基于最小二乘支持向量机的电网企业供应链碳排放预测方法研究
2024-06-13卞龙江李俊颖胡承鑫徐友刚周晓斌
卞龙江 李俊颖 胡承鑫 徐友刚 周晓斌
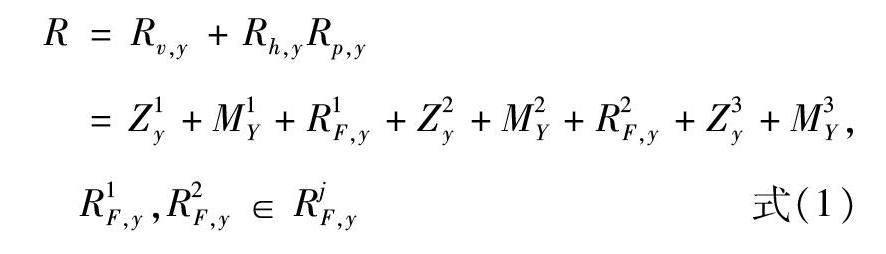

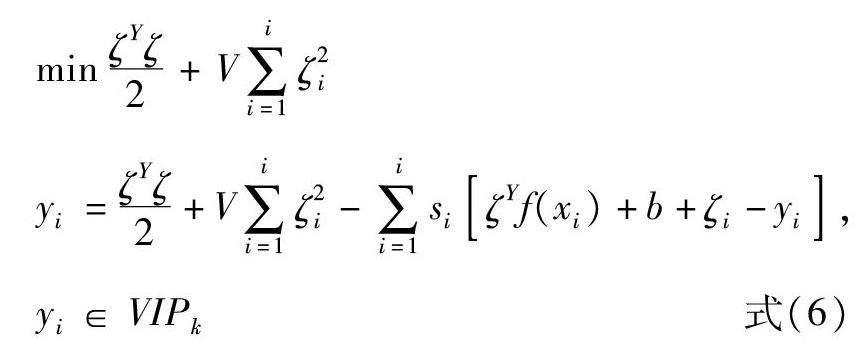
摘要:电网企业供应链碳排放的预测对推动产业链供应链绿色转型具有重要意义,为此提出基于最小二乘支持向量机的电网企业供应链碳排放预测方法。首先,利用4E平衡模型获取电网企业供应链碳排放数据;其次,利用PLS-VIP算法对碳排放数据实施数据筛选,得到有效的碳排放数据变量;最后,引入最小二乘支持向量机,构建碳排放预测模型,并且采用量子粒子群优化算法对其展开优化,实现电网企业供应链碳排放高精度预测。实验结果表明,所提方法在保证预测过程较高稳定性的同时,一定程度上提高了预测精度和预测效率。
关键词:最小二乘支持向量机;4E平衡模型;PLS-VIP算法;数据筛选;碳排放预测模型
中图分类号:X32 文献标志码:A
前言
在面对严峻的全球变暖和环境污染问题,电网企业作为供应链核心企业,承担着减少碳排放、推动低碳发展的重要责任。因此,对电网企业的碳排放量进行准确预测和评估至关重要。有效的碳排放预测方法可以为制定低碳发展战略、实施节能减排政策提供科学依据,助力电力部门迈向更加环保、可持续的发展方向。通过深入研究和应用先进的碳排放预测技术,电网企业可以更好地管理和监控其碳排放,为应对全球变暖挑战贡献自身的力量。因此,相关学者针对碳排放预测问题进行了深入研究,如苏琪2等人以历史电网企业供应链碳排放数据为依据,将帝王蝶优化算法引入到一种灰色预测模型中,完成碳排放关键因素GM(1,1)发展系数和灰作用量的寻优过程,提高模型精度,以此实现对电网企业供应链碳排放的预测。该方法的关键参数寻优过程较长,降低碳排放预测效率。为了解决上述方法中存在的问题,提高碳排放预测效率和精度,提出基于最小二乘支持向量机的电网企业供应链碳排放预测方法。该研究以最小二乘支持向量机为核心算法,利用4E平衡模型获取电网企业供应链碳排放数据,结合PLS-VIP算法,构建了电网企业供应链碳排放预测方法。以期通过该方法有效预测电网企业供应链碳排。
1 电网企业供应链碳排放相关数据预处理
1.1 数据获取
供应链碳排放量是电网企业供应链碳排放预测过程所需的主要数据,与能源需求和碳排放密切相关,为此所提方法首先采用一种4E平衡模型计算上述2个模块数据,以建立电网企业供应链碳排放数据库,具体过程如下:
根据其发电效率,将煤电和气电折算为碳排放能源标准量,以此得到发电用化石能源RjF,y=Fjyφ,其中Fjy所形容的是在y年内j种能源的发电量,且j=1,2,3,φ代表发电量转换系数。将RjF,y与终端消耗化石能源作加法运算求出化石能源消费总量,计算方法如式(1):
式(1)中,Rv,y、Rh,y、Rp,y是在第y年煤炭、天然气和石油的消费总量;Mjy是在第y年终端化石能源消耗总量;Zjy描述能源加T转换损失量。利用IPCC提供的能源碳排放系数求出供应链碳排放总量。能源相关碳排放总量的关键是碳排放系数,在此基础上将其与不同类化石能源消费量相乘,求得能源相关碳排放总量如式(2):
V=R[γv,γh,γp]T 式(2)
式(2)中,γv、γh、γp为不同能源的碳排放系数,T为转置。由此得到电网企业供应链碳排放量数据库。
1.2 数据筛选
上述碳排放数据库存在较多冗余数据,影响碳排放预测精度,为此筛选数据。PLS-VIP是一种通过计算变量的VIP值得到变量重要度的变量选择方法,具体过程如下:
假设在上述收集到的碳排放数据库中样本数量为m,m中含有表征供应链碳排放量的因变量u以及q个自变量,用C和U描述m×q零均值自变量矩阵与mx1因变量矩阵,分别为C=YAy(V)+R、U=IWY(y)+G,以此为依据将两者相结合后整体区分为1个外在关系式以及2个内在关系式,数学表达为I=nY+r,其中,Y是矩阵C的得分,I是矩阵U的得分,且Y≠/;A和W所代表的是载荷矩阵;R和G是通过PLS回归拟合后获取到的矩阵C和U的残差;n和r是潜变量回归系数以及PLS回归残差。将上述获取的数据引入低维数据空间,筛选碳排放数据自变量,过程为:
(1)考虑不同因子引发干扰,自然对标准化处理样本数据,生成标自变量矩阵C=[*ok]和因变量矩阵U=[u*o];
(2)建立PLS回归模型,采用解释性检验法以及留一法(LOO)交叉检验法对模型中的最佳潜变量数展开提取;
(3)构建权值向量eo=CYu/||CYU||,且||eo||=1;
(4)根据权值向量e。求出潜变量yo=Ceo,并使其与U的协方差最大,满足条件如式(3):
式(4)中,q和l代表提取的自变量个数以及潜变量个数;ζjk表示ck在潜变量yj上的权重,且∑qk=2ζ2jk=ζYjζj=1;tj(U;yj)表示第j个潜变量的得分矢量yj矩阵U间的相关系数,且tj(U;yj)=uYjyj;
去除模型中VIP值相对较小的自变量,将余下变量按降序排列,筛选满足VIPk>1的变量以及VIPk<1的第一个自变量作为最终保留的自变量;重复建模以及VIP计算,以决定系数R2极大值为筛选终止条件,得到更精准的供应链碳排放数据作为下述碳排放预测模型的最终输入。
2 最小二乘支持向量机的碳排放预测方法
最小二乘支持向量机(LV-SVM)是一种具有较高预测效率的自适应加权回归预测方法,所提方法通过建立回归模型完成电网企业供应链碳排放的初始预测。将通过1.2小节得到的碳排放输入变量作为训练样本集合,用{(xi,yi)|i=1,2,…,M}描述,其中M代表训练样本容量;xi和yi分别代表第i个输入变量和输出值,通过非线性映射得到LSSVM的回归模型表达式如式(5):
f(xi)=ζrγ(xi)+b,xi∈VIPk 式(5)
式(5)中,ζ用于表示特征空间权系数向量;y(xi)是低维空间到高维空间的映射;b是阈值;由此得到LVSVM的最小二乘的优化问题:
式(6)中,V代表正则化参数;ζi表示拟合误差;si(i+1,2,…,I)代表Lagrange乘子。
为了更便于计算,将式(6)优化问题转换为式(7)线性方程组求解问题,根据式(7)获取最小二乘支持向量机的碳排放预测模型:
式(7)中,L(co,ck)代表的是核函数。
为了提高LVSVM碳排放预测模型的拟合程度和泛化能力,避免核函数参数寻优过程过早收敛,所提方法采用一种基于量子粒群的最小二乘支持向量机算法实现电网企业供应链碳排放预测。正则化参数V以及核函数宽度σ2是LVSVM碳排放预测模型中的主要待定参数,为此利用量子粒子群优化(OPSO)算法优化两个参数,具体过程如下:
(l)用Q、f形容粒子数目和量子粒子群维数;用Ymax、Yg∈(Ygmin,Ygmax)和b代表最大迭代次数、滤波器参数以及迭代精度;
(2)在控制可行区域范围内设定初始迭代次数y=0,并随机生成Q个粒子组合为初始量子粒子群;
(3)在量子种群中引入核函数,估计每个粒子的适应值对其局部最优值A。以及全局最优值Ah实施更新操作,最终求得LVSVM模型参数优化的目标函数:
式(9)中,β0.5+(1-0.5)(Ymax-y)/Ymax为收缩扩张系数,y为当前迭代次数;以此更新每个粒子的所在位置;
(5)若y满足最大迭代次数Ymax,则终止迭代,反之则y=y+1,回到步骤(3)继续迭代;通过该操作即可完成对最小二乘支持向量机碳排放预测模型的优化,实现电网企业供应链碳排放的高精度预测。
3 实验与分析
3.1 实验方案
首先,以某地区某城市的电网企业供应链夏季和冬季的部分碳排放数据作为基础数据,两个季节中的碳排放量相差较大,通过文章方法采集碳排放相关数据,包括供应链节点的碳排放数据、供应链节点的特征数据(如产能、运营时间等)以及其他可能影响碳排放的因素数据。其次,通过文章方法筛选数据,将数据划分为训练集和测试集,并且确保训练集和测试集具有代表性和独立性。然后,使用最小二乘支持向量机算法进行模型训练。通过最小化模型的平方误差来拟合训练数据。根据训练集的特征和对应的碳排放数据,使用LS-SVM算法拟合出一个预测方法(3.3章节)。最后,使用测试集进行方法性能评估,计算拟合优度、预测结果与真实值之间的误差指标以及方法的预测耗时,以上述三个指标为实验性能指标,并且将文章方法与文献[2]方法和文献[3]方法进行对比分析,在对比分析过程中,绘制预测结果与真实值的对比图表,以直观地展现方法的预测能力。
3.2 实验数据
采集的电网企业供应链相关数据,采集数据的时间跨度为6-7月份和12-2月份,共计6个月的数据,其中6-7月份为夏季,12-2月份为冬季,采集的数据包括以下特征数据和对应的碳排放数据。
特征数据为4类,分别为供应链节点1:产能为100MW,运营时间为5年,使用煤炭能源;供应链节点2:产能为200MW,运营时间为3年,使用天然气能源;供应链节点3:产能为150MW,运营时间为4年,使用风能;供应链节点4:产能为120MW,运营时间为2年,使用太阳能。碳排放数据也分为4类,分别为供应链节点1的碳排放为2000吨二氧化碳当量;供应链节点2的碳排放为1500吨二氧化碳当量;供应链节点3的碳排放为1000吨二氧化碳当量;供应链节点4的碳排放为800吨二氧化碳当量。根据上述数据,构建训练样本集和测试集,每个样本包括供应链节点的特征数据和对应的碳排放数据。具体为训练样本1:[100,5,1],2000:训练样本2:[200,3,2],1500:训练样本3:[150,4,3],1000:测试样本4:[120,2,4],800。
3.3 方法训练
在确定实验数据后,需要训练文章设计的方法,训练过程为:(1)初始化基于最小二乘支持向量机的电网企业供应链碳排放预测方法的参数;(2)将上述构建的训练数据样本输入文章构建的方法中。(3)通过最小化模型的平方误差来拟合训练数据,得到模型的参数。得到优化后的参数数值见表1。
3.4 结果分析
实验评估通过所提方法构建的碳排放预测模型的拟合优度与文献[2]方法、文献[3]方法展开对比。
3.4.1 拟合优度分析模型
拟合优度表征建立的模型与实际数据之间的拟合度,是衡量预测模型精度的重要指标,在模型不断迭代的过程中,若越大,说明建立的模型预测精度越高;测试结果见图1。
分析图1可知,在迭代次数不断增加的情况下,所提方法构建的碳排放预测模型拟合优度处于平稳且不断增长的状态,相比于文献[2]方法和文献[3]方法具有更好的拟合效果,这是由于所提方法所采用的量子粒子群优化算法提高了碳排放预测模型的拟合能力,证明了所提方法的有效性。
3.4.2 预测精度分析
为了进一步地体现所提方法的可行性,以此将预测值和实际值对比结果作为评价指标,采用所提方法和文献[2]方法、文献[3]方法对测试样本展开预测:
如图2所示,无论是夏季还是冬季,相比于其他两种传统方法,所提方法依然具有较高的预测精度,误差极小,几乎与实际值相同,且预测性能较为平稳;文献[2]方法的预测结果与实际值相差过多,预测性能较差;文献[3]方法相比于文献[2]方法较优一些,但仍存在误差较大的现象,预测性能不够稳定;由此可知,采用所提方法能够更高精度地实现对电网企业供应链碳排放的预测。
3.4.3 预测时间分析
碳排放预测方法的计算时间是决定其性能优劣的关键因素,耗时越短说明该方法具有更高效的预测能力,以此为依据将上述测试中选取的碳排放数据中夏季的6月、7月、8月和冬季的12月、1月、2月作为实验数据采用上述三种方法展开预测的耗时对比见表2。
根据表2可得,在夏季的6月、7月、8月,所提方法的平均预测运行时间为10.08s,分别低于文献[2]方法和文献[3]方法16.39s和2.16s;在冬季的12月、1月、2月,文献[3]方法的平均预测运行时间为10.25s,低于文献[2]方法9.09s,但高于所提方法3.51s,由此可以说明所提方法在计算速度方面具有明显优势,其他两种传统方法受到数据规模不同的影响,计算速度均明显下降,因此所提方法具有更高的稳定性和预测效率。
4 结束语
随着绿色发展理念的出现,人们逐渐重视生态环境,避免生态环境的污染,而电网企业供应链由于碳排放问题,其对生态环境造成污染,因此,需要预测电网企业供应链,为了提高电网企业供应链碳排放预测方法的预测精度和预测效率,提出基于最小二乘支持向量机的电网企业供应链碳排放预测方法。该方法首先获取电网企业供应链碳排放的基础数据;其次利用PLS-VIP算法从该数据库中筛选出对碳排放预测有利的有效数据变量;最后建立基于最小二乘支持向量机的碳排放预测模型并利用量子粒子群优化算法对其实施优化,完成对电网企业供应链碳排放数据的精确预测。经验证,所提方法在保障预测过程稳定性的同时,一定程度上提高了预测精度和预测效率。
