基于ERNIE及改进DPCNN的棉花病虫害问句意图识别
2024-08-22李东亚白涛香慧敏戴硕王震鲁








关键词:棉花病虫害;问句意图识别;ERNIE模型;DPCNN模型;词位置信息
中图分类号:S435.62:TP391.1 文献标识号:A 文章编号:1001-4942(2024)06-0143-09
棉花是一种重要的经济作物,是纺织业中最重要的原料之一,被广泛种植于世界各地。病虫害是棉花种植和生产中的主要问题之一,对棉花产量和质量的影响很大,严重时甚至会导致大面积的歉收。目前,大多棉花种植人员依赖于采用人工方式寻找解决棉花病虫害问题的方案,这很难满足生产上需要及时解决问题的要求。随着互联网和大数据技术的高速发展,构建专业领域的智能问答系统将能够为人们提供准确的诊断结果和个性化的信息服务,为棉花产业的信息化和智能化奠定基础。知识问答方法主要包括问句意图识别、信息抽取和答案检索三个部分,其中问句意图识别是关键步骤,使用识别效率高的方法能有效提升问答质量。
问句分类是一种将自然语言问句分类到不同的类别或类别集合的自然语言处理任务,其目的是将问题与可能的答案类型相对应,以便自动回答问题或帮助用户更快地找到答案。目前针对该任务的方法有传统的基于规则和统计的机器学习方法,以及深度学习方法。传统方法包括支持向量机(SVM)、朴素贝叶斯等机器学习算法,这些方法通常依赖于手工提取特征,人力、物力成本高。深度学习方法包括卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)等,已有许多研究者将其应用到文本分类任务中,例如Zhang等提出了一种基于多层CNN的问句分类方法,可以提高问句分类的准确率:Lu等提出了一种基于分层注意力机制的深度神经网络模型用于问句分类任务,具有较好的性能:王奥等提出一种基于特征增强的多方位农业问句语义匹配模型,使用双向长短期记忆网络及多维注意力机制对农业问句进行语义匹配,实现了农业问句快速自动检测。
在农业领域,王郝日钦等提出了一种基于Attention_DenseCNN的水稻问句文本分类方法,能够快速、准确地对水稻问句文本进行自动分类,分类精确率及F1值分别为95.6%和94.9%;李林等提出了一种用于农业病虫害问句分类的深度学习模型BERT_Stacked LSTM,使用堆叠长短期记忆网络(Stacked LSTM)学习到隐藏的复杂语义信息,用于农业病虫害问句分类取得了较好的效果。金宁等提出了BiGRU_MulCNN分类模型,利用双向门控循环单元获取文本特征信息,进行多粒度的特征提取,能准确地完成用户问句的自动分类,
然而目前棉花病虫害领域缺少公开的数据集,而且存在棉花病虫害问句多为短文本、包含的语义特征少、文本特征提取方法单一等问题。为有效解决上述问题,本研究构建了一个棉花病虫害问句数据集,并提出了一个基于ERNIE(En-hanced Representation through Knowledge Integra-tion)及改进DPCNN(Deep Pyramid Convolutional Neural Networks for Text Categorization)模型的问句分类模型,以期实现棉花病虫害问句的精准分类。
1材料与方法
1.1棉花病虫害问句数据集构建
针对目前没有公开的棉花病虫害问句数据集以及网络中相关的问句数量少等问题,通过查阅相关数据文献及咨询领域专家,构建了棉花病虫害问句数据集CQCls。该数据集中定义了棉花病虫害实体共78种,问句类型9种,问句类型与棉花病虫害知识图谱实体关系相对应。通过将不同的实体名称及问句类型进行组合,可生成不同类型的问句,例如“棉花白粉病的危害症状是什么?”;通过使用句式模板、同义词替换等方法进行问句数据的扩充,例如,利用不同的句式模板可以将“棉花立枯病的分区区域有哪些?”转化为“棉花立枯病主要分布在哪些地方?”,而通过同义词替换又可以将其转换为“立枯病主要集中在哪些地区?”,以此完成数据集的扩增。对于问句类型的标注,通过判断问句中是否出现同一类型的关键词,如“别名”、“别称”、“俗称”等进行统一标注,最后通过人工校对完成标注。棉花病虫害问句实例如表1所示。
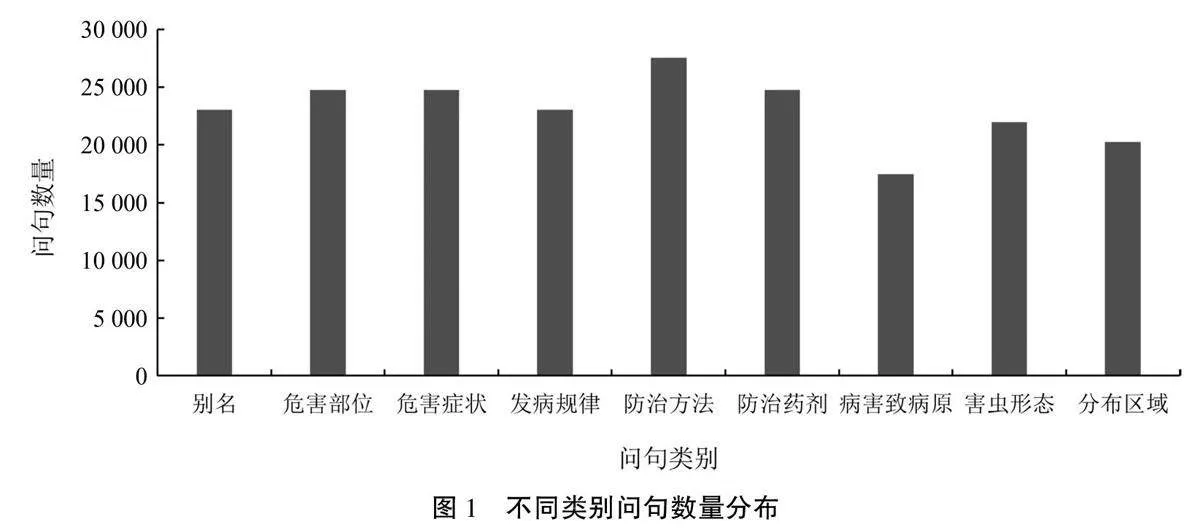
通过以上方法最终获得问句数据共207644条,其中病虫害别名类问句23058条,危害部位类问句24766条,危害症状类问句24766条,发病规律类问句23058条,防治方法类问句27572条,防治药剂类问句24766条,病害致病原类问句17446条,害虫形态类问句21960条,分布区域类问句20 252条(图1)。
1.2棉花病虫害问句意图分类模型
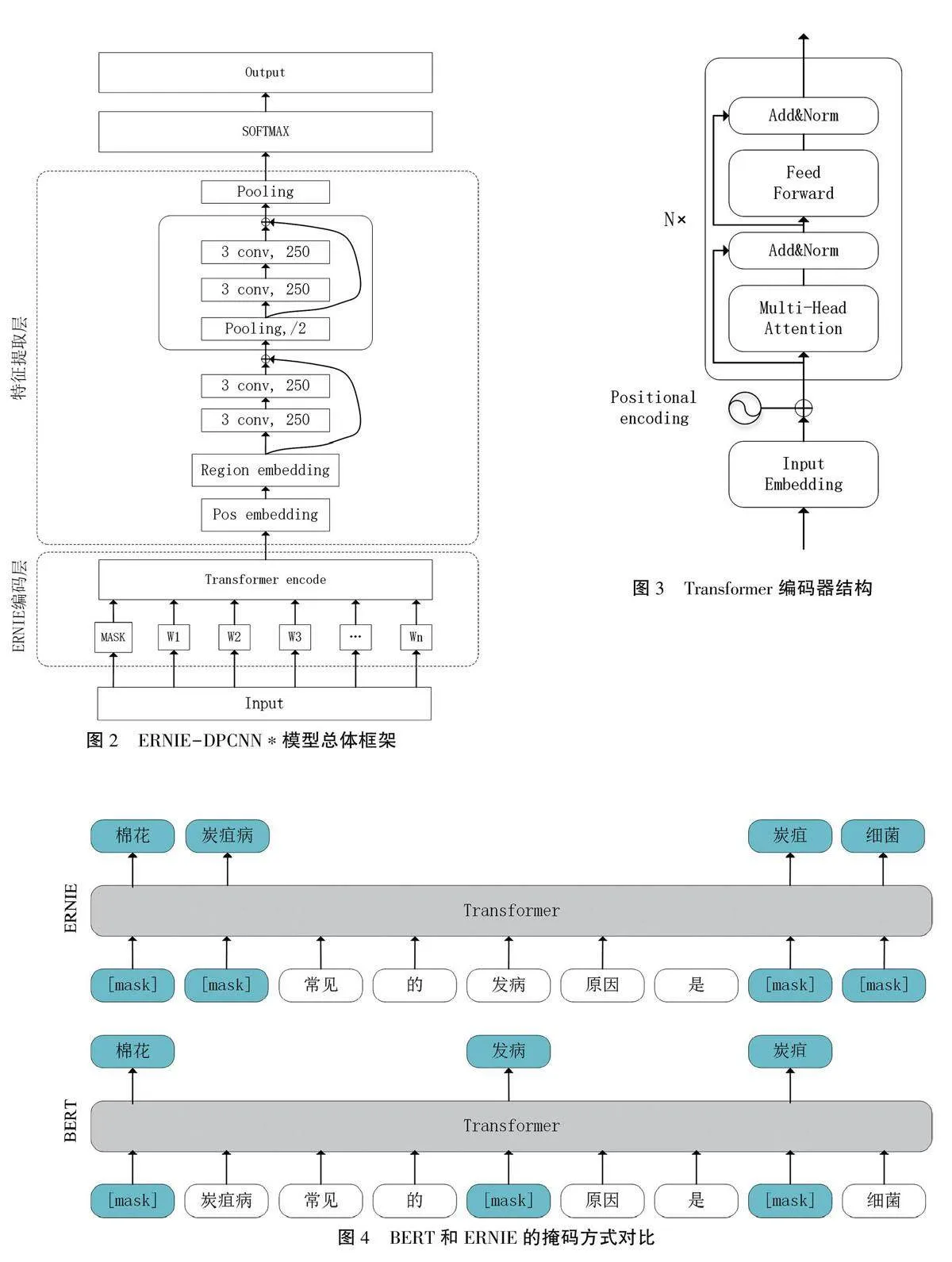
针对棉花病虫害问句较短、类型多样等问题,提出了一种基于ERNIE预训练模型和融合词位置信息的DPCNN模型的深度学习模型,用ERN-IE-DPCNN*表示,用来完成对自然语言问句意图分类的任务。模型总体框架如图2所示。
该模型首先使用预训练的ERNIE模型进行文本编码,得到每个词的embedding表示;对每个词的embedding进行位置信息编码,即将每个位置映射为一个embedding向量,然后将该向量与词embedding结合得到带有位置信息的embed-ding表示;将带有位置信息的embedding输入DPCNN模型中进行特征提取,最后通过全局池化层将特征图转换成固定大小的向量,使用全连接层将该向量映射到类别空间。
1.2.1 ERNIE模型 ERNIE是百度公司于2019年提出的一种基于预训练的语言模型,是百度自然语言处理技术的重要组成部分,旨在通过引入外部知识(如实体、知识图谱等)和多任务学习等方式,进一步提高语言表示的质量和泛化能力。它采用与BERT相同的双向Transformer架构进行预训练。ERNIE主要包含两种类型的预训练模型:基于单语言的ERNIE和跨语言的ERN-IE。基于单语言的ERNIE在中文、英文、泰文等多种语言上预训练,其中中文预训练使用的是比BERT更大的中文语料库,包括百度百科、百度贴吧、百度知道等多种数据源。跨语言的ERNIE则在多种语言上预训练,包括英文、中文、阿拉伯语、德语等多种语言。
ERNIE的预训练模型是基于Transformer编码器(图3)构建的。它采用多层Transformer编码器对输入进行编码,每层Transformer编码器由多头自注意力机制和前向全连接网络组成。ERNIE使用的是相对位置编码,这种编码方式可以更好地表示句子中单词之间的位置关系。
ERNIE与BERT的区别在于ERNIE在预训练过程中加入了实体知识,即通过改变掩码策略——将BERT中的随机掩码替换为实体或短语级别的掩码,引入了聚合知识的学习机制,使ERNIE能够更有效地学习句法和语义知识,更好地理解和表示中文文本中的实体和短语,提高模型在语义理解、命名实体识别、关系抽取等任务上的性能。ERNIE使用开源的百度知识图谱(Baidu Knowledge Graph,BKG)来为输入序列引入知识,数据输入后,通过编码、添加位置信息,利用多头注意力机制进行计算并归一化,经过多个层的前向传播和再次归一化,实现对输入数据的编码和丰富的特征表示,最终输出编码。这种聚合知识的引入为ERNIE的语义理解能力和多任务学习效果带来了显著的提升,使其成为在中文自然语言处理任务中表现最优秀的模型之一。BERT和ERNIE的掩码方式对比如图4所示,这种方式可以使ERNIE在多项自然语言处理任务上表现出更好的性能。
1.2.2改进DPCNN模型 DPCNN是Johnson等提出的一种深度卷积神经网络,包括输入层、卷积层、池化层、残差连接、全局池化层和输出层,主要用于文本分类任务。它的核心思想是通过多个池化层和卷积层来捕捉句子中不同长度的局部特征,并且通过残差连接和固定池化来避免过拟合和梯度消失的问题。但DPCNN模型不考虑文本中的位置信息。针对棉花病虫害问句总体较短的特点,本研究对DPCNN进行改进,通过引入位置编码来融合位置信息,可以有效提高模型的表达能力。改进后的DPCNN模型如图5所示。
首先,将输入序列与词位置向量进行融合,然后使用Region embedding将其转换为句向量表示,并逐个输入到一系列卷积组中。每个卷积组由一个卷积层和残差连接组成,然后这些卷积组通过步长为2的池化层连接在一起,通过设置多个卷积组可以逐步提取更丰富的特征,最后一个卷积组将会生成输入序列的最终特征向量表示。
2结果与分析
2.1软硬件环境及模型参数
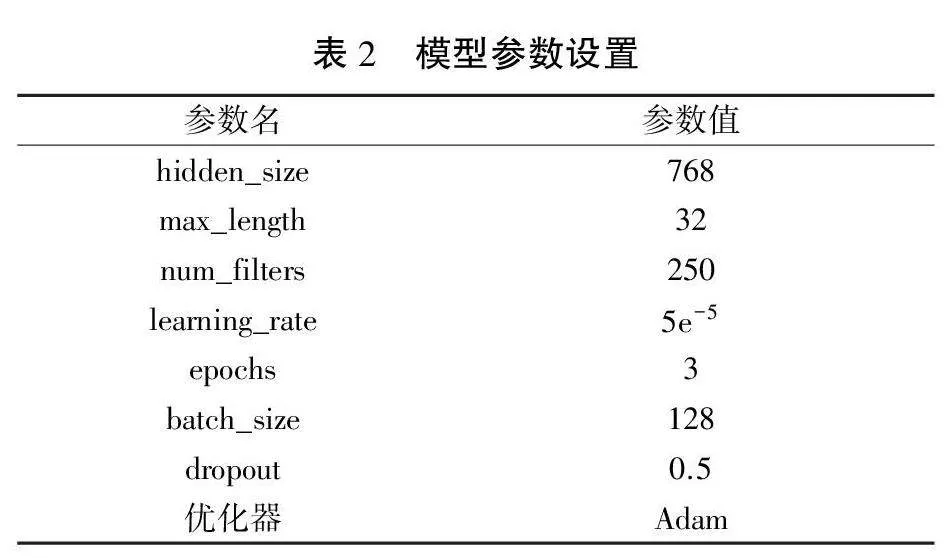
所使用的计算机硬件环境包括Intel(R) Xe-on(R) CPU E5-2620 v4 @ 2.10 GHz处理器,NVIDIA TITAN V显卡,以及64.0 GB的内存。软件环境包括Python 3.6版本和PyTorch框架的1.7.1+cu110版本。模型具体参数设置如表2所示。
2.2模型评价指标
使用准确率(Precision)、召回率(Recall)、F1分数(F1-Score)对深度学习模型的训练效果进行评价。具体公式如下:
P=TP/(TP+FP)×100% ; (1)
R=TP/(TP+FN)×100% ; (2)
F1=2×P×R/(P+R)×100% 。 (3)
式中:P代表准确率;R代表召回率;F1代表F1分数;TP(真阳性)为模型预测为正例的样本中实际为正例的数量;FP(假阳性)为被识别为正例的样本中实际为负例的数量;TN(真阴性)为被分类为负例的样本中实际为负例的数量;FN(假阴性)为模型预测为负例的样本中实际为正例的数量。
另外,在使用深度学习方法进行文本多分类任务时,通常采用宏平均(MacroAvg)、权重平均(WeightedAvg)综合评价每个模型的结果。其中,宏平均是对每个类别分别计算Precision、Re-call和F1-Score的平均值,并将所有类别视为同等重要,不考虑各类别样本数量不平衡造成的影响。权重平均是对每个类别分别计算Precision、Recall和F1-Score的加权平均值,其中权重是每个类别的样本数目占总体样本数目的比例。宏平均和权重平均的具体计算公式如下。
2.3不同深度学习模型的训练效果评价
针对棉花病虫害问句,使用不同的深度学习模型进行多组实验:以BERT模型作为基准模型,分别结合TextCNN、TextRCNN、RNN和DPCNN模型对BERT进行改进。通过实验对比,发现使用BERT结合DPCNN的模型训练效果整体表现较好,性能上超过了其他组合模型;进一步使用ERNIE优化BERT对中文掩码不足的缺点,并增加词位置信息优化DPCNN模型,得到改进后的ERNIR-DPCNN*模型,用于对棉花病虫害问句意图进行分类,取得较好的训练效果,基于Mac-roAvg和WeightedAvg的Precision、Recall和F1-Score均在97%以上(表3)。表明DPCNN模型对特征的提取相较于其他模型表现良好,通过在输入向量中融入词位置信息能进一步增强模型的学习能力,从而提升模型的性能。
不同模型训练结果的混淆矩阵如图6所示,其中横纵坐标的标签均代表了棉花病虫害问句的不同类别。
2.4 DPCNN模型卷积核层数对训练结果的影响
DPCNN模型的核心思想是通过多个池化层和卷积层来捕捉句子中不同长度的局部特征,在一定范围内增加DPCNN的层数可以提高模型的表现,但是过多的层数可能会导致模型出现过拟合等问题,同时也会增加模型的训练时间和复杂度。通常,一个层数适中的DPCNN模型在文本分类等任务中能够取得较好的性能。本研究针对棉花病虫害问句意图分类任务,对比包含不同层数卷积核的模型训练结果,表4可知,在本研究构建的数据集上,使用DPCNN模型进行文本多分类任务时,当卷积核为2层时模型性能最好,其宏平均和权重平均下的Fl值分别为97.30%和97.39%,Precision分别为97.48%和97.33%,Re-call分别为97.45%和97.31%。因此在本研究提出的模型采用2层卷积核的DPCNN完成特征的提取任务。
2.5数据集对比实验
为验证ERNIR-DPCNN*模型在其他公开数据集上的表现效果及泛化能力,选用TNEWS今日头条中文新闻数据集、DMSCD豆瓣电影短评数据集和THUCNews中文新闻数据集与本研究构建的CQCls数据集进行对比实验。其中,TNEWS数据集包含10个分类的新闻标题和摘要数据,涵盖了时政、财经、房产、教育、科技、军事、体育、娱乐、游戏和时尚领域,总样本超过50万条,训练集和测试集各占50%。THUCNews是清华大学自然语言处理实验室发布的中文新闻数据集,包含14个分类的新闻数据,涵盖了时政、财经、教育、科技、文化、体育、娱乐等领域,总样本数超过26万条,训练集、验证集和测试集的比例为8:1:1。DMSCD是由豆瓣网用户发布的中文电影短评数据集,包含了超过200万条的电影短评数据,每条短评数据都由一段文字组成,包含了该用户对电影的评分和一些标签信息,涵盖了电影的剧情、演员、音乐等各个领域。对于DMSCD数据集,本研究选取了12个电影的212043条评论数据构成该数据集的子集,然后按8:1:1划分训练集、测试集和校验集。对比实验结果(表5)显示,本研究提出的ERNIR-DPCNN*模型在棉花病虫害问句数据集CQCls以及其他公开数据集上的训练结果均表现良好,对于文本语料数据内容复杂多样且文本格式不规范的DMSCD数据集,基于权重平均的F1-Score也能达到73.42%,证明了本研究所提出模型的有效性及泛化能力。
2.6不同模型的棉花病虫害问句意图分类结果对比分析
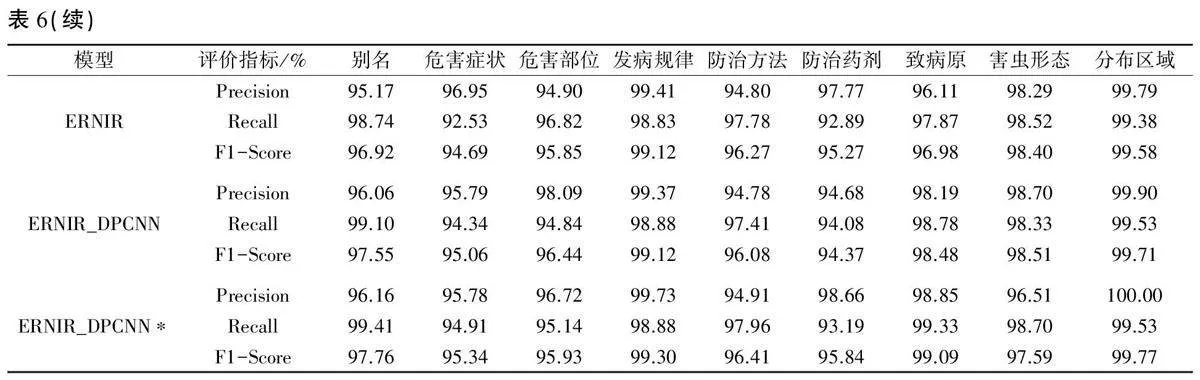
由实验结果(表6)可以发现,各个模型在不同问句类别的Precision、Recall、F1-Score表现相差不大,其中发病规律和分布区域的F1-Score相较于其他类别更高,均在98%以上。这是由于这两类问句的特征词较明显,例如分布区域类问句中大多会出现“地区”、“区域”等词语。从整体上看,本研究提出的ERNIR_DPCNN*模型在Recall和F1-Score指标上表现最好,各类问句的评价结果均高于95%,在棉花病虫害问句意图分类任务上性能良好:但是其Precision值及Recall值在部分类型中表现不是最好,说明该模型对于问句类型分类的正确率还需进一步提升。
3讨论与结论
随着农业领域信息化的发展,不同农作物病虫害防治的智能化、信息化管理在农业生产中起着越来越重要的作用。本研究针对棉花病虫害领域相关问句信息的现状,构建了棉花病虫害问句数据集CQCls,并基于ERNIE及改进DPCNN构建了棉花病虫害问句意图识别模型ERNIR_DPC-NN*,通过使用ERNIE预训练模型以及在DPC-NN模型中增加词位置信息提高了模型的表达能力,在文本分类任务上取得了较好的效果,并且能够平衡各类别样本数量不同的影响。
为使ERNIR_DPCNN*模型的分类效果达到最优,本研究对DPCNN模型的卷积核层数进行了筛选实验,结果发现,在CQCls数据集上,使用2层卷积核的DPCNN模型达到了最好的性能。而过多的层数可能会导致过拟合等问题,并增加模型的训练时间和复杂度。
此外,选用TNEWS今日头条中文新闻数据集、DMSCD豆瓣电影短评数据集和THUCNews中文新闻数据集对ERNIR_DPCNN*模型的分类效果进行了实验,结果表明,该模型在数据量不足、数据特征不明显的数据集上也能取得较好的分类效果,说明该模型具有一定的泛化能力和有效性。
但本研究仅针对棉花病虫害领域的问句分类做了研究,各类问句数据的形式还不够丰富,在接下来的研究中,可以从更多途径收集实际生产过程中用户提出的不同问题,从而进一步提升模型的识别准确率。另外,模型训练对硬件设备的算力要求较高,后续可以对模型进行精简,在减少参数量的同时保证准确率,从而减少模型训练所需的时间,降低对硬件设备的要求。
