基于分层强化学习的多智能体博弈策略生成方法
2024-09-19畅鑫李艳斌刘东辉






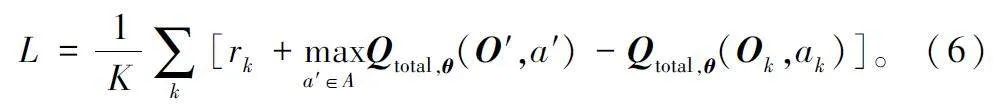
摘 要:典型基于深度强化学习的多智能体对抗策略生成方法采用“分总” 框架,各智能体基于部分可观测信息生成策略并进行决策,缺乏从整体角度生成对抗策略的能力,大大限制了决策能力。为了解决该问题,基于分层强化学习提出改进的多智能体博弈策略生成方法。基于分层强化学习构建观测信息到整体价值的决策映射,以最大化整体价值作为目标构建优化问题,并推导了策略优化过程,为后续框架结构和方法实现的设计提供了理论依据;基于决策映射与优化问题构建,采用神经网络设计了模型框架,详细阐述了顶层策略控制模型和个体策略执行模型;基于策略优化方法,给出详细训练流程和算法流程;采用星际争霸多智能体对抗(StarCraft Multi-Agent Challenge,SMAC)环境,与典型多智能体方法进行性能对比。实验结果表明,该方法能够有效生成对抗策略,控制异构多智能体战胜预设对手策略,相比典型多智能体强化学习方法性能提升明显。
关键词:分层强化学习;多智能体博弈;深度神经网络
中图分类号:TN929. 5 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)06-1361-07
0 引言
策略生成技术是指通过计算或学习,生成用于指导决策策略的方法和技术。随着人工智能技术的不断发展,策略生成技术被广泛应用于解决各种复杂的问题。策略通常是一个映射,将环境的状态映射到可能的行动或决策,以最大化某种目标函数(如累积奖励、成功率等)。相比于利用并且依靠专家经验和领域知识的策略生成方法,基于海量数据的智能决策降低了知识门槛,并且过程更加客观,避免主观因素影响[1],特别是在零和对抗场景中[2-3]。因此,当前智能博弈策略生成技术已经广泛应用于无人机协同对抗[4]、通信智能抗干扰[5]和智能协同欺骗[6]等电磁频谱作战任务中。
当前,主流策略生成技术采用深度强化学习方法[7],根据方法结构和应对受控体数量,可以分为集中式方法和分布式方法。集中式方法统一汇集观测信息并完成所有受控实体的动作映射。特别是基于Deep QNetwork (DQN)方法的集中式方法在电磁频谱规划等场景中获得良好表现[8-10],得益于结构良好的可扩展和改进性,能够适应多种状态形式的观测数据,如图形化的频谱瀑布图[11]、长短时高维数据[12]等。但是,随着受控数量的增加,集中式方法神经网络的神经元数量将成指数上升,使得参数优化效率变慢,策略生成性能变差,并且资源需求量大幅增加。
针对该缺点,“集中式训练,分布式执行”成为解决当前问题的主流理念。分布式方法分别构建对应受控个体的观测到动作的映射网络,再构建拟合网络用于拟合个体动作价值到整体价值的映射。将整体“大网络”拆分成多个“小网络”,避免了维度爆炸。但是,该方法的难点在于由个体动作价值拟合整体价值。作为经典方法Value-Decomposition Net-works(VDN)直接将个体动作价值相加得到对整体价值。但是,并非所有个体都具有相同权重的动作价值。特别是在异构博弈对抗环境中,由于受控个体能力不同,权重必然不同。文献[13]中,“QMIX”多智能体强化学习方法采用超神经网络的方法对于整体价值进行了估计,使得个体动作价值到整体价值的映射具有非线性特性,有利于对整体价值的估计。文献[14]中,“Qtran”方法在此改进思路上进一步延伸,通过构建等价函数、改进值分解等方法,提高了方法的适应性,获得更优的效果。但是,该思路在全局信息的利用上存在缺点。个体只采用部分可观察信息决策,协同能力是在训练过程中由整体价值分解得到的,以损失反馈的形式对各个体策略施加影响。在执行过程中,难以实时利用全局信息或者由各实体观测信息整合得到融合信息,影响决策性能。
针对该缺点,以分层强化学习为核心的博弈策略生成方法成为研究重点[15]。该思路通过构建顶层控制单元和个体执行单元形成层级支配控制。顶层控制单元汇总个体信息并产生控制信息,控制个体基于部分可观测信息决策。相比于典型多智能体深度强化学习方法,分层强化学习通过任务分配和组合形成整体策略。智能体在训练过程中能够避免智能体策略同时更新,使得单一个体对于体系内其他个体的策略拟合效率更高。文献[16]在通信抗干扰领域中采用了该思想。首先,顶层控制模块识别出当前通信干扰样式,再针对性调用抗干扰样式。但是个体策略的抗干扰样式需要提前人为设计。文献[17]顶层控制单元和个体执行单元均采用神经网络,个体策略也由数据训练得到。上述2 种方法主要解决单一受控个体面对多任务情况下的策略生成问题,针对异构多智能体问题需要对策略生成框架改造。
基于分层强化学习,本文提出改进的多智能体博弈策略生成方法。首先,基于深度神经网络,构造融合观测信息的顶层策略控制模型,完成控制信息的生成。在结构上,具有根据全局信息产生控制信息的能力。在训练过程中,能够引导个体决策模型的生成。然后,将个体的部分观察信息和控制信息映射为个体动作价值。最后,融合个体动作价值形成全局价值,并利用奖赏函数对整个神经网络参数进行优化,达到博弈策略优化的目的。
后续研究思路如下。首先,基于分层强化学习构建观测信息到整体价值的决策映射,以最大化整体价值作为目标构建优化问题,并推导了策略优化过程,为后续框架结构和方法实现的设计提供了理论依据;然后,基于决策映射与优化问题构建,采用神经网络设计了模型框架,详细阐述了顶层策略控制模型和个体策略执行模型;再次,基于策略优化方法,给出详细训练流程和算法流程;最后,采用典型星际争霸多智能体对抗(StarCraft Multi-Agent Chal-lenge,SMAC)环境,与典型多智能体方法进行性能对比,验证方法性能,并总结全文。
1 策略生成原理
博弈对抗策略的实质是完成观测信息到动作空间的影射,影射过程即为策略,而利用该过程得到动作即为决策。基于深度神经网络的策略生成方法中的策略具象化是神经网络结构和网络参数。本文网络结构具体分为策略控制网络和策略执行网络。在网络结构确定的情况下,对网络参数进行优化即对策略优化。基于此理念,本节详细推导策略映射、优化问题构建和策略优化方法。
1. 1 决策映射与优化问题构建
通过全局信息生成控制信息,并以控制信息对各智能体的策略形成过程施加影响,提高各智能体之间的协同能力。对于策略控制网络模型f0 用于完成融合信息o0 到控制信息I 的映射:
I = f0,θ0(o0 ), (1)
式中:I = {In},n∈[1,N]表示拟合得到的控制信息,In 表示对应N 个受控智能体;o0 表示各个智能体整合得到的全局信息,是多维矩阵形式[o1 ,…,on,…,oN],on 表示各智能体的观测空间,即部分可观测空间,n∈[1,N];θ0 表示深度神经策略控制网络参数。
在控制信息的影响下,能够降低智能体对其他智能体策略估计的难度,降低了个体策略生成的难度。对于策略执行网络fn 用于实现控制信息I 和部分可观测空间on 到离散动作价值Qn 的影射。为了协同能力的提升,各个智能体均均等的拿到所有控制信息。
Qn = fn,θn(I,on ), (2)
式中:Qn 表示第n 个智能体离散动作价值的集合{qa1 ,qa2 ,…,qam },θn 表示深度神经策略执行网络参数。θ0 和θn 构成整个模型的网络参数θ。
从Qn 中选择最大值所对应的离散动作am′[18]:
am′ = argmax m Qn , (3)
式中:m∈[1,M],M 为离散动作数量。
1. 2 策略优化方法
面对多智能体策略生成问题,整体价值最大化是策略生成与优化的目标。多智能体整体价值Qtotal 表示各个智能体价值的累加[19]:
Qtotal = ΣNn = 1Qn,am′ , (4)
式中:Qn,am′ 为第n 个智能体对应的最大离散动作价值。
在各智能体动作在博弈环境中与对手策略交互之后,获得的全局奖赏值为r。采用时序差分方法对离散动作价值进行更新:
Qtotal(O,a)← Qtotal(O,a)+ α[r + max a′∈A Qtotal(O′,a′)- Qtotal(O,a)],(5)
式中:α 表示折扣系数,Qtotal(O,a)表示在当前t 时刻观测空间O 和各智能体所选动作对应的整体价值,max a′∈A Qtotal(O′,a′)表示在后续t+1 时刻观测空间O′下各智能体对应的离散动作价值中的最大值求和得到整体价值。
用于网络参数θ 更新的目标损失函数L 定义为:
进行K 次决策后,将每次差值求取平均值得到目标损失函数。通过最小化目标损失函数更新网络参数θ。
2 框架结构
本节给出基于分层强化学习的模型框架,并逐层详细阐述控制模型。
2. 1 基于分层强化学习的模型框架
基于策略生成原理,基于分层强化学习的模型框架如图1 所示。
根据模型框架的结构,其计算过程可以阐述如下:
首先,顶层控制模型产生控制信息。全局信息由个体部分可观察信息组成,顶层策略控制模型基于全局信息产生控制信息,对应式(1)。
然后,个体策略执行模型产生个体动作价值。执行模型依据个体信息给出对应离散动作的动作价值,使得框架可以根据动作价值的最大值选择需要执行的动作,对应式(2)和式(3)。
最后,根据个体动作价值形成整体价值。对执行模型产生的所有个体的最大动作价值进行累加,形成整体价值,对应式(4)。通过对整体价值的迭代优化实现策略优化,对应式(5)和式(6)。
2. 2 顶层策略控制模型
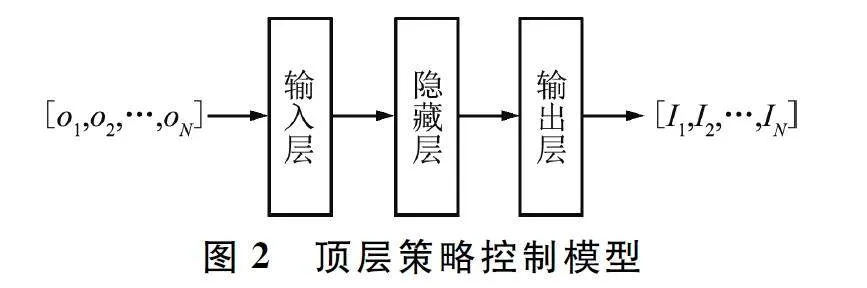
顶层策略控制模型采用深度神经网络,包含输入层、隐藏层和输出层三部分。为了不失一般性并且突出本框架能力,观测信息和离散动作空间结构采用一维矩阵,顶层策略控制模型中各层均采用全连接神经网络,并采用ReLU 作为激活函数。特别需要说明,本文核心在于阐述并验证改进方法的优秀性能,弱化了特征工程,如观测信息为高维数据矩阵等形式,可针对实际工程需求的特异性采用卷积神经网络(Convolutional Neural Network,CNN)、长短期记忆(Long Short Term Memory,LSTM )网络和Transform 等神经网络结构,对本框架进一步改造。顶层策略控制模型如图2 所示。
全局信息由个体观测信息拼接组成,形成一维矩阵。全局信息矩阵维度为N×odim,其中odim 为个体观测信息维度。输入层的维度与全局信息维度一致。隐藏层用于将全局信息映射为原始控制信息。输出层用于将原始控制信息按照控制信息维度要求进行特征提取,用于控制个体策略执行模型。控制信息为一维矩阵,维度为N×Idim,其中Idim 为对应各个体的控制信息维度。
2. 3 个体策略执行模型
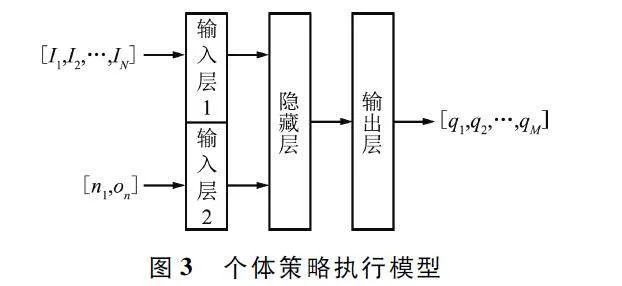
个体策略执行模型的构建逻辑与顶层策略控制模型一致,均采用全连接神经网络,并采用ReLU 作为激活函数,同样包含输入层、隐藏层和输出层三部分。个体策略执行模型如图3 所示。
该模型输入分为两部分,分别是控制信息和融合标志位的个体信息。融合标志位的个体信息由个体标志位n 和部分可观测信息on 构成。加入个体标志位目的是明确区分当前单体,有助于从控制信息中明确自己对应的信息特征。控制信息和个体信息经过输入层后,隐藏层提取输入信息中包含的特征,用于支撑输出层生成对应离散动作的动作价值,维度为M。
3 方法实现
本节基于训练流程和算法流程详细描述了方法实现。
3. 1 训练流程
训练流程采用环形结构,不断迭代优化博弈策略。除了优化过程,还不断对策略性能进行评估,并保存最优参数作为最优博弈策略。具体而言,环形训练流程包括5 个阶段,分别为决策、交互、训练、评估和更新,如图4 所示。
在决策阶段,基于分层强化学习的模型,输入观测信息,得到动作价值,并选择最大动作价值对应的离散动作。
在交互阶段,在博弈环境中,利用得到的离散动作与对手策略进行交互。通过交互获得下一步观测信息和当前奖赏,构建包含当前观测数据、执行动作、当前奖赏和动作执行后得到的下一步观测信息,将上述4 个元素保存为经验,并存储在内存空间中,命名为经验池R。
在训练阶段,随机从经验池中抽取多条经验数据,采用目标损失函数计算损失误差,并且采用累加求和的方法估计误差,使得参数寻优的过程相对稳定。
在评估阶段,将对当前得到的策略参数进行蒙特卡洛测试验证。通过与对手策略进行多轮对抗,得到平均总奖赏。除此之外,如果当前训练得到的策略参数所对应的平均总奖赏优于历史最优参数,可以将当前参数保留,作为最优策略。
在更新阶段,将训练阶段得到的策略参数装载于基于分层强化学习的模型框架,用于在下一次迭代过程中进行决策并与环境进行交互。
3. 2 算法流程
基于训练流程,本文提出了如算法1 所示的基于分层强化学习的多智能体博弈策略生成训练算法。
4 实验结果与分析
实验结果与分析由实验场景、实验过程、参数设置和结果分析四部分组成。
4. 1 实验场景
本文采用OpenAI 和暴雪公司基于“星际争霸2”构造的SMAC 环境中名为“3Z2S”的场景开展实验[20]。SMAC 是一个用于研究多智能体强化学习的环境。这个环境基于即时战略游戏“星际争霸2”提供了一个多智能体竞技场,可以用来评估和比较不同的多智能体强化学习算法。SMAC 环境提供了丰富的地图和任务,涵盖了多种不同的游戏场景和挑战,旨在推动多智能体强化学习技术的发展,并且为研究人员提供一个标准化的评测平台。在“3Z2S”场景中,本文方法与基线策略方法分别控制5 个异构Agent 对抗,在对抗中SMAC 环境将给出对应奖赏值并自动评判是否获胜。
除此之外,本实验在Windows 10 操作系统开展,采用的主要设备为处理器、内存和图像处理器。处理器规格为Intel(R)Core(TM)i710700K,机带内存容量为80 GB,图像处理器为RTX 2070 SUPER。
4. 2 实验过程
本文实验过程与经典多智能体强化学习方法验证实验的过程保持一致[13-14]。
在实验中,共设置了106 步的训练周期,每5 000 步为一个周期,分为训练阶段和评估阶段。在训练阶段,共进行了5 000 步训练,期间进行了神经网络参数的优化更新。每当完成了5 000 步的训练,即进行一次性能评估。在性能评估阶段,与基线策略进行了24 回合的对抗。
在评估指标方面,使用了胜率和平均奖赏。对于胜率,统计了与“3Z2S”场景的基线策略进行对抗获胜的次数,然后除以总回合数24,得到了胜率。而对于平均奖赏,则是累加了24 回合对抗中SMAC给出的奖赏,再除以总回合数24,得到了平均奖赏。
除此之外,在实验过程中,将QMIX 和VDN 方法作为对照组,在“3Z2S”场景中分别计算了它们的胜率和平均奖赏。以验证本方法在性能方面的表现,并与已有的方法进行比较。
4. 3 参数设置
方法参数分为2 类:一类为在策略优化过程的学习参数;另一类为构成模型的深度神经网络参数。学习参数包括奖赏折扣参数、学习率和批量大小,分别设置为0. 99、5×10-4 和32。模型的深度神经网络参数如表1 所示。
4. 4 结果分析
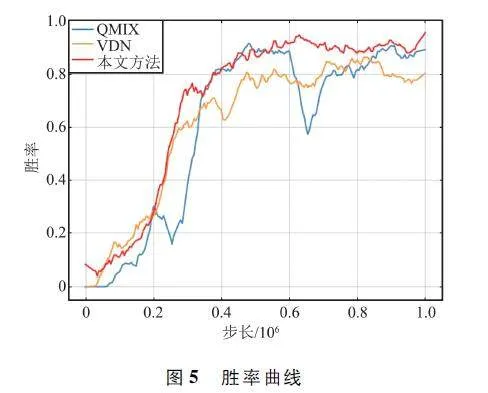
胜率曲线如图5 所示。通过图中对比可以直观发现,在初始阶段,本方法可获得高于QMIX 和VDN 的胜率。二者较慢的原因是由于全局信息间接反馈,并且初始阶段数据量较少,个体策略无法稳定生成,从而其他个体也无法有效通过估计其他个体的策略生成协同策略。除此之外,本文方法相比于2 种典型方法能够更快达到胜率稳态,更高效地形成博弈对抗策略。
平均奖赏曲线如图6 所示。通过图中曲线对比可以看出,平均奖赏曲线图与胜率曲线图的趋势近似,本文方法在效率上明显超过典型方法。
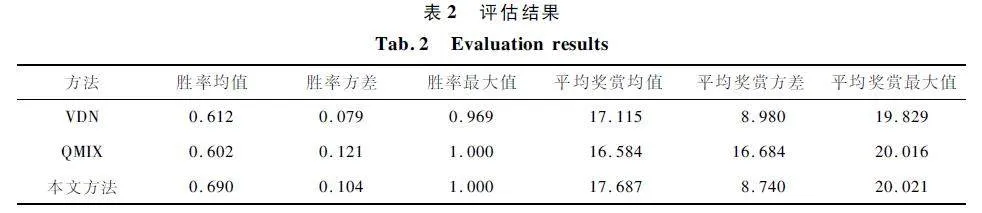
为了客观评估本方法,给出与2 种典型方法的指标评估,指标包括胜率均值、胜率方差、胜率最大值、平均奖赏均值、平均奖赏方差和平均奖赏最大值。评估结果如表2 所示。
对于胜率,本文方法能够获得最大胜率均值。虽然胜率方差低于VDN 方法,但是能够获得最大胜率。对于平均奖赏,对比均值和方差,本文方法的均值最高并且方差最低,充分说明了本文方法的稳定性。除此之外,在胜率和平均奖赏上,本文方法的最大值均为三者之中最高,有效地说明了本文方法的高效性。
5 结束语
针对典型多智能体深度强化学习方法对于全局信息利用不重复导致个体策略生成慢的问题,本文提出了一种基于分层强化学习的多智能体博弈策略生成方法,通过构建顶层策略控制模型,完成全局信息的提取和控制信息的映射,从而实现层次化分解策略。个体策略执行模型在控制信息的引导下,完成部分可观测信息到动作价值函数映射。将典型方法被动优化群体值函数的拟合参数转化为主动将群体策略分解为个体策略,便于快速生成协同策略的目标。实验验证表明,本文所提方法在于基线策略对抗胜率达到100% ,相较典型方法VDN 和QMIX,本文方法胜率最高且方差较低。本文所提方法结构简洁、可解释性强,能够针多受控体有效、高效地生成并优化博弈策略。本方法采用个体离散动作价值相累加的方法估计整体价值。虽然结构简单且计算复杂度低,但是对于各智能体的特性能力缺少较多关注,限制了整体能力。然而,利用超神经网络估计整体价值的计算复杂度高,并且给策略生成效率带来了挑战。在后续研究中,重点应放在从个体价值相整体价值的估计上,给出能够平衡计算复杂度和策略效果的估计方法。
参考文献
[1] FENG S,SUN H W,YAN X T,et al. Dense ReinforcementLearning for Safety Validation of Autonomous Vehicles[J]. Nature,2023,615:620-627.
[2] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Humanlevel Control Through Deep Reinforcement Learning[J].Nature,2015,518:529-533.
[3] VINYALS O,BABUSCHKIN I,CZARNECKI W M,et al.Grandmaster Level in StarCraft II Using Multiagent Reinforcement Learning[J]. Nature,2019,575:350-354.
[4] 畅鑫,李艳斌,赵研,等. 基于MA2IDDPG 算法的异构多无人机协同突防方法[J]. 河北工业科技,2022,39(4):328-334.
[5] CHANG X,LI Y B,ZHAO Y,et al. An Improved Antijamming Method Based on Deep Reinforcement Learningand Feature Engineering [J]. IEEE Access,2022,10:69992-70000.
[6] CHANG X,LI Y B,ZHAO Y,et al. A MultiplejammerDeceptive Jamming Method Based on Particle Swarm Optimization Against Threechannel SAR GMTI [J]. IEEEAccess,2021,9:138385-138393.
[7] MNIH V,KAVUKCUOGLU K,SILVER D,et al. PlayingAtari with Deep Reinforcement Learning [EB / OL ].(2013-12-19)[2024-01-06]. https:∥arxiv. org / abs /1312. 5602.
[8] HASSELT H V,GUEZ A,SILVER D. Deep ReinforcementLearning with Double Qlearning[C]∥Proceedings of theThirtieth AAAI Conference on Artificial Intelligence. Phoenix:AAAI,2016:2094-2100.
[9] SCHAUL T,QUAN J,ANTONOGLOU I,et al. PrioritizedExperience Replay[EB / OL]. (2015 - 11 - 18 )[2024 -01-06]. https:∥arxiv. org / abs / 1511. 05952.
[10] WANG Z Y,SCHAUL T,HESSEL M,et al. DuelingNetwork Architectures for Deep Reinforcement Learning[C]∥ Proceedings of the 33rd International Conferenceon International Conference on Machine Learning. NewYork:JMLR,2016:1995-2003.
[11] LIU X,XU Y H,JIA L L,et al. Antijamming Communications Using Spectrum Waterfall:A Deep ReinforcementLearning Approach [J]. IEEE Communications Letters,2018,22(5):998-1001.
[12] NAPARSTEK O,COHEN K. Deep Multiuser Reinforcement Learning for Distributed Dynamic Spectrum Access[J]. IEEE Transactions on Wireless Communications,2019,18(1):310-323.
[13] RASHID T,SAMVELYAN M,WITT C S D,et al. Monotonic Value Function Factorisation for Deep MultiagentReinforcement Learning[J]. Journal of Machine LearningResearch,2020,21(1):7234-7284.
[14] SON K,KIM D,KANG W J,et al. Learning to Factorizewith Transformation for Cooperative Multiagent Reinforcement Learning [EB / OL]. (2019 - 05 - 14)[2024 -01-06]. http:∥arxiv. org / abs / 1905. 05408.
[15] SHI W S,LI J L,WU H Q,et al. Dronecell TrajectoryPlanning and Resource Allocation for Highly Mobile Networks:A Hierarchical DRL Approach[J]. IEEE Internetof Things Journal,2020,8(12):9800-9813.
[16] LIU S Y,XU Y F,CHEN X Q,et al. Patternaware Intelligent Antijamming Communication:A Sequential DeepReinforcement Learning Approach [J ]. IEEE Access,2019,7:169204-169216.
[17] KULKARNI T D,NARASIMHAN K R,SAEEDI A,et al.Hierarchical Deep Reinforcement Learning:IntegratingTemporal Abstraction and Intrinsic Motivation[C]∥Proceedings of the 30th International Conference on NeuralInformation Processing Systems. Barcelona:Curran Associates Inc. ,2016:3682-3690.
[18] NOCEDAL J,WRIGHT S J. Numerical Optimization[M].New York:Springer,2006.
[19] SUTTON R S,BARTO A G. Reinforcement Learning:AnIntroduction[M]. Cambridge:MIT Press,1998.
[20] SAMVELYAN M,RASHID T,WITT C S D,et al. TheStarCraft Multiagent Challenge. [EB / OL]. (2019 - 02 -11)[2024-01-06]. http:∥arxiv. org / abs / 1902. 04043.
作者简介
畅 鑫 男,(1990—),博士,高级工程师。
刘东辉 女,(1990—),博士,讲师。主要研究方向:复杂系统管理、策略优化等。
基金项目:中国博士后科学基金(2021M693002);国家自然科学基金(71991485,71991481,71991480)
