基于大数据配电网运行线损异常诊断研究
2024-06-04枣庄矿业集团有限责任公司供电工程处崔安原
枣庄矿业(集团)有限责任公司供电工程处 崔安原
配电网线损传统分析方法往往受限于技术和数据量,导致结果并不准确。大数据技术的崛起为该问题带来了新的解决思路。大数据不仅能够处理海量的数据,还可以深入挖掘数据背后的潜在信息,从而为线损异常诊断提供了更为准确的依据。此外,大数据技术结合先进的机器学习和深度学习算法,可以实时地监控和预测配电网的线损异常,帮助电力系统操作者快速定位问题,并采取有效措施减少损失[1]。可见大数据技术在配电网线损分析中的存在一定潜力,本研究旨在探讨如何利用大数据技术进行配电网线损的异常诊断,以期为电力行业提供一个新的、更为高效的线损管理方案。
1 大数据与配电网线损
配电网线损是电能在传输与分配过程中不可避免的能量损失,主要受导线的物理特性、电气设备的固有损耗,以及非线性负荷如电子设备的增长等多重因素影响。随着非线性负荷的增加,电网中谐波产生的压力加大,导致更大的线损和电压畸变的风险。同时,人为因素如电力盗窃和非法用电也对线损产生重大影响。
在应对这些挑战的背景下,大数据技术为配电网线损的分析和管理提供了创新的解决方案。利用其处理和分析海量数据的能力,大数据技术不仅能深入探究线损的成因和模式,还可以实现电网的实时监控和异常状态的预测,从而大幅提高系统的响应效率。通过收集和分析从智能传感器和电表中获得的数据,大数据平台可以准确识别和预测哪些区域或时间可能会出现高线损,使得电力公司能够迅速采取措施,优化电网运行。
结合如深度学习等现代技术,大数据不仅可以提高线损分析的精确度,还促使配电网管理向智能化发展。例如,通过训练机器学习模型来识别和预测线损异常,可以在问题发生前进行预警,从而避免潜在的风险和损失。这些技术的应用为决策提供了强大的数据支持,确保电网的高效、稳定和安全运行,同时也为电网的未来智能化升级奠定了基础。
2 基于大数据的配电网线损数据的采集与预处理
2.1 数据采集方法与工具
随着配电网的升级,众多智能设备和数据采集技术已投入使用,不仅带来了大量数据还优化了数据处理方法。电流、电压传感器和智能电表监测电网状态,而技术如NB-IoT 和LoRa支持远程数据采集。现有工具,如SCADA 和Prometheus 可以优化数据管理。相比传统方法,这些新技术更适应大数据挑战,确保数据质量(见表1)[2]。
2.2 基于大数据技术的数据处理方法
配电网现代化进展迅速,大量传感器和智能设备被广泛部署,为人们提供了丰富的数据资源。数据的采集和预处理是后续分析的关键步骤,对其正确性和有效性有着直接影响。数据处理方法步骤分为数据清洗、数据转换、数据归一化(见表2)。
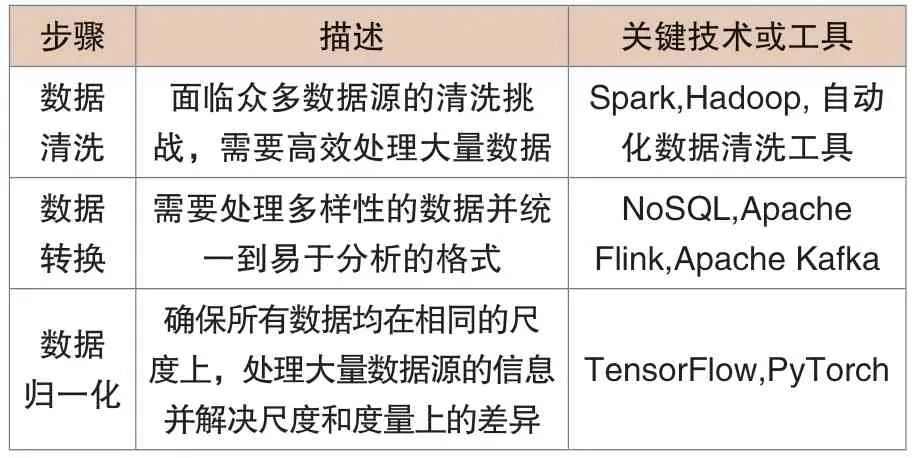
表2 数据处理方法步骤简介
3 基于大数据的线损异常诊断技术
3.1 机器学习与深度学习在异常诊断中的应用
在配电网线损异常的诊断中,机器学习和深度学习技术逐渐成为主流工具。机器学习常用的算法如决策树、随机森林、支持向量机等,能够在大数据环境下进行训练,并从历史数据中学习线损的模式。通过历史线损数据,机器学习模型可以识别何时、何地和如何产生的线损,从而为运维团队提供实时的告警和建议。深度学习适用于大量和复杂的数据,特别是时序数据。卷积神经网络(CNN)和递归神经网络(RNN)等模型,被广泛应用于配电网数据的分析,这些模型能够自动地提取关键特征并进行预测[3]。
3.2 常见的线损异常诊断模型介绍
配电网线损异常的诊断中涉及多种模型,每种模型都有其特定的应用场景和优势。常用的有自回归模型,主要适用于时序数据,能够基于历史数据预测未来的线损情况;孤立森林作为一个异常检测算法,可高效地识别线损中的异常数据点;长短期记忆网络是RNN 的一种,特别适用于时序数据的分析,能够捕捉数据中长期的依赖关系,从而更准确地预测线损[4]。
3.3 特征工程与模型选择
特征工程是机器学习中的核心步骤涉及从原始数据中选择、转换和构建正确的输入特征。在配电网线损异常诊断中,特征包括电流强度、电压波动、设备状态等。正确的特征选择可以显著提高模型的准确性。模型选择是根据具体的业务需求和数据特性选择合适的算法和模型。例如,对于小规模数据,决策树是一个好的选择;而对于大量的时序数据,LSTM 更为合适[5]。
3.4 LSTM 诊断线损异常技术
LSTM 技术适合大量的时序数据的研究,将其作为线损异常诊断的技术较为合适。如何利用该技术进行配电网运行线损异常诊断是本研究的重点,其具体技术细节和执行步骤如下。
3.4.1 模型定义
一是LSTM 网络结构:LSTM 模型通常包含一个或多个LSTM 层,随后是一个或多个全连接层用于输出。对于线损异常检测,模型可以设计为多对一的架构,即输入过去的一系列读数,输出预测的下一个线损值。二是参数设置:选择合适的时间步长,即考虑过去多少时间的数据和LSTM 神经元的数量。例如,如果选择过去24h 的数据来预测下一个小时的线损,时间步长就是24。
3.4.2 模型训练
一是损失函数与优化器:对于回归问题,如线损预测,常使用均方误差(MSE)作为损失函数。选择合适的优化器是关键,其中Adam 优化器因其自适应学习率调整而广受欢迎,而RMSprop 优化器则在处理非平稳目标时表现出色。这些优化器通过迭代更新模型的权重,以最小化损失函数,从而提高模型的预测精度。二是训练数据的构造:构造有效的训练数据是训练任何机器学习模型的基础。对于时序数据如电网线损数据,通常采用滑动窗口方法来构造输入和输出。例如,可以将前N 个时间点的数据作为输入特征,而当前时间点的数据则作为目标输出。这种方法使模型能够学习到数据随时间变化的动态特性。三是训练模型:在实际训练中,LSTM 模型通过逐步学习历史数据中的模式来优化其预测性能。训练过程涉及多个周期(epoch),每个周期都会遍历整个训练集。通过反复迭代,模型的参数逐渐调整,直至损失函数的值趋于稳定或达到预设的收敛条件,这通常表明模型已经从训练数据中学到了足够的信息。
3.4.3 异常检测
一是用模型进行预测:使用经过训练的LSTM模型对测试数据进行预测是异常检测的第一步。这一步骤的目的是利用模型对未见过的数据进行泛化,从而评估模型的实际应用能力。二是计算残差:残差是真实线损值与LSTM 模型预测值之间的差异。三是确定异常阈值:常见的方法是先在训练数据上计算残差,然后使用其均值和标准差来确定阈值。例如,如果残差超过均值的2或3倍标准差,那么该数据点可能是异常的。四是标记异常:应用上述定义的阈值来检查每个数据点。通过这种方式,可以系统地识别和标记那些符合异常标准的数据点。这一步骤不仅有助于及时发现和处理问题,还可以进一步分析异常的根本原因,为未来的预防措施提供数据支持。
4 试验与结果分析
4.1 试验设置与数据集描述
在基于大数据的配电网运行线损异常诊断试验中,考虑到LSTM 在处理时序数据上的优越性能,选择了LSTM(长短期记忆网络)模型来进行配电网线损的异常诊断。数据集来自多个地级市的配电站的运行记录,包含了连续的电流、电压、温度和其他相关的参数数据。每条数据还伴随着时间戳,以便于建模时序关系。数据集在分为训练集和测试集前,经过了一系列的预处理后,数据集被划分为训练集(80%)和测试集(20%)。利用上文叙述的数据集采集与预处理方法进行了该步骤,产生了130M 的原始数据。
4.2 模型训练与验证
在训练过程中,LSTM 模型使用了多层结构,每层包含128个隐藏单元。模型训练的时候使用了Adam优化器,学习率设置为0.001,并采用了早停策略以防止过拟合。验证方面,模型在测试集上的性能通过计算MSE(均方误差)来评估。与此同时,为了比较LSTM 的性能,还使用了其他常见的时序预测模型,如AR 和Isolation Forest,进行相同的试验。
4.3 结果分析与讨论
通过以上试验,本研究将试验结果处理后得到了如图1所示的结果。由图1(评分越低,性能优越)可知,LSTM 模型表现优越,这验证了LSTM 对于捕捉时序数据的长期和短期依赖关系的能力。在配电网线损异常预测任务上,成功捕获了数据中的关键模式。而AR 模型的性能略低于LSTM。这可能是因为AR 模型主要考虑了数据的自回归性质,但可能没有完全捕获到数据中的某些复杂模式和长期依赖关系。孤立森林(Isolation Forest)算法作为一种主要用于异常检测的算法,其在预测任务上的性能略显不足。这表明该模型可能更适合直接的异常检测,而不是为了预测任务。
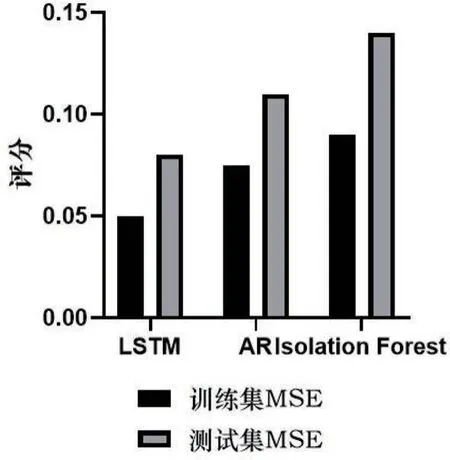
图1 三种模型评分结果
5 结语
本研究围绕配电网线损异常进行了深入探讨,采用基于LSTM 的深度学习模型,结合大数据处理技术,对线损数据进行了准确的预测与分析。研究结果揭示了LSTM 模型在处理配电网线损数据时,具有出色的性能和准确性。与先前的研究相比,本研究将大数据技术与机器学习相结合来进行线损的预测与分析,确保了大规模数据的高效处理和准确分析。这为配电网的实时监控与运营提供了新的可能性。
