数据要素对经济增长的影响
2024-08-05刘治彦王谦


[摘要]在数字经济时代,数据要素作为数字化与智能化的基础,是促进经济增长的关键生产要素。数据要素通过辅助市场主体进行科学决策对经济增长产生重要影响。为论证数据要素对经济增长产生的作用,文章将数据要素引入经济增长理论模型,并进行数值模拟,从理论层面论证数据要素对经济增长产生的影响。同时,利用2013—2020年的中国284个地级市为面板数据,对数据要素对经济增长的影响及科学决策机制进行验证。结果表明随着数据要素投量的增加,公司利润、社会总利润随之增加,并收敛于某一上限,数据共享可以有效促进经济增长。数据要素发展水平显著提升了经济增长,但存在区域异质性,科学决策对经济增长起到中介作用。
[关键词]数据要素;决策;经济增长
[中图分类号]F49;F1241[文献标识码]A[文章编号]1673-0461(2024)09-0009-11
一、研究背景
数字经济时代是数字化与智能化的时代,随着互联网、大数据、人工智能等现代化信息技术的不断发展,数据不断联通、积聚,成为继土地、资本、劳动、技术之后的又一关键的生产要素[1-2],在经济运行中起到提高经济效率、改善资源配置、实现价值增值等重要作用。2022年1月12日国务院发布的《“十四五”数字经济发展规划》中明确提出,数据要素是数字经济深化发展的核心引擎。数据对于提高生产效率具有显著的乘数作用,是具有时代特征的生产要素。2022年12月9日公布的《中共中央国务院关于构建数据基础制度更好发挥数据要素作用的意见》中强调,数据是数字化、网络化、智能化的微观基础,已渗透到生产、分配、流通、消费和社会服务管理等各环节,改变着我们的生产、生活方式和社会治理方式。
数据成为新时期推动社会经济发展的新动力。大数据发展为数据生产要素,最本质的原因是在于数据在生产过程中发挥重要作用,在价值创造中担当重要角色[3-4]。JONES和TONETTI[5]认为数据可以看成是信息的重要组成部分,是排除了创意和知识内容的其他部分。王胜利和樊悦[6]则认为数据要素的价值伴随商品生产过程被转移到新产品中,“抽象劳动在创造价值的同时,具体劳动和数据等其他生产要素共同生产使用价值,同时转移数据等生产要素的价值”。田杰棠和刘露瑶[7]则提出,数据并不能直接参与生产,必须要转化成有生产价值的信息。数据要素具有虚拟性[8-10]、非竞争性[11-12]、非排他性[13-15]、增值性、外部性[16]等基本特征[17]。
数据要素通过辅助决策影响经济增长。在大数据技术应用范围不断扩展的背景下,市场主体倾向于更加理性的预期经济现象。企业管理者决策的制定也发生了改变,以往主要以经验为依据来做出决策,现阶段更加地依赖数据分析做出决策,这一决策制定模式成为数据驱动决策模式。ERIK等[18]分析了数据驱动决策模型的实际应用情况,分析了这一模型作出的贡献,具体地构建了相应的分析框架。PROVOST和FAWCETT[19]具体探讨了数据科学以及数据驱动决策模型之间的区别,指出企业经验管理过程中,需要重视数据科学。MCAFEE等[20]认为,传统的企业决策制定,主要依赖于管理者的经验,而数据驱动决策模型的运用则具备更加明显的优势,同时这一模型的运用,能够制定出更加科学的决策。企业对数据驱动决策重要性的认识是循序渐进的,JANSSEN等[21]认为,数据驱动决策模型能够发挥怎样的作用受到很多因素的影响,大数据的规模巨大,大数据技术的广泛应用使得企业能够更快地发现各种不良行为,避免出现错误决策。而要想发挥好数据驱动决策模型的作用,需要处理好各种管理挑战[20],具体来说,需要对企业的管理体制进行改善,企业管理中的各种因素都需要为了数据驱动决策模型的应用而调整。
在实践中,数据辅助在政府决策制定过程中发挥了越来越重要的作用。在大数据技术支撑下,政府相关决策制定和实施模式发生了转变,不再是传统的分阶段连续执行模式,而是在每一个阶段对政策决策效果进行评估,然后实时地提出替代性方案。学者HCHTL等[22]构建了政府政策制定周期模型。通过这一模型论证了数据要素在政府决策制定中发挥的作用。另外,由于运用大数据技术能够快速地搜集到大量的信息,在每一个政府决策制定过程中群众的参与程度都很高,这样就能够充分地采纳群众的意见。通过数据技术的运用,能够为决策的制定提供很好的指导,政府部门能够更好地分配社会支出,更好地为群众提供服务[23]。
数据要素对生产过程发挥作用主要是以提高企业预测精度与决策科学度为媒介的。企业借助协同网络、智能分析技术与海量数据,可以建立有效的信息系统,掌握企业外部信息渠道和企业内部信息流,及时准确地获取、收集、加工、传递决策过程所需要的各种信息,这是企业进行最优决策的基础。
数据要素通过辅助市场主体进行科学决策对经济增长产生重要影响,为论证数据要素对经济增长产生的作用,本文以柯布-道格拉斯为基础,构建了一个数据要素参与的经济增长模型,发现数据要素参与生产过程,并通过影响企业技术决策影响经济增长,社会总利润会随数据要素投入量的增加迅速上升,到达拐点后增长趋势放缓,最终趋于某个确定的上界。
本文的创新与贡献有以下两个方面:第一,将数据要素纳入传统的经济增长分析框架,在传统生产要素研究基础之上,探索数据新要素影响经济增长的特殊机制——辅助决策机制;第二,在数据要素统计数据受限的情况下,进行数据要素发展水平评价,尝试进行数据要素影响经济增长的计量分析。
二、理论模型与模拟
(一)基本假设
数据作为经济增长模型的要素之一,应符合以下三个假设:
第一,数据是经济活动的副产品,建模中需要考虑数据的反馈循环过程,更多的数据能够使公司的生产力提高,从而带来更多的生产和更多的交易,并进一步促进更多数据的产生。
第二,边际产出递减。本研究所考虑的数据是公司技术和生产决策中减少不确定性的一种手段,显然即使公司利用充分多的数据作出了完美的决策,产出也不可能是无限大的。因而最终公司拥有的数据越多,它从额外数据中获得的收益就越少,最终收敛至0,亦即满足稻田条件。
第三,规模报酬递增。与传统的生产要素不同,数据具有高度的可复制性、可共享性,数据规模的扩大对于产出的增加是有利的。已有的研究也都认为,数据要素的引入使得生产活动呈现出规模报酬递增的特征。
(二)理论模型基本框架
本研究以柯布-道格拉斯生产函数为基础,考虑引入数据要素的生产过程,对原始模型进行改造。将时间拆分为离散的1,2,3,…,t,…期,并假设市场上存在i个相互竞争的公司,则每个公司在第t期的产出可表示为:
yit=AitKitαL1itβL2itγ(1)
式中,Ait为该公司产品的质量,KitαL1itβL2itγ为该公司t期的商品产量,Kit为公司投入的资本,Lit代表公司投入的劳动,L1it为投入到数据的收集、管理、使用、分析等活动的劳动,L2it为除数据相关内容之外的其它劳动。规模报酬递增假设为:
α+β+γ>1(2)
(三)数据要素与技术决策
每一期生产过程中,公司都需要对生产技术做出选择,记作ait,这一选择能够直接影响其产品的质量Ait。其最佳的生产技术假设为θt+εait,其中θt为长期趋势项,仅与时间有关,随着时间推移缓慢变化;εait为瞬时波动项,与具体的时期和公司有关。假设长期趋势项θt随时间的变化符合一阶自回归模型,即:
θt=θ-+ρθt-1-θ-+ηt(3)
式中,θ-和ρ为以递归形式表达的一阶自回归模型的参数,θ-反映θt的整体影响,ρ反映θt-1对θt的影响程度;
随机干扰项ηt遵从均值为μ、标准差为δθ2的正态分布。瞬时波动项εait遵从均值为0、标准差为δa2的正态分布,在不同时期、不同公司之间为独立同分布,并且无法观测获得。
依据前文的假设,当公司所选择的生产技术达到最优时,产品的质量达到最大;选择的生产技术与最优技术相差越远,其产品质量就越差。因此可以用如下的公式来表征这一假设:
Ait=A--[ait-(θt+εait)]2(4)
式中,A-代表当选择的生产技术完全达到最优时产品的质量;所选择技术ait与最优技术(θt+εait)之间的距离的平方代表由于所选技术不够优化所带来的质量损耗。
数据的作用在于能够帮助公司选出更优的生产技术。举例而言,公司通过分析历史市场交易的数据,更好地把握消费者的偏好,从而调整自己不同种类商品的产量,进而获得更高的效益。当然,数据虽然能够揭示出消费者的偏好,但偏好本身随着时间会不断发生变化,公司必须不断积累更多数据,以不断逼近最新、最真实的结果。显然,在该假设下,数据能够提供关于长期趋势项θt的信息,而瞬时波动项εait则为公司基于数据推测θt的过程带来阻碍。
由于数据来自以往的每一次交易活动,因此可以认为,第i个公司在第t期生产后能够获得的数据量为:
nit=ziKitαL1itβL2itγ(5)
式中,系数zi表征了该公司从生产活动中挖掘数据的能力,专业的大数据挖掘公司在该项上显著优于普通公司。对于总数为nit的数据量,每一条数据都对下一期的最优技术选择具有一定的表征能力:
sitm=θt+1+εitm(6)
式中,sitm为第m条数据所揭示的t+1期最优技术选择。为方便后续模型简化处理,认为噪音项εitm也符合正态分布,均值为0、标准差为δ2。
数据作为一种新型的生产要素,具有很强的流动性和可交易性。因此,对于第i个公司而言,其第t期可利用的数据量并不等于自身历史累积的数据量。它还可以通过数据交易从其它公司获得更多的数据。用δit代表第i个公司在第t期内交易的数据量。如果δit>0,表示该公司购入了更多的数据,如果δit<0,表示该公司将自身产生的一部分数据卖出。显然公司不可能售出超过自身数据生产量的数据,即δit≥-nit。每一条数据的价格假设只与时间相关,记作πt。
虽然数据具有可复制性,公司可以一方面使用数据,另一方面也将这些数据出售给其它公司,但这一活动必定是有成本的,否则全社会所有公司都会选择共享全部的数据。不妨用数据交易过程中的损耗代表这一成本,当一家公司向另一家公司出售δit单位的数据后,其数据储量由nit变为nit-ιδit,ι为损耗比例系数。在实际生产活动中,这种数据可以解释为公司由于共享自身数据而受到削弱的相对信息优势。相应地,当一家公司购入δit单位的数据后,其数据储量由nit变为ait+δit。
接下来分析公司利用其拥有的数据进行生产技术决策的过程。对于第i家公司而言,其选择第t期的生产技术ait时所拥有的全部信息来源包括自身从τ=0期到τ=t-1期的产品质量Ait,以及从τ=0期到τ=t-1期所积累的每一条数据所揭示的最优技术选择sitm。这些信息以集合来表示为Γit=[{Ait};{sitm}]。公司基于对Γit的分析,能够得到对于θt的最佳估计E(Γit)。当然这一最佳估计与理想状态下的最优生产技术θt之间还会存在一定差异,二者之差的平方记为对最优生产技术预测的方差,再取倒数即为预测的精度:
Ωit=[E(Γit)-θt]-2(7)
通过以上的分析可以说明,公司对于最优生产技术的预测精度与其数据储备成正比。数据储量越大,其对于未来最优生产技术的预测也越准确,进而产品质量越高。因此在后续分析中,Ωit可以理解为预测的精度,它代表了公司由数据分析所得到的知识量。
当然,对于数据的存储和分析也是需要成本的,既包括新的计算机设备、数据分析领域的专业员工,也包括团队管理方法的改进。如果数据在可交易的情况下还没有调整成本,那么所有公司都会立刻买入最佳数量的数据,这显然是不现实的。不妨假设第i家公司的知识量由Ωit增加到Ωi,t+1后,其用于数据存储分析的成本增加量为:
Φit=φΩi,t+1-ΩitΩit(8)
(四)公司利润与社会总利润
综合以上分析可以得到,第i个公司在t期的总利润为:
Rit=PtAitKitαL1itβL2itγ-Φit-πtδit-rKit
-p1L1it-p2L2it(9)
式中,Pt为单位质量的产品卖出的价格。式子右边第一项代表公司产品出售所获得的利润,第二项代表用于数据存储分析的成本支出,第三项代表交易数据的成本支出,第四、五、六项分别代表用于投资、数据分析人员、非数据分析人员的成本,r、p1、p2为相应的价格系数。
对于第i个公司而言,其目标为基于第0到第t-1期的数据信息Γit估计最优技术θt,进而决定其在第t期的技术选择ait、数据交易量δit、资本投入量Kit、数据分析人力L1it、非数据分析人力L2it,使得公司的长期总利润最大化:
RMAX=max∑∞t=011+rt(PtAitKitαL1itβL2itγ
-Φit-πtδit-rKit-p1L1it-p2L2it)(10)
可见公司的长期总利润目标RMAX取决于其对每一期的技术选择ait、数据交易量δit等的决策。由于本研究重点关注数据要素与经济增长之间的关系,因此还需要将式(10)转换为知识量(即Ωit)的函数。
在前文关于式(7)的分析已经说明,第i个公司在t期对于生产技术的最佳估计为E(Γit)。将其代入式(4)可以得出,第i个公司第t期产品的质量的期望为:
E(Ait)=A--E{[E(Γit)-θt-εait]2}(11)
式中,E{[E(Γit)-θt-εait]2}反映了预报误差平方的期望,也等于(θt+εait)的条件方差。由式(7)和εait的分布假设可知,这一期望值等于Ωit-1+δa2。因此,式(11)可以转换为:
E(Ait)=A--Ωit-1-δa2(12)
结合式(3)、式(8)及前文关于数据交易过程中损耗的假设,可以得到公司第t+1期间的知识量Ωi,t+1与第t期知识量Ωit的关系:
Ωi,t+1=[ρ2(Ωit+δa-2)-1+δθ2]-1+[nit
+δit(1δit>0+ι1δit<0)]δε-2(13)
式中,1δit>0项和1δit<0项的含义为:当下标条件满足时,该项存在且取值为1;否则该项不存在,即取值为0。
接下来考虑数据要素对劳动产出效率和劳动投入成本的影响。已有的研究均表明,数据要素进入经济活动使得公司对于数据分析人才的需求显著提高,专业人力资源的投入既会带来更高的劳动生产效率,同时也会提升公司的人力资源成本。
依据式(1),第i个公司第t期的商品产量为KitαL1itβL2itγ。其中L1it为公司为数据的收集、管理、分析所投入的劳动力。当数据量Ωit为0时,L1it显然也为0。随着数据量Ωit的不断增加,相应的劳动投入L1it也应随之增加。然而当数据量Ωit趋于无穷大时,劳动投入L1it不可能为无穷大,由于数据分析处理本身的规模效应,所需要的边际劳动投入逐渐缩小,最终的劳动投入L1it也趋于一定上限,记为L1i,max。因此,可以用如下的函数形式描述公司所需的劳动投入L1it与当前数据量Ωit的关系:
L1it(Ωit)=Ωit1+ΩitL1i,max(14)
同时,基于前文假设,数据在生产活动中重要性的增加能够提升复杂劳动L1it的生产效率,并使得简单劳动L2it的产出弹性降低;即随着积累的数据量不断增大,β随之增大,γ随之减小。设初始数据量为0时,β=β0,γ=γ0;当数据量趋于无穷大时,β=β1,γ=γ1。构造β、γ与Ωit的依赖方程β(Ωit)和γ(Ωit),使得β(Ωit=0)=β0,β(Ωit=∞)=β1;γ(Ωit=0)=γ0,γ(Ωit=∞)=γ1:
β(Ωit)=(β1-β0)Ωit1+Ωit+β0(15)
γ(Ωit)=(γ1-γ0)Ωit1+Ωit+γ0(16)
将式(8)、(12)、(14)、(15)、(16)代入式(9),得到第i个公司在t期的总利润:
Rit(Ωit)=Pt×A--Ωit-1-δa2×Kitα
×Ωit1+ΩitL1max(β1-β0)Ωit1+Ωit+β0×L2it(γ1-γ0)Ωit1+Ωit+γ0-φ
×Ωi,t+1-ΩitΩit-πtδit-rKit-p1Ωit1+ΩitL1i,max
-p2L2it(17)
由此构建了总利润Rit与来自数据的知识储备Ωit之间的关系模型。同时,结合式(13)给出的Ωi,t+1与Ωit之间的关系,能够实现该模型随时间的递归推演。
以上是对于第i个公司的利润分析,对于N个公司所组成的社会总体而言,社会总利润也将同步发生变化。显然,对于t期的社会总体的资本量KTt、最大数据分析劳动力L1Tt,max、总的其它劳动力L2Tt、总数据量ΩTt,有:
KTt=∑Ni=1Kit(18)
L1Tt,max=∑Ni=1L1it,max(19)
L2Tt=∑Ni=1L2it(20)
ΩTt=∑Ni=1Ωit(21)
在社会总体层面,不妨假设社会上全部N个公司的资本量Ki符合帕累托分布(Paretodistribution),即:
P(Ki>x)=xxmin-m(22)
则由式(17)可得,t期的社会总利润RTt为:
RTt(ΩTt)=∑Ni=1Pt×A--Ωit-1-δa2×Kitα
×Ωit1+ΩitL1max(β1-β0)Ωit1+Ωit+β0×L2it(γ1-γ0)Ωit1+Ωit+γ0-φ
×ΩTt+1-ΩTtΩTt-∑Ni=1πtδit-rKTt-p1ΩTt1+ΩTtL1Tt,max
-p2L2Tit(23)
(五)数据要素促进经济增长数值模拟
1数据储备对公司利润的效用
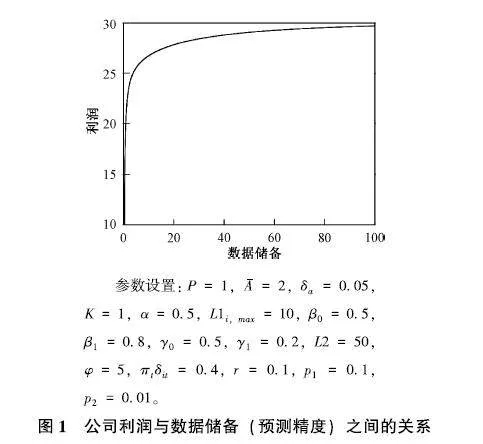
在理论建模中,式(17)得到了公司在t期的总利润Rit与来自数据的知识储备Ωit(同时是代表预测精度的指标)之间的关系模型,下面基于该模型对二者的关系进行数值模拟分析。当固定除了Ωit之外的所有参量,仅考察Rit(Ωit)时,结果如图1。
参数设置:P=1,A-=2,δa=005,K=1,α=05,L1i,max=10,β0=05,β1=08,γ0=05,γ1=02,L2=50,φ=5,πtδit=04,r=01,p1=01,p2=001。
图1公司利润与数据储备(预测精度)之间的关系
由图1可见,随着数据储备Ωit的增加,公司的总利润Rit也随之增加,数据要素的边际产出恒大于0。但是随着Ωit的不断增大,Rit(Ωit)曲线的斜率逐渐减小,说明数据要素的边际回报效率递减。当Ωit逐渐趋于无穷大时,曲线斜率趋于0,Rit也收敛于某个确定的上界。因此,数据虽然对经济增长具有促进作用,但其效用并不是无限大的,即使在充分利用所有数据的前提下做出最优的技术选择,总的商品产出和收益也是固定的最大值,而不能无限增长。
2总数据量对社会总利润的效用
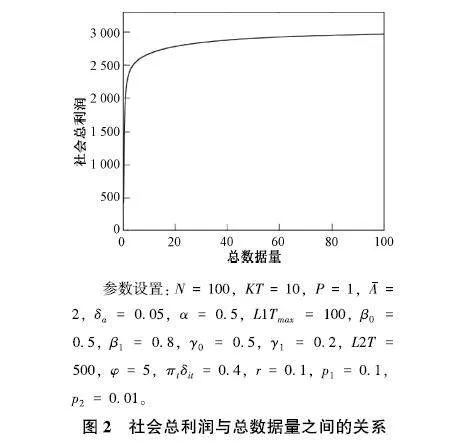
由式(23)可以得到社会总利润RTt与社会总数据量ΩTt之间的数值模拟关系,如图2。
由图2可见,社会总利润随着总数据量的增加迅速上升,到达拐点后增长趋势显著放缓,最终趋于某个上界。说明数据要素作为重要生产要素进入经济活动中后,能够极大地促进经济水平的增长。但这一促进作用并不是无限的,当数据量积累到一定体量后,其对于经济总量的促进作用变得较不明显。同时,数据要素对于经济总量的促进是有上界的,仅靠数据量的积累不可能无限制地提升社会总利润。
参数设置:N=100,KT=10,P=1,A-=2,δa=005,α=05,L1Tmax=100,β0=05,β1=08,γ0=05,γ1=02,L2T=500,φ=5,πtδit=04,r=01,p1=01,p2=001。
图2社会总利润与总数据量之间的关系
3数据要素联通共享对经济增长的影响模拟
生产资料成为生产要素的前提是该资源可以实现大规模的应用,且带来极大的经济价值。数据自古以来就是存在的,它之所以成为生产要素,一个关键的原因在于数字条件下数据急剧增长以及多源数据的联通共享,为数据成为关键生产要素创造了条件。在理论模型中,每个公司在进行生产技术选择时,判断的基础为其掌握的数据。这些数据既包括公司本身在历史经济活动中积累的,也包括公司与其它公司进行数据交易活动所获得的。在本文中,将数据交易量看作数据要素互联共享的替代量,分析数据交易活动对于公司利润的影响,即分析数据要素联通共享对于经济增长的影响。
首先分析数据交易活动对于公司在不同时期所获取的信息量Ωit的影响。式(13)给出了公司t+1期的信息量Ωi,t+1和t期信息量Ωit之间的递归关系。该式中的nit即为公司i在t期生产活动中所获取的数据量,如式(5)所示。δit即为t期与其它公司交易的数据量,ι为公司卖出数据后的损耗系数(0<ι<1)。由于一家公司对数据的买入必然对应着另一家公司对数据的卖出,而卖出的损耗系数ι<1,因此只要存在数据交易活动,必然有E[δit(1δit>0+ι1δit<0)]>0。这也意味着,公司之间的数据交易活动会使两家公司可以利用的总数据量增大。这也是数据作为新型的生产要素,与资本和劳动等传统要素所不同的地方。
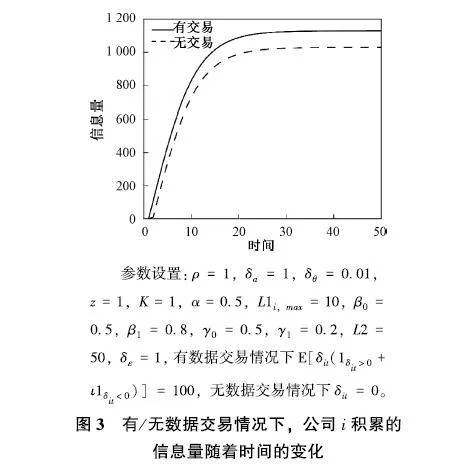
而当公司之间不进行任何数据交易时,δit=0。通过对式(13)的数值模拟,可以比较公司i的信息量Ωit随时间的变化情况,如图3所示。可见,如果公司之间不存在数据交易活动,那么相同时间下,公司i积累的信息量更少,而且其长期平衡态下的信息保有量也会更少。这说明,公司之间的数据交易活动,使每个公司在进行生产技术决策时拥有的信息更加丰富,其产品质量必然也更好。
参数设置:ρ=1,δa=1,δθ=001,z=1,K=1,α=05,L1i,max=10,β0=05,β1=08,γ0=05,γ1=02,L2=50,δε=1,有数据交易情况下E[δit(1δit>0+ι1δit<0)]=100,无数据交易情况下δit=0。
图3有/无数据交易情况下,公司i积累的信息量随着时间的变化
进而,基于式(17),可以比较有/无数据交易情况下,公司i的利润变化情况。结果如图3。由图3可见,在公司之间无数据交易的情况下,公司前期的利润显著小于有数据交易的情况;然而随着时间的积累,公司的利润也将趋于有数据交易情况下的利润。这是由于后期公司的数据积累量已经足够大,使得公司的技术决策已经非常接近最优,因而数据对利润的影响已经不再占主要地位。
三、现实证据
由于数据要素作为新兴要素,具有产权不明晰、价格机制不健全等问题,数据要素的投入、产出缺乏科学严谨的统计。本研究基于全国284个地级市数据要素发展水平展开评价,采用数据要素发展水平指数作为数据要素投入量的替代变量,采用固定效应模型、中介效应模型检验数据要素促进经济增长的作用与科学决策机制。
(一)指标构造与变量选取
1解释变量
模型的作用为检验数据要素发展水平对经济增长的影响,解释变量为数据要素的发展水平Datai,t。本研究选用了2种指标作为其表征,分别是各城市数据要素发展水平得分与数据要素发展程度灰色面积关联度指数。
本文从数据进入生产过程的应用价值出发,采用指数化的思维,聚焦政用价值、商用价值、民用价值3个评价纬度,采用数据要素发展水平得分、灰色面积关联度等评价方法、对地区数据要素的发展水平进行评估,以此作为数据要素的投入依据(见表1)。该评价以284个地级市为研究对象,指标变量数据来源于《中国城市统计年鉴》、各省统计年鉴、各地级市统计年鉴、《中国人口和就业统计年鉴》、中国284个地级市政府官方网站、桔子IT数据库、高德地图、北京大学企业大数据研究中心等,数据要素发展水平指数计算年份截至2020年。
2被解释变量
基准回归模型中的被解释变量为经济增长水平yi,t。本研究采用2013—2020年284个地级市的国内生产总值GDPi,t作为其指标,数据来源于《中国城市统计年鉴》。
3控制变量
本模型还考虑了4类控制变量Xj,i,t,分别为社会零售品销售总额(Retail)、全社会固定资产投资(Invest)、人口密度(Populationdensity)、进出口贸易额(Imexports)。数据来源于《中国城市统计年鉴》、各省市统计年鉴、CEIC数据库等。2018年、2019年、2020年全社会固定资产投资根据增长率计算得出。
4中介变量
本模型的中介变量为科学决策。科学决策是基于独立信息的分析与应用,在多目标导向与比较原则下得出的最优解和等效最优解[24]。科学决策的标准在于以相对小的代价与副作用实现决策目标。基于科学决策的原则与判定标准,本研究以地级市层面为研究单位,拟选取数据要素带来的绿色全要素生产率变化(以最小的环境代价实现最大化的经济收益)为科学决策SDMi,t的替代变量。
SDMi,t=ki,t×GTFPi,t(24)
ki,t=DIZLi,t/ZLi,t(25)
式中,SDMi,t表征科学决策,ki,t为数据要素对GTFP的贡献系数,为数字经济专利占所有专利申请量的比重,GTFPi,t为绿色全要素生产率。GTFPi,t采用数据包络分析法(DEA)、非径向、非角度的基于松弛变量的SBM(SlackbasedMeasure)方向性距离函数测算获得,专利数据来源于国家知识产权局。
(二)实证模型与回归结果
在数据要素影响经济增长的基准回归中,双向固定效应模型(TwowayFixedEffectsModel)既考虑到时间效应又考虑到个体固定效应,考虑到不同时期、不同地区残差的相关性,和传统的固定效应模型相比,该模型得到的估计结果更好,偏误更小。因此,为了消除传统固定效应模型估计所带来的偏误,选取2013—2020年284个城市的数据要素发展水平得分作为解释变量Datai,t,各省国内生产总值GDPi,t作为被解释变量yi,t建立固定效应回归模型:
yi,t=β0+β1Datai,t+∑jγj×Xj,i,t+μi+λt+εi,t(26)
式中,下标i代表城市,下标t代表年份;yi,t为第i个城市第t年的经济增长水平;Datai,t为模型的核心解释变量,代表数据要素的发展水平;Xj,i,t为第j个控制变量,包括社会零售品销售总额(Retail)、全社会固定资产投资(Invest)、人口密度(Populationdensity)、进出口贸易额(Imexports)。μi代表不可观测的地区固定效应,λt代表时间固定效应,εi,t是随机干扰项。
1基准回归结果分析
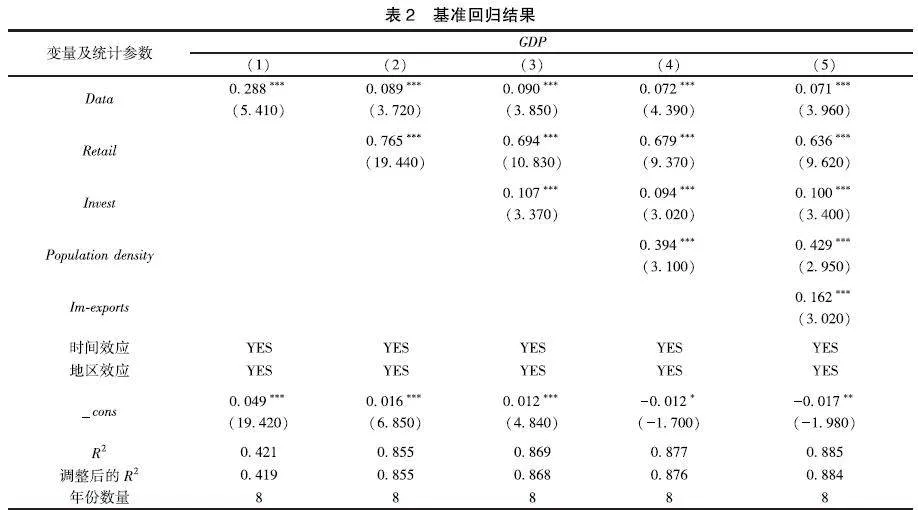
为提高结果的稳健性,在回归过程中逐步增加控制变量的数量,观察不同控制变量数量的情况下数据要素发展水平对经济增长水平的回归系数,检验结果如表2。
其中,第(1)列在控制了年份固定效应与地区固定效应的基础上,仅纳入核心解释变量,回归系数为正,且通过了1%的显著性水平检验,说明数据要素对经济增长具有显著的促进作用。且每提高一单位数据要素发展水平,GDP增长0288。第(2)列在此基础上加入了社会零售品销售总额作为控制变量,核心解释变量的系数依然在1%的显著性水平下为正,再次表明了数据要素对于经济增长的促进作用。以此类推,第(3)、(4)、(5)列分别加入固定资产投资、人口密度、进出口贸易额作为控制变量,数据要素核心解释变量系数依然显著为正,每提高一单位数据要素发展水平,GDP增长0071,结果表明,数据要素促进了经济增长。
控制变量方面,选取社会零售品销售总额、固定资产投资、人口密度、进出口贸易额指标,原因在于“消费、投资、出口”是拉动经济增长的“三驾马车”,劳动作为生产资料投入是实现经济增长的直接原因,实证结果表明,控制变量指标的选取均在1%的显著性水平下拉动了经济增长。
2稳健型检验
进一步利用数据要素发展水平的灰色面积关联度指数作为数据要素发展水平的替代变量,进行稳健性检验。由于灰色面积关联度指数为2013—2020年综合评价结果,所以此检验采用2020年截面数据进行回归分析。对该数据进行多重共线性检验结果表明所有变量VIF值均小于10,MeanVIF值为457,并以1%的显著性水平通过White检验,不存在异方差性。检验结果如表3所示,结果表明,数据要素对经济增长有显著的促进作用,与基准回归结果相一致。
3异质性分析
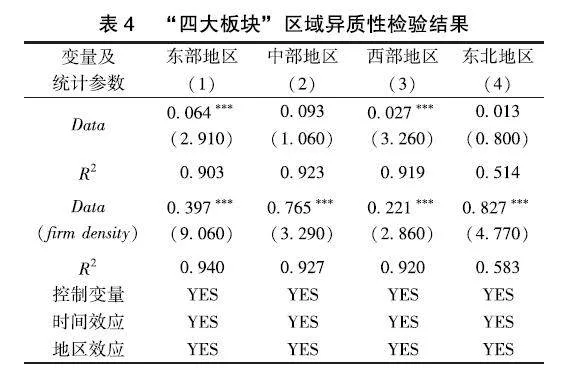
鉴于数据要素发展水平存在较为明显的区域差异,本论文按照地理位置将样本划分为东部地区、中部地区、西部地区与东北地区四大区域①,深入分析数据要素发展水平与经济增长之间的关系,结果如表4。
东部地区和西部地区数据要素发展水平的系数分别为0064和0027,且t值分别为2910和3260,在1%的水平上显著,说明东西部地区的数据要素发展能有效促进经济增长。对于东部地区来说,数字产业基础雄厚、基础设施完善、人才聚集、数字需求旺盛且居民数字化素质总体较高,数字经济带来的新的发展模式已经渗透到生产生活的方方面面,数据要素作用于经济增长有优越的基础条件、环境支持,也就更容易实现数据要素价值的挖掘。对于西部地区来说,数据要素参与经济活动为其提供了“弯道超车”、甚至是“换道超车”的可能性,数据要素的出现可以帮助西部地区在某种程度上克服本身存在的自然缺陷,尽管产业基础相对薄弱、需求不够旺盛,但西部地区的某些自然地理特征(比如气候凉爽)有助于其布局大数据产业,加之政策扶持,数据要素对于促进经济增长效应显著。
以数据要素发展水平评价得分作为数据要素发展水平替代变量的回归中,中部地区与东北地区系数不显著,说明中部地区与东北地区数据要素并未体现出对经济增长的显著影响。中部地区和东北地区在信息化基础与配套方面较为薄弱,相比较东部地区,人才缺乏、数据要素发挥作用的支持体系不够完善,相比较西部地区,又缺乏政策优势。产业数字化转型进程缓慢、需求不够旺等原因导致数据要素对经济增长的促进作用并不显著。综上,数据要素对于经济增长的影响存在显著的区域异质性。
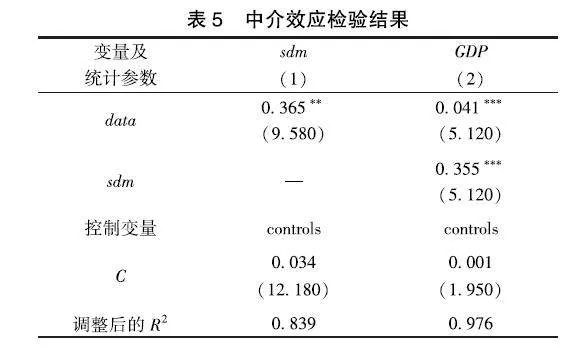
4机制分析
上文研究表明,数据要素可以有效促进科学决策,为进一步明确数据要素检验促进经济增长的作用机制,选用中介效应模型进行分析,实证结果如表5所示。从检验结果来看,数据要素对科学决策呈1%水平下正向显著,将数据要素与科学决策同时放入模型中,如列(2),科学决策对经济增长呈正向显著性作用,且科学决策在数据要素对经济增长的影响中发挥中介效应作用。
四、结论与政策启示
数据要素通过科学决策机制影响经济增长,将数据要素纳入经济增长模型,通过数值模拟与实证检验,得出如下结论:
(1)数据要素可有效促进公司利润与社会总利润的增长,但收敛于某一上界,不能无限增长。随着数据储备的增加,公司的总利润随之增加,数据要素的边际产出恒大于0。但是随着数据储备量的不断增大,数据要素的边际回报效率递降。即使在充分利用所有数据的前提下做出最优的技术选择,总的商品产出和收益也是固定的最大值,而不能无限增长。
(2)长期来看,数据要素进入生产过程前期,公司会快速积累大量的数据,利润也得到显著的提升。但是当数据量达到一定程度之后,利润增长的趋势显著放缓,提升数据储备对于提升利润的作用逐渐变得不明显。
(3)数据联通共享可以使公司前期的利润显著小于有数据交易的情况,在公司发展与上升期具有重要的提升作用。
(4)数据要素发展水平影响经济增长存在显著的区域异质性,东西部地区的数据要素发展能有效促进经济增长,中部地区与东北地区在数据要素促进经济增长作用发挥上不显著;科学决策对经济增长起到部分中介作用。
数据真实准确、充分联通与算力算法支持是数据要素发挥作用的前提条件。当前数据孤岛、产权与数据安全问题突出,严重限制与阻碍了数据要素在经济运行中发挥新动能作用,基于本文研究与当前存在的现实问题,提出以下政策思路与建议:
(1)确保数据真实准确。对于企业由自己业务生成并储存在自有或租赁服务器中的数据,需要在审计环节加强核查,核查内容涉及企业数据生成和数据保管,以及数据转移与数据修改等,此外还需要核查企业所采取的内部控制措施等,保证数据从生成到最终审计的整个过程中不存在可能导致数据被修改的因素或者隐患。对于储存在统一平台上的无数家企业集合的数据,则需要对统一平台的数据生成与管理措施严格监管,在确保企业从统一平台获取数据方式合理合规合法、发行人数据值得信赖的前提下,再进一步分析数据是否具有虚假成分。
(2)促进数据联通共享,打破数据孤岛、数据壁垒,治理数据垄断。实现数据体系建设及数据资源归集,进行数据共享资源池管理;推进数据要素的市场化,以实现社会福利最大化为原则进行数据产权的界定、明确数据资产交易规则;采取多种措施促进数据要素的流通,推动跨区域、跨部门、跨业务的数据共享,建设数据开放平台;打造公正、自由的市场环境,坚持市场在数据资产定价中的基础性作用,规范数据要素市场监管体系,保障市场秩序。
(3)以软硬件协同为手段,保障算力供给、提高算力水平。随着数据复杂性与多样性程度的不断加深,对于算力的要求也不断增强。推动建立完善多层次的算力设施体系是基础,硬件支持下的更高性能的计算资源、存算融合、跨域计算能力共享是核心环节。与此同时,重视相关领域科研人才的培养,比如数据分析人才、数据应用人才等,创新大数据技术,全面挖掘数字经济的潜在价值。
[注释]
①
四大区域的划分按照国家统计局的经济地带划分标准:东部地区包括北京、天津、河北、上海、江苏、浙江、福建、山东、广东和海南;中部地区包括山西、安徽、江西、河南、湖北和湖南;西部地区包括内蒙古、广西、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏和新疆;东北地区包括辽宁、吉林和黑龙江。
[参考文献]
[1]威廉·配第. Ttik8EhHxAkbOqgE47wwh/K+kPxxBUVMTKkFyhSzwSk=;配第经济著作选集[M].北京:商务印书馆,2001.
[2]大卫·李嘉图.政治经济学及赋税原理[M].北京:商务印书馆,1962.
[3]王谦,付晓东.数据要素赋能经济增长机制探究[J].上海经济研究,2021(4):55-66.
[4]张昕蔚,蒋长流.数据的要素化过程及其与传统产业数字化的融合机制研究[J].上海经济研究,2021(3):60-69.
[5]JONESCI,TONETTIC.Nonrivalryandtheeconomicsofdata[Z].NBERWorkingPaper,NO.26260,2020.
[6]王胜利,樊悦.论数据生产要素对经济增长的贡献[J].上海经济研究,2020(7):32-39.
[7]田杰棠,刘露瑶.交易模式、权利界定与数据要素市场培育[J].改革,2020(7):17-26.
[8]徐翔,厉克奥博,田晓轩.数据生产要素研究进展[J].经济学动态,2021(4):142-158.
[9]DALEW,JORGENSON,KHUONGM.TheITrevolution,worldeconomicgrowth,andpalicyissues[J].Telecommunicationspolicy,2016,40(5):383-397.
[10]MUELLERM,GRINDALK.Dataflowsandthedigitaleconomy:informationasamobilefactorofproduction[J].Digitalpolicy,regulationandgovernance,2019,21(1):71-87.
[11]ACQUISTIA,TAYLORC,WAGMANL.Theeconomicsofprivacy[J].Journalofeconomicliterature,2016,54(2):442-492.
[12]VELDKAMPL,CHUNGC.Dataandtheaggregateeconomy[C].Washington:SocietyforEconomicDynamics,2019.
[13]王江容.数据生产要素的统计核算研究[J].河北企业,2022(2):32-34.
[14]戴双兴.数据要素:主要特征、推动效应及发展路径[J].马克思主义与现实,2020(6):171-177.
[15]丁文联.数据竞争的法律制度基础[J].上海法学研究,2020,3(1):352-361.
[16]CARRIERESWALLOWY,HAKSARV.Theeconomicsandimplicationsofdata:anintegratedperspective[R].lMFdepartmentalpapers/policypapers,2019.
[17]EDDD.Whatisbigdata?[EB/OL].[2023-01-24].http://strataoreillycom/2012/01/whatisbigdatahtml.
[18]ERIKB,LMHITT,HELLENKH.Strengthinnumbers:howdoesdatadrivendecisionmakingaffectfirmperformance[Z].SSRNworkingpaper,NO.1819486,2011.
[19]PROVOSTF,FAWCETTT.Datascienceanditsrelationshiptobigdataanddatadrivendecisionmaking[J].Bigdata,2013,1(1):51-59.
[20]MCAFEE,ANDREW,ERIKB.Bigdata:themanagementrevolution[J].Harvardbusinessreview,2012,90(10):60-68.
[21]JANSSENM,VOORTH,WAHYUDIA.Factorsinfluencingbigdatadecisionmakingquality[J].Journalofbusinessresearch,2017,7(1):338-345.
[22]HCHTLJ,PARYCEKP,SCHOELLHAMMERR.Bigdatainthepolicycycle:policydecisionmakinginthedigitalera[J].Journaloforganizationalcomputingandelectroniccommerce,2016,26(1/2):147-169.
[23]COULTONCJ,GOERGER,PUTNAMHORNSTEINE.Harnessingbigdataforsocial good:agrandchallengeforsocialwork[R].Grandchallengesforsocialworkinitiativeworkingpaper,NO.11,2015.
[24]龚代华.科学决策学派:基于独立信息的经济管理模式[M].南昌:江西高校出版社,2021.
TheImpactofDataElementsonEconomicGrowth
—AnalysisofMediationEffectBasedonScientificDecisionMaking
LiuZhiyan,WangQian
(ResearchInstituteforEcocivilization,ChineseAcademyofSocialSciences,Beijing100710,China)
Abstract:Intheeraofdigitaleconomy,dataelementswhichplaytheroleofthebasisofdigitizationandintelligencearekeyproductionfactorstopromoteeconomicgrowth.Dataelementsaffecteconomicgrowththroughassistingmarketplayersinscientificdecisionmaking.Toillustratetheimpactofdataelementsoneconomicgrowththeoretically,thispaperintroducesdataelementsintothetheoreticalmodelofeconomicgrowthandmakesnumericalsimulation.Inaddition,itappliesthepaneldataof284nationalprefecturelevelcitiesandabovefrom2013to2020toverifytheimpactofdataelementsoneconomicgrowthandscientificdecisionmakingmechanisms.Theresultsshowthattheincreaseofdataelementinvestmenthaswitnessedthespurtofthecompany’sprofitandsocialtotalprofitwhichwillstopatacertainlimit.Datasharingcaneffectivelypromotetheeconomicgrowth.Thedevelopmentlevelofdataelementshassignificantlyimprovedeconomicgrowth.However,thereexistsregionalheterogeneity.Atthesametime,scientificdecisionmakingplaysanintermediaryroleineconomicgrowth.
Keywords:dataelements;decisionmaking;economicgrowth
(责任编辑:张积慧)
