基于YOLOv7的边缘增强水面漂浮垃圾小目标检测
2024-07-01周华平李云豪党安培
周华平 李云豪 党安培


【摘 要】 水面漂浮垃圾不断增多引起关注,针对水面漂浮垃圾边缘信息模糊的问题,提出E-MP模块,在MPConv的基础上添加Laplacians,Sobel-dx和Sobel-dy增强小目标水面漂浮垃圾的边缘信息。针对小目标漂浮垃圾仅占据图像少量像素的现象,引入了Biformer注意力模块。Biformer利用前后两个方向的上下文信息,更好地捕捉序列中的依赖关系,同时降低背景信息对检测目标物体带来的一部分影响。在此基础上引入SIoU来构建损失函数,将边界区域作为目标区域来进行加权,可以更好地捕捉目标的边界信息,从而提高检测精度。在Flow-Img子数据集上进行了大量实验,实验结果表明,YOLOv7-edge模型比原来的模型检测精度更高,mAP@0.5和mAP@0.5:0.95分别提高了7个百分点和5个百分点。
【关键词】 小目标;垃圾检测;E-MP模块;Biformer注意力模块;SIoU
Edge Enhanced Small Target Detection of
Floating Garbage Based on YOLOv7
Zhou Huaping, Li Yunhao*, Dang Anpei
(Anhui University of Science and Technology, Huainan 232001, China)
【Abstract】 The increasing amount of floating garbage on the water surface has attracted people's attention. In response to the problem of blurred edge information of floating garbage on the water surface, this article proposes an E-MP module, which adds Laplacians, Sobel-dx, and Sobel-dy to enhance the edge information of small floating garbage targets on the water surface based on MPConv. In response to the phenomenon that small floating garbage targets only occupy a small number of pixels in the image, a Biformer attention module has been introduced. The Biformer utilizes contextual information from both the front and back directions to better capture dependencies in the sequence while reducing some of the impact of background information on detecting the target object. On this basis, introducing SIoU to construct a loss function and weighting the boundary region as the target region can better capture the boundary information of the target and improve detection accuracy. A large number of experiments are conducted on the Flow-Img sub dataset, which shows that the YOLOv7 edge model had higher detection accuracy than the original model, mAP@0.5 and mAP@0.5 0.95 increased by 7 % and 5 % respectively.
【Key words】 small goals; garbage detection; E-MP module; Biformer attention module; SIoU
〔中图分类号〕 TP183 〔文献标识码〕 A 〔文章编号〕 1674 - 3229(2024)02- 0045 - 07
[收稿日期] 2023-10-09
[作者简介] 周华平(1979- ),女,博士,安徽理工大学计算机科学与工程学院教授,研究方向:目标检测。
[通讯作者] 李云豪(1999- ),男,安徽理工大学计算机科学与工程学院研究生,研究方向:目标检测。
0 引言
水面漂浮垃圾检测是目标检测的一种。目标检测是在图像或视频中准确地识别和定位特定的目标物体[1],在许多领域中都有广泛的应用[2],如自动驾驶、视频监控等。目标检测需要确定目标物体的位置,并用边界框或像素级的分割来标记目标的准确位置。因此,目标检测算法需要具备对目标识别和定位的能力。
目标检测算法的发展经历了多个阶段。早期的算法在复杂场景中的性能有限,随着深度学习的发展,Krizhevsky 等[3]使卷积神经网络重焕光彩,开创了现代CNN的先河。其中,最具代表性的算法是基于区域的卷积神经网络(R-CNN)系列算法,包括R-CNN、Fast R-CNN、Faster R-CNN等。这些方法通过将目标检测问题转化为候选区域生成和目标分类/定位两个子问题,大大提高了目标检测的准确性和效率。
相比于其他领域的目标检测,小目标检测的发展时间相对较短,仍有许多方面尚未完善。小目标的定义有很多种,MSCOCO通用数据集将分辨率小于32*32像素的目标定义为小目标。2016年Chen等 [4]将占总目标帧面积0.05%~0.58%的同类目标定义为小目标,开创了小目标检测的先例。2018 年Han等[5]第一次提出了把R-CNN用于遥感小目标的检测。在此文献的影响下,很多研究人员以Faster R-CNN[6]、SSD[7]以及 YOLO等网络模型对小目标物体进行检测。其中Han等[8]、Zand等[9]、Yu等[10]使用旋转预测框和旋转检测器来提高遥感检测场景的精度,但对其他类型的小目标的效果并不好。在这种背景下,Zhu等[11]提出增加目标检测层,在检测小目标方面得到了良好的结果。但在目标较小且密集的情况下,还有漏检和误检的情况,YOLO-Z的PAFPN被Bi-FPN取代,提高了小目标的检测效果,但忽略了图像中较大目标的问题。
为 解 决 上 述 问 题 ,本 文 提 出 一 种 YOLOv7-edge模型。通过增加边缘信息更加准确地找到水平边缘。引入注意力机制加强对信息的筛选,提高模型的泛化能力和解释能力。最终通过改进损失函数,提高网络对于目标尺寸的鲁棒性。
1 相关工作
1.1 YOLOv7 模型
YOLOv7[12]是一种目标检测模型,通过将目标检测问题转化为一个回归问题,直接在图像上进行目标定位和分类,从而实现快速高效的目标检测。YOLOv7快速且准确的检测受到广泛关注。模型如图1所示。
YOLOv7是由Wang等[12]于2022年提出的,主要包括Backbone层(由卷积、E-ELAN模块、MPConv模块以及SPPCSPC模块构成)、Neck层(采用了传统的 PAFPN 结构,在不同层级上进行特征融合,从而提取多尺度的特征)和Head层(由多个卷积层和全连接层组成,用于对特征进行处理和转换,并输出目标的位置和类别信息)。与其他模型相比,YOLOv7的设计更加简洁和高效,可以在处理大规模数据时保持较高的速度和精度。
1.2 注意力机制
注意力机制[13-14]是一种计算模型,它模拟人类的注意力过程,使得模型能够聚焦于输入数据中最重要的部分。注意力机制已经被广泛应用于提高模型的性能。在注意力机制中,较高的权重意味着该部分对模型的输出有更大的影响力。模型可以根据输入数据的不同部分来调整其关注的重点,这使得模型能够更好地理解输入数据的结构和语义,提高模型的性能和泛化能力。
经过多次试验发现,YOLOv7模型在提取水面漂浮垃圾小目标的浅层纹理和轮廓数据方面没有取得理想的结果,容易导致信息丢失,并显著影响小型物体的检测。因此本文引入了一个对小目标有效的注意力机制。
1.3 IoU 损失函数
IoU是目标检测中常用的衡量指标,计算预测框和真实框的交并比。但是,IoU只考虑了两个框之间的重叠程度,没有考虑到框的位置、大小等因素。GIoU[15]引入了框的全局信息,解决了IoU的不足。在一些情况下,预测框与真实框之间的距离也是很重要的因素,因此,DIoU[16]在GIoU的基础上引入了框的距离信息。最后,CIoU在DIoU的基础上进一步考虑了框的长宽比例的影响。其中,CIoU公式中[α]是一个可调参数,v表示预测框和真实框的长宽比例的差异。
2 YOLOv7 目标检测模型的改进
2.1 E-MP模块
MPConv 模块(如图2所示)的作用是进行多尺度特征融合和信息传递。MPConv 模块是一种多尺度卷积模块,在目标检测任务中,需要对不同尺度的特征进行融合和利用,以提高检测性能。MPConv在特征提取过程中采用的最大池化操作,会将小目标的特征图压缩成较小的尺寸,从而导致小目标的细节信息丢失,难以准确地进行检测和识别。MPConv在进行特征提取时采用固定大小的池化窗口,无法适应小目标的尺度变化,因此在小目标的检测和识别过程中容易出现漏检或误检的情况。本文在MPConv的基础上增加了Laplacians算法来增强小目标的边缘信息,然后再通过Sobel-dx和Sobel-dy计算图像中每个像素点的水平梯度值来检测图像中的水平边缘。本文提出的用来增强水上目标边缘的E-MP模块如图3所示。
2.2 Biformer注意力机制
Biformer[17-18]注意力机制(如图4所示)称为BiAttention。BiAttention在BERT自注意力机制上添加一个相互注意力机制,在文献[19-20]的基础上应用BRA模块和2层扩展比为e的MLP模块进行跨位置关系建模和逐位置嵌入,其核心思想是将Transformer模型的编码器和解码器结构相结合,以实现双向的信息流动,BiformerBlock包含了两个注意力机制:正向注意力和反向注意力。正向注意力用于从左到右处理输入序列,而反向注意力则从右到左处理输入序列。这样,模型可以同时利用前后两个方向的上下文信息,从而更好地捕捉序列中的依赖关系。
2.3 损失函数
本文用SIoU损失函数替换了原模型中的CIoU损失函数,考虑了角度问题。其中b表示预测框,bgt表示真实框,c表示预测框和真实框的最小闭合区域的对角线距离,[α]是平衡参数,用于衡量长宽比是否一致。添加角度成本可提高检测精度,如图5所示。
判断使用 [β] 还是[α]是通过和45°的比较,角度成本的计算如式(1):
[∧=1-2×sin2(arcsinx-π4)] (1)
SIoU损失函数对分割结果进行了平滑处理,可以减少分割结果的噪声和不连续性,减少了真实框和预测框之间的距离,如式(2):
[Δ=t=x,y(1-e-γρ)] (2)
SIoU只关注两个形状的重叠部分,而不考虑它们的位置和大小。因此,无论形状在图像中的位置和大小如何变化,SIoU都可以正确地衡量它们之间的相似度。形状成本[Ω]的定义如式(3):
[Ω=t=w,h(1-e-ωt)θ] (3)
损 失 函 数 的 最 终 定 义 如 式(4):
[LSIoU=1-IIoU+Δ+Ω2] (4)
总的来说,SIoU损失函数适用于目标检测任务,具有尺度不变性、对称性、可导性和相似度度量等特点。改进后的模型图命名为YOLOv7-edge,其中深色模块为改进部分,如图6所示。
3 实验结果与分析
3.1 实验环境与参数设置
网 络 实 验 环 境 为 Win10、Python3.8 和PyTorch1.12.1,相关硬件配置和模型参数如表1 所示,其中训练数据量为 300。
3.2 评价指标
本实验主要由准确率、召回率、平均准确率(AP)、平 均 精 度 均 值(mAP)4个指标在相同实验环境下的漏检和误检情况来评判,计算公式如下:
[P=TTPTTP+FFP×100%] (5)
[R=TTPTTP+FFN×100%] (6)
[AP=01P(R)dR] (7)
[mAP=i=1kAPik] (8)
准确率用[TTP]表示;错误率用[FFP]表示,错误包含误检和漏检两种情况,误检情况用[FFN]表示;其中P 表示准确率,R 表示召回率。P-R 曲线与坐标轴围成的面积为 AP 值大小。一般情况下网络模型性能的评价指标是所有类别的 AP 值的平均数mAP。
3.3 实验数据集
FloW-Img 子数据集是全球第一个水面漂浮垃圾真实影像数据集,图像数据集包含2000张图像,其中包含5271个标记的水面漂浮垃圾。训练集和测试集采用6:4的划分,用1200张不经过筛选的图像作为训练集,其余的自动成为测试集。
由整个数据集、训练集和测试集在一帧内的对象数量和标记对象占用面积的分布情况可以看出,不同大小的目标在训练数据和测试数据中的分布近似匹配。小目标(面积< 32 × 32)在本文数据集中所占的比例最大,这使得检测更具挑战性。数据集示例如图7所示。
3.4 消融实验
本文针对以下 3 种情况对E-MP模块的位置进行了实验,情况1在Backbone中替换MPConv模块,情况2在Neck中替换MPConv模块,情况3在Backbone和Neck中替换MPConv模块,实验结果如表 2 所示。其中,mAP@0.5 和 mAP@0.5∶0.95 分别表示 IoU=0.5、0.5≤IoU≤0.95 时各个类别的平均 AP 值。
注意力模块的添加对小目标检测的信息提取也有很大的作用,不同模块对目标检测会产生很大的影响。为了使BiFormer提取更充足有效的信息,分别在E-ELAN模块、SPPCSPC模块、REP模块中进行实验,实验结果如表 3 所示。
3.5 YOLOv7 网络模型与改进网络模型实验对比
对水面漂浮小目标检测得出的 P-R 曲线对比如图8所示。改进后的 YOLOv7-edge网络模型在水面漂浮垃圾小目标数据集的检测中表现了良好的性能,检测目标的 AP 值比改进前网络模型和ACAM-YOLO模型(对小目标检测有利的网络模型)提高了很多。
本文针对实际情况中水面漂浮垃圾小目标图像、水面漂浮垃圾超小目标图像和水面漂浮垃圾密集超小目标图像这三种类型的图片,对原网络模型进行了改进。改进后的模型在检测这些具有代表性的水面漂浮垃圾小目标方面表现出色,有效解决了水上漂浮垃圾检测问题。对比图如图9至图11所示。
3.6 改进YOLOv7网络模型与其他网络模型的对比
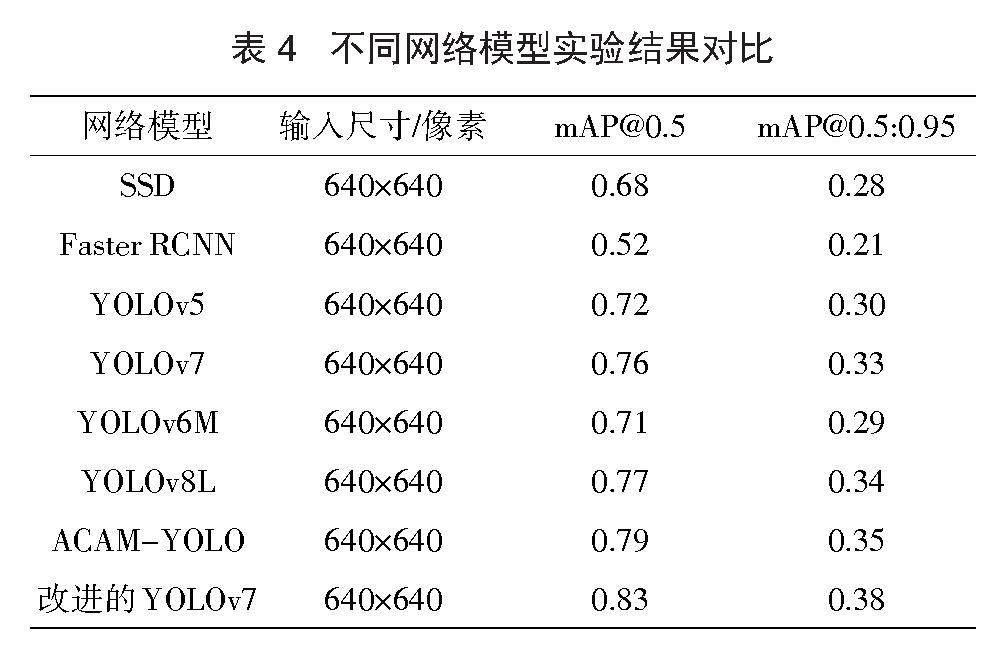
在相同环境、训练参数和配置下,将经典网络和一些对小目标检测有益的模型与YOLOv7-edge进行比较,结果表明本方法在水面漂浮垃圾检测方面表现出有效性。mAP@0.5和mAP@0.5:0.95指标均取得了一定的提升,如表4所示。
4 结论
针对水面漂浮垃圾边缘信息模糊的问题,本文提出了一种基于YOLOv7的边缘增强模型,首先通过本文提出的E-MP模块,增强了小目标的边缘信息,其次在SPPCSPC模块中引入Biformer注意力机制加强底层信息的提取,最后通过对IoU损失函数进行优化,减少了误检和漏检。实验表明改进后的模型与原有的模型相比检测精度有了很大的提升,对水面漂浮垃圾治理有一定的实际意义。
[参考文献]
[1] 戚玲珑,高建瓴. 基于改进YOLOv7的小目标检测[J]. 计算机工程,2023,49(1):41-48.
[2] 谷永立,宗欣欣. 基于深度学习的目标检测研究综述[J]. 现代信息科技,2022,6(11):76-81.
[3] Girshick R,Donahue J,Darrell T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[A]. Proceedings of the IEEE conference on computer vision and pattern recognition[C]. Washington D.C.,USA:IEEE Press,2014:580-587.
[4] Chen C,Liu M Y,Tuzel O,et al. R-CNN for small object detection[A]. Proceedings of IEEE International Conference on Computer Vision[C]. Washington D.C.,USA:IEEE Press,2016:214-230.
[5] Hu G,Yang Z,Han J,et al. Aircraft detection in remote sensing images based on saliency and convolution neural network[J]. EURASIP Journal on Wireless Communications and Networking,2018(2018):1-16.
[6] 赵加坤,孙俊,韩睿,等. 基于改进的Faster Rcnn遥感图像目标检测[J]. 计算机应用与软件,2022,39(5):192-196+290.
[7] 贾可心,马正华,朱蓉,等. 注意力机制改进轻量SSD模型的海面小目标检测[J]. 中国图象图形学报,2022,27(4):1161-1175.
[8] Han J,Ding J,Xue N,et al. Redet: A rotation-equivariant detector for aerial object detection[A]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C]. Washington D.C.,USA: IEEE Press,2021: 2786-2795.
[9] Zand M,Etemad A,Greenspan M. Oriented bounding boxes for small and freely rotated objects[J]. IEEE Transactions on Geoscience and Remote Sensing,2021,60(5): 1-15.
[10]Yu D,Xu Q,Guo H,et al. Anchor-free arbitrary-oriented object detector using box boundary-aware vectors[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2022,15: 2535-2545.
[11] Zhu X,Lyu S,Wang X,et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[A]. Proceedings of the IEEE/CVF international conference on computer vision[C].Washington D.C.,USA: IEEE Press,2021: 2778-2788.
[12]Wang C Y,Bochkovskiy A,Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[A]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C]. Washington D.C.,USA: IEEE Press,2023: 7464-7475.
[13]Niu Z,Zhong G,Yu H. A review on the attention mechanism of deep learning[J]. Neurocomputing,2021,452: 48-62.
[14]Brauwers G,Frasincar F. A general survey on attention mechanisms in deep learning[J]. IEEE Transactions on Knowledge and Data Engineering,2021,35(4): 3279-3298.
[15] Zhou D,Fang J,Song X,et al. Iou loss for 2d/3d object detection[A]. 2019 international conference on 3D vision (3DV)[C]. Washington D.C.,USA: IEEE Press,2019: 85-94.
[16]Zheng Z,Wang P,Liu W,et al. Distance-IoU loss:faster and better learning for bounding box regression[J]. Artificial Intelligence,2020,34(7):12993-13000.
[17]Chu X,Tian Z,Wang Y,et al. Twins: Revisiting the design of spatial attention in vision transformers[J]. Advances in neural information processing systems,2021,34: 9355-9366.
[18]Zhu L,Wang X,Ke Z,et al. BiFormer: Vision Transformer with Bi-Level Routing Attention[A]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C]. Washington D.C.,USA:IEEE Press,2023:10323-10333.
[19]Dong X,Bao J,Chen D,et al. Cswin transformer: A general vision transformer backbone with cross-shaped windows[A]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C]. Washington D.C.,USA: IEEE Press,2022: 12124-12134.
[20]Liu Z,Lin Y,Cao Y,et al. Swin transformer: Hierarchical vision transformer using shifted windows[A]. Proceedings of the IEEE/CVF international conference on computer vision[C]. Washington D.C.,USA: IEEE Press,2021:10012-10022.
