大学学报,2022,37(6):31-41.
[7] LIU S,QI L,QIN H F,et al. Path Aggregation Network for Instance Segmentation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8759-8768.
[8] LIN T Y,DOLLÁR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE,2017:936-944.
[9] IOANNOU Y,ROBERTSON D,CIPOLLA R,et al. Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:5977-5986.
[10] GE Z,LIU S T,WANG F,et al. YOLOX: Exceeding YOLO Series in 2021 [J/OL].arXiv:2107.08430v2[cs.CV].[2023-09-20].https://arxiv.org/abs/2107.08430.
作者简介:尹泉贺(2000—),男,汉族,河南周口人,硕士研究生在读,研究方向:图像分类与识别;原素慧(2001—),女,汉族,河南安阳人,硕士研究生在读,研究方向:图像分类与识别;朱梦琳(1998—),女,汉族,河南洛阳人,硕士研究生在读,研究方向:图像分类与识别;兰洁(1999—),男,汉族,河南三门峡人,硕士研究生在读,研究方向:大数据技术分析与应用。
收稿日期:2023-12-04
