基于静态博弈和遗传算法的多智能体博弈策略生成方法
2024-09-19刘东辉郑赢营畅鑫李艳斌

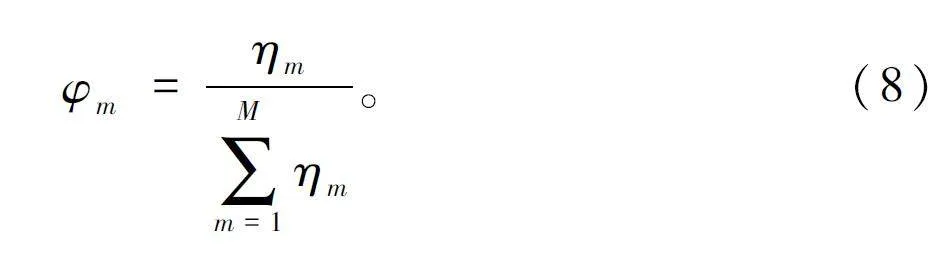
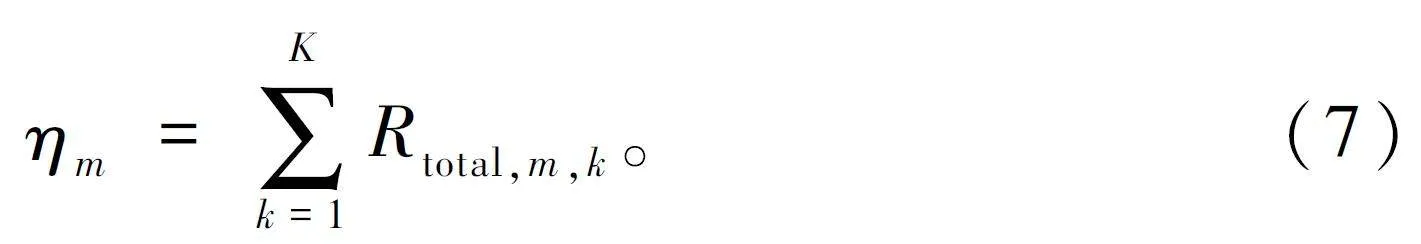

摘 要:在多智能体协同对抗策略生成的过程中,奖励稀疏和神经网络参数多易导致策略生成速度慢。针对特定场景如何快速产生对抗策略这一问题,提出了一种基于静态博弈和遗传算法的多智能体博弈策略生成方法。基于静态博弈理念,对马尔科夫决策过程演化,将策略映射为一串动作组成,简化策略映射原理;对策略优化问题数学建模。以对抗结果作为目标函数,基于动作集合优化目标函数,通过优化的方法能够获得对抗结果最优的策略;给出策略优化框架,并改进遗传算法实现对于多智能体博弈策略的快速并行寻优。实验结果表明,相比于经典多智能体强化学习方法,所提方法能够高效产生多智能体博弈策略。
关键词:静态博弈;遗传算法;策略生成
中图分类号:TN929. 5 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)06-1355-06
0 引言
随着人工智能技术的发展,近年来在各控制领域不断取得亮眼表现,如人机博弈[1]、无人驾驶[2]和智慧医疗[3-4]等。特别是对于多智能体协同管控的现实客观需求,使得智能策略生成和优化技术快速发展,多智能体博弈策略生成方法成为当前的研究热点。
在实践过程中,面临的典型问题为:对手策略或者环境较为固定的情况下,如何快速生成对抗策略。传统方法采用强化学习方法通过估计当前状态的状态转移过程和动作分布从而估计出得到最大值奖赏值的策略[5-10],如深度Q 网络(Deep Qnetwork,DQN)、Soft ActorCritic (SAC)。但是,随着实体个数的增加导致部分可观测信息和状态信息的维度增加,神经网络维度增加,进一步引起神经元参数收敛困难,从而导致神经网络难训练引起策略生成和优化失败。多智能深度强化学习方法被提出用以解决该问题,具有代表性的方法是QMIX[11]和Qtran[12]等。除此之外,强化学习需要动作具有良好的反馈,但是在工程落地过程中,存在中间态指标多维度高难以最终结果作为目标进行拟合,从而引起在强化学习领域中较难处理的“回报稀疏”问题[13-14],但是从对抗结果衡量策略效果较易实现。如在文献[15]中,任务是否成功可以直接通过判断无人机是否达到指定位置,但是仅依靠终局结果很难对深度神经网络进行训练,所以基于课程学习思路引入了迁移性评估指标对奖赏空间在数学表征上进行稠密化[16]。但是该方法并不通用,原因在于需要对领域知识的深刻理解形成专家知识牵引智能模型进行训练。故针对特定策略产生对抗策略的关键问题在于如何在稀疏奖赏的引导下生成对抗策略。文献[17]在雷达探测策略假定的情况下,梳理出智能干扰设备可调整的干扰参数。基于任务目标构建目标函数和约束函数,采用元启发算法对参数进行优化,从而产生最优对抗策略。该方法对博弈过程采用静态建模,在整个过程中,雷达在特定模式下初始参数和行为模型固定,所以干扰参数数值求解,并形成静态对抗策略。但是,在动态博弈过程中,需要通过动作组成策略。策略内的动作间会变化,需要针对动态场景进行改进[18]。
针对该不足,基于静态博弈理论[19],提出面向动态场景的多智能体博弈策略生成方法。对马尔科夫决策过程演化,将策略映射为一串动作组成,简化策略映射原理。将策略优化问题转化为数学寻优问题。以对抗结果作为目标函数,基于动作集合优化目标函数,获得对抗结果最优的策略。除此之外,构建并行优化框架,改进遗传算法实现对于多智能体博弈策略的快速并行寻优[20]。实验结果表明,相比于经典多智能体强化学习方法,本方法能够高效产生多智能体博弈策略。
本文余下内容结构组织如下:第1 节详细推导并阐述基于静态博弈理论的策略优化模型,为后续第2 节提出的方法奠定了基础,并在第3 节通过实验验证本方法的有效性,最后总结全文。
1 基于静态博弈理论的策略优化模型
基于博弈论,策略π 是由一系列动作a 构成的。
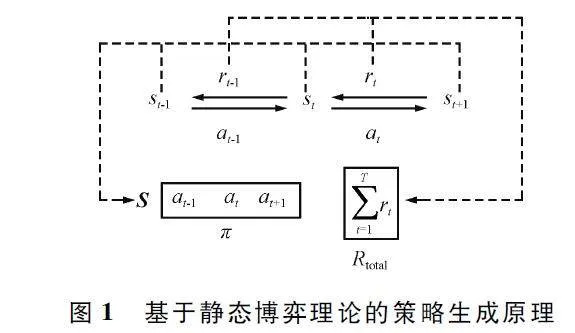
马尔科夫决策过程的本质也是在数学上寻找到由状态st 到at 的映射过程,其中st ∈S,S 为状态空间;at∈A,A 为动作空间。在针对特定策略这一假设前提下,对手策略的状态动作映射较为固定。对手策略的状态动作映射可以弱化为策略标签,用于区分不同对手策略。进一步,可以弱化对于对手状态st 的特征提取过程,使策略π 直接施加于对手策略上,通过对抗结果进行反馈。上述演进过程如图1 所示。
从最优化角度分析可知,对手策略和博弈环境可以固定为博弈函数f,策略博弈产生结果的过程可以表述为:
Rtotal = f(π), (1)
式中:Rtotal 为总奖赏。
Rtotal = ΣTt = 1rt。(2)
在典型对抗环境中,中间奖赏较难获得,需要通过奖赏塑形等大量的专业领域才能构成,所以最直观为采用最终结果作为奖赏:
Rtotal = rT 。(3)
最优策略即为使得博弈函数最大的策略,即优化目标为:
π* = argmax π f(π), (4)
式中:π 为由一系列动作构成的策略,π 为所有可能的动作组合成的策略集合,π 为最优策略。
该模型的优势在于能够有效地解决奖赏稀疏的问题。在智能决策应用场景中,通过结果设计奖赏函数较为容易,如将目标击毁个数转化为奖赏分值[15]。但是,在博弈过程中,通过结果设计奖赏会使得大部分时间没有奖赏值,无法预测奖赏值出现时间,无法准确评估动作的有效性,指引策略的收敛方向。而采用领域知识可以使得奖赏稠密,如将智能体与目标之间的距离或者将抗干扰跳频时选择的信道间隔转化为奖赏值[15,18],有助于策略加速收敛。但是,需要领域专家根据场景需求设计,容易引入主观因素导致收敛在局部最优策略。所以,针对上述矛盾,依据静态博弈理论,在奖赏稀疏的假设前提条件下,将马尔科夫决策过程演化为静态优化问题,明确目标函数,将策略优化问题完全数学化表征,使得策略可以通过数学优化方法进行求解,规避了马尔科夫决策过程在奖赏稀疏条件下策略生成困难的弊端。
2 基于遗传算法的策略生成方法
得益于在理论层面将动态博弈问题简化为了优化问题,使得采用遗传算法能够快速找出博弈过程中的最优动作排序,并将其映射为策略,从而实现针对特定策略的快速生成。但是,对于遗传算法而言,其计算量大且耗时的部分在于需要计算种群中每个个体的适应度,故提出并行优化框架对方法进行加速。后续本节分为两部分,详细阐述基于遗传算法的策略生成方法,分别为并行求解框架和优化方法。
2. 1 并行优化框架
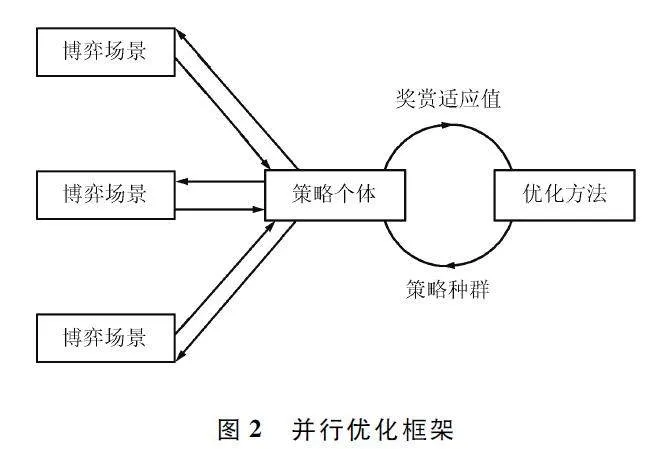
并行优化框架如图2 所示。整个并行优化过程阐述如下:首先,构建由一系列动作作为基因组成策略个体,再将多个策略个体组成策略种群。在该阶段,需要根据对抗时长和受控体的个数相乘得到策略个体中包含的动作基因个数。然后,每一个策略个体在博弈场景中与对手策略对抗,将奖赏作为每个策略个体的适应值返回。在此过程中,利用并行进行多个策略个体的对抗,能够快速获得。最后,将策略种群和个体依次对应的奖赏适应值传入优化方法。优化方法过滤并生成新的策略种群,并进入下一次策略优化环路。由基于静态博弈理论的策略生成数学优化模型一节的数学分析过程可以看出,作为核心理论,其在实施层面具有良好的并行化能力,从而使得并行化框架的构建成为可能,并将结合硬件算力大幅度提升策略优化的性能。
2. 2 优化方法
在优化过程中,需要完成策略的数学化表达。假设在多智能体对抗环境中,智能体个数为N,在博弈期间需要执行动作次数为T,每次执行离散动作。故策略个体π 由N×T 个动作基因组成,即:
π = [a1 ,a2 ,…,aT ]NT 。(5)
当策略种群由M 个策略个体组成时,策略种群π 可以表示为:
π = [π1 ,π2 ,…,πM ]M ×NT 。(6)
构建多个线程L,线程之间相互独立。针对不同策略个体的开展K 次博弈对抗,得到与个体相对应的奖赏适应值:
当所有策略个体对应的奖赏适应值计算运行完成后,按照奖赏适应度由高到低,对策略种群π 中的策略个体π 排序。
根据策略种群π 奖赏适应值进行个体奖赏适应值的归一化,对于第m 个策略个体π,其种群选择概率为:
根据个体策略的奖赏适应值对种群进行过滤,保留指定数量M′个奖赏适应值排名靠前的策略个体。除此之外,在剩余策略个体中,随机抽取2 个策略个体进行拼接形成新策略个体并放回种群中,该过程可以通过数学表达为:
π′1 = [π1 [1:t′],π2 [t′ + 1:T]], (9)
π′2 = [π2 [1:t′],π1 [t′ + 1:T]], (10)
式中:π1 和 π2 为随机抽取出的策略个体,π1′和 π2′为拼接后的策略个体,t′为随机生成的拼接位置,t′∈NT,随机概率门限为ε1 。
为了进一步提高策略种群的搜索能力,对种群中的个体进行动作基因突变操作。遍历新生成策略种群中每个动作基因,以概率门限为ε2 为基础进行随机变异。当超过变异门限时,从可选动作范围内随机选择一个离散动作进行替换。
经过上述过程的迭代,最终即可获得最优策略个体和其对应的最优奖赏适应值。
3 实验验证
实验验证由实验场景、实验设计、参数设置和结果分析四部分组成。
3. 1 实验场景
为了能够有效验证本方法的有效性,采用DeepMind 和暴雪公司开发的基于“星际争霸2”的多智能体对抗环境(StarCraft MultiAgent Challenge,SMAC)进行实验[21]。SMAC 内置基线对抗策略,用于验证策略效果。除此之外,由于典型用于多智能体策略对抗的深度强化学习需要对应场景进行超参数调整,该典型场景公认性较高,故均基于此环境进行开发和调试,其对照算法的超参数可以直接获得。采用SMAC 环境中名称为“3m”的多智能体同构场景进行验证。
3. 2 实验设计
实验过程共设置步长为106 ,分为训练阶段和评估阶段,以5 000 步为周期循环。在训练阶段,设置种群训练门限为5 000 步。在该阶段内,对种群内个体进行适应度并行计算和交叉变异。当每种群运行步数超过5 000 步进行一次性能评估。在性能评估阶段,与基线策略对抗24 回合。衡量对抗策略的有效性,最根本在于评估胜率,故在实验中用胜率作为评估指标。对于胜率而言,计算24 回合内与“3m”场景的基线策略对抗获胜的次数,再除以总回合数得到胜率。除此之外,在实验过程中,将QMIX和ValueDecomposition Networks (VDN )方法在“3m”场景中的胜率和平均奖赏作为对照组,验证本方法的性能。除此之外,VDN 和QMIX 方法分别使用以结果作为奖赏的非奖赏塑形和SMAC 环境提供的奖赏塑形。在判断胜负的基础上,SMAC 环境提供的塑形奖赏通过受控体之间的位置关系和生命值等特征构建了奖赏函数。通过设置对照实验,用于展示奖赏稀疏对于典型算法的影响,突出该问题解决的必要性,并验证了本方法在解决该问题上的有效性。
3. 3 参数设置
本文实验所用到的算法参数如下表1 所示。
3. 4 结果分析
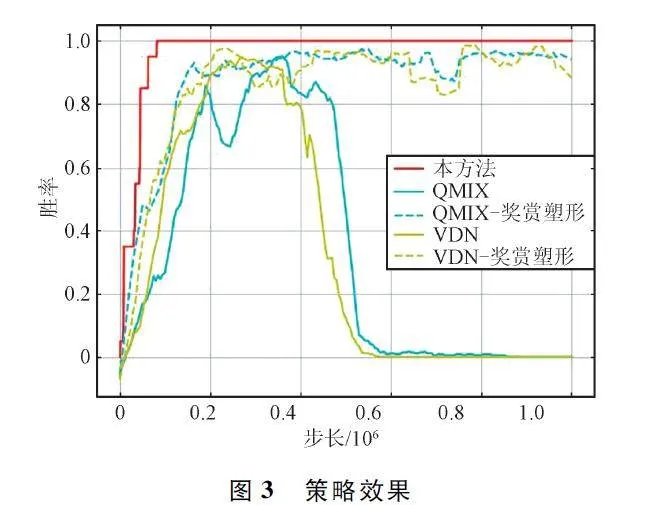
策略效果如图3 所示,展示了本方法、VDN 和QMIX 随训练步长增加的胜率变化趋势。在图3中,“VDN-奖赏塑形”和“QMIX-奖赏塑形”表示采用SMAC 提供的奖赏塑形进行训练得到的博弈策略,而VDN 和QMIX 表示仅通过胜负关系构建奖赏得到的博弈策略。从对比采用奖赏塑形和非奖赏塑形的2 种方法可以看出,采用奖赏塑形的方法胜率提升趋势较为稳定,而采用非奖赏塑形的由于奖赏反馈稀疏,在实验初期胜率提升较慢,且在实验中后期出现明显的胜率衰退现象。虽然通过保存最大胜率对应的神经网络参数的方法使其不至于出现严重衰退,但是胜率无法与塑形奖赏相比。相比之下,虽然本文方法、“VDN -奖赏塑形”和“QMIX -奖赏塑形”都能够达到最大胜率,但是本文方法速度快且稳定,且能够有效避免由于奖赏稀疏导致的性能衰退。
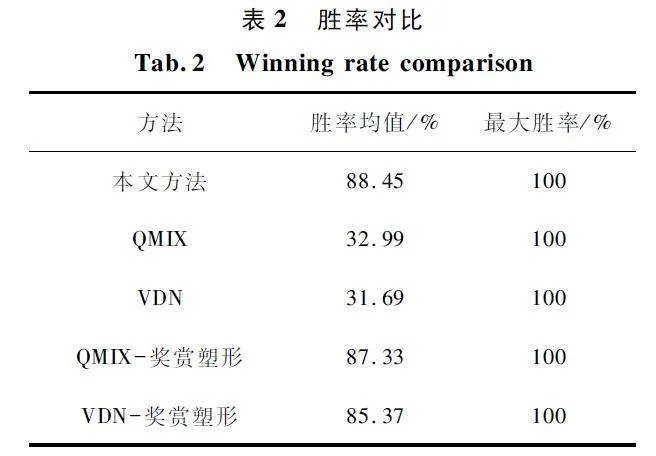
为了进一步量化对比方法性能,对5 种方法的胜率求取均值和最大值,如表2 所示。5 种方法均能够达到最大胜率,但是通过胜率均值可以发现,本文方法相比于其他方法的胜率均值最大,表明本文方法相对稳定。
综合图3 和表2 的胜率趋势和量化胜率,可见本文方法在针对特定对手策略时,在奖赏稀疏的情况下,能够快速且稳定地生成对抗策略。
4 结束语
针对特定策略如何快速产生对抗策略这一问题,结合博弈论中的静态博弈理论和遗传算法,提出了一种改进的多智能体博弈策略生成方法。在理论层面,基于静态博弈理念,对马尔科夫决策过程演化,将策略映射为一串动作组成,简化策略映射原理。在理论基础上,对策略优化问题数学建模。以对抗结果作为目标函数,基于动作集合优化目标函数,通过优化的方法能够获得对抗结果最优的策略。在实现层面,设计策略优化框架,并改进遗传算法实现对于多智能体博弈策略的快速并行寻优。在实验中,将典型多智能体强化学习方法作为基线,通过与基线方法对比,表明了本方法产生策略的高效性,并且展现了本文方法基于并行方法能够有效提高策略生成与优化速度。
参考文献
[1] MNIH V,KAVUKCUOGLU K,SILVER D,et al. HumanLevel Control through Deep Reinforcement Learning[J].Nature,2015,518:529-533.
[2] FENG S,SUN H W,YAN X T,et al. Dense ReinforcementLearning for Safety Validation of Autonomous Vehicles[J]. Nature,2023,615:620-627.
[3] ZHU Y,LIANG X F,WANG T T,et al. MultiinformationFusion Fault Diagnosis of Bogie Bearing under Small Samples via Unsupervised Representation Alignment Deep Qlearning [J]. IEEE Transactions on Instrumentation andMeasurement,2022,72:3503315.
[4] ZHU M X,ZHU H G. Learning a Diagnostic Strategy onMedical Data with Deep Reinforcement Learning [J ].IEEE Access,2021,9:84122-84133.
[5] MNIH V,KAVUKCUOGLU K,SILVER D,et al. PlayingAtari with Deep ReinforcementLearning [EB / OL ].(2013-12-19)[2024-03-06]. https:∥arxiv. org / abs /1312. 5602.
[6] HASSELT H V,GUEZ A,SILVER D. Deep ReinforcementLearning with Double Qlearning [C]∥ Proceding of theThirtieth AAAI Conference on Artifical Intelligence. Phoenix:AAAI Press,2016:2094-2100.
[7] SCHAUL T,QUAN J,ANTONOGLOU I,et al. PrioritizedExperience Replay[EB / OL]. (2015 - 11 - 18 )[2024 -03-06]. https:∥arxiv. org / abs / 1511. 05952.
[8] HAARNOJA T,ZHOU A,ABBEEl P,et al. Soft Actorcritic:Offpolicy Maximum Entropy Deep ReinforcementLearning with a Stochastic Actor[EB / OL]. (2018 - 01 -04)[2024-03-06]. https:∥arXiv:1801. 01290v2.
[9] HAARNOJA T,ZHOU A,HARTIKAINEN K,et al. SoftActorcritic Algorithms and Applications[EB/ OL]. (2018-12-13)[2023-09-06]. https:∥ arXiv:1707. 06347v2.
[10] WANG Z Y,SCHAUL T,HESSEL M,et al. Dueling NetworkArchitectures for Deep Reinforcement Learning [C]∥Proceeding of the 33rd International Conference on MachineLearning. New York:JMLR. org,2016:1995-2003.
[11]RASHID T,SAMVELYAN M,WITT C S D,et al. MonotonicValue Function Factorisation for Deep Multiagent Reinforcement Learning [J]. Journal of Machine Learning Research,2020,21(1):7234-7284.
[12]SON K,KIM D,KANG W J,et al. QTRAN:Learning to Factorize with Transformation for Cooperative Multiagent Reinforcement Learning [EB/ OL]. (2019 -05 -14)[2024 -03 -06]. http:∥arXiv. org/ abs/ 1905. 05408.
[13]WANG X,CHEN Y D,ZHU W W. A Survey on CurriculumLearning [J]. IEEE Transactions on Pattern Analysis andMachine Intelligence,2022,44(9):4555-4576.
[14] OKUDO T,YAMADA S. Learning Potential in Subgoalbased Reward Shaping [J ]. IEEE Access,2023,11:17116-17137.
[15] 畅鑫,李艳斌,赵研,等. 基于MA2IDDPG 算法的异构多无人机协同突防方法[J]. 河北工业科技,2022,39(4):328-334.
[16] YIN H,GUO S X,LI A,et al. A Deep ReinforcementLearningbased Decentralized Hierarchical Motion ControlStrategy for Multiple Amphibious Spherical Robot Systemswith Tilting Thrusters [J]. IEEE Sensors Journal,2024,24(1):769-779.
[17] CHANG X,LI Y B,ZHAO Y,et al. A MultiplejammerDeceptive Jamming Method Based on Particle Swarm Optimization against Threechannel SAR GMTI [J]. IEEEAccess,2021,9:138385-138393.
[18] LIU S Y,XU Y F,CHEN X Q,et al. Patternaware Intelligent Antijamming Communication:A Sequential DeepReinforcement Learning Approach [J ]. IEEE Access,2019,7:169204-169216.
[19] 阿维亚德·海菲兹. 博弈论[M]. 刘勇,译. 上海:上海人民出版社,2015.
[20] ENGELBRECHTA P. Computational Intelligence:An Introduction[M]. New Jersey:Wiley,2007.
[21] SAMVELYAN M,RASHID T,WITT C S D,et al. TheStarCraft Multiagent Challenge[C]∥ Proceedings of the18th International Conference on Autonomous Agents andMulti Agent Systems. Montreal:International Foundutionfor Autonomous Agents and Multiagent Systems,2019:2186-2188.
作者简介
刘东辉 女,(1990—),博士,讲师。主要研究方向:复杂系统管理、策略优化等。
郑赢营 女,(1998—),硕士研究生。主要研究方向:复杂系统管理。
畅 鑫 男,(1990—),博士,高级工程师。
基金项目:国家自然科学基金(71991485,71991481,71991480);中国博士后科学基金(2021M693002)
