基于R语言的陶瓷样本化学成分数据可视化分析
2024-09-13吕珍宋国柱李凡何婷婷




摘要:随着大数据时代不断发展,数据中蕴藏着丰富的知识,且其价值日益提升。为了更好地认识数据规律,通过从UCI数据库中选取陶瓷样本化学成分数据集,基于开源的R语言对该数据集进行了预处理,然后使用不同的功能函数进行可视化与分析,经过实验探索在一定程度上反映了陶瓷样本数据中化学成分的规律。
关键词:R语言;数据分析;陶瓷样本化学成分;可视化分析;UCI
中图分类号:TP312 文献标识码:A
文章编号:1009-3044(2024)22-0067-03
开放科学(资源服务)标识码(OSID)
0 引言
以大数据为核心的时代,数据在社会中扮演着重要资产的角色并发挥着可观的作用,其种类来源日趋丰富。因此,如何从数据中准确挖掘信息并提取价值,继而赋能科技生产,促进社会经济向前发展成为当今时代的主题。
R是一种开源的编程语言(https://cloud.r-project.org) ,其具备强大的数据分析与统计功能,并能产生优越的作图效果。第一届中国R大会于2008年在中国人民大学召开,至今已成功延续至16届。与此同时,R语言已愈发受到人们的广泛关注,应用于农业、医学、教育、材料等领域的各项分析任务中。余等人[1]从教学改革的角度出发,利用R语言进行了课程探索。唐等人[2]从课程创新的角度出发,利用R语言针对医学类信息专业教学进行了探索研究。杨等人[3]从防灾应用的角度出发,利用R语言对地震数据进行了可视化以对防震工作和防震规律的认识形成参考。本文选取了UCI数据库中的陶瓷样本化学成分数据,基于R语言对其进行了预处理与可视化过程,旨在通过分析获得数据集内隐含的知识。
针对数据集的分析过程分为数据采集、数据预处理、数据可视化与分析三个步骤,均在以下实验环境中进行:R版本为4.3.3(64位),Rstudio版本为2023.06.1.0(64位),硬件操作系统为Windows11,处理器参数为11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40 GHz。
1 数据采集
UCI数据库[5]是机器学习领域中一个不可或缺的数据源,其由世界各地的研究人员捐赠数据集并保持更新,该库中的数据集涵盖范围广泛,数据格式标准且种类繁多,适用于聚类、分类、回归等多种场景。本文从UCI数据库中将数据集Chemical Composition of Ceramic Samples[4]下载至本地,并采用read.table函数将其导入Rstudio集成开发环境中。
在UCI数据库中对Chemical Composition of Ceramic Samples即陶瓷样品的化学成分数据集的描述如下:
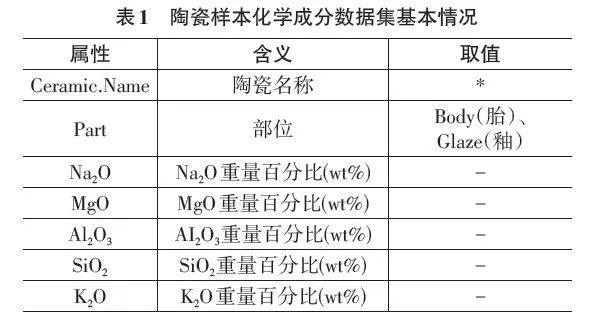
该数据源于采用了能量色散X射线荧光测定了龙泉窑(大瑶县)和景德镇窑青瓷胎体和釉料的化学成分,选取了一些典型碎片,对其原材料和烧制工艺进行了研究。该数据集中各个属性名称、含义及其取值情况如表1所示。
2 数据预处理
由于相关研究人员在将本数据集上传至UCI网站之前经过了前期处理,因此在本文的数据预处理步骤中,仅使用is.na函数对数据集中的缺失值进行查询,并结合summary函数对数据集中各个变量进行初步了解与分析,如变量个数、变量最大最小值、均值等,以便进一步提高数据质量,进行后续的数据分析与可视化步骤。
在数据集中非数值型变量有两个,分别是Ceramic.Name和Part。为了便于后续可视化与分析,根据各自取值情况和含义的不同分别对这两个变量进行了转换,并将Ceramic.Name列的位置由第一列调整至最后一列。
由于Part的取值包含两种(Body、Glaze) ,这里使用R语言中的as.numeric函数对其进行了编码处理,将因子型变量转换为数值型变量。(转换规则:数值1代表字符Body,2代表字符Glaze) 。
变量Ceramic.Name的取值为字符串型,需对其进行规约化。首先通过R语言中的grepl函数进行字符串匹配,然后结合as.numeric函数对其进行了编码处理,将字符串型变量转换为数值型变量。通过分析得知,该变量下每个字符串中第一子串的取值为二元情况,即“FLQ”与“DY”,因此将该变量下的两类字符型值全部转换为二元数值1和2。以字符串“FLQ-1-b”为例,对其转化后用数值1表示。这里将第一个子串“FLQ”视作瓷器种类,将中间数字字串“1”视作为该种类下的实例序号,将最后字串“g”视作部位标识釉(Glaze的首字母)。本文按照上述规则对Ceramic.Name变量下的取值进行转换后的结果如表2所示。
3 数据可视化与分析
3.1 pairs函数分析
首先确保R中导入graphics包,便可使用包中的pairs函数绘制矩阵图形,以同时涵盖数据集中的所有变量,针对变量两两之间的关系形成整体描述。对陶瓷样本化学成分数据集经过上述预处理完成后,得到的可视化分析结果如图1和图2所示。
如图1所示为去掉标签列Ceramic.Name后的可视化结果,对角线位置依序为陶瓷样本的化学成分数据集中各个特征的名称。例如,第一行的第一个图形为本数据集第一个变量Part,第一行的第二个图形显示了第一个变量Part和第二个变量Na2O重量百分比之间的关系,而第二行中对角线位置的右侧第一个图形显示了Na2O重量百分比和第三个变量MgO重量百分比之间的关系。图2所示为保留标签列Ceramic.Name后的可视化结果,可以看到右下角比图1多一个对角线位置即标签列。
3.2 PCA函数分析
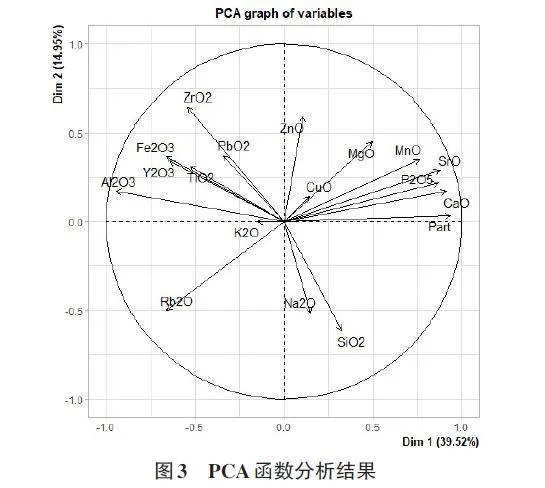
PCA是统计学中常用的分析技术,其通过降维的思想,结合计算特征值等数学量作用于数据集中的主成分分析。为了便于可视化分析,这里将陶瓷样本数据集作为分类集对待,首先删除了标签列即Ceramic.Name,其次需确保R中导入ggplot2、factoextra、FactoMineR包,便可使用包中的PCA函数一步到位绘制主成分分析图,预处理完成后的数据集可视化分析结果如图3所示。
由图3可知,经PCA函数分析后可视化为一个半径为1的圆,横纵坐标轴1.0刻度处的Dim1和Dim2分别表示经PCA函数分析后确定的两个主成分,贡献百分比分别为39.52%和14.95%。圆内各个箭头标识了不同的特征,在同一空间内反映了陶瓷样本数据集中主成分与各个特征之间的关系。另外,特征之间的夹角不同,例如,ZnO与MgO之间较为靠近且夹角为锐角,表示两者之间为正相关关系;而Al2O3与MgO之间较为疏远且夹角为钝角,表示两者之间为负相关关系。
为了进一步探索不同种类陶瓷样本与化学成分的规律,使用get_eigenvalue函数查看PCA分析后的统计量,包括各个主成分的eigenvalue(特征值)、variance.percent(贡献百分比)、cumulative.variance.percent(累积贡献百分比),并根据每个主成分的贡献百分比使用fviz_eig函数绘制柱形图,当贡献百分比降低的趋势基本稳定并达到初期设定的阈值时,可得出数据集中的主成分各项及数目,柱形图分析结果如图4所示。
根据图4可知,在本数据集中,各项的贡献百分比在x坐标轴上从左至右呈现下降现象。例如,第一维特征贡献百分比为39.5%,第二维特征贡献百分比为15%,二者下降梯度较大;第三维特征贡献百分比为8.4%,第二、三维特征间下降梯度较上一间隔要小,此后依次各维特征贡献百分比与相邻特征间下降梯度的数值不断减小且渐趋平稳,因此可选取纵坐标数值较大所对应的特征作为此数据集的主成分,例如前三个特征。
4 结论
本文选取UCI数据源中的陶瓷样本化学成分数据集作为分析对象,基于R语言对该数据集进行了预处理,在此基础上使用不同的功能函数进行了数据可视化与分析操作,旨在对陶瓷样本数据中化学成分的规律进行探索,对后续该数据集及相关领域的分析具有一定的参考意义。
参考文献:
[1] 余卓芮,孙怡恒,刘钰,等.基于开源R语言建模的空间分析教学改革研究[J].电脑知识与技术,2024,20(1):10-13.
[2] 唐丹丹,张志豪,田翔华.基于R语言的医学院生物信息学课程教学探新[J].电脑知识与技术,2023,19(19):133-135.
[3] 杨丽佳,陈新房,汪世伟.基于R语言与BDP的地震数据可视化[J].科学技术创新,2024(2):139-142.
[4] UCI Machine Learning Repository. Chemical Composition of Ceramic Samples[DB/OL]. https://doi.org/10.24432/C54P5X, 2019.
【通联编辑:王 力】
