自然语言处理领域国内发展态势分析
2024-09-26李惠娇苏博

摘 要:自然语言处理(NLP)对于理解机器如何与人类语言交互至关重要。通过对2000—2023年的文献进行深入分析,结合CiteSpace等文献计量可视化工具,全面探讨了NLP在中国的发展趋势、关键技术和研究热点。研究表明:深度学习、人工智能、机器学习等技术在NLP领域占据核心地位,推动了自然语言理解、生成和解释的进步。知识图谱构建、文本分类、情感分析等研究方向成为研究热点,显示出在信息检索、内容分析等方面的应用潜力。多模态信息融合、自然语言生成的可解释性、跨语言NLP技术,这些方向的探索将为NLP的进一步发展开辟新的道路。
关键词:自然语言处理;发展态势;文献计量;CiteSpace;知识图谱
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)14-0030-07
Analysis of the Domestic Development Trend in the Field of Natural Language Processing
LI Huijiao, SU Bo
(Business School, Shandong University of Technology, Zibo 255000, China)
Abstract: Natural Language Processing (NLP) is essential for understanding how machines interact with human language. Through an in-depth analysis of the literature from 2000 to 2023, combined with bibliometric visualization tools such as CiteSpace, this paper comprehensively discusses the development trend, key technologies and research hotspots of NLP in China. The results show that Deep Learning, Artificial Intelligence, Machine Learning and other technologies occupy the core position in the field of NLP, promoting the progress of natural language understanding, generation and interpretation. Construction of knowledge graph, text classification, sentiment analysis and other research directions have become research hotspots, showing the application potential in information retrieval and content analysis. The exploration of multimodal information fusion, interpretability of natural language generation, and cross-language NLP technology will open up a new path for the further development of NLP.
Keywords: Natural Language Processing; development trend; biblioitrics; CiteSpace; Knowledge Graph
0 引 言
自然语言处理(Natural Language Processing, NLP)是人工智能领域中重要的研究方向,主要目标是使计算机能够理解和处理人类语言,实现自然的人机交互、高效的信息处理和智能化的文本分析[1],对于提升国家信息处理能力、促进科技创新、增强国际竞争力具有重要意义。近年来,随着国家对人工智能[2]领域的重视,NLP技术的发展得到了前所未有的支持。根据《中国制造2025》规划,人工智能被列为新一代信息技术的核心组成部分,而NLP作为人工智能的重要分支,其发展对于实现智能制造、智能服务等领域的突破具有重要作用。
在《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》中明确提出要加强原创性引领性科技攻关。在新一代人工智能领域提到“前沿基础理论突破,专用芯片研发,深度学习框架等开源算法平台构建,学习推理与决策、图像图形、语音视频、自然语言识别处理等领域创新。”要推动人工智能与经济社会各领域深度融合,特别是在自然语言处理等关键技术领域[3],要实现重大突破。此外,NLP技术在智能制造、国家安全、公共管理、文化传播等方面也具有重要作用。
综上所述,自然语言处理领域的研究对于实现国家的现代化建设目标具有重要意义。通过深入分析NLP领域的发展趋势,可以为国家在人工智能领域的战略布局提供科学依据,同时也为相关企业和研究机构提供决策参考,共同推动NLP技术的健康发展。因此,深入研究自然语言处理领域的发展现状和问题,对于促进经济高质量发展、推动智能制造和人工智能高水平应用具有重要的现实意义。
1 研究方法与数据收集
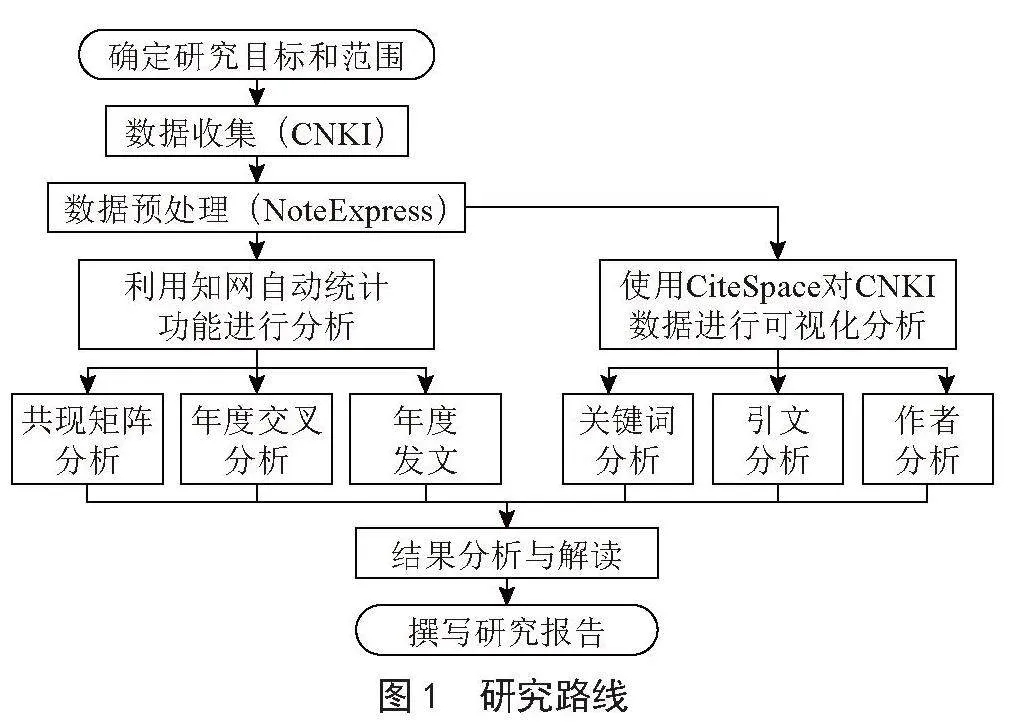
本文采用CiteSpace和VOSviewer等工具进行引文可视化分析,主要以中国知网(CNKI)数据库收录的期刊文献为检索数据源,并开展了检索策略设计,主要研究路线如图1所示。检索策略主要包括:主题检索词设定为“自然语言处理”,语种设置为“中文”,期刊来源设置为“全部期刊”,期刊发表年份范围设置为“2000—2023年”,共计检索出相关文献2 539篇,旨在分析2000—2023年NLP的发展趋势、关键技术、主要研究机构和研究热点。
在数据预处理阶段,利用NoteExpress软件对数据进行清洗和整理,去除冗余和无关数据。随后,利用知网自动统计功能统计该主题的年度发文趋势、共现矩阵和年度交叉分析等。利用CiteSpace软件用于构建关键词分析、机构分析和其他研究热点分析等,以揭示研究热点、趋势、主要研究团队和领军人物,以及国际合作和跨学科研究的模式。通过引文分析,识别领域内的经典和高影响力论文,结合关键词共现和引文分析,识别研究前沿和潜在发展方向。最终,总结NLP领域的发展趋势、关键技术和研究热点,并撰写研究报告,为该领域的未来研究提供参考。
2 NLP领域研究热点分析
2.1 年度发文量趋势分析
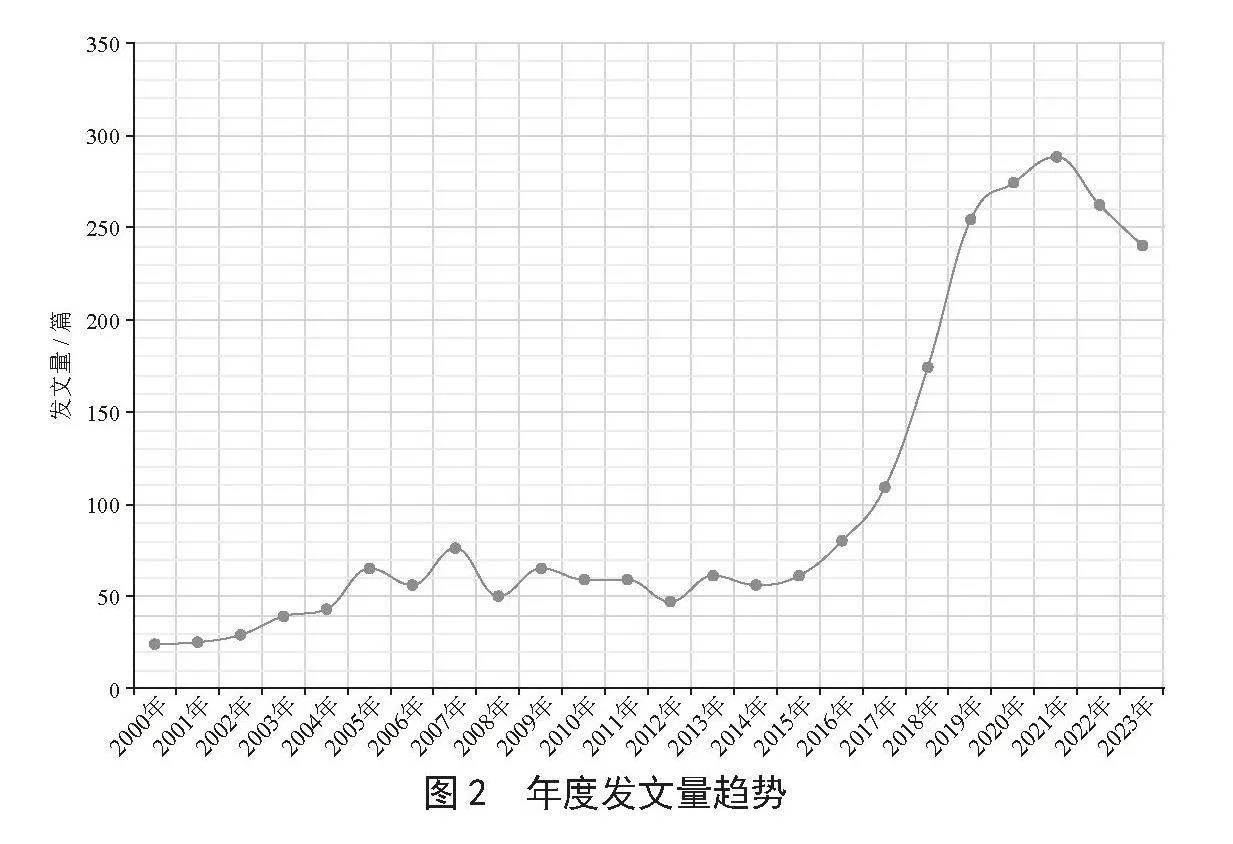
年度发文量趋势标志着该领域研究的活跃度和创新能力的变化趋势,也预示着NLP技术在实际应用中的潜力和未来的发展趋势,如图2所示。
2000—2015年,NLP领域经历了一个相对平稳的发展期,这期间的研究主要集中在基础算法和模型的改进上。然而,从2016年开始,这一领域经历了显著的增长,尤其是在2016—2018年间,发文量呈现出快速上升的趋势。这一增长背后有多个推动因素,主要包括深度学习技术的突破、计算资源的丰富以及应用场景的拓展等。
2.2 阶段发展分析
为了更加直观的了解自然语言处理领域的关键词,通过NoteExpress对得到的2 539条数据进行数据处理。其次,通过CiteSpace来进行关键词的提取,对自然语言处理(NLP)领域的关键词词频和中心度进行分析,得到关键词词频前10位分布情况,如表1所示。
在词频方面,深度学习以259次位居第一,表明深度学习在自然语言处理领域具有极高的关注度。紧随其后的是人工智能(167次)和机器学习(119次),这两个关键词在NLP领域也具有很高的热度。知识图谱、文本分类、情感分析、神经网络、词向量和自然语言等关键词的词频分别为75、70、68、62、46、43次,表明这些技术在NLP领域也受到了广泛关注,根据词频统计得到如图3所示的词云图。
最后,从年份的角度分析,这些关键词在不同年份的关注度有所差异,结合如图4所示的关键词时区图可以观测到NLP领域关键词的发展情况。
深度学习在2013年达到高峰,人工智能在2015年受到广泛关注,而机器学习则在2014年取得了显著的发展。这可能与当时计算机硬件的进步、大数据的普及以及算法的创新等因素有关。知识图谱、文本分类、情感分析、神经网络、词向量和自然语言等关键词在2017—2018年间逐渐崛起,表明这些技术在近年来的自然语言处理领域中越来越受到重视。这些技术的快速发展为自然语言处理领域带来了新的机遇与挑战。
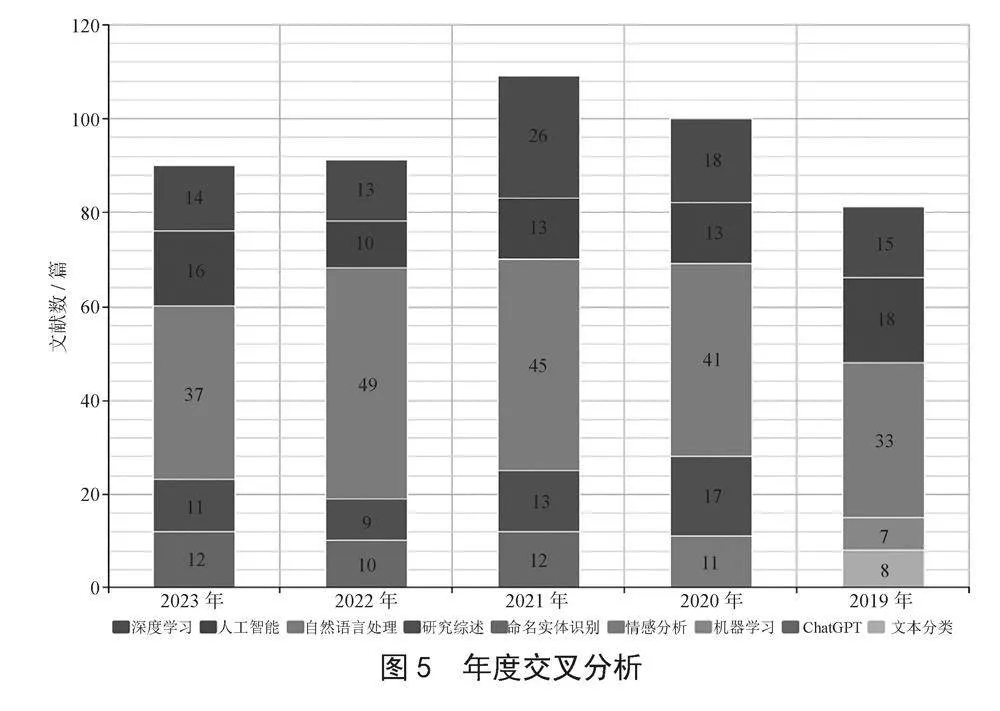
为了更直观更详细的观测近五年内NLP领域的发展趋势,利用如图5所示的年度交叉分析图进行分析。
2019—2023年,自然语言处理(NLP)领域的研究取得了显著的进展。这一领域的研究主要集中在深度学习、人工智能、自然语言处理、研究综述、命名实体识别、情感分析、机器学习和文本分类等方面。
2019年,自然语言处理领域的研究主要集中在深度学习和人工智能技术的发展。研究人员开始探索如何将这些技术应用于自然语言处理任务,如文本分类和机器学习。此外,研究者们开始关注机器学习在自然语言处理中的应用,以及如何利用这些技术进行文本分类。在这一年,自然语言处理文献数量最多,其次是人工智能。
2020—2021年,随着深度学习和人工智能技术的不断发展,研究开始关注这些技术在自然语言处理任务中的应用。命名实体识别和情感分析等任务得到了更多的关注。此外,研究综述文章开始关注这些技术的潜力和挑战。在这两年,自然语言处理文献数量依然最多,深度学习紧随其后。
2022—2023年,随着自然语言处理领域的不断发展,研究开始关注如何将这些技术与其他领域相结合,以解决更复杂的问题。例如,研究者们开始关注ChatGPT [4]等对话系统在客户服务、教育和娱乐等领域的应用。此外,研究者们还开始关注如何利用这些技术进行跨语言和跨领域的知识迁移。在这一年,自然语言处理文献数量仍然最多,其次是人工智能和命名实体识别。
2023年(截至11月),自然语言处理领域的研究继续关注深度学习和人工智能技术的发展。研究者们开始关注如何利用这些技术解决实际问题,如信息检索、知识图谱构建和自动摘要等。此外,研究者们还开始关注如何利用这些技术提高自然语言处理任务的性能和效率。在这一年,自然语言处理文献数量仍然最多,人工智能紧随其后。
2.3 关键词共现分析
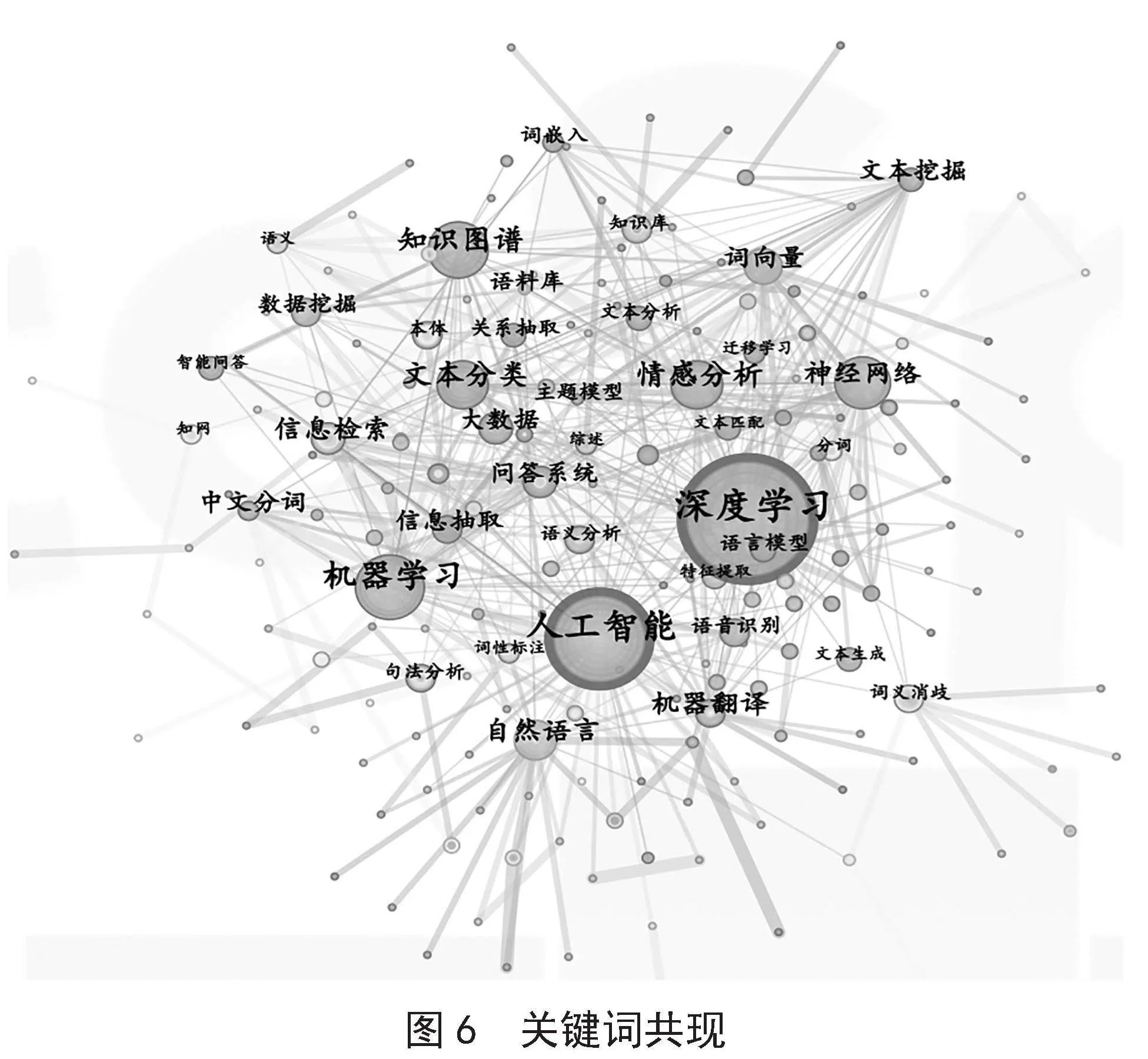
关键词共现分析是一种研究文献中关键词之间相互关系的方法。它通过统计关键词在文献中出现的频次和位置,以及它们与其他关键词的共现情况,来揭示文献主题和内容的特征。使用CiteSpace对关键词进行了分析,共得到299个节点(N节点),表示文献中的关键词数量,528条连线(E连线)连接这些节点,表示关键词之间的共现关系,如图6所示。
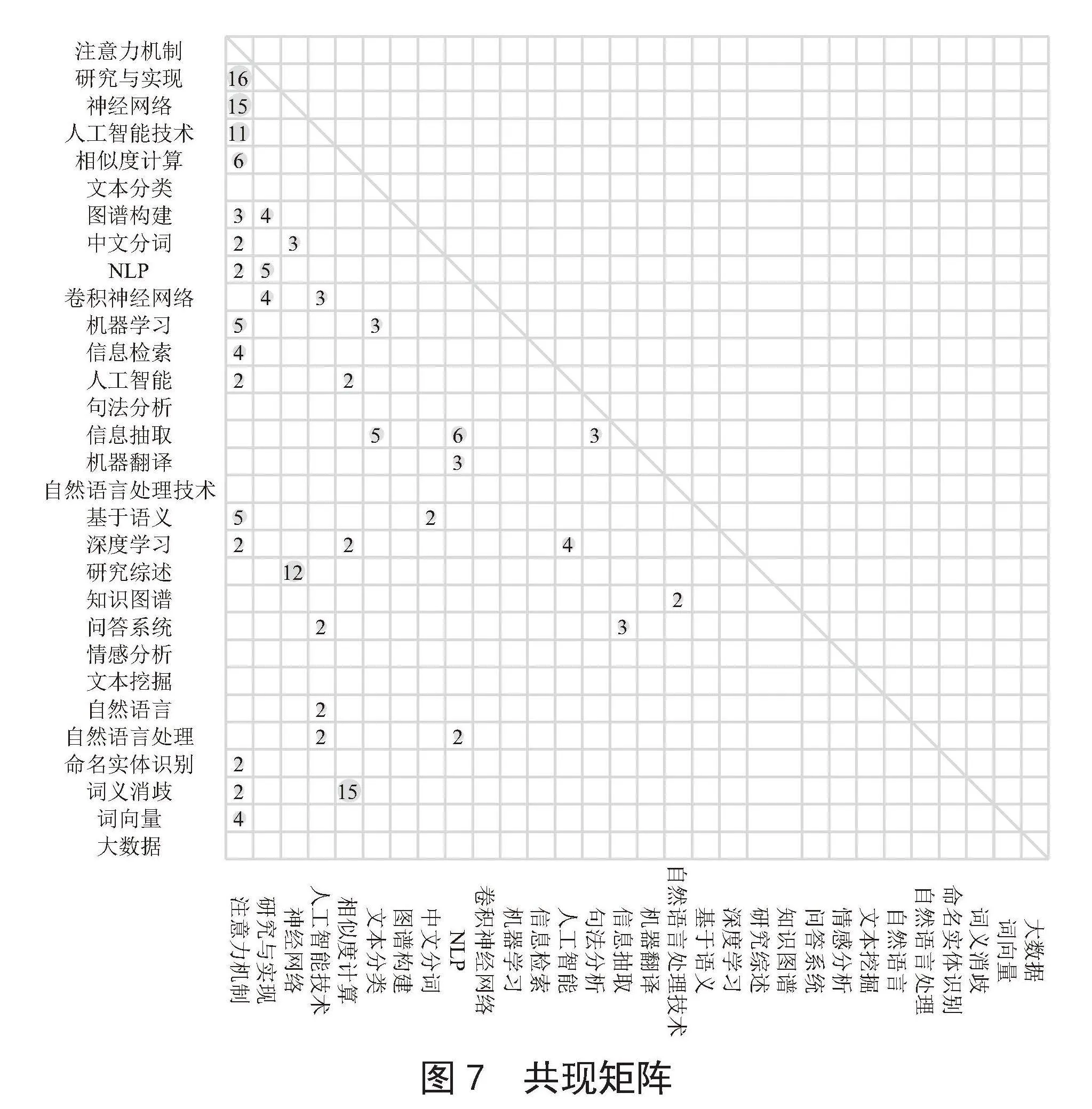
在关键词共现图谱中,关键词字体的大小反映了其出现频次数量的不同,频次大小与可视化节点的字体大小成正比;关键词间连线的粗细程度反映了关键词之间的联系程度,其间的连线越粗代表关键词联系越紧密。同时利用知网自动统计出的如图7所示的共现矩阵可以更直观地看出关键词之间的联系情况。
在神经网络和关系抽取[5]之间,关系抽取是从文本中识别实体之间的关系,如人物、地点、组织等。神经网络在关系抽取任务中表现出色,可以有效地捕捉实体之间的语义关系。
在神经网络和注意力机制之间,神经网络是深度学习的基础,通过模拟人脑神经元的连接和计算方式来进行学习。结合注意力机制,神经网络可以更好地处理自然语言处理任务,如文本分类、情感分析等。
然而,这些研究课题仅仅是自然语言处理领域中众多共现领域的冰山一角。随着技术的不断发展,我们可以预见到更多有待研究的领域,如跨语言处理、多模态信息融合、知识图谱构建等。这些领域不仅具有广泛的研究前景[6],还有望为人类带来更智能、更高效的自然语言处理技术。
2.4 关键词聚类分析
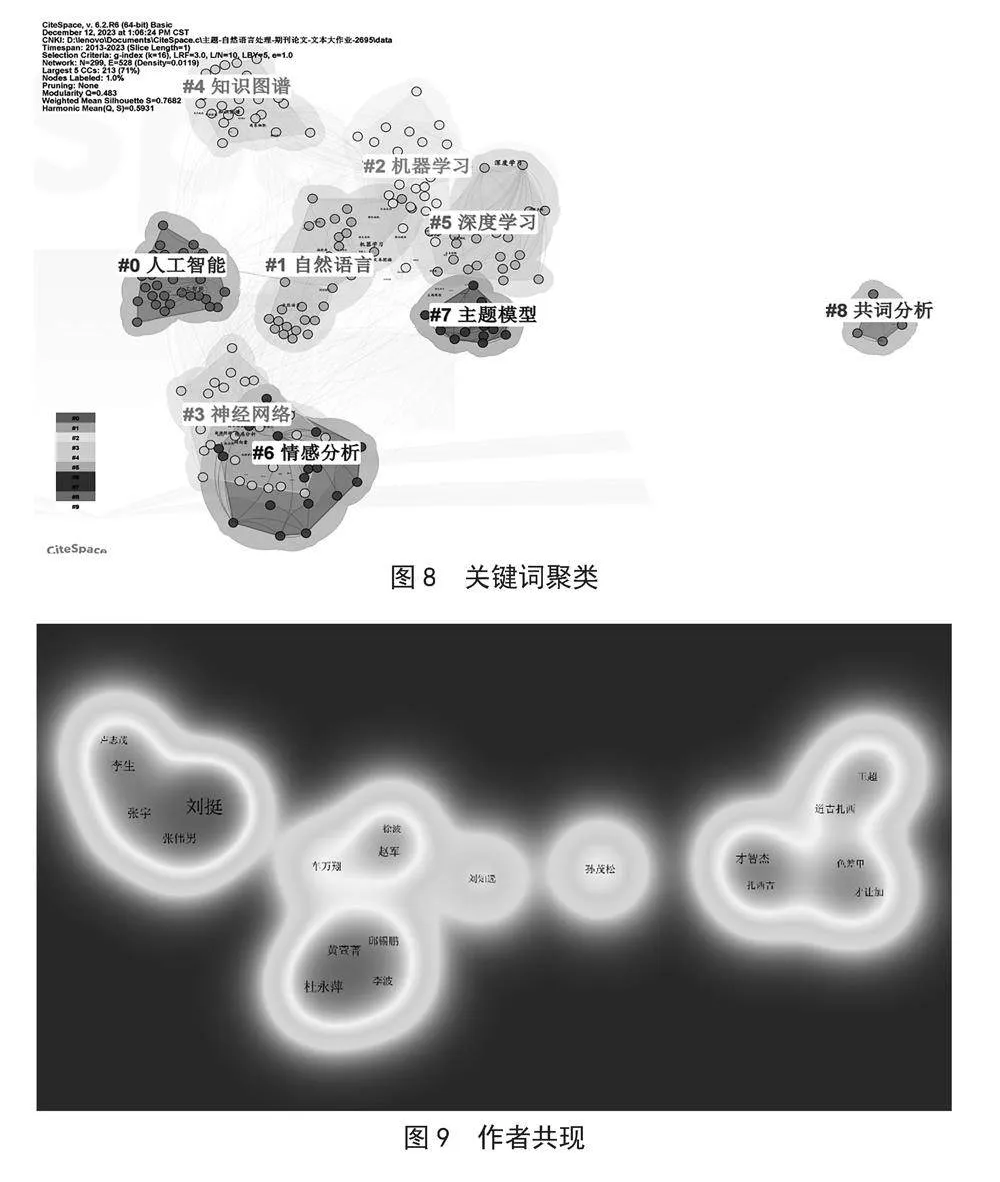
关键词聚类分析是一种常用的文本挖掘方法,用于将大量文本数据中的关键词进行分类和组织,以揭示其中的关联和模式。利用CiteSpace我们得到了关键词聚类分析图,如图8所示,把相近的同一主题的关键词进行归类。
关键词共聚成了92类,为保证图谱清晰[7],本文仅选取具有代表性的前8个聚类,分别是人工智能、自然语言、神经网络、知识图谱、深度学习、情感分析、主题模型、共词分析。其中Q值= 0.483>0.4,表明聚类结构显著;S值= 0.768 2>0.7,说明聚类中的关键词之间的关联程度较高。所以,聚类结果具有较高的内部一致性和外部有效性。这意味着识别出的这八个聚类在自然语言处理领域具有很好的代表性和区分度,可以为后续的研究和应用提供有价值的参考。
2.5 作者分析
为了更直观的看出作者之间的合作关系,使用了VOSviewer软件对作者进行了分析,得出如图9所示的作者共现图。
在作者共现分析图里面,我们设置了作者最低的发表项目为3,其中267位作者符合,但是,能够合作完成的只有24位,说明在自然语言处理领域,发表的文章是很多的,但是作者与作者之间的合作相对较少,其中这24名作者中大概分了4部分,以刘挺为首的那一组项目最多,说明刘挺、张伟男、张宇、李生和卢志茂他们几个人合作是比较密切的。孙茂生作者与其他的作者合作是比较少的。
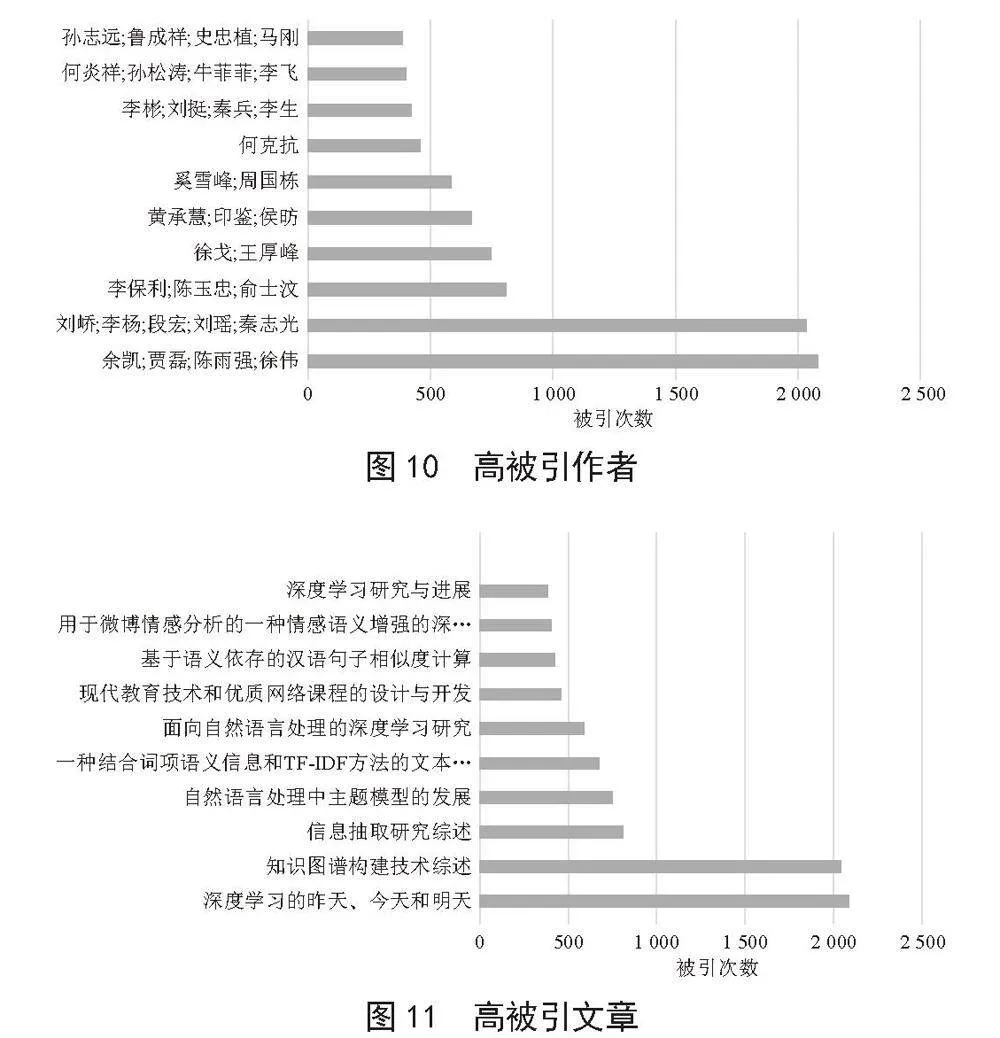
一个学科的发展归根结底是要靠其学者的共同努力,而高被引科学家的学术影响力可通过ESI高被引论文数量高低来衡量,高被引作者和高被引文章分析图如图10和11所示。
借助Excel软件对自然语言处理领域研究的2 539篇期刊论文进行筛选统计前10个高被引文章及其作者。可知余凯学者最早在2013年带领其团队研究的关于自然语言领域方面的文章《深度学习的昨天、今天和明天》被引用数最多,被引用数量是2 080次。
余凯先生现任地平线创始人兼CEO,是国际知名机器学习专家,中国深度学习技术主要推动者。余凯是深度学习领域的领军人物之一,他带领的团队在语音识别,计算机视觉,互联网广告,网页搜索排序等互联网核心业务上取得突破性进展。2014年以来,余凯还领导了百度大脑,自动驾驶,BaiduEye,以及DuBike等一系列创新项目,在国内外业界产生重大影响。余凯先生在学术界的不断努力和探索,取得了很多成果,发表期刊论文600余篇。余凯先生对于自然语言处理领域的深入研究和贡献,为这一领域的发展做出了重要贡献,对后来者提供了很好的借鉴。
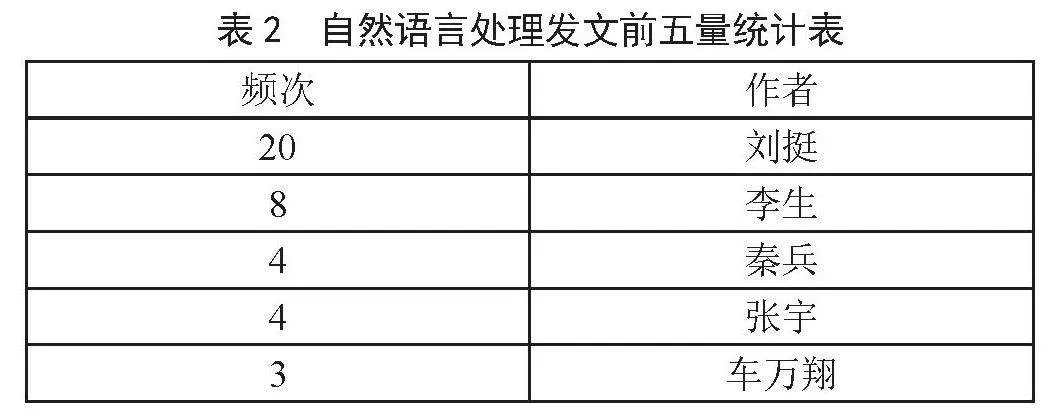
在对导出2 539篇自然语言处理领域的学术期刊中,摘取发文数量最多的前5名学者,如表2所示,刘挺学者的发文数量最多,频次为20次,2012—2017年在自然语言处理领域顶级会议发表的论文数量列世界第8位(据剑桥大学统计),主持研制“语言技术平台LTP”“大词林”等科研成果被业界广泛使用。近几年,随着计算机算力的提升与深度学习技术的发展,自然语言处理相关问题也迎来许多重大的创新与突破。尽管研究难度不小,但是对于人类的发展必须需要学者们不断地努力探索和创新。
3 思考与建议
3.1 多语种处理的需求尚未满足
在全球化的背景下,多语言交流的需求日益增长。针对低资源语言,研究者和开发者应开发更加灵活和适应性强的NLP工具,这些工具应能够利用有限的数据资源,通过迁移学习等技术,快速适应新的语种环境。此外,考虑到文化差异对语言理解的影响,建议在工具开发中融入跨文化交际的考量,以提高模型在不同文化背景下的适用性。
3.2 语言歧义的识别与处理
歧义性是自然语言的固有特性,它包括词汇歧义、句法歧义和语义歧义等。为了提高NLP系统对歧义的识别和处理能力,研究者可以探索结合深度学习和知识图谱的方法,利用上下文信息和先验知识来消解歧义。同时,认知科学和语言学的研究成果可以为模型提供更丰富的语义[8]理解框架,帮助系统更好地理解语言的多义性。
3.3 信息安全与社会伦理问题
随着NLP技术在自动化内容生成、情感分析等领域的应用,信息安全和社会伦理问题变得尤为突出。建议制定全面的技术标准和伦理指南,包括但不限于数据隐私保护、算法透明度和公平性、以及防止滥用技术进行误导和操纵。此外,建立监管机制,确保NLP技术的应用符合社会道德和法律规定[9]。
3.4 跨学科研究的深化
NLP的发展需要计算机科学、语言学、心理学等多学科的共同努力。建议建立跨学科研究中心,促进不同领域的专家共同探讨NLP的理论和实践问题。此外,通过组织跨学科研讨会和工作坊,鼓励研究人员分享最新的研究成果和方法,推动学科间的知识和技术融合[10]。
3.5 开放资源和数据共享
开放资源是推动NLP研究和应用的关键。建议建立一个全球性的开放资源平台,收集和整理各种语言的语料库、预训练模型和工具包。这样的平台不仅能够降低研究和开发的成本,还能够促进全球范围内的技术创新和知识传播[11]。
3.6 教育和人才培养
为了满足NLP领域对专业人才的需求,建议在高等教育机构中加强NLP相关课程的设置,同时提供实践性强的课程和项目,让学生能够在实际问题中应用所学知识。此外,通过与企业的合作,为学生提供实习和就业机会,帮助他们更好地将理论知识转化为实际技能。
4 结 论
本文综述了2000—2023年中国NLP领域的进展,强调了深度学习、人工智能和机器学习技术在推动自然语言理解、生成和解释方面的关键作用。研究热点集中在知识图谱构建、文本分类和情感分析,这些技术在信息检索和内容分析中显示出巨大潜力。未来研究方向包括多模态信息融合、自然语言生成的可解释性以及跨语言NLP技术。文献计量分析揭示了自2016年以来NLP领域的快速增长,以及深度学习等技术的高频关键词。文章还讨论了学者合作网络和高被引作者的重要性。最后,提出了促进NLP健康发展的建议,如满足多语种需求、关注信息安全与伦理、深化跨学科研究、资源和数据共享,以及加强人才培养,以支持国家人工智能战略和经济高质量发展。
参考文献:
[1] 杨裕楷,赵毅,章成志.什么类型的机构合作会产生更高的学术影响力?——以自然语言处理领域为例 [J/OL].图书馆论坛,2023:1-14[2024-01-21].http://kns.cnki.net/kcms/detail/
44.1306.G2.20231215.0810.002.html.
[2]郝立涛,于振生.基于人工智能的自然语言处理技术的发展与应用 [J].黑龙江科学,2023,14(22):124-126.
[3] 陈伟.人工智能在自然语言处理中的研究 [J].信息记录材料,2023,24(10):92-94.
[4] 武俊宏,赵阳,宗成庆.ChatGPT 能力分析与未来展望 [J].中国科学基金,2023,37(5):735-742.
[5] 任敏慧,樊宇.自然语言处理在我国社会科学领域应用的发展路径识别与构建研究 [J].科技和产业,2023,23(18):7-16.
[6] 任乐,张仰森,刘帅康.基于深度学习的实体关系抽取研究综述 [J].北京信息科技大学学报:自然科学版,2023,38(6):70-79+87.
[7] 孙伟,李一,马永强.基于自然语言处理技术的知识图谱构造方法研究 [J].集宁师范学院学报,2023,45(5):94-97.
[8] 车万翔,窦志成,冯岩松,等.大模型时代的自然语言处理:挑战、机遇与发展 [J].中国科学:信息科学,2023,53(9):1645-1687.
[9] 常宝宝.自然语言分析与生成术语简介 [J].术语标准化与信息技术,2010(4):19-22+25.
[10] 刁丽娜.基于Citespace的电子资源研究图谱化分析 [J].河南图书馆学刊,2019,39(5):92-95.
[11] 张勇,王永明,王春伟,等.BIM技术在国内外项目管理中的应用现状与发展趋势 [J].广东水利电力职业技术学院学报,2023,21(1):42-46.
作者简介:李惠娇(2002—),女,汉族,山东济宁人,本科在读,研究方向:文本挖掘与大数据技术;苏博(2004—),男,汉族,山东菏泽人,本科在读,研究方向:数据挖掘。
收稿日期:2024-01-22
基金项目:2023年山东理工大学大学生创新创业训练项目
DOI:10.19850/j.cnki.2096-4706.2024.14.007
