基于协同过滤和机器学习的新闻推荐
2024-09-13承孝敏
摘要: 针对传统基于内容的推荐、协同过滤和机器学习推荐存在的问题,如庞大数据的弱处理能力、时效性差以及缺乏可解释性,提出了一种基于协同过滤和机器学习融合的新闻推荐算法。首先构建了用户-新闻交互评分模型、新闻时效性评分模型和新闻内容评分模型,利用协同过滤相关算法预测用户新闻推荐分数。然后通过构建用户档案和新闻档案提取用户特征和新闻特征,利用机器学习模型预测用户-新闻评分。最后,通过软投票机制将用户-新闻对的协同过滤分数和机器学习分数融合,进行全面的新闻推荐。实验结果表明,该算法能够有效提高新闻推荐的准确性。
关键词: 机器学习;协同过滤;用户画像;新闻画像;融合推荐
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)22-0001-03
开放科学(资源服务)标识码(OSID)
0 引言
随着互联网技术的迅猛发展和普及,新闻和信息的获取与发布发生了深刻的变化。在信息爆炸的时代,从庞大的新闻中过滤出用户感兴趣的内容并准确推送给他们是一个重大挑战。传统的推荐方法依赖于浏览历史和兴趣偏好,但存在数据稀疏、冷启动等问题,无法满足个性化和准确的需求。
基于内容的推荐(CB) 是指基于物品相关信息、用户相关信息以及用户对物品的操作行为进行推荐。通常使用 TF-IDF、word2vec 以及语言模型等方法来处理新闻并生成用于推荐的标签。推荐结果具有解释性,但缺乏多样性且难以提取特征。协同过滤(CF) 采用与用户相似的用户行为(评分、点击次数等)来推断用户对特定产品的偏好,然后根据这些偏好做出相应的推荐[1]。通常使用 SVD[2]等算法对评分矩阵进行分解以解决矩阵问题,主要包括基于用户[3]和基于产品[4]的两种方式。作为经典的推荐算法,协同过滤无须对商品或用户进行分类或标注,可以高效解决难以提取特征的问题。然而,在处理新闻推荐时,协同过滤算法面临一些问题,例如新闻的时效性和用户的动态变化。
另一方面,基于机器学习的推荐可以通过构建用户画像和新闻画像来克服新闻时效性的变化和用户兴趣的动态变化等问题。然而,它通常在可解释性方面表现较差,并对数据质量有较高的要求。文献[5]提出了一种基于图注意力和神经协同过滤的社会推荐模型 AGNN-SR,通过学习用户项目交互图和社交网络图上的用户和项目潜在特征,以及利用神经协同过滤层编码用户项目交互的协作信号,实现了有效的社交推荐。然而其在冷启动场景下的表现结果不佳。文献[6]则从知识图谱的角度出发,设计了一种融合社交关系和知识图谱的推荐算法 MSAKR,通过图卷积神经网络提取用户社交关系特征,并利用知识图谱学习物品属性信息,以缓解数据稀疏性并提升推荐性能。但是这种方法主要依靠用户或物品之间的关联关系,对用户与物品之间的交互信息利用程度较低。
为了克服这些问题,本文提出了一种协同过滤和机器学习集成的新闻推荐算法,能够有效利用用户的历史行为数据和时效性信息,提高推荐的准确性。本文的主要贡献包括:1) 提出了一种基于协同过滤和机器学习融合的新闻推荐算法。通过协同过滤推荐分数和机器学习分数的融合,提高了推荐的准确性和用户满意度。2) 使用协同过滤相关算法预测用户新闻推荐分数矩阵中的缺失值,即用户新闻推荐分数的缺失值,有效解决了数据的稀疏问题。3) 通过构建用户画像和新闻画像,并利用机器学习算法推荐新闻,提高了推荐的个性化程度。
1 方法
本文提出了一种基于协同过滤和机器学习融合的新闻推荐算法,主要包括三个部分:基于协同过滤的评分预测、基于机器学习的评分预测以及融合推荐。首先,构建了用户-新闻互动评分模型、新闻时效性评分模型和新闻内容自身评分模型,并通过关联算法-时间的协同过滤预测用户的新闻推荐得分。然后,通过构建用户画像和新闻画像提取用户特征和新闻特征,利用机器学习模型预测用户-新闻评分。最后,采用软投票机制实现用户-新闻对的协同过滤分数和机器学习分数的融合,进行全面的新闻推荐。
1.1 用户新闻评分计算
1.1.1 行为因素评分
在行为因素评分计算模块中,核心目标是计算由用户与新闻的互动构建的互动分数。用户对新闻内容的点赞、收藏、分享和评论可以代表用户对新闻内容的兴趣。单个点赞、收藏、分享和评论的分数分别如下[P,C,S,Comm]:用户评论的分数是根据用户行为累积得到的,通过使用sigmoid函数进行标准化:
[Tb=np×P+nc×C+ns×S+nComm×Comm] (1)
[Tbehaviour=11+e-Tb] (2)
式中:[np,nc,ns,nComm]分别表示用户的点赞、收藏、分享和评论的数量。
互动内容得分由两个得分组成:阅读时间得分和评论内容得分。假设所有用户对一则新闻的平均阅读时间为[t0],某一则新闻的阅读时间为[t],则阅读时间得分如下:
[Treading=11+e-k(t-t0)] (3)
当用户的阅读时间长于平均阅读时间时,阅读时间得分接近1,表示用户对新闻的兴趣较高。
评论内容得分基于特定关键词,构建了内容情感分析模型。首先,使用中文分词工具将评论内容分词成相应的分词序列。然后,使用TextRank算法从评论内容中提取关键词,并利用BERT预训练语言模型表征关键词序列,将关键词序列映射到一系列高维向量。最后,通过计算和标准化与关键词序列对应的高维向量的混乱度,得到相应的评论质量得分:
[Tc=exp(-log2softmax(wcomment)N)] (4)
[Tcomment=11+e-Tc] (5)
其中,[wcomment]表示与关键词序列对应的向量编码,[N]表示关键词序列的长度。通过组合获得的三个得分,得到与用户行为因素对应的得分:
[T=whTbahaviour+wrTreading+wcTcomment] (6)
其中,[wh,wr,wc]为融合权重且[wh+wr+wc=1]。
1.1.2 时间衰减函数
为了更准确地反映用户当前的兴趣,本文引入了时间衰减函数以消除时间因素对评分的影响。通过在评分计算中给予最近用户行为更多的权重:
[T=ek(T1-T0)T] (7)
其中,[T0,T1]表示新闻发布时间和当前时间,[k]代表时间衰减因子。
1.2 基于协同过滤的得分预测
协同过滤通过分析历史行为数据来预测用户未来的兴趣和偏好。在本文提出的模型中,采用协同过滤技术,通过找到与用户兴趣相似的其他用户喜欢的新闻来进行新闻推荐。
首先,基于用户在新闻平台上收集的历史行为数据,计算基于行为因素的得分。用户对历史数据的评分被计算并转换为二维矩阵。
接着,为了获得与用户和新闻对应的隐含因子向量,采用因子分解算法对构建的因子进行分解。利用历史评分数据,并通过最小二乘法基于预测与实际评分之间的差距,训练矩阵分解模型,将原始的用户-新闻评分矩阵分解为两个低秩矩阵的乘积,[userM]和[itemM]分别表示用户兴趣和新闻内容的隐藏向量。
完成矩阵分解模型的训练后,对于给定的用户[u]和新闻[i],计算其对应的隐含因子向量的点积,可作为用户对新闻的整体评分向量:
[Tu,i=userMu⋅itemMi] (8)
其中,[userM]表示用户隐含因子向量,[itemM]表示新闻隐含因子向量。之后,通过激活函数映射得分,将其转换为在标准评分范围内的预测得分:
[T′u,i=sigmoid(Tu,i)] (9)
最后,计算所有用户对所有新闻的预测评分,生成完整的用户-新闻预测评分矩阵,然后根据预测评分对所有候选新闻进行排序,选择评分最高的前n条新闻作为用户的推荐结果。
1.3 基于机器学习的得分预测
基于机器学习的得分预测需要使用用户数据和新闻数据。因此,在本文中,对用户数据和新闻数据进行处理,实现用户画像和新闻画像的构建,这可以提供丰富的用户和新闻特征,并为基于机器学习的推荐得分预测提供强有力的支持。
1.3.1 用户画像构建
用户画像是对用户信息的综合描述,包括用户的基本信息、兴趣偏好和行为特征。构建用户画像的过程可分为数据收集与处理、特征提取、画像构建和画像更新四个步骤。
数据收集与处理收集包括注册信息、历史行为记录、社交网络信息等在内的用户各种数据,清理原始数据,去除噪声和冗余,处理缺失值。从清理后的数据中提取特征,如基本信息和行为特征。根据特征标注用户以构建画像。定期更新画像以反映用户变化,使用时间窗口或增量学习。对提取的特征进行向量处理,使用不同的编码方法处理不同标签,生成用户特征向量。
1.3.2 新闻画像构建
新闻画像构建包括数据收集与处理、特征提取、画像构建和更新四个步骤。推荐系统需考虑多维信息,需获取新闻文本和相关元数据,如发布时间、来源和作者,可从新闻网站、社交媒体等获取。预处理包括去除停用词、词形变化、分词等,有助于提取有效信息。从预处理后的文本中提取新闻特征,如标题、关键词、命名实体识别结果、情感倾向、主题分类等。根据提取的特征对新闻进行标注,如领域标签、情感标记。定期更新新闻画像,可使用时间窗口或增量学习。需对新闻特征进行向量化处理作为模型输入,类似于用户标签编码,不同标签使用不同编码方式。
1.3.3 基于XGBoost的得分预测
在构建并将用户画像和新闻画像编码成特征向量后,可以为基于机器学习的推荐得分提供丰富的用户和新闻特征,从而提高得分特征的准确性。
首先,将历史用户特征向量和用户已阅读新闻特征向量拼接,得到用户-新闻特征向量,并将y标签设为正向。然后,将历史用户特征向量和用户未阅读新闻特征向量拼接,得到用户-新闻特征向量,并将y标签设为负向。最后,基于构建的用户-新闻正负样本,采用XGBoost模型进行建模,并对所有用户-新闻配对进行得分预测,从而得到所有用户-新闻得分的矩阵。
1.4 综合推荐
基于协同过滤和基于XGBoost模型计算的得分通过软投票机制进行合并。即对于用户[u]和新闻[i],假设它们的协同过滤得分为[Su,icf],XGBoost模型得分为[Su,ixgb],得分[S]的计算方法如下:
[S=λ1Su,icf+λ2Su,ixgb] (10)
其中,[λ1]和[λ2]为融合权重,[λ1+λ2=1]。
对所有用户-新闻配对的得分进行融合,得到最终的用户-新闻得分矩阵。对于任意用户 [u],根据评分矩阵的结果,对用户与所有由新闻构建的用户-新闻配对进行得分和排序,然后根据排序结果进行新闻推荐。
2 实验
2.1 数据集
为了评估本文推荐算法的性能,本文采用了一个大规模的真实新闻推荐数据集。该数据集包含了515 673个用户与新闻的互动,包括点击、浏览、点赞、评论等行为。数据集中的每条记录包含userID、newsID以及用户对新闻的具体行为。
2.2 基准模型
为验证本文提出的推荐算法的有效性,选择以下推荐算法作为比较实验的基准模型:
· POP:根据历史新闻的流行度进行推荐,即推荐集中关注历史上最受欢迎的新闻。
· S-POP:根据当前时间段内新闻的流行度进行推荐,即在推荐训练中根据时间集中推荐具有最高流行度的新闻。在推荐过程中,随着项目获得更多事件,推荐列表会发生变化。
· Item-KNN[7-8]:基于新闻相似性进行推荐,定义为其推荐向量的余弦相似度。
· BPR-MF[9]:通过SGD优化配对排序的目标函数,即通过矩阵分解算法处理用户-新闻排序矩阵,得到用户对新闻的排序结果进行推荐。
· SVD++:通过分析用户的历史行为数据,找到具有相似兴趣的用户群体或找到与用户先前喜欢的新闻相似的新闻进行推荐。
2.3 对比实验
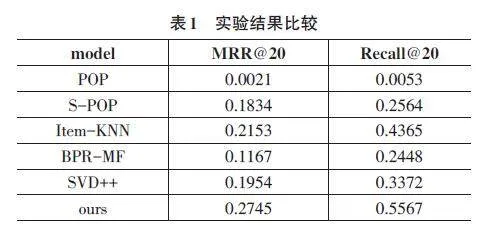
本文实验采用MRR@20(即推荐列表前20条新闻的平均倒数排名)和Recall@20(即推荐列表前20条新闻的召回率)作为评价指标,本文提出的推荐算法与基准模型的对比实验结果如表I所示。
实验结果表明,本文提出的推荐算法在各种指标上均优于其他基准模型。具体而言,与其他基准模型相比,本文的算法在MRR@20上至少提高了6%,在Recall@20上提高了12%。通过比较实验结果,可以看出本文提出的推荐算法在新闻推荐任务中具有更好的性能。
3 结论
本文提出了一种基于协同过滤和机器学习融合的新闻推荐算法。该算法首先结合了三个评分模型,即用户-新闻互动评分、新闻时效性评分和新闻内容评分。使用协同过滤相关算法来估计用户对新闻的推荐评分。然后,构建用户画像和新闻画像,利用基于机器学习的模型预测用户-新闻评分。最后,采用软投票机制将协同过滤得分和机器学习得分整合,实现全面的推荐。实验证明,本文的推荐算法能够有效提高新闻推荐的准确性和用户满意度。
参考文献:
[1] LIU Q,CHEN E H,XIONG H,et al.Enhancing collaborative filtering by user interest expansion via personalized ranking[J].IEEE Transactions on Systems,Man,and Cybernetics Part B,Cybernetics:a Publication of the IEEE Systems,Man,and Cybernetics Society,2012,42(1):218-233.
[2] PENG S W,SUGIYAMA K,MINE T.SVD-GCN:a simplified graph convolution paradigm for recommendation[C]//Proceedings of the 31st ACM International Conference on Information & Knowledge Management.Atlanta GA USA.ACM,2022:1625–1634.
[3] ADOMAVICIUS G,TUZHILIN A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[4] XUE F,HE X N,WANG X,et al.Deep item-based collaborative filtering for top-N recommendation[J].ACM Transactions on Information Systems,2019,37(3):1-25.
[5] 章琪,于双元,尹鸿峰,等.基于图注意力的神经协同过滤社会推荐算法[J].计算机科学,2023,50(2):115-122.
[6] 高仰,刘渊.融合社交关系和知识图谱的推荐算法[J].计算机科学与探索,2023,17(1):238-250.
[7] LINDEN G,SMITH B,YORK J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[8] DAVIDSON J,LIEBALD B,LIU J N,et al.The YouTube video recommendation system[C]//Proceedings of the fourth ACM conference on Recommender systems.Barcelona Spain.ACM,2010.
[9] RENDLE S,FREUDENTHALER C,GANTNER Z,et al.BPR:Bayesian personalized ranking from implicit feedback[J].ArXiv e-Prints,2012:arXiv:1205.2618.
【通联编辑:唐一东】
