局部特征互补的遮挡行人重识别研究
2024-09-13张孟思



摘要:本研究致力于解决行人重识别领域面临的挑战,特别是由于遮挡等问题导致的识别难题。现有方法通常在整体图像上进行处理,容易忽略被遮挡的细节信息,从而可能导致错误的识别结果。为了应对这一问题,本研究提出了一种局部特征互补的遮挡行人重识别方法。该方法通过对局部特征提取、学习以及特征间互补,有效地减轻了背景干扰和遮挡对行人重识别准确性的负面影响。研究结果表明,该方法在提高行人重识别准确性方面表现出明显的优势,为解决遮挡问题提供了新的思路,具有重要的实际意义和应用前景。
关键词:行人重识别;计算机视觉;遮挡;局部特征;特征互补
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)22-0007-04
开放科学(资源服务)标识码(OSID)
0 引言
公共安全问题已成为社会高度关注的焦点,对于国家繁荣和社会和谐至关重要。在城市中,电子监控设备的广泛应用使行人重识别成为监控和安防领域的主要任务。行人重识别在智能安防、智能寻人系统和智能分类系统等领域中发挥着重要作用,能够快速定位犯罪嫌疑人、协助寻找走失人员,并对照片进行分类和聚类。在计算机视觉领域中,行人识别扮演着关键的角色。然而,行人重识别任务面临着遮挡带来的挑战。遮挡导致查询集图像和候选集图像同时被障碍物遮挡,增加了特征提取的难度,降低了识别的准确性。尽管针对单一摄像头捕获的行人图像进行分析已相对成熟,但随着监控力度增强、摄像头数目增加以及拍摄环境的复杂多变,单一摄像头下的分析处理已不再足够,迫切需要关注多个摄像头下捕获同一行人的多张图像。多摄像头下的行人图像提供了更丰富的信息,但也面临着摄像头视角、分辨率变化等挑战,增加了行人重识别任务的复杂性。为了更好地应对遮挡的行人重识别问题,本文提出了一种局部特征互补的行人重识别方法,解决多公共摄像头下遮挡行人识别问题,提取跨摄像头共享特征,为公共安全和社会稳定做出积极贡献。
1 相关工作
近年来,为了有效克服行人重识别过程中遮挡干扰带来的挑战,业界涌现出一系列杰出的研究成果。这些研究不仅专注于算法的优化和改进,还致力于创新技术的开发和应用,以期在提高识别精度和速度方面取得突破。目前,现有的遮挡行人重识别方法主要侧重特征提取和对齐[1-2]。这些方法在一定程度上提高了识别准确性,但仍面临一些挑战。例如,特征融合可能会引入噪声或干扰信息,从而影响最终的识别结果;局部特征匹配可能会受到遮挡部分的影响,导致提取的特征不够完整或准确;缺乏对特征间复杂关系的建模,限制了在处理遮挡情况下的识别能力。为了克服这些挑战,一些研究者开始探索基于深度学习的方法来提高遮挡行人重识别的效果,并在大规模数据集上进行端到端的训练,从而可以更好地捕捉特征之间的复杂关系。一些最新的研究工作表明,基于深度学习[3-4]的方法在处理遮挡情况下能够取得更好的识别效果,甚至超过传统方法的表现。除了深度学习技术,一些研究者还尝试结合多模态信息来提高遮挡行人重识别的性能。通过融合不同传感器或模态的信息[5-6],可以更全面地捕捉行人的特征,从而提高识别的准确性和鲁棒性。
2 本文方法
2.1 特征提取
为了提升行人重识别的性能,更好地识别和区分不同的行人,本文提出了基于姿态估计的局部特征提取方法。该方法通过提取姿态特征、识别遮挡区域以及保持姿态信息相似性,从而提高准确性和鲁棒性。通过提取人体关键点的位置信息获取局部特征,以识别遮挡区域。由于姿态信息在不同角度下具有相似性,有助于使模型聚焦于未被遮挡的显著区域,突出人体部位的局部显著特征。采用姿态引导的方法,联合学习局部特征以探索更具区分性的特征,使模型更专注于行人的姿态信息,从而更好地区分不同行人的特征差异。通过学习局部特征的注意力权重,模型能更准确地捕捉关键的局部特征信息,进而提高行人重识别的准确性。这种方法即使在遇到遮挡情况下仍能构建出有效的特征表示,确保模型能在复杂环境下准确识别行人,为行人重识别领域带来新的思路和方法。
具体而言,在给定一个行人图像x1的情况下,首先使用ResNet50作为卷积神经网络(CNN) 的主干网络,并在删除全局平均池化层和全连接层后得到特征映射mcnn。随后,利用姿态估计模型获取行人的14个关键姿态点,生成去除遮挡的关键点热度图mkp和关键点置信度分数βk。在这里,热度图的值代表关键点位置的二维高斯分布,最大值为关键点的坐标,而置信度分数表示关键点的可见程度。因此,最终为输入图像生成14张h×w热度图和14个关键点置信度分数,如图1所示。
通过对原始输入得到的特征映射与关键点热度图进行乘法操作(U)和求和操作,可以得到特征提取阶段关键点的单一信息特征Fl。其中,mkp经过Normalization和Softmax函数处理,旨在减少噪声干扰和错误值的影响。通过对特征映射执行全局最大池化操作,可以得到包含整体信息的全局特征Fg,具体公式如下所示:
[Fl=fk14k=1=SUMmcnn⊗mkp] (1)
[Fg=fk+1=Fmax] (2)
损失函数LE涉及目标人图像的真实标签,用于学习人的表现,分别使用Lcls表示分类损失,Ltri表示三元组损失,k表示关键点特征,取值从1到15。βk表示第k个关键点特征的置信度,若k=15表示全局特征的置信度,即βk=1。具体公式如下所示:
[LE=1kβkLclsfk+Ltrifk] (3)
2.2 特征学习
姿态估计用于获取局部特征信息,然而由于遮挡干扰,不可避免地会引入一些无意义甚至噪声信息,从而降低行人重识别的准确性[7]。在某些情况下,不同摄像头下的不同图像,由于行人姿态和遮挡区域的相似性,使得人体姿态信息无法完全有效地区分行人身份。为了有效利用关键点信息,本文采用人体关键点的结构,将人体姿态信息和全局对比信息共同构建出行人的局部特征和全局特征表示。
引入基于人体关键点结构的方法用于构建行人的有效局部特征和全局特征表示。在该方法中,每个姿态点的位置信息被看作节点的独立特征,用于建立节点之间的关系。具体而言,若两个节点之间存在连接,则连接值为1,否则为0。在建立身体各部位关系时,最初节点之间没有连接,随后无论如何学习更新节点关系,节点之间仍保持无连接状态。通过全局特征、局部特征以及人体关键点结构的相互关联,实现节点特征的汇聚和更新。这种方法不仅考虑了单一节点特征信息,还考虑了边的特征信息,节点之间的连接基于姿态点之间的相对位置关系来确定邻近关系R。通过学习和聚合相关节点特征,得到每个身体部位丰富的语义信息特征表示,如图2所示。
本文在保留局部和全局上下文信息的同时对特征进行调整和更新,优化节点特征,使每个节点能更好地学习行人节点的特征信息,监督关系信息,学习更具区分性的特征信息,以提高识别精度。
一个简单的图卷积可以通过将输入的局部特征Fl与特征矩阵R融合,得到最终的输出特征FK。在这个过程中,使用全连接层FC1和FC2,它们之间的权重不共享。具体公式如下所示:
[FK=FC1R⊗Fl+FC2Fl,Fg ] (4)
损失函数([LBCE]) 用于确定提取的特征是否与真实的标签属于同一个人。其中,y表示真实标签,p表示第K个特征属于同一个身份标签(即正样本)的概率。如果第K个特征是一个正样本,则y=1,否则为0。具体公式如下所示:
[LBCE=-1Kk=1Ky∙logp+y'∙logp'] (5)
2.3 特征互补
建立人体关键点联系,关注特征的融合信息,更全面地了解目标人的特征和特点,以便更有效地抓取目标人的有利信息。然而,此过程并未解决行人图片在匹配阶段行人图像空间不对齐的问题。传统的对齐策略是匹配相同关键点的特征,但在遮挡严重的情况下效果较差。虽然图匹配可以考虑人的高阶拓扑信息,但只能进行简单的一对一对齐,对异常值敏感,缺乏健壮性。
为了解决这个问题,本文提出了一种多对多的软对齐方法,将一张图片的特征对应到另一张图片的各个特征,建立一组图片中各个节点之间的联系,不仅关注节点与节点之间的对齐,还关注边与边的对齐。这样一组图像之间的节点信息以及边的信息可以相互传递,提高对齐的准确性,提高识别效率。
具体而言,首先,使用余弦距离函数提取三元组图像,其中图像x1是从一个图像中提取的所有联合特征的集合,图像x3与x1属于不同行人,图像x2与x1属于同一行人。在给定图像匹配过程中的一组图片x1和x2,其中,x1的图为G1=(F1,E1),x2的图为G2=(F2,E2)。其次,建立了匹配矩阵S,其中Sia是指F1i和F2a之间的匹配度。然后,根据一元和成对点特征建立了一个平方对称正矩阵M,其中Mia,jb指的是E2与E1边的匹配程度。对于不形成边的对,它们在矩阵中的相应项被设置为0。对角线部分包含节点到节点的值,而非对角线部分包含节点到节点边的值。最后,通过深度学习框架利用随机梯度下降不断优化最优匹配矩阵U。优化过程采用幂次迭代和双随机运算。
[U=argmaxSTMS] (6)
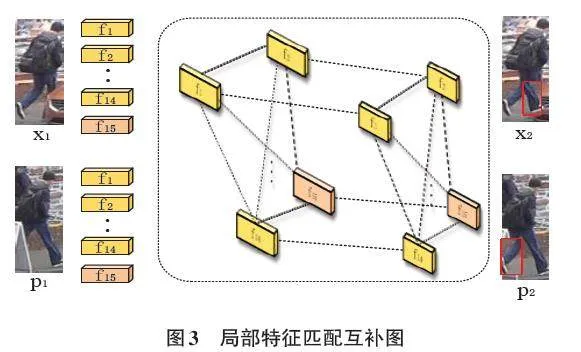
在关注边的对齐后,可以通过比较两幅图像中相应位置来确定哪些区域被遮挡了。一旦确定了被遮挡的部分,可以利用另一幅图像中对应位置的未被遮挡部分来填补这些缺失区域,实现互补。如图3所示,一张图像的左腿被遮挡,另一张图片的右腿被遮挡,将左右腿部被遮挡的部分进行互补,每张图片不仅拥有自身的鉴别信息,还拥有特征互补信息,从而减少遮挡干扰。这样有效地减少遮挡带来的影响,提高图像的完整性和质量。
通过最小化L来训练端到端的框架。首先,输入一组图片中提取到的特征F1和F2,将亲和力矩阵与特征F1i和F2i进行乘法操作([⊗]) ,然后与另一张图片的对应特征进行通道维度连接。其中,Con表示沿通道维度的连接操作,FC是一个全连接层。最后,连接的特征通过全连接层与原图像特征相加,生成更具鉴别力的特征。具体公式如下所示:
[Fa=FCConF1,U⊗F2+F1] (7)
[Fp=FCConF2,U⊗F1+F2] (8)
损失函数(Lv) 用于测量两个样本图像之间的关系,即图像[x1]和图像[x2]的输入,可以是同一个人,也可以是不同的人。每对训练图像(x1,x2)都有一个标签,表明它们是正样本对还是负样本对。如果两张图像为正样本即属于同一个人,则y=1,否则为0。Sx1,x2表示x1和x2之间的相似性。具体公式如下所示:
[LV=ylogsx1,x2+1-ylog1-sx1,x2] (9)
3 实验分析
3.1 实验环境设置
本次实验的硬件环境包括Intel(R) Xeon(R) CPU E5-2670×2处理器、48GB DDR4内存、4块Nvidia GeForce Titan X GPU、3块4TB HDD和512GB SSD。软件环境为Ubuntu18.04操作系统、Pytorch深度学习框架和Python3.7。训练网络时,批量大小为64,共有16个人,每人有4张256×128像素的图像。在图像预处理过程中,添加了随机水平翻转、随机擦除、随机裁剪,并进行填充10个像素。其中,随机水平翻转和随机擦除的概率均设置为0.5,如图4所示。训练包括120个epochs,学习率从3.5e-4逐渐衰减至0.1,采用SGD优化器进行端到端学习。在测试含遮挡数据集时,采用额外的颜色抖动增强来减少域方差。
3.2 实验数据集
本文利用三个公开的行人重识别数据集来验证所提出的方法,分别为整体数据集 Market1501 和 DukeMTMC-ReID 以及遮挡数据集 Occluded_DukeMTMC。其中,Market1501 包含来自6个摄像机视角的1 501个身份,所有数据集中都包含很少被遮挡或部分遮挡的人物图像。DukeMTMC-ReID 包含1 404个身份。而遮挡数据集 Occluded_DukeMTMC 是从 DukeMTMC-ReID 中提取而来,保留了含有遮挡的图像,丢弃了重叠的图像。该数据集包括以下内容:训练图像涵盖702个人共计15 618幅图片,图库图像包含1 110个人共计1 7661幅图片,而含有遮挡的查询图像有519个人共计2 210幅图片。
3.3 实验结果
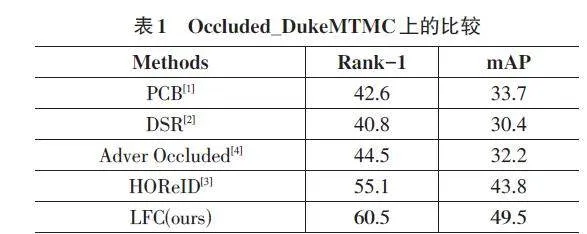
在遮挡数据集 Occluded_DukeMTMC 上进行评估,根据表1的结果显示,本文所提出的方法在 Rank-1方面取得了60.5%的成绩,mAP方面达到了49.5%。这显示了该方法在处理数据遮挡方面的优越性,凸显了模型在遮挡数据集上的高性能。
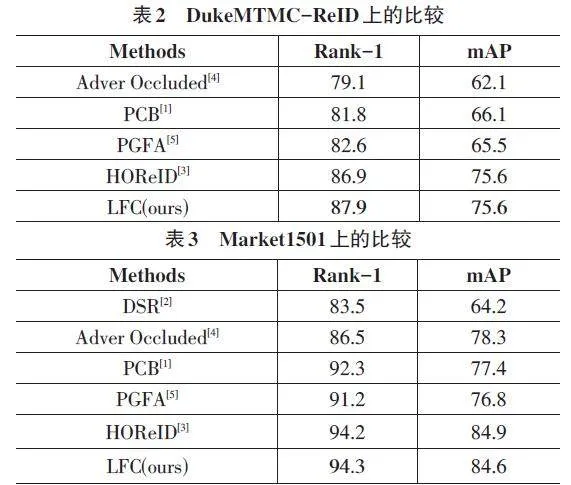
目前,一些遮挡 ReID 方法仅仅在遮挡或仅含身体部分的数据集上有改进,但它们在整体数据集上通常表现不尽如人意,这是由于特征学习和对准过程中的噪声所致。为了展现模型的泛化能力,在整体数据集 DukeMTMC-ReID 上进行实验。本模型在该数据集上取得了 Rank-1和mAP分别为87.9% 和75.6%的成绩,在 Market1501上取得了Rank-1和mAP分别为94.3%和84.6%的成绩,如表3所示。尽管本文的模型在整体数据集上并非最领先,但相较于大多数整体数据集上的模型,仍有更好的表现,表明本文方法具备较好的通用性和泛化能力。
4 结论
局部特征互补的遮挡行人重识别研究展现出巨大潜力。首先,通过姿态估计模型有效提取了含细节信息的局部特征,增强了模型的鲁棒性和准确性。其次,结合人体关键点的连接结构,成功建立了节点之间的联系并实现了特征信息的传递、融合及学习,从而显著提升了特征的鉴别性和全局特征表示。最后,引入了多对多的软对齐和特征互补,增强了对遮挡的感知能力,有效地处理了遮挡和干扰等问题。在实验验证方面,本文在多个数据集上进行了验证实验,结果表明所提出的框架在行人重识别任务中具有显著的优势和有效性。这些实验结果为解决行人重识别中的遮挡和干扰等问题提供了新的思路和方法,有望推动行人重识别技术的进一步发展和应用。
参考文献:
[1] SUN Y F,ZHENG L,YANG Y,et al.Beyond part models:person retrieval with refined part pooling (and A strong convolutional baseline)[C]//European Conference on Computer Vision.Cham:Springer,2018:501-518.
[2] LI W,ZHU X T,GONG S G.Harmonious attention network for person re-identification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:2285-2294.
[3] WANG G A,YANG S,LIU H Y,et al.High-order information matters:learning relation and topology for occluded person re-identification[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle,WA,USA.IEEE,2020:6448-6457.
[4] ZHANG S S,YANG J,SCHIELE B.Occluded pedestrian detection through guided attention in CNNs[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:6995-7003.
[5] HE L X,LIANG J,LI H Q,et al.Deep spatial feature reconstruction for partial person re-identification:alignment-free approach[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:7073-7082.
[6] 李爽,李华锋,李凡.基于互预测学习的细粒度跨模态行人重识别[J].激光与光电子学进展,2022,59(10):1010010.
[7] 李枘,蒋敏.基于姿态估计与特征相似度的行人重识别算法[J].激光与光电子学进展,2023,60(6):3788/LOP212869.
【通联编辑:唐一东】
