基于TRIZ发明原理的专利自动分类方案设计与实现
2024-07-09张玉静
张玉静
关键词:TRIZ发明原理;专利自动分类方案;朴素贝叶斯
0引言
近几年,TRIZ发明原理因其科学性和可操作性而得到广泛关注。作为一种创造性思维方法,TRIZ发明原理可以将一个整体对象或系统分割为较小的部分,同时展示不同技术集成的过程,并深刻揭示创造发明的内在规律。在新时期的专利分析中应用TRIZ发明原理,可以进一步提高科研工作者解决创造发明问题的效率。因此,探讨基于TRIZ发明原理的专利自动分类方案设计与实现具有重要意义。
1基于TRIZ发明原理的专利自动分类方案设计需求
1.1功能需求
TRIZ发明原理通过分割和转换系统问题来解决问题。在设计基于TRIZ发明原理的专利自动分类方案时,首先需要落实TRIZ发明原理的内涵,增加系统问题录入功能。同时,方案应允许普通用户填写相应字段进行提交,提交后自动根据专利名称生成分类词条并进行准确分类[1]。
其次,专利分类方案应具备登录注册、退出登录、增加、删除、修改、查询、权限设置等功能。
最后,方案应提供专利查询入口,允许专利使用者根据个性化需求查询分类结果,并赋予文档生成、下载、打印的权限。
1.2非功能需求
根据发明问题解决的需求,基于TRIZ发明原理的专利自动分类方案应布局清晰、界面简洁、操作便捷。同时,新专利信息录入后,系统应能在短时间内提取专利关键词并反馈结果,且分类页面应能正常跳转,使用端响应时间应短于10秒[2]。
2基于TRIZ发明原理的专利自动分类方案设计方案
2.1基于TRIZ发明原理的专利自动分类方案框架
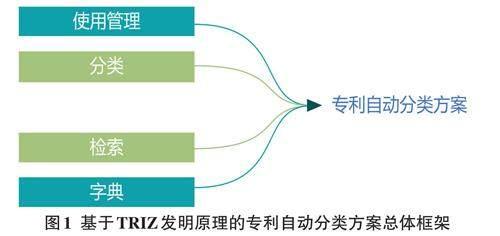
根据方案的功能需求和非功能需求,基于TRIZ发明原理的专利自动分类方案可以划分为使用管理模块、分类模块、检索模块、字典模块几个部分,整体框架如图1所示。
图1中,使用管理模块主要负责满足专利发明者和专利信息使用者的不同需求;分类主模块包括特征词提取和类别划分两个核心功能;检索模块可分为精确检索和任意检索;字典模块主要负责专利信息分类管理。
在总体框架内,可以以NB(NaiveBayes,朴素贝叶斯)为支撑,基于贝叶斯定理,将专利自动化分类问题视为基于贝叶斯公式的专利文本所属类别条件概率估计。即:根据已知的特征和类别,进行待分类专利文本所属类别概率的核算,公式如式(1):
式中:P(c|x)为专利文本内每一特征属于类别的概率;x为类标号未知的专利样本;c为专利所属类别。c为一个集合,具体为{c1,c2,...,cm},表示c共有m个类别。P(x|c)为某一类别属于特征的概率;P(c)为专利文本全部类别概率;P(x)为某一专利文本样本概率。根据式(1),可以将待分类专利归类到与其关系最紧密的类别,求解向量归属特定类别的概率P,概率最大的类别为对应专利所属类别。
2.2基于TRIZ发明原理的字典设计
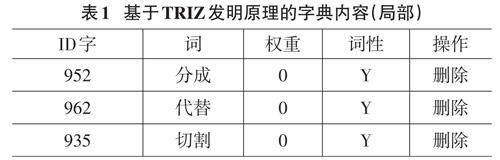
字典设计是准确切分表征TRIZ发明原理特征词(专利文本内)的前提。在基于TRIZ发明原理的字典设计时,可以先参考TRIZ发明原理及应用书籍,准备TRIZ发明原理的经典描述、每一发明原理下的案例描述,再利用已标注发明原理的海量专利,为特征词切分做好准备。最终,面向以TRIZ发明原理为基础的字典,借助人工识别手段,加入表征发明原理特征词。局部字典内容如表1所示。
后期,根据专利信息扩充要求,可以借助网页抓取的方式,进入国家知识产权局的网站,由服务器端下载URL(UniformResourceLocator,统一资源定位符)对应内容到本地,并记录URLHTTP请求对应编码数据,顺利采集新领域大量专利特征词,实现基于TRIZ发明原理的字典内容不断更新。
2.3基于TRIZ发明原理的训练集构建
文本分类训练是基于TRIZ发明原理的专利自动分类的基础,主要依靠已标记类别的训练测试数据集。在训练数据集构建前,由专人采集专利文献,分析下载专利文献页面标题、权利要求、摘要等文本数据,初步明确分词[3]。明确分词后,以基于TRIZ发明原理的字典为依据,抽取特征,完成特征向量化处理,并获得训练数据集。在获得训练数据集后,以标记为类别不一的数据集为对象,借助两两组合的手段,进行一个向量矩阵的合并处理。在向量矩阵中,将第一列定义为标签列,标记每一篇专利向量化结果所在行,同类标记、另一类标记分别为1、-1。最终,将打上标签的向量矩阵保存为.xls格式文件。
基于TRIZ发明原理的训练集具体设计过程如下:
1)输入jieba(结巴分词)库,导入分词工具。同时打开已筛选的特征词文件并读取,将文件存储为字符串形式。进而正则化筛选特征词文件内词语,选中全部特征词后连接,并对特征词进行去重处理。
2)选中全部基于TRIZ发明原理的特征词,导入创建Excel表格库。在库内新建工作簿和一个表格,将表格命名为0,遍历全部特征词,将所遍历的特征词写入表格。
3)选中专利文本并打开,读取文件,将文件存储为字符串形式。同时正则化选择专利文件内文本内容,以专利文本内容分词为对象,连接分词后词语,对分词后词语进行去空格处理。去空格后,在文本列表内存储分词后词语[4]。
4)遍历分词后全部专利文本内容(含词语),根据每一篇文章对应列表,对比专利文本分词训练结果、字典特征向量。若特征词位于专利文本内,则在表格中写入1;若专利文本未包含特征词,则在表格中写入0。
5)在Excel表格中保存全部专利文本数据。
3基于TRIZ发明原理的专利自动分类方案实现措施
3.1实现环境
基于TRIZ发明原理的专利自动分类方案实现语言为Java语言。实现环境为安装JDK(JavaDevelop?mentKit,Java语言的软件开发工具包)的PC机,操作平台为Windows10,操作平台中已安装Tomcat7.0,数据库为JDBC数据库连接池连接技术支撑的MySQL关系型数据库,工具为MyEclipse8.5,浏览器为谷歌浏览器[5]。环境后台、前台分别为SSM框架、EasyUI框架,以JavaServlet、JSP与JavaScript、HTML技术为支撑。
3.2实现流程
基于TRIZ发明原理的专利自动分类方案实现流程如下:
第一,中文专利自动分类主要是恰当选择专利中的几个成分组合(权利要求、标题、摘要、说明等)作为输入。输入优选可体现专利中包含TRIZ发明原理的信息,如选择输入为标题、摘要,避免因选用成分过多而影响分类结果准确性。同时因中文句子内各词条间无分隔符,在分类器分类前,需借助基于HMM(Hi?erarchicalHiddenMarkovModel,多层隐马模型)的ICTCLAS(InstituteofComputingTechnology,ChineseLexicalAnalysisSystem,中科院计算所中文信息处理系统)分词系统,开展专利摘要词条切分。切分须先后经历“建立切分词图”“词语粗分获得若干概率最大切分结果”“角色标注识别计算概率”“加入未登录词”“动态规划优选切分结果”几个环节,最终完成分词。
第二,完成分词后,针对专利文本内存在大量仅发挥语法作用的词,参考《现代汉语语料库文本分词规范》,借助哈希表建立一个停用词列表,汇总停用词,如“新型”“发明”“领域”等实意词和“然后”“最终”等非实意连词[6]。在每次中文专利查询时,自动搜集哈希表,及时发现、删除停用词表对应词,降低向量空间维数。若为英文专利样本,可以免除分词、去停用词环节,直接利用专利文本中英文分隔符,进行特征选取。
第三,在停用词删除后,针对专利文档内无法辅助类别区分的词条,由低层次出发,进行高层次正交维数特征集的构造。构造方法可选择基于概率的交叉熵法,其公式为:
式中:CE(t)为词汇的交叉熵;t为词汇;P(ci|T)为真实分布中c类别的概率;T表示模型预测分布中c类别的概率;P(ci|t)表示文本主题类分布概率;ci表示某一类别专利的数量;log为以2为底的对数。CE(t)是文本主题类概率分布、出现特定词汇下主题类概率分布之间距离的彰显,词汇交叉熵与文本主题类分布所受干扰成正比。
第四,选取词汇交叉熵较大的特征后,可以在NB(Na?veBayes,朴素贝叶斯)分类器内进行专利分类。最终建立近千条发明数据集,从数据集中提取百余可标示所使用TRIZ发明原理的专利,显示为分类选择组合框,在选择测试文本时,自动进行专利分类并输出分类结果(含分类器性能评价),整体界面较为直观、简洁。
3.3质量评估
基于TRIZ发明原理的专利自动化分类质量评估与传统评估方法存在较大差异。传统专利分类效果评估为单一样本分类,以专利被标注单一标签是否有误为判断依据[7]。而在TRIZ发明原理支撑的专利自动化分类质量评估中,一个专利可能对应多个TRIZ发明,即一个标签集合,集合内存在部分有误或无误的标签,甚至存在隐藏标签。因此,在专利自动分类质量评估时,可以分类器为对象,核算真实TRIZ发明原理集合、预测TRIZ发明原理集合的差异。
考虑预测错误、遗失错误,以海明损失评估样本TRIZ发明原理被错误划分类别的概率。在海明损失等于0时,样本分类取得最佳效果;海明损失越小,专利自动分类效果越佳。同时将全部分类的正确专利文本、实际专利文本的文本数之比作为准确度评估依据,将全部分类正确的文本与应有专利文本数量之比作为召回率评估依据。在已有条件下,依托基于MODEL-x的多标签名分类模式,对方案进行测试,确定方案应用效果。在发明数据集标示专利数量为688个时,分类准确率达到0.73,分类召回率达到0.65,基本满足中文专利分类要求。
4结束语
综上所述,专利文献是全球最大最新技术信息源,对专利信息进行分类是信息利用的前提条件。TRIZ发明原理是一种解决发明创新问题的系统方法学体系,可以加快专利分类方案优化。因此,可以构建基于TRIZ发明原理的字典和分类器,梳理基于TRIZ发明原理的专利分类流程,有序推进分词、去停用词、特征提取、分类、测试等环节,顺利实现专利文档类别划分的自动化。
