基于深度强化学习的多路径调度模型
2024-06-01赵静


摘 要:文章提出一种基于深度强化学习的多路径调度模型,在聚合场景中将深度学习技术应用于流量管理,以解决多路径环境下的数据包调度问题。文章使用了一个多路径快速UDP网络连接协议(MPQUIC)来实现多路径场景中的路径选择,并训练了一个代理人(Agent)来改进最优选择路径的算法,展示了将深度Q网络代理(DQN Agent)应用于数据流量管理问题的优势。实验证明了在实时环境中使用DQN Agent来提高包调度器性能的可行性,以及使用该技术对新的5G网络进行优化的潜力。实验结果表明:基于深度强化学习的多路径调度模型能够自适应地调整路径选择策略,从而提高网络的稳定性和可靠性。改进的模型不仅具有理论价值,还为实际应用提供了有益的参考和借鉴。
关键词:5G网络;多路径;分组调度;深度强化学习;QUIC;MPTCP
中图分类号:TP181 文献标志码:A
*基金项目:甘肃省基础研究计划-软科学专项“‘强省会战略下推进‘四型机场建设的实施路径和策略研究—以兰州中川国际机场为例”(22JR4ZA108)。
作者简介:赵静(1981-),女,硕士,讲师,主要研究方向:人工智能技术。
0 引言
随着人工智能技术的不断发展,深度强化学习作为一种新兴的学习范式,正在被广泛应用于各个领域。在传统的调度问题中,如任务调度、生产调度等,采用深度强化学习进行多路径调度优化已成为研究热点。然而,在实际应用中,仍然存在着许多问题和挑战,如路径选择、任务分配、资源利用率等方面的优化。文章旨在基于深度强化学习,设计并构建一种多路径调度模型,以解决传统调度问题中存在的优化难题,提高路径选择、任务分配和资源利用率的效率和准确性。通过对多路径调度模型进行深入研究和实验验证,探索深度强化学习在该领域的应用前景,提高多路径调度问题的解决效率和质量。5G 架构的关键概念之一是网络接入(Access Networks,AN)的合并。5G系统架构[1]定义了一个具有公共接口AN-CN的融合核心网(CN),它集成了第三代合作伙伴计划(3GPP)和非3GPP网络,如Wi-Fi或固定接入网,在这些场景中可以同时使用多个网络接入[2]。通过多访问架构,可以定义新的应用场景,并根据访问的用途进行分类:(1)聚合应用,它以终端用户只感知一个接入的方式聚合接入网络,具有底层接入(如聚合带宽,延迟等)的聚合特性;(2)弹性应用,它只使用一个网络接入,并使用其余的网络接入进行冗余。弹性应用的一个例子是Apple Siri服务[3],它默认使用Wi-Fi网络接入,但通过移动网络接入打开会话以进行备份。
文章采用深度强化学习算法,考虑任务调度、路径选择、资源利用率等因素,构建多路径调度模型。首先,将对传统的调度问题进行深入分析,明确问题的关键点和难点;其次,设计出基于深度强化学习的多路径调度模型;最后,在模型构建完成后,将进行大量的仿真实验和案例分析,以验证模型的有效性和优越性。文章的研究工作主要集中在聚合场景中,特别是符合宽带论坛(BBF)规范的架构。主要关注L4多路径网络,其主要特点是使用多路径传输协议,通过多条路径来控制流量。基于前述BBF规范,根据策略、数据包流量类别和每个可用访问路径的性能,将流量分布在不同的路径上。
根据性能选择最佳路径通常称为分组调度(Packet Scheduling)。大多数多路径协议的实现都使用平滑往返时间(Smoothed Round-Trip Time,SRTT)和拥塞窗口作为表征访问路径性能的参数。尤其是在拥塞窗口不满的情况下,选择SRTT较低的路径对数据包进行调度,以实现多路径传输控制协议(MPTCP)[4]。理论上讲,在明确网络参数的前提下,可以建立一个提供最优性能的调度器。但在实际应用中,网络访问的延迟会随着时间而变化,特别是在移动网络中,带宽也会随着并发连接数的变化而变化。通過引入其他参数和更复杂的算法,研究认为可以通过预测访问的演化来改进分组调度。
在强化学习领域,深度学习系统广泛应用于许多Atari视频游戏,提出利用机器学习技术对Packet Schedule算法进行改进,并将该方法应用于深度强化学习代理作为数据包调度器,通过与测试环境的交互来查看代理人(Agent)如何学习,以得到分发数据包的最佳算法。结果表明,在某些场景中,深度强化学习方法给出了最优的结果。因此,文中技术可以用于改进大多数多路径实现中使用的默认包调度器。
1 研究背景及相关研究综述
随着互联网的飞速发展和大数据时代的到来,网络流量呈现出爆炸式增长的态势。传统的单路径传输方式已经难以满足日益增长的网络需求,多路径传输因其能够充分利用网络资源、提高传输效率而备受关注。然而,多路径调度问题涉及复杂的决策过程,传统的优化方法难以应对其动态性和不确定性。因此,文章提出利用深度强化学习技术来解决多路径调度问题,以期实现更高效的网络传输。
1.1 相关概念
1.1.1 深度强化学习
深度强化学习(Deep Reinforcement Learning,DRL)是一种结合深度学习和强化学习的技术,通过深度神经网络来逼近强化学习中的值函数或策略函数,从而处理更加复杂和大规模的问题。
1.1.2 多路径调度
多路径调度(Multi-path Scheduling)指在网络传输中,根据一定的策略将数据流分配到不同的路径上进行传输,以充分利用网络资源,提高传输效率。
1.2 已有研究分类
1.2.1 基于传统优化算法的研究
这类研究主要利用数学优化方法,如线性规划、整数规划等,来解决多路径调度问题。虽然这些方法在理论上有较好的性能保证,但在实际应用中,由于问题的复杂性和动态性,往往难以获得理想的效果。
1.2.2 基于启发式算法的研究
启发式算法通过模仿人类决策过程或借鉴自然界中的某些现象来进行路徑选择和调度。这类方法通常具有较好的实时性和适应性,但在处理大规模复杂问题时,其性能往往不稳定。
1.2.3 基于深度强化学习的研究
近年来,随着深度强化学习技术的快速发展,越来越多的研究开始尝试利用DRL来解决多路径调度问题。这类方法能够自动学习和优化调度策略,适应网络环境的动态变化,具有较高的潜力和应用价值。
传统优化算法虽然理论性强,但在实际应用中难以处理复杂的动态问题;启发式算法虽然实时性好,但性能不稳定;而深度强化学习则能够结合深度学习的表征学习能力和强化学习的决策能力,有效应对多路径调度问题的复杂性和动态性。然而,目前基于深度强化学习的多路径调度研究仍处于探索阶段,面临着诸多挑战,如模型设计、训练效率、稳定性等问题。
综上所述,基于深度强化学习的多路径调度模型研究具有重要的理论价值和实践意义。文章旨在探索更加高效的深度强化学习算法,以解决多路径调度问题中的关键挑战。具体研究问题包括:设计合适的深度神经网络结构以充分提取网络状态的特征;设计有效的奖励函数以引导模型学习到高质量的调度策略;提高模型的训练效率和稳定性。通过解决这些问题,期望能够为多路径调度问题的研究提供新的思路和方法。
2 实验平台与实验过程
2.1 研究目标
研究的主要目标是使用深度强化学习代理来改进多路径协议的数据包调度。主要的挑战是如何在网络系统中集成现有的、最先进的、具有强制性低延迟性的Agent。一方面,通过对通信网络有时延要求,在新的5G网络中,超可靠低时延通信(Ultra Reliable Low Latency Communications,URLLC)服务的时延要求为1 ms;另一方面,包调度器的实现必须是快速的,达到微秒级甚至纳秒级,以不干扰实验的结果。
2.2 实验中使用的技术
2.2.1 多路径协议
在实验中,使用 MPQUIC 作为多路径协议。MPQUIC是基于QUIC协议的改进QUIC-GO5,使用Go编程语言实现。该协议的优点之一是不依赖于内核实现,并且允许“快速实现-运行-测试”的周期循环。
2.2.2 深度强化学习代理
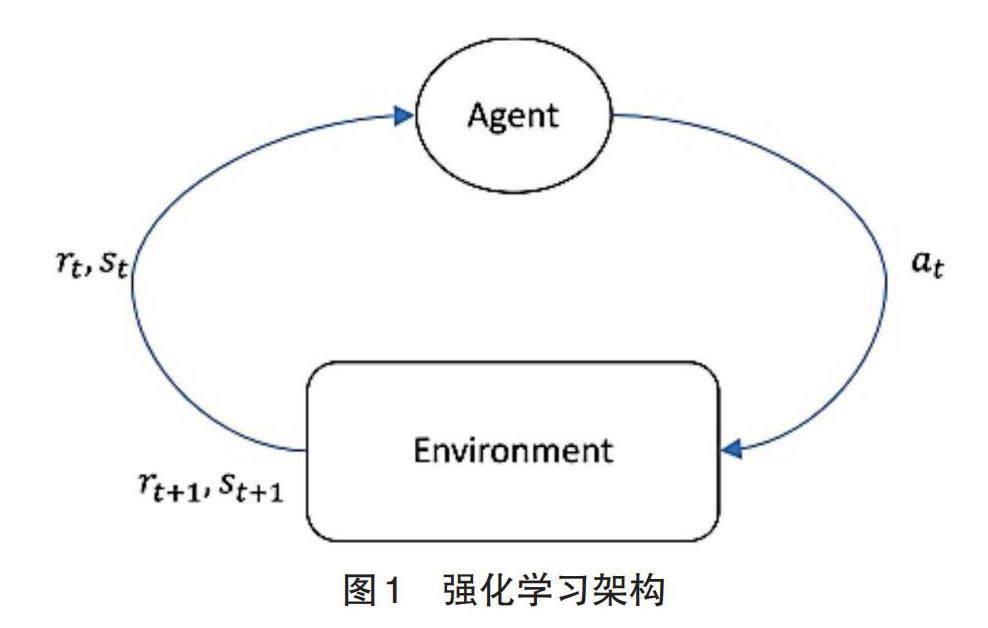
深度强化学习(DRL)是融合了试错法学习范式的强化学习(Reinforcement Learning,RL)和使用深度神经网络的深度学习(Deep Learning,DL)的创新概念。DeepMind公司在2013年推出了应用于旧式Atari游戏的新范式,其结果有时竟然超过了人类。这项工作使用Q-Learning强化学习技术,基于从初始状态 s 0 开始,寻找在连续步骤中获得最大获益的策略。图1演示了强化学习技术的流程架构。即:Agent读取当前的环境状态s t ,并从可用的动作集合A中选择一个动作 a t ∈A ;通过执行选定的动作,过渡到另一个状态 s t+1 ,并为Agent r t+1 提供一个可观奖赏,并通过学习选择奖赏最大化的最优算法。DeepMind 最初的目标是通过一个深度神经网络(Deep Neural Network,DNN)来代替传统的获取最佳动作的算法。因此,这种新技术被称为深度Q网络(Deep Q Network,DQN),而实现它的Agent就是DQN Agent。
2.3 实验流程
图2展示了一个深度强化学习代理的体系结构,包括2个主要阶段:(1)前馈,其中Agent使用当前状态作为深度神经网络的输入,并获得具有最佳预测奖励的动作(最优动作);(2)反向传播,其中Agent使用以前的经验(批量回放)来更新深度神经网络的权重和偏置。由于反向传播消耗大量的计算资源,该任务必须在离线模式下完成,即与数据包调度分离。TensorFlow库中DQN Agent的最新实现的快速审查结果表明,前馈过程需要在5~10 ms,这与5G网络中所需的延迟处于同一数量级。为此,在2个模块中实现一个DQN Agent:其中一个模块嵌入到MPQUIC服务器中,为每个状态选择最优动作;以及另一个具有学习逻辑的离线模块。为模块之间的通信定义了2个接口:第一个接口包含一个公共分离值(CSV)文件,其中包含在线Agent的经验,即状态列表 s t ,动作 a t 和奖励 r t 。这些信息被离线Agent用于执行学习。第二个接口用于将DNN的新值上传至在线Agent。为此,使用了层级数据格式5(hdf5)文件,其广泛应用于现有框架。
2.4 状态、奖励和行为
最优状态和奖赏函数的选择对深度强化学习的性能至关重要。此外,还需要保证选择与马尔可夫决策过程(MDP)框架兼容,特别是状态向量s表示唯一的状态。在DQN Agent[5]的原始工作中,这个问题是通过在状态向量中堆叠框架来解决的。在案例中,提出了保证唯一性的特征组合:平滑往返时间、拥塞窗口和发送的数据。
2.4.1 平滑往返时间(SRTT)
往返时延(Round-Trip Time,RTT)是MPTCP的内核实现[6]和MPQUIC原型[7]中分组调度算法使用的基本参数。同时使用了Smooth RTT,即:
SRTT= ( ) 1-α *SRTT+α*R ' (1)
式中:R ' 是最后一个RTT, α= 1 / 8 。
在DQN Agent的实现中使用了SRTT特征。
SRTT '=SRTT/150 (2)
式中:SRTT ' 为将SRTT特征重新缩放到150 ms。
2.4.2 拥塞窗口(CWND)
拥塞窗口特征是通过拥塞控制算法计算得到的拥塞窗口的字节大小。
CWND '=CWND /(300 * TCP_MSS) (3)
式中:CWND ' 意为将CWND特征重新縮放为300个最大片段的尺寸(MaximumSegment Size,MSS),在实现中定义为1 460个字节。
2.4.3 发送字节(BiF)
BiF 是指 Flight 中的字节数,即未收到相应的(ACK消息)从而被确认为未确认发送的字节数。它是状态向量中使用的最后一个特征。
BiF '=BiF/CWND (4)
式中:BiF ' 为将BIF特征被重新缩放到CWND的大小。
另一个需要界定的,是如何进行奖励计算。因为它是Agent的反馈,因此比状态定义更为关键。奖励和惩罚之间的不平衡可能会导致学习过程中的错误。
partial Reward = sentBits /(3 500 * sessionTime)(5)
式中:参数 partial Reward (部分奖励)以兆比特每秒(Mbps)为单位,表示在部分奖励的情况下,基于会话具有任意数量的3 500个数据包的假设前提下,使用MPQUIC服务器发送的尚未确认的字节数和会话的持续时间来估计会话的吞吐量。
最终的奖励定义为会话的平均吞吐量,用兆比特每秒(Mbps)表示。此外,当 MPQUIC 达到限制值,例如最大不带ACK的数据包数时,或者在没有丢包的理想信道中存在重传或丢包时,奖励中存在惩罚。
2.5 Agent实现
深度强化学习Agent分2个模块实现。在线模块在MPQUIC的包调度内执行,为简化操作,只作为MPQUIC服务器的一部分,对下行流进行测试。离线模块是对keras-rl框架的扩展实现,该框架在Py?thon中实现深度强化学习算法,并与流行的深度学习Python库keras9集成。
2.5.1 在线Agent
在线Agent的主要组件是gorl库,它实现了深度Q网络。为了重用代码,实现了一个通用的DNN,其中包含了这项工作所需的基本要素。它支持基于全连接层的多层神经网络,具有任意的层数和可配置的层大小。它还支持最常见的激活函数,包括该工作中使用的激活函数(ReLu和Linear)。深度神经网络定义在spec文件中,激活为keras格式。该库支持2种工作模式:训练与生产。在学习阶段,使用了Training(训练)模式,因为它每一层级产生一个CSV文件,其中包含一个用于每个数据包调度的行,元组为( r t 、 s t 、a t )。在案例中,每个情节被映射到一个 MPQUIC 会话,情节描述文件中包含的关于Agent 的状态、奖励和动作的信息被用于离线训练。gorl支持使用从离线代理导出的HDF5文件对DNN进行更新。另一个组件插入到MPQUIC服务器的包调度器中,该组件的任务是设置 DNN,从MPQUIC服务器中可用的信息中收集状态向量 s t ,调用DNN获取动作 a t 并计算奖励 r t 。
DQN Agent必须解决的基本问题是探索与开发之间的平衡。Agent必须寻找一个状态的不同行动方案,从而确定最优方案。为此它将测试不同的行动方案下不同奖励,并更新Deep Q网络。在线代理实现了2个功能:选择最优动作(对于非学习型运行)的ArgMax函数和以概率进行探索的ε-greedy函数以 ε 的概率进行利用。在训练的执行过程中,使用了一个 ε∈[ 0.1,0.9],从0.9开始,线性减小直到0.1,至训练结束。
2.5.2 离线Agent
离线Agent使用keras-rl框架实现,它是实验框架的一部分。通过扩展了kera的DQNAgent的行为,以支持在线代理生成的CSV情节文件。keras-rl框架很好的集成到了Gym OpenAI环境中,提供了不同场景的环境基础。在案例中,创建一个OpenAI环境,用于加载CSV情节文件,以便为离线代理提供在线代理的经验。此外还扩展了keras-rl DQN Agent,以便在训练过程中使用由在线代理决定的动作a t 。
2.6 实验流程及结果
文章提供了一个执行代理的环境来进行训练和测试Agent。基本设置是一个MPQUIC客户端和服务器运行在Mininet网络仿真器之上,该仿真器模拟网络拓扑,NetEm仿真器允许配置通道的带宽和它们的延迟。实验流程如图3所示,包括从MPQUIC客户端下载文件,直到有足够的信息开始离线训练。离线训练完成后,将新的DNN模型加载到在线代理中继续测试。
流程中包括为MPQUIC客户端配置了2条可能的路径,通过在交换机上增加2条连接,交换机上也有1条通往MPQUIC服务器的路径。该框架支持离线 Agent 的执行,并提供了用于创建不同测试的Jupyter笔记本应用程序。最后,用所有的实验框架创建一个Docker镜像,以允许在任何环境中重现实验结果。
3 实验结果分析
实验目的是评估多条路径带宽聚合的效率。为了衡量效率,使用在下载固定大小(2 MB)文件的实验中测量吞吐量。在实验框架中,配置了带宽为5 Mbps,基延迟为100 ms的MPQUIC路径。为了比较不同场景下的结果,改变其中1条路径的延迟,以模拟它们之间存在延迟的非对称路径,即delta(ms)∈[0,50]。第一个实验设置了MPQUIC协议的性能基线,用于测量效率。如图4所示,图(a)表示使用单条路径测量吞吐量的结果,并以此作为该场景下MPQUIC协议吞吐量的基础。图(b)表示使用默认调度器RTT的多路径场景下的吞吐量,图(c)表示随机选择任意路径的随机调度器。初始测试结果表明,选择低延迟路径和随机选择路径之间只有很小的差异。
一旦基线建立,即可对延迟为0的不同场景进行 DQN Agent 的训练,其中 delta(ms)∈[0,50]。且考虑到消耗的时间和资源,必须对训练进行限制。此外,假设在训练过程中,不同路径的测量SRTT之间的差异在δ范围内变化,因此Agent将在所有可能的SRTT值中进行训练。图5描述了DQN Agent在训练时间上的演化,以步数(预定数据包)为横轴进行了分析。训练经过130 000步后具有最大的吞吐量,此模型用于训练的验证。
為了比较聚合策略的效率,定义聚合效益(Ag?gregation Benefit,ABen)为:
式中:?是实测吞吐量的平均值,?s 是MPQUIC在单路径场景下的基线平均吞吐量。
图6描述了MPQUIC默认包调度器(SRTT)和训练好的DQN Agent之间的聚合效益对比ABen。可以看到,尽管DQN Agent仅在0延迟场景下训练,但聚集效益在delay(ms)∈[0,50]范围内得到了提高,验证了实验假设。
综合效益在4.45%和7.58%之间得到改善,见表1。
为了测试DQN Agent的鲁棒性,文章使用背景流量进行了重复实验。为此,在Agent的训练和测试过程中,通过网络的 2 条路径生成背景 TCP 流量。由于在之前的场景中取得了不错的效果,只在0 延迟场景中重复训练DQN Agent,并在24 050步取得了最大的吞吐量。使用训练好的代理,得到了类似的改进结果,但只有 delay(ms)∈[ 0 ,20 ]。从30 ms的差异来看,聚合效益的改善下降到1 %,如图7和表2所示。
4 结论与讨论
文章分析了深度强化学习在一个具体的流量管理问题中的应用,即多路径环境下的数据包调度问题。在实验中,证明了在实时环境中使用DQN Agent来提高包调度器性能的可行性,以及使用这种技术对新的5G网络进行优化的潜力。在实验过程中使用了一个全连接层的DNN。今后可以尝试引入其他具有时间记忆的模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型可以更好地预测路径条件的变化,从而更好地学习最优行为。离线-在线架构工作良好,但仍需要占用大量的资源和时间,使得工作效率还有待提升。今后可以使用预训练的方法,通过使用Gym OpenAI环境来模拟网络和多路径行为。研究过程中将 DQN Agent与MPQUIC协议集成,将Agent动作定义为选择发送数据包的路径,结果并不理想不足以解决完整的问题,今后可能需要 DQN Agent 通过控制MPQUIC的更多方面,如重传控制或数据包来进行更加充分的集成。最后,在奖励方面,定义的微调也可以促进学习的改进,这也是今后改进的方向。
文章深入探讨了基于深度强化学习的多路径调度模型,并将其应用于网络流量优化问题中。通过对模型的构建、训练以及实验验证,得出了以下结论:
(1)模型有效性。文章设计的深度强化学习多路径调度模型在复杂的网络环境中表现出了显著的有效性。通过不断地学习和调整,模型能够自适应地选择最优路径,实现网络流量的高效调度。
(2)性能优势。与传统的调度算法相比,基于深度强化学习的多路径调度模型在多个评价指标上均表现出了明显的优势。特别是在高负载和网络拥堵的情况下,该模型能够更好地平衡网络负载,减少数据包的丢失和延迟。
(3)可扩展性。文章提出的模型具有良好的可扩展性。通过调整模型的参数和结构,可以将其应用于不同类型的网络和调度场景,满足不同的流量优化需求。
虽然文章取得了一定的研究成果,但仍存在一些有待解决的问题。未来的研究可以进一步探索模型的优化策略,提高其适应性和鲁棒性。同时,也可以考虑将更多先进的深度学习技术引入到多路径调度中,以实现更高效、更智能的网络流量管理。
综上所述,基于深度强化学习的多路径调度模型在网络流量优化方面表现出色,具有广阔的应用前景和研究价值。文章为网络流量管理提供了新的思路和方法,对于提升网络性能和服务质量具有重要意义。
参考文献:
[1]石红晓,程永志. 基于5G核心网的网络演进及策略研究[J]. 通信与信息技术,2020(4):39-41+50.
[2]贾靖,王恒,夏旭,等. 空地一体网络接入选择与切换控制技术研究[J]. 无线电通信技术,2023,49(5):826-833.
[3]高菁阳.下一场战役:人机对话 — —对话Siri创始人诺曼(Norman Winarsky)[J]. 清华管理评论,2017(Z2):8-13.
[4]廖彬彬,张广兴,刁祖,等. 基于深度强化学习的MPTCP动态编码调度系统[J]. 高技术通讯,2022,32(7):727-736.
[5]LI J,Dang X,LI S. DQN- based decentralized multi-agent JSAP resource allocation for UAV swarm commu?nication[J]. Journal of Systems Engineering and Elec?tronics,2023,34(2):289-298.
[6]夏雨峰,占敖,吴呈瑜,等. 基于MPTCP耦合的自适应带宽估计算法[J]. 无线电通信技术,2022,48(2):336-341.
[7]黄培纪,蒋艳,陈斌,等. 基于线性规划的MPQUIC调度算法[J]. 计算机时代,2023(6):38-42.
Multi-path Scheduling Model Based on Deep Reinforcement Learning
ZHAO Jing
(School of Information Engineering, Lanzhou Vocational Technical College,Lanzhou Gansu 730070,China)
Abstract::In this paper, a multi-path scheduling model based on deep reinforcement learning is proposed,and deep learning technology is applied to traffic management in aggregation scenario to solve the problem of packet scheduling in multi-path environment. A multi-path Quick UDP Internet Connection is used to implement path se?lection in multi-path scenarios, and an agent is trained to improve the optimal path selection algorithm, demonstrat?ing the advantages of applying DQN Agent to data traffic management problems. Experiments demonstrate the feasi?bility of using DQN Agent to improve the performance of packet scheduler in real-time environment, and the poten?tial of using this technology to optimize the new 5G networks. The experimental results show that the multi-path scheduling model based on deep reinforcement learning can adaptively adjust the path selection strategy, thereby improving the stability and reliability of the network. The improved model not only has theoretical value, but also provides useful reference for practical application.
Key words::5G network; multi-path; packet scheduling; deep reinforcement learning; QUIC; MPTCP
