基于Stacking集成学习的声波时差测井曲线复原研究
2024-06-07曹志民丁璐韩建
曹志民 丁璐 韩建


DOI:10.20030/j.cnki.1000?3932.202403015
摘 要 声波时差测井曲线在石油勘探中发挥着不可或缺的作用,但是受地质或仪器的影响,经常会出现部分甚至完整的声波测井曲线缺失的情况。针对这一问题,提出了一种基于Stacking集成学习的声波时差测井曲线复原方法,该模型使用随机森林(RF)、梯度提升决策树(GBDT)、輕量梯度提升机(LightGBM)和极限梯度提升(XGBoost)作为基学习器,支持向量回归(SVR)作为元学习器,同时采用5折交叉验证的方法。实验选取了大庆油田某区块的实际测井数据,分别进行了同井和异井间的缺失声波时差测井曲线复原实验,结果表明,所提方法比单一模型预测更加准确,验证了此方法的可行性。
关键词 声波时差测井曲线 Stacking集成学习 测井曲线复原 5折交叉验证
中图分类号 TP274 文献标志码 A 文章编号 1000?3932(2024)03?0470?07
基金项目:海南省科技专项(批准号:ZDYF2022GXJS220,ZDYF2022GXJS222)资助的课题。
作者简介:曹志民(1980-),副教授,从事地球物理测井、油气人工智能方面的科研与教学工作。
通讯作者:韩建(1976-),教授,从事油井信号检测、机器学习、模式识别的研究,han?jian@126.com。
引用本文:曹志民,丁璐,韩建.基于Stacking集成学习的声波时差测井曲线复原研究[J].化工自动化及仪表,2024,51(3):470-476.
声波时差测井曲线在地质勘探和油气开发中具有重要的应用价值,它能够提供关于岩性、孔隙度、渗透率及裂缝等地下岩石特征的信息,为油气勘探和开发决策提供科学依据[1]。然而在实际工作中,受钻井液污染、仪器故障等原因,经常出现部分声波测井曲线失真或缺失的情况,重新测量井的经济成本和时间成本可能很高,特别是在已经投入大量资金和时间的情况下,重新测量不切实际。随着人工智能等领域的不断发展,机器学习在储层测井评价[2,3]、岩性识别[4]及测井曲线复原[5~7]等方面得到了成功的应用。其中,集成学习具有解释性强、训练速度快和泛化能力高等优点。
笔者以随机森林(Random Forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、轻量梯度提升机(Light Gradient Boosting Machine,LightGBM)和极限梯度提升(eXtreme Gradient Boosting,XGBoost)作为基学习器,以支持向量回归(Support Vector Regression,SVR)作为元学习器,同时采用5折交叉验证的方法,建立了一个基于Stacking集成学习算法的声波时差测井曲线预测模型。
1 基本理论
1.1 RF
RF是以随机的方式建立一个森林,通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,每一棵决策树之间没有关联。RF的基本原理如下[8]:
a. 从训练数据集中,用Bootstrap重采样方法随机有放回地抽取n个数据集,得到n个子训练集。
b. 使用子训练集训练决策树。在训练过程中,对于每个节点的切分都需要先随机选择k个特征,然后从这k个特征中找到最优的切分点来划分左右子树(这里生成的决策树都是二叉树)。
c. 重复步骤b,生成多个决策树模型。
d. 对每棵决策树进行预测,RF最终的预测结果是所有决策树预测结果的均值。
RF的结构示意图如图1所示。
1.2 GBDT
GBDT结合了决策树和梯度提升算法的特点,是一种基于迭代的集成学习算法[9]。在每一轮迭代中,GBDT首先训练一个新的决策树模型来拟合当前模型的残差(预测值与真实值之间的差异),然后将新的决策树模型与原有的模型进行加权组合,得到一个更准确的预测模型,这个过程会一直迭代,直到达到预定的迭代次数或者达到某个停止条件。GBDT的表达式为:
F(x,ω)=ph(x,ω) (1)
其中,x为输入样本,p为第i棵决策树的权重系数,h为第i棵决策树,ω为第i棵决策树的参数。
1.3 LightGBM
LightGBM是一种梯度提升框架,其原理与GBDT基本一致[10]。LightGBM通过引入基于梯度的单边采样(Gradient?based One?Side Sampling,GOSS)和互斥特征捆绑(Exclusive Feature Bundling,EFB)方法,有效解决了传统GBDT算法在计算特征分裂点时需要遍历全部数据计算信息增益的耗时问题。GOSS方法通过对样本梯度的绝对值进行上下采样,选取梯度绝对值较大的样本进行计算,从而去除了大量梯度较小的样本,使得计算效率得到显著提高。而EFB方法则通过对具有相似特征分布的特征进行捆绑,减少了特征分裂时的计算量,进一步加快了算法的执行速度。
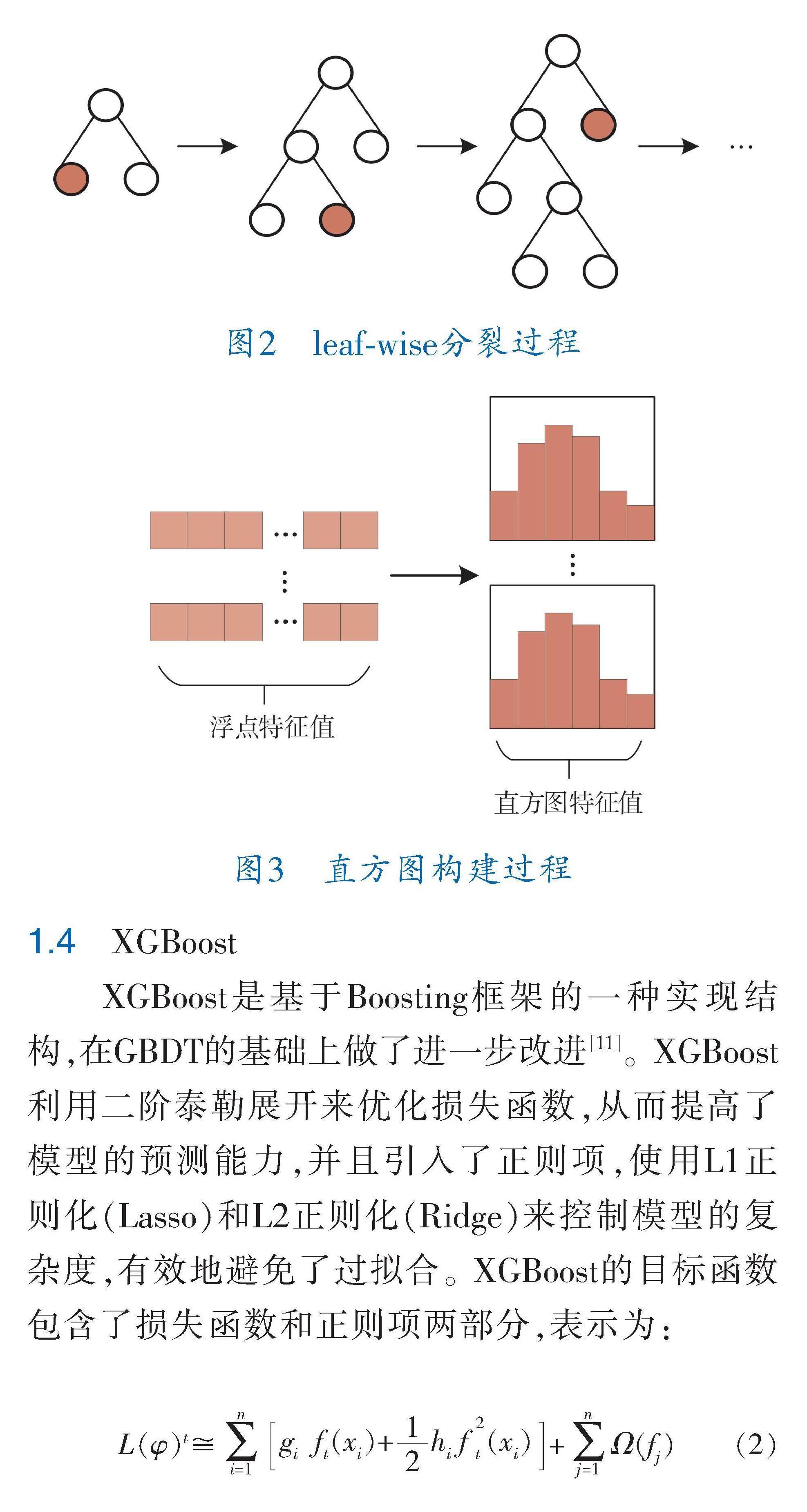
LightGBM采用带深度限制的叶子生长leaf?wise节点分裂方法,在当前所有节点中找到具有最优增益的节点来进行下一次的搜索和分裂,其分裂过程如图2所示。为了快速找到最优分裂节点,LightGBM还使用了直方图算法,将特征值按照降序或升序排列,并将其分为多个桶(即直方图),每个桶中存储了该特征值的统计信息,如数量、梯度及梯度平方和等,即可以快速计算各个分裂节点的增益,并找到最优的分裂节点,其构建过程如图3所示。
1.4 XGBoost
XGBoost是基于Boosting框架的一种实现结构,在GBDT的基础上做了进一步改进[11]。XGBoost利用二阶泰勒展开来优化损失函数,从而提高了模型的预测能力,并且引入了正则项,使用L1正则化(Lasso)和L2正则化(Ridge)来控制模型的复杂度,有效地避免了过拟合。XGBoost的目标函数包含了损失函数和正则项两部分,表示為:
L(φ)t?
g
f(
x)+
hf
(
x)+Ω(f) (2)
其中,L(φ)t为第t次迭代的目标函数,g为x的一阶导数,h为x的二阶导数,f()为第t次迭代的决策树模型,Ω(f)为第j次迭代的正则项。
1.5 SVR
SVR是一种基于支持向量机的回归方法,它的回归过程与线性回归类似,但具有更高的准确度和泛化能力[12]。不同于传统的线性回归方法,SVR的目标不是直接拟合数据,而是通过在二维空间中找到一个分离超平面来建模回归问题。同时,SVR通过将再投影误差作为复杂度惩罚项来调节回归模型的灵活性。这个惩罚项控制着模型对数据点的拟合程度,从而对模型的复杂度进行调节。通过调节复杂度参数,可以灵活地控制模型的泛化能力,使其更好地适应不同的数据集。对于数据集的某个样本点(x,y)(i=1,2,…,l),SVR的优化目标为:
[w,ξ,ξ][min] w +C(ξ+ξ)
s.t.
y-w?(
x)-b≤ε+
ξ ,
ξ≥0,i=1,2,…,l
-y-w?(
x)+b≤ε+ξ,
ξ≥0(3)
其中,w为权重系数,C为惩罚系数,b为常值偏差,ξ和ξ为松弛变量,?()为将输入数据映射到高维特征空间的非线性函数。
SVR的结构示意图如图4所示。只有当样本点落在间隔ε之外时,才会考虑其损失,而在间隔ε内的样本点则不计入损失。
1.6 Stacking模型
Stacking模型是一种集成学习方法,采用基学习器层和元学习器层两层架构,用于组合多个基础学习器的预测结果,以提高模型的准确性和鲁棒性[13]。Stacking模型的基本思想是通过训练一个元模型,来组合多个不同的基模型的预测结果,其结构示意图如图5所示。
1.7 K折交叉验证
在机器学习建模过程中,一般会将数据集划分为训练集和测试集。测试集是独立于训练过程的数据,不参与模型的训练,而是用于评估最终模型的性能。在训练模型的过程中,常常会出现过拟合的问题,即模型在训练数据上表现良好,但在未见过的测试数据上的预测效果较差。如果使用测试数据来调整模型参数,就相当于在训练时已经利用了部分测试数据的信息,这将影响最终评估结果的准确性。因此,一种常见的做法是将训练数据再划分出一部分作为验证数据,用于评估模型的训练效果。这样可以确保最终评估是在模型未曾接触过的数据上进行的。
K折交叉验证将数据集分为K个互斥的子集,称为折。在每一轮中,将其中一个折作为子验证集,其余K-1个折作为子训练集,使用子训练集进行模型训练,并在子验证集上进行模型评估。这一过程会重复K次,每次都会选择不同的子验证集。最终,将K次验证的结果进行平均,这种方法可以更准确地评估模型的性能,因为它会使用到数据集中的所有样本进行验证,避免了只使用一部分数据可能带来的偏差[14]。
1.8 评价指标
为了定量评价本方法的客观性能,采用均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)、平均绝对相对误差(Mean Absolute Percentage Error,MAPE)、对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error,SMAPE)和皮尔逊相关系数(Pearson Correlation Coefficients,PCCs)作为评价指标。评价指标MSE、RMSE、MAE、MAPE、SMAPE的数值越小,代表模型的准确性越高。PCCs表示真实值与预测值之间的相关程度,其值越大,模型的准确性越高。
2 实验与结果分析
文中的Stacking模型选用RF、GBDT、LightGBM、XGBoost4种模型作为基学习器,SVR作为元学习器,并采用K折交叉验证(这里K取5)的方法。实验的总体框图如图6所示。
笔者选用大庆油田某区块的两口井(编号为W1、W2)作为实验数据来源,采样间隔均为0.125 m,即每隔0.125 m有一个采样点,均包含井径(CaLiper,CAL)、自然伽马(Natural Gamma Ray,GR)、自然电位(Spontaneous Potential,SP)、深侧向电阻率 (LateroLog Deep,LLD)、浅侧向电阻率(LateroLog Shallow,LLS)、密度(Density,DEN)、声波时差(Acoustic,AC)7条测井曲线。W1井的起止深度为井下1 284~2 712 m,共计11 425个采样点。W2井的起止深度为井下1 578~1 954 m,共计3 009个采样点。AC曲线作为目标曲线,其他6条曲线作为母曲线。为了验证笔者所提方法的有效性,进行了两组实验:
a. 同井缺失声波时差测井曲线复原实验;
b. 异井缺失声波时差测井曲线复原实验。
2.1 同井缺失声波时差测井曲线复原实验
这里以W1井和W2井缺失某些声波时差测井曲线的复原实验为例。随机选取30%的AC曲线进行删除,作为缺失的AC曲线段,并作为此次实验的测试集,其他完整测井曲线作为训练集。W1井和W2井的实验结果分别如图7、8所示。
为了进一步体现笔者所提模型的复原效果,表1和表2分别列举了W1井和W2井的AC曲线缺失段的不同复原方法和笔者所提方法的定量评价结果。
从各个评价指标结果来看,笔者所提方法结果均优于对比方法。
2.2 异井缺失声波时差测井曲线复原实验
这里分别以W1井和W2井作为此次实验的训练集和测试集,并将W2井的AC曲线全部删除,作为完整缺失AC曲线的井。实验结果如图9所示。
为了进一步体现笔者所提模型的复原效果,表3列举了W2井的AC曲线不同复原方法和笔者所提方法的定量评价结果。虽然W1井与W2井同处一个区块,但是储层岩性分布差异较大,加大了W2井的AC曲线复原难度,复原结果没有同井复原结果好,但仍优于对比方法。
3 结束语
介绍了一种基于Stacking集成学习的缺失声波时差测井曲线复原方法。该方法将RF、GBDT、LightGBM和XGBoost作为Stacking模型的基学习器,SVR作为Stacking模型的元学习器,并采用了5折交叉验证的方法,以减少过拟合的风险。对同井和异井间缺失的声波时差测井曲线进行了复原实验,结果表明笔者所提方法可以有效地提升缺失声波时差测井曲线复原的精确度,从多种评价指标来看,该方法的评价指标均优于单一模型。
参 考 文 献
[1] 霍学文.声波测井仪器的基本原理及应用探析[J].石化技术,2017,24(11):184.
[2] WANG Z ,TANG H M,HOU Y M,et al.Quantitative evaluation of unconsolidated sandstone heavy oil reservoirs based on machine learning[J].Geological Journal,2023,58(6):2321-2341.
[3] 秦瑞宝,叶建平,李利,等.基于机器学习的煤层含气量测井评价方法——以沁水盆地柿庄南区块为例[J].石油物探,2023,62(1):68-79.
[4] 谷宇峰,张道勇,鲍志东,等.利用GS?LightGBM机器学习模型识别致密砂岩地层岩性[J].地质科技通报,2021,40(4):224-234.
[5] 王俊,曹俊兴,尤加春.基于GRU神经网络的测井曲线重构[J].石油地球物理勘探,2020,55(3):510-520;468.
[6] CHENG C,GAO Y,CHEN Y,et al.Reconstruction Me? thod of Old Well Logging Curves Based on BI?LSTM Model—Taking Feixianguan Formation in East Sichuan as an Example[J].Coatings,2022,12(2):113.
[7] 李枫林,刘怀山,杨熙镭,等.基于U?Net神经网络的声波测井曲线重构[J].中国海洋大学学报(自然科学版),2023,53(8):86-92;103.
[8] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[9] 陈天锴,王贵勇,申立中,等.基于GBDT算法的柴油机性能预测[J].车用发动机,2022(5):51-58.
[10] WANG D N,LI L,ZHAO D.Corporate finance risk pr? ediction based on LightGBM[J].Information Sciences:An International Journal,2022,602:259-268.
[11] 赖儒杰,范启富.基于指数平滑和XGBoost的航空发动机剩余寿命预测[J].化工自动化及仪表,2020,
47(3):243-247;250.
[12] PENG X J,DONG X.Projection support vector regression algorithms for data regression[J].Knowledge?Based Systems,2016,112:54-66.
[13] YANG R X,SUN C Y,XU L.Prediction of photovoltaic power generation based on stacking model fusion[J].Computer System Application,2020,29(5):36-45.
[14] 朱文广,李映雪,杨为群,等.基于K-折交叉验证和Stacking融合的短期负荷预测[J].电力科学与技术学报,2021,36(1):87-95.
(收稿日期:2023-07-26,修回日期:2024-04-08)
Research on Acoustic Moveout Logging Curves Restoration Based on Stacking Ensemble Learning
CAO Zhi?min1a,1b,2, DING Lu1a,2, HAN Jian1a,1b,2
(1a. SANYA Offshore Oil & Gas Research Institute;
1b. School of Physics and Electronic Engineering, Northeast Petroleum University;
2. Research Center for Oil & Gas Testing and Measurement Technology and Instrumentation of Heilongjiang Province)
Abstract Acoustic moveout logging curves play an indispensable role in petroleum exploration, but the influence from geology and instruments results in the loss of partial or even complete acoustic logging curves. In this paper, a method of acoustic moveout logging curve restoration based on Stacking ensemble learning was proposed. The model employs random forest(RF), gradient lifting decision tree(GBDT), lightweight gradient lifting machine(LightGBM) and extreme gradient lifting(XGBoost) as the base learners, takes support vector regression(SVR) as the meta?learner and adopts a five?fold cross validation method. In the experiment, the a sections actual logging data in Daqing Oilfield was selected to respectively implement the restoration experiments of the same well and different wells missing acoustic transit time logging curves. The experimental results show that, the method proposed outperforms the single model in the prediction and it verifies the feasibility of this method.
Key words acoustic moveout logging curves, Stacking ensemble learning, restoration of logging curves, five?fold cross validation
