基于递归神经网络的藏语语音转文本应用研究
2024-09-20彭杨徐健卓嘎付好邢立佳


摘要:本文针对藏语中的卫藏方言,探讨了自动语音识别(automatic speech recognition,ASR)技术在语音识别模型构建方面的应用。利用时间递归神经网络(recurrent neural network,RNN)及其变体来提升ASR系统的性能。通过引入LAS(listen,attend and spell)模型,并结合多任务学习框架、深度卷积神经网络和改进的注意力机制,显著提升了ASR系统的性能。在实验中,改进后的LAS模型在测试集和训练集上的词错误率分别达到了12.40%和16.23%,实验结果验证了方法的有效性。
关键词:时间递归神经网络;自动语音识别;藏语语音
引言
藏语是汉藏语系中的一个分支,主要在西藏自治区、青海省、四川省、甘肃省和云南省等地使用。藏语使用人数少,且使用者大多分布在经济水平较低的地区,导致藏语的语音处理技术方面较为落后。藏语语系有三个分支,分别为卫藏方言、安多方言、康巴方言,本文的语音识别以卫藏方言作为研究对象。
自动语音识别(ASR)技术在现代人机交互中至关重要,应用广泛。随着深度学习技术的发展,端到端ASR系统成为研究热点,其中LAS[1]模型因其高效和性能优越而备受关注。LAS模型通过编码器、注意力机制和解码器的结合,能够直接将语音输入映射为文本输出,简化了系统架构,并通过端到端训练提升了识别精度。
时间递归神经网络(temporal recursive neural network)也称为循环神经网络(recurrent neural network,RNN)[2],是一类专门用于处理序列数据的神经网络,通过在时间维度上递归地处理输入数据,能够捕捉时间序列中的动态变化和依赖关系。与传统的前馈神经网络不同,RNN具有循环连接,使网络能够保留和利用过去时间的信息,使其在自然语言处理(NLP)、语音识别和时序预测等领域得到广泛应用。
在本文中,RNN及其变体如长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gated recurrent unit,GRU)被广泛应用于多个关键模块,以增强系统对时间序列数据的处理能力。在自动语音识别(ASR)模块中,RNN层用于对语音特征进行编码,通过递归地处理音频帧,捕捉音频信号中的时间依赖性。在解码器部分,GRU模块用于将语音特征转换为文本。在连接时序分类(connectionist temporal classification,CTC)解码过程中,结合RNN语言模型(RNNLM)以提供上下文信息,增强语言建模能力,提高识别准确率。
此外,在解码过程中,通过维护和更新LSTM和GRU的隐藏状态,保证了解码过程的连续性和准确性。通过在这些模块中的应用,RNN及其变体显著提升了系统处理语音信号的能力和整体性能。引入多任务学习框架提升模型的泛化能力,采用深度卷积神经网络捕捉卫藏方言的时频特征,并改进注意力机制,以在长时间语音处理中表现更佳。实验结果表明,改进后的LAS模型在多个卫藏方言数据集上的性能优于现有方法,验证了该方法的有效性。
1. ASR
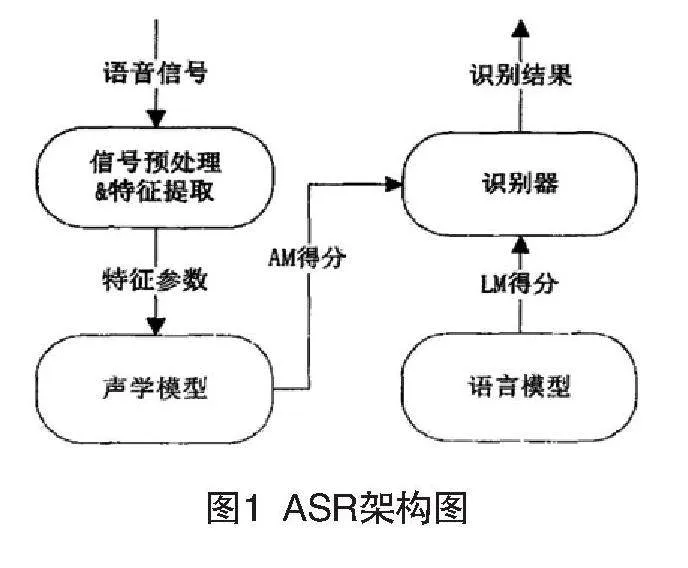
语音识别系统(ASR)的基本处理流程就是将接收到的语音信号经过处理后转化为相应的词序列,典型的ASR架构如图1所示。
ASR主要由四个部分组成:信号预处理和特征提取、声学模型(AM)、语言模型(LM)和识别器。信号预处理和特征提取组件以音频信号作为输入,通过消除噪声和信道失真来增强语音信号,将信号从时域转换到频域,然后提取适合下一步声学模型的特征矢量。声学模型组件通过集成声学和语音学知识,W特征提取组件生成的特征向量序列作为输入,并生成该特征向量序列的声学模型得分。语言模型组件通过对训练语料的学习获得词间相关性,并以此来估计假设词序列的概率或者语言模型(LM)得分[3]。根据统计语音识别的基础数学理论可知:假设X表示待识别的语音特征向量序列(观察序列),W表示词序列,那么对应于观察序列的词序列W*表示为
(1)
根据贝叶斯理论有
(2)
(3)
其中,P(X\W)表示在给定词序列W的情况下观测到语音特征X的概率,即声学模型的概率;P(W)表示词序列的先验概率,即语言模型的概率。
2. LAS模型
LAS模型是一种端到端的序列到序列(seq to seq)模型,旨在解决语音识别任务。与传统的语音识别系统不同,LAS模型不需要明确的音素边界标注和语言模型,可以直接从语音信号中学习到对应的文本序列。LAS模型的架构图如图2所示。
模型的输入和输出分别为x和y。
(4)
(5)
其中,,yi是输出序列的字符。[sos]、[eos]分别是句子开头和结尾的标志,[unk]表示未知标志。LAS根据前面输出的字符y<i和输入信号x使用概率的链式规则,将输出字符建模成条件分布
(6)
LAS模型主要包括两个子模块:listener和speller。listener是声学模型的编码器,主要执行Listen操作,这个操作主要将原始信号x转换为高层次的表示h=(h1,…,hu)且满足U≦T。speller是一个基于注意力机制的编码器,只要执行操作AttendAndSpell这个操作将h作为输入,计算一个概率分布
(7)
(8)
Listen操作使用金字塔形的BLSTM,记为pBLSTM,这个结构可以将h的长度从T减到U,因为T是输入信号的长度,输入信号可以很长。传统的BLSTM,当在第i时间第j层时,输出为
(9)
在pBLSTM中,其表达式为
(10)
在每一步的操作中,模型根据目前已经预测出的字符,来估计下一个字符概率分布。输出字符yi的分布与解码状态si和上下文向量context vector(ci)有关。解码状态si与三个参数有关,分别为:前一个解码状态si-1、前面预测的字符yi-1、前一个上下文变量ci。上下文向量ci根据注意力机制[4]计算得到,即
(11)
(12)
(13)
其中,CharacterDistribution是MLP关于字符的输出,RNN是2层LSTM。
在时间i中,注意力机制(文中用AttentionContext表示)产生一个上下文向量ci,这个上下文向量可以从声学模型获取产生下一个字符的信息。注意力模型与内容相关,解码器状态si与高层特征表示hu匹配,可以产生注意力因子α,用参数αi对向量进行线性压缩,即可得到上下文向量ci。具体而言,在时间i里,AttentionContext函数使用参数hu和si来计算标量波能量scalar energy(记为ei,u),其中。然后,标量波能量ei,u使用softmax函数,转换为概率分布。softmax概率当作混合权重,用于将高层特征hu压缩成上下文向量ci,即
(14)
(15)
(16)
其中,和是多层感知机网络,训练后,αi分布比较集中,只关注小部分h中的帧;上下文向量ci可以看成h的权重向量。
3. 实验
为保证所有模型训练环境的一致性,本文所有实验均在安装Linux操作系统的同一台高性能服务器上完成,使用PyTorch2.3.0深度学习框架和Python3.12(Ubuntu 22.04)进行神经网络模型的构建、训练与测试,并配置NVIDIA RTX 4090D GPU(24GB显存)进行加速。实验硬件配置包括15个vCPU(Intel(R) Xeon(R) Platinum 8474C处理器)、80GB内存、30GB系统盘和50GB数据盘。该环境采用CUDA12.1确保GPU加速性能,所有实例共享同一地区的网络带宽。
3.1 数据集
实验采用Zhao等[5]公开的包含30小时的卫藏藏语语音数据TIBMD@MUC,具体数据如表1所示。
本次实验词错误率为评判标准(WER),公式为
(17)
其中,S是替换错误(substitutions)的数量,即将一个正确的单词错误地识别为另一个单词的数量。D是删除错误(deletions)的数量,即漏掉了一个正确单词的数量。I是插入错误(insertions)的数量,即额外插入了一个错误单词的数量。N是参考文本中的单词总数(即正确单词的总数)。
3.2 实验结果及分析
在本实验中,使用torchaudio工具对语音数据进行特征提取[6]。具体来说,提取了80维的滤波器组(Fbank)特征,音频窗长为25毫秒,窗移为10毫秒。为增强数据的多样性和模型的鲁棒性,在每帧音频中添加了0.1的随机噪声系数。此外,应用了均值和方差归一化(CMVN),这种方法能够标准化音频特征,使其具有零均值和单位方差,从而消除不同音频信号之间的统计差异。增加了二阶差分特征,捕捉音频信号的动态变化。设置了每1000步进行一次验证(valid_step),以便实时监控模型的性能,防止过拟合。最大训练步数(max_step)设定为100万步。采用了教师强制策略(teacher forcing),起始值和结束值均为1.0,步长为50万步,有助于在训练的早期阶段通过提供正确的历史输出来稳定模型训练过程。使用AdamW作为优化器,这是一种改进的Adam优化器,适用于大规模数据训练。学习率设置为0.001,epsilon值为1e-8,以确保优化过程的数值稳定性。使用了warmup策略的学习率调度器,预热步数为4000。
在训练阶段,使用了CTC损失和注意力损失的联合损失函数[7]。具体来说,CTC损失的权重设置为0.5,而注意力损失的权重也设置为0.5。这种权重设置的目的是平衡模型对齐问题和上下文建模的能力,从而优化模型在处理复杂语音信号时的表现。CTC可以实现对齐输入序列和输出标签,但是若建模单元为互相独立,没有考虑到标签之间的组合关系,即没有语言模型,则会导致识别准确率不高。而Attention机制通过注意力权重建立标签各种组合的可能性,但输出序列和输入序列不一定按顺序严格对齐。因此,将CTC和Attention结合起来构建联合CTC/Attention模型,Attention融入CTC自动对齐的优点,可以避免解码时对齐过于随机,提高识别率[8]。
在解码阶段,结合了CTC解码和语言模型解码的策略。CTC损失的权重设置为1.0,而语言模型的权重设置为0.5。在解码过程中,CTC解码负责提供基础的语音到文本的转换,而语言模型则通过其语言建模能力对初步的解码结果进行修正和优化。联合解码策略通过综合利用CTC解码的精确性和语言模型的上下文理解能力,显著提升了解码的准确率。最终实验结果如表2所示。
通过联合损失[9]和联合解码策略的应用,能够在训练和解码的不同阶段充分利用各自的优势。联合损失在训练过程中平衡了不同损失函数的影响,提升了模型的泛化能力和对复杂语音信号的处理能力。联合解码在解码过程中结合了CTC和语言模型[10]的优势,显著提高了最终的解码准确率。实验结果表明,这种综合策略在不同数据集上的表现均优于单一损失或单一解码策略,验证了方法的有效性。
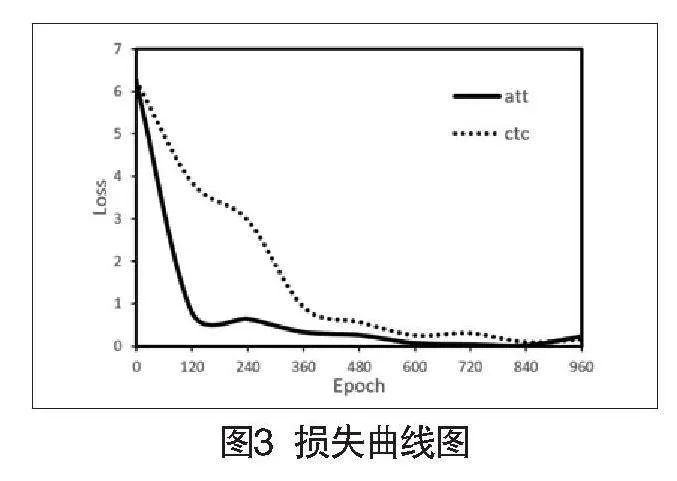
CTC、Attention的损失曲线图如图3所示,在藏语语音中,两个损失函数都在训练初期迅速下降,表明模型在学习过程中逐渐提高了性能。Attention在整个训练过程中下降速度较快,且在中期达到稳定状态,表明注意力机制在帮助模型捕捉数据中的相关模式方面非常有效。CTC下降速度较慢,并且在中期和后期出现了一些波动。由此看来,Attention损失相对CTC更小,且下降得更快。
结语
实验结果表明,改进后的LAS模型在多个卫藏方言数据集上的表现优于现有方法,验证了方法的有效性。在实验过程中,通过联合损失和联合解码策略,充分利用了连接时序分类(CTC)和语言模型(LM)的优势,提高了语音识别的准确率。具体来说,CTC解码提供了基础的语音到文本转换,而语言模型则对初步的解码结果进行了优化和修正。这种综合策略不仅增强了模型对复杂语音信号的处理能力,也提升了其泛化能力。
本文研究为端到端ASR系统在少数民族语言识别中的应用提供了新思路,并为卫藏方言的数字化建设提供了实验数据,以期进一步推动ASR技术在卫藏方言识别中的发展及其实际应用。
参考文献:
[1]Chan W,Jaitly N,Le Q,et al.Listen,Attend and Spell:A Neural Network for Large Vocabulary Conversational Speech Recognition[EB/OL].(2016-05-19)[2024-08-02].https://xueshu.baidu.com/usercenter/paper/show?paperid=70115bedb293ef7b4b3393d894c27a41&site=xueshu_se.
[2]杨丽,吴雨茜,王俊丽,等.循环神经网络研究综述[J].计算机应用,2018,38(S2):1-6,26.
[3]王之杰.基于迁移学习的跨语言藏语拉萨话语音识别研究[D].北京:中央民族大学,2023.
[4]朱张莉,饶元,吴渊,等.注意力机制在深度学习中的研究进展[J].中文信息学报,2019,33(6):1-11.
[5]ZHAO Y,XU X,YUE J,et al.An open speech resource for Tibetan multi-dialect and multitask recognition[J].International Journal of Computational Science and Engineering,2020,22(2/3):297-304.
[6]高耀荣,边巴旺堆.基于端到端深度学习的藏语语音识别研究[J].现代计算机,2023,29(17):25-30.
[7]刘晓凤.藏语语音深度特征提取及语音识别研究[D].北京:中央民族大学,2017.
[8]滕思航,王烈,李雅.融合音字特征转换的非自回归Transformer中文语音识别[J].计算机科学,2023,50(8):111-117.
[9]王志峰,李军,张晓平.基于联合损失函数的深度学习模型训练方法研究[J].计算机科学,2020,47(6):45-52.
[10]李明,王伟,刘杰.结合CTC和语言模型的语音识别系统研究与实现[J].软件学报,2021,32(10):2378-2386.
作者简介:彭杨,本科在读,3311986574@qq.com,研究方向:语音处理和语音识别。
