大数据环境下位置轨迹安全存储系统研究与实现
2024-06-01何博宇潘洪志
何博宇 潘洪志


摘要:随着大数据技术的迅猛发展,位置轨迹数据的广泛应用为经济和社会带来了巨大的价值。然而,在大数据环境下,位置轨迹的存储涉及用户隐私和数据安全等关键问题。为了解决传统存储系统在面对大规模数据和隐私泄露等挑战时的不足,文章研究和实现了一种安全的位置轨迹存储系统,提出了一个安全存储的架构,包括数据采集、存储、访问控制和加密等模块,旨在分布式存储环境下实现高效且安全的位置轨迹管理。通过实验评估,文章验证了系统在性能、安全性和隐私保护方面的有效性。结果表明,与现有系统进行对比,新系统在保护用户隐私方面具有显著优势。
关键词:位置轨迹;用户隐私;数据安全;存储系统;访问控制
中图分类号:TP31 文献标识码:A
文章编号:1009-3044(2024)10-0077-04
0 引言
在当今数字时代,大数据技术的迅猛发展使得位置轨迹数据成为大规模应用领域的重要组成部分。随着移动设备和传感器技术的普及,个体的位置信息不断被记录和传输,为城市规划、智能交通、个性化服务等领域提供了丰富的数据资源。然而,大数据应用的不断深入对位置轨迹的存储、管理和分析提出了更高要求,特别是在涉及用户隐私和数据安全的情况下。传统的位置轨迹存储系统在面对大规模数据、隐私泄露和数据安全等方面面临诸多挑战[1]。位置数据的集中存储往往成为潜在的隐私泄露点,而传统系统的安全性机制在大数据环境下显得愈发不足以应对多变的威胁[2]。因此,为了更好地平衡大数据应用的需求与用户隐私的保护,本研究致力于提出一种全新、高效且安全的位置轨迹存储系统。
通过对相关工作的深入研究,我们发现现有系统在位置轨迹安全存储方面存在一些不足,包括对隐私的忽视、安全性机制的薄弱以及在大规模数据处理方面的性能等问题[3]。鉴于此,本研究旨在设计一种新型的位置轨迹安全存储系统,以弥补现有系统的不足,实现对用户隐私的更全面保护,并确保数据在大规模环境中的高效存储和管理。本文将详细介绍系统的设计和实现过程,并通过实验验证其有效性。这一研究将为大数据环境下位置轨迹存储的安全性提供新的思路和解决方案,对于推动大数据应用的发展、维护用户隐私权具有重要的学术和实际价值。
1 相关工作
位置轨迹数据的存储和安全性问题在大数据环境下备受关注[4]。传统的位置轨迹存储系统,如Ha?doop Distributed File System(HDFS) 和一些关系型数据库系统,尽管在大规模数据处理方面表现出色,但它们在隐私保护方面存在局限[5]。这些系统通常缺乏针对位置数据的细粒度访问控制和匿名化技术,导致隐私泄露的风险上升。为了解决位置数据的隐私问题,研究者提出了一系列隐私保护技术。差分隐私技术通过在数据中引入噪声来保护隐私,但其在大规模数据环境下的应用效果仍存在争议。同态加密技术能够在数据加密的同时进行计算,但其性能开销可能限制其在大数据场景的实际应用。在分布式存储领域,一些系统如Ceph和GlusterFS提供了强大的分布式存储能力[6]。然而,这些系统在位置轨迹数据的安全性和隐私保护方面未能提供足够支持,缺乏对用户隐私的细粒度管理和多层次加密等关键特性。随着大数据应用的广泛发展,一些国家和地区制定了涉及隐私保护的法规,例如欧洲的通用数据保护条例(GDPR) 和美国的《加州消费者隐私法案》等,对位置数据的合法收集和处理提出了更为严格的要求,为研究位置轨迹安全存储系统提供了法律框架。
尽管已经有一些关于位置轨迹数据存储和隐私保护的研究,但现有工作在安全性、隐私保护和大规模数据处理方面仍存在不足。本研究旨在借鉴和改进现有工作,设计一种更为全面、高效的位置轨迹安全存储系统,以适应大数据环境下的复杂需求。
2 面向加密的轨迹安全存储的系统总体框架设计
传统数据存储模型采用集中式存储结构,数据存储在单一的高端服务器上。这种架构的扩展性有限,随着数据量的增长,性能和容量瓶颈问题越来越突出。而分布式存储系统将数据分散存储在多台独立的x86服务器上,通过通用的存储协议对外部提供多种存储接口。这种架构使用若干台存储服务器共同分担存储压力,采用IP和IB网络结构,不仅提高了系统的稳定性,也适应了互联网数据量增长的趋势。因此,本文选择分布式存储模型来存储位置轨迹数据,并构建系统总体框架,如图1所示。
此框架中,用户通过客户端向外部发出请求。当正常建立连接后,客户端发起的相关数据操作会发送到资源调度中心。资源调度中心解析这些请求,并将任务调度到控制节点,再由控制节点下发作业给计算節点执行。这些节点会运行MapReduce作业,计算完成后,通过资源调度中心与HDFS文件系统交互,确认是否有作业要求存储。HDFS通过在多个服务器上分布式地存储大文件的数据块,每个数据块会有多个副本分散存储在不同的节点上,以确保数据的持久性和容错性。在计算节点中,该系统可以运行相关差分隐私算法,在数据聚合或分析过程中加入噪声,根据数据类型和隐私需求选择合适的噪声,以确保其既有效又符合预期的隐私标准。
3 系统详细设计
3.1 系统拓扑结构
为了满足大数据环境下大量数据存储的高可用性,该系统采用了树型模型作为网络拓扑结构。该结构中各节点均支持动态增删节点,当某一控制节点出现故障时,只会影响该节点及其子节点,不会影响其他分支节点的工作。由于故障较易隔离,因此采用此拓扑结构易于管理维护,如图2所示。
在图2中,资源调度中心负责将作业下发到控制节点。控制节点根据服务器资源环境对计算节点进行集群安排以完成作业。整体结构呈现为树型模型,这种结构无须对网络进行任何改动即可扩充工作站。在系统运行过程中,资源调度中心会监控各节点的资源情况,并根据分类将作业输送到相应的控制节点。针对不同业务需求,系统生成相应的作业命令,以达到预期的存储效果。控制节点作为拓扑结构中的重要组成部分,除了负责监控节点资源和下发作业外,还具备数据处理后调度HDFS存储数据的功能。根据用户的需求,控制节点能够实时反馈进度,具有较高的可用性。
3.2 系统描述
本系统采用树状分布式存储架构,由多个节点构成,每个节点均负责存储和处理位置轨迹数据。通过引入元数据服务器来协调各节点的工作,实现对位置数据的全局视图和元数据的可追溯性。数据存储依赖于HDFS的Block存储机制,采用分块存储的方式来确保数据的安全性。通过数据压缩、去重和脱敏等技术,高效的数据采集和预处理模块在降低数据体积的同时保护敏感信息,确保数据质量和隐私安全。系统引入了基于角色的访问控制和细粒度访问控制机制,结合访问令牌和身份验证技术,确保仅授权用户能够访问特定的位置轨迹数据。同时,通过应用同态加密和差分隐私技术,系统在数据传输和存储过程中保护了位置数据的隐私性并降低了其敏感性。系统通过并行计算、负载均衡和分布式缓存等技术优化了性能,具备良好的可扩展性,能够轻松應对不断增长的位置轨迹数据和用户数量。总体而言,本系统设计充分考虑了隐私保护、性能优化和可扩展性等因素,为大数据环境下位置轨迹的安全存储提供了全面有效的解决方案。
3.3 系统实现
系统实现过程包含架构设计、数据存储设计、位置轨迹数据采集与预处理、访问控制和加密、性能优化和可扩展性、元数据管理等步骤。
1) 架构设计。系统采用树状分布式存储架构,由多个节点组成,每个节点负责存储和处理位置轨迹数据。同时,引入元数据服务器,用以管理位置数据的元信息,并协调分布式系统中的各个节点。
2) 数据存储设计。数据存储主要依赖于HDFS的Block存储机制,通过分块存储实现对位置轨迹数据的安全存储操作。每个节点能够有效管理自身分配的存储空间,并实现数据的冗余备份,以确保数据的安全性。
3) 位置轨迹数据采集与预处理。系统实施高效的数据采集模块,从多个源头收集位置轨迹数据。通过数据压缩、去重和脱敏等预处理技术,降低数据体积,同时保护敏感信息,确保数据质量和隐私安全。
4) 访问控制和加密。引入基于角色的访问控制(RBAC) 和细粒度访问控制机制,允许管理员对用户进行权限管理。采用访问令牌和身份验证技术,确保只有合法授权的用户能够访问特定的位置轨迹数据。同时,使用同态加密技术对位置数据进行加密处理,并结合差分隐私技术,提高隐私保护水平。
5) 性能优化和可扩展性。通过并行计算、负载均衡和分布式缓存等技术,优化系统性能,确保系统具备良好的可扩展性,能够轻松应对不断增长的位置轨迹数据和用户数量,保持高效运行。
6) 元数据管理。实现元数据服务器,存储位置数据的元信息,包括数据的所有者、访问权限等信息。通过元数据管理,实现对位置轨迹数据的全局视图和元数据的可追溯性。
4 系统测试结果与分析
物理机采用Intel(R) Core(TM) i7-10700K CPU @3.8GHz,拥有32GB 内存,运行64 位Windows 操作系统,其上装有9台CENTOS 7.9.2009虚拟机(Py3.7.9) ,每台虚拟机配置为2核CPU、1GB内存。本次实验测试主要是通过Hadoop集群环境模拟,对比在实际环境下传统存储方式与利用MapReduce对位置轨迹数据进行差分隐私保护的分布式存储在存储效率和数据安全性的差异。实验数据来源于美国联邦公路局的NGSIM数据采集项目,作为数据源模拟Hadoop分布式文件系统HDFS的基本操作。在数据存储过程中,会创建存储目录,读取给定数据源的数据,并将文件数据分割成若干块进行存储,每块的大小由文件大小除以节点数量得出。此外,考虑到噪声大小对数据的影响可能会干扰测试结果,我们通过对原始数据转换数组后为每个元素添加拉普拉斯噪声,并引入动态函数,结合数据的字段数量动态调整噪声大小值,即由epsilon参数控制。
4.1 测试结果分析
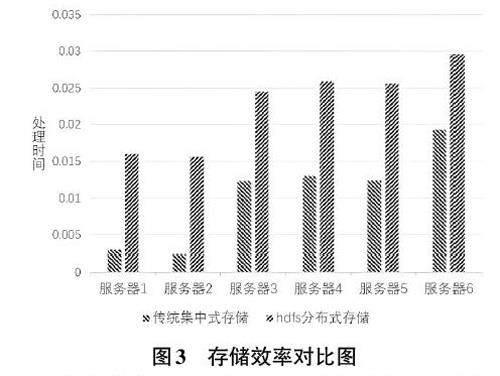
1) 存储效率对比。实验通过对比传统存储方式与差分隐私分布式存储的效率,相关测试结果如图3 所示。
通过随机抽查,本文对六台服务器进行测试,在给定相同数据量的前提下,对比了传统集中式存储和HDFS分布式存储的性能。本文利用后台日志数据,计算了两种不同架构对额定数据量的存储处理时间,并进行了对比分析。在实验中,前两组服务器进行了单文件存储测试,而后四组则进行了多文件存储测试。实验结果表明,在额定数据量下,HDFS分布式存储的应用效果更佳,显著提升了存储效率,符合系统开发性能要求。
2) 数据安全性对比。实验测试的主要目的是验证HDFS+Laplace架构在存储效率相较于传统存储更优的情况下,其数据隐私保护的效果,实验结果如图4 所示。
实验测试主要是通过对比传统数据隐私保护和差分隐私数据保护在个体数据对总体数据影响的表现占比情况。在测试过程中,我们均保证了数据的有效存储。传统数据隐私保护采用匿名化数据加密对数据进行隐私保护,而差分隐私数据保护则通过添加拉普拉斯噪声对位置轨迹数据进行差分隐私保护。测试结果表明,通过添加噪声,成功实现了数据隐私安全,显著降低了个体数据对总体数据的影响,有效满足了大数据环境下数据存储的实际需求,并且不会对数据存储操作的安全性造成负面影响。
当存储系统的前端和后端运行完毕后,该系统主要利用数据采集模块对位置轨迹数据进行MapRe?duce分组聚合运算,并进行安全存储。其中,该系统在后台页面添加了动态调整隐私保护强度的功能,主要是为了适应实际环境的需要,并且限制单次允许的最大上传文件大小,以提高系统稳定性。当用户在系统前端提供设备数据接口给数据上传模块后,后台将根据数据大小计算预计的存储时间,用户可以在存储效率面板的选项卡中查看存储完成的预计时间。后台管理人员在此期间可在数据采集模块下查看相关数据文件,监测并观察保护进度。如若出现类似输出,则表示一切正常,数据正在进行安全计算处理。
5 结束语
本文围绕位置轨迹数据隐私安全保护存储系统的设计方案展开探究,主要针对位置轨迹数据在存储方面的安全管控进行设计。系统选取HDFS分布式存储作为框架,构建了系统整体框架。该系统以资源调度中心为管理工具,下发作业到控制节点进行差分隐私保护计算,并利用MapReduce对数据进行拉普拉斯噪声的添加。测试结果显示,在保证存储效率明显优于传统存储效率的同时,该系统能够有效地对数据进行隐私保护,可以作为位置轨迹数据存储管理工具。
参考文献:
[1] 李乐彤,田源,胡舜欣,等.基于差分隐私的轨迹保护综述[J].中国科技信息,2022(24):91-94.
[2] 吴万青,赵永新,王巧,等.一种满足差分隐私的轨迹数据安全存储和发布方法[J].计算机研究与发展,2021,58(11):2430-2443.
[3] 刘雯雯.基于云计算环境下的计算机网络安全存储系统的设计与实现[J].电脑知识与技术,2022,18(12):38-40.
[4] 秦呈旖,吴磊,魏晓超,等.位置轨迹相关性差分隐私保护技术研究与进展[J].密码学报,2023,10(6):1118-1139.
[5] 盛丹丹.基于大数据分析的隐私信息保护系统设计与实现[J].信息安全研究,2023,9(9):914-920.
[6] 王爱兵.基于区块链的社区矫正系统数据分布式安全存储方法[J].电脑知识与技术,2023,19(28):63-65.
【通联编辑:代影】