人工智能技术对电子商务领域的影响探究
2024-05-30杨晓茜
杨晓茜
(辽宁金融职业学院,辽宁 沈阳 110122)
0 引言
随着网络技术的不断发展和应用,中国逐渐步入了“智联型”智能物联网(AIOT)的时代,而人工智能技术则是其中一个重要的组成部分。人工智能技术是当前信息技术的核心,在通信系统、物联体系中起到了十分关键的作用。借助人工智能技术能够更好地开发先进的网络系统,从而提高物联网的智能化和自动化水平。比如智能手机、工业4.0、可穿戴的设备等就有很多采用遗传算法、BP神经网络和SVM等技术,并基于这些技术进行了算法的创新,如语音识别、视频图像处理以及大量的数据分析处理等[1]。对于电子商务行业而言,将人工智能技术应用于其中可以提升消费者的购物体验,满足消费者的层次需求。但人工智能技术在发展的同时也出现了一些恶意评论的情况,直接误导了消费者的购物方向,同时也给电商行业的诚信度体验造成较大的影响。有学者基于人工智能技术中的D-S证据理论进行分析,该理论是一种不确定推理方法,它比贝叶斯概率具有更少的约束条件,可以对不确定性信息进行直接处理[2]。在此基础上,借助人工智能的电商差评检测算法,通过降低待鉴别对象的不确定性,有效提升电商差评的识别性能,实现对虚假评论的更精确检测。
1 人工智能技术应用于电子商务虚假评论的检测方式
1.1 评论信息的采集
本文基于分布式评论分析的方式将信息收集系统应用于电子商务工作的评论工作中。如图1所示为在样本触发控制下抓取机器从网上收集电商平台上的产品信息,该预处理模块根据收集到的产品信息,通过统一资源定位器(Uniform Resoure Locator,URL)连接,对最新评论数量、评论时间等进行初始化,并对商品URL进行管理,根据收集周期调节模块的收集周期设置,将项目URL放入回收的队列中。一种与Hbase模块相结合的基于商品URL排序的分布式增量抓取模型,可实现电商平台上的商品评论信息的增量收集与增量存储,同时也能达到对评论信息的实时监控[3]。

图1 分布式评论信息采集系统
1.2 评论者的特征识别
评论人评论内容的情感特性可以从评论属性词的覆盖率、第一人称使用频率、情感词汇使用频率、平均评分差异、初次评论时间间隔、初次评论与最后一次评论之间的时间间隔几个方面进行选择。
1.2.1 属性词包含率
因为错误评论者对产品的评价都是虚构的,因此在评价中很少会出现具体的细节。因此,在所有评论内容的单词q(rp)中如果商品属性单词s(rp)的覆盖率较低,则评论者是不实评论者的可能性较大,其公式表达如下。
(1)
1.2.2 第一人称代词使用率
第一人称代词可以提高评价的准确性。因此,定义了在评论内容的所有词汇集q(rp)中第一人称词语d(rp)的使用率愈高,则评价者为不实评论者的可能性愈大,其公式表达如式(2)。
(2)
1.2.3 情感词使用率
在评价的过程中用户的情绪表现是一种线性的,而不是真实的评价者。因此,在所有的评论内容词汇q(rp)中情绪词w(rp)使用率愈低,则评论者是不实评论者的可能性愈大,其公式表达如式(3)。
(3)
1.2.4 商品类别包含率
与真评论者相比,虚假评论者在评论中所涉及的物品种类很少。因此,在产品评论人的所有评论中定义了含有产品分类的评论的数目c(rp),而产品的总评论数目是C(rp),当第一条评论与第二条评论的比例较小时,评论人是不实评论的可能性较大,其公式表达如式(4)。
(4)
1.3 虚假评论者检测
在目标辨识层次上,D-S证据理论以可信度函数代替概率,实现了不需要事先已知条件下的不确定推理[4]。利用D-S证据理论,对评论中评论内容的情绪特性、产品兴趣等因素对评论人的识别能力。用zeta来描述一个具有穷尽性,将其作为一种检测信息的方式,并在此基础上使用2zeta表示所有的子集。借助D-S证据理论的算法对评论者进行判断,基于检测结构zeta的Mass函数的表达如公式(5)。
v:2ζ→[0,1]
(5)
多源信息融合即多传感器数据融合,其关键是对同一或不同模态的多源信息进行综合分析,获取具有相关性和整体性的信息。其中,决策层融合是三级融合研究的最终结果,而D-S证据理论作为一种重要的决策方法,因其所依据的概率赋值(BPA)对决策结果产生重大影响,因此,采用基于贝叶斯统计的决策模型对决策过程中的关键问题进行研究,目前的研究多依靠人的经验实际应用效果较差。SVM由于其较好的理论依据及分类结果,与D-S证据理论进行融合可构建出更合理、更高效的BPA,提高识别率。根据评论者特征的不同建构出对应的Msaa函数,其模型构建如公式(6)
(6)
公式(6)中,Pn(w)表示为特定的概率密度函数,在公式(1)的基础上将该公式进行输出和转换,即可得到对应的概率分配,具体表达如公式(7)
(7)
2 仿真测试
为检测人工智能技术应用于电子商务虚假评论中的应用成效,本研究通过模拟实验验证了该算法在电子商务中的应用效果。考虑到电商平台上的评论信息获取和发现过程中蕴含着大量的数据,本研究以Storm为平台搭建4个虚拟节点的Storm集群。所有的虚拟节点都使用了免费Ubuntu19.04,CPU和内存则是inteli5-7400LGA115114nm-3.0GGHz、8 G,StormComponent使用Nimbus绩效管理软体及Supervisor管理与维护软件。同时,以EC-SHOP网站为平台搭建虚拟电商平台,设置评论人2000人,真实评论人数与虚假评论人数相同。在此模拟系统中对所提算法的探测性能进行验证。
2.1 评论者信息采集
每小时的数据处理规模可以用产量来表示。在模拟实验中利用所提的方法收集评价对象的评价信息并对其进行评价。通过对不同节点数目的产品评价信息收集所需的时间进行比较,对本文提出的方法的生产率进行验证,在不同的虚节点数目下收集过程重复10次取平均值,具体如表1所示。
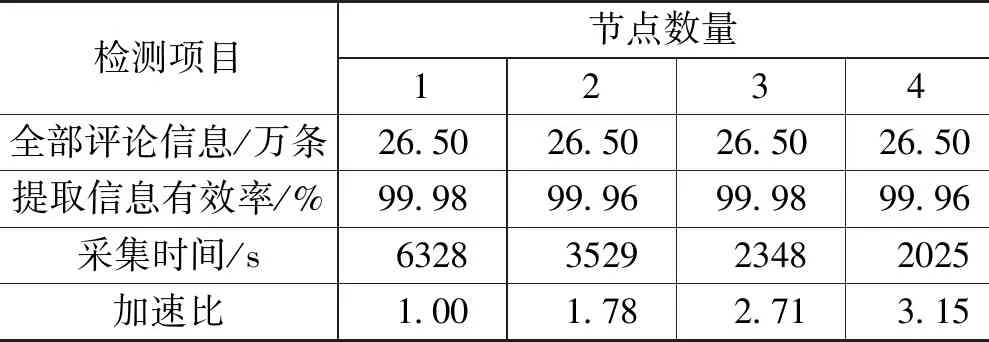
表1 Mass集群算法吞吐实验检测结果
通过表1的数据可以看出,Mass集群算法在实际检测的过程中能够耗费较少的时间加快检测的速度,对于提升检测的效率具有较好的效果。
2.2 虚假评论检测结果分析
利用SVM模型计算各个ass函数的基本概率值,然后融合各个ass函数,获得真实评价者、虚假评价者以及不确定性的评价,将y1和y2设为0.1、0.2,得到虚假评论者的检测结果,如表2所示。

表2 虚假评论检测部分结果分析
从表2的数据可以看出,将虚假评论检测方式应用于评论中其检测的准确率可以提升至100%以上,说明该种方式可以用于电子商务虚假评论的检测当中。
3 结语
本研究基于前者研究的基础上提出了D-S证据理论算法,利用支持向量机模型确定真实评论者、虚假评论者和不确定的赞同度,完成虚假评论者检测。得出的结果提示将虚假评论检测方式应用于评论中,其检测的准确率可以提升至100%以上,将其应用于电子商务工作中可以提升消费者的购物体验。
