基于多尺度特征融合的轻量化道路提取模型
2024-05-25刘毅陈一丹高琳洪姣
刘毅,陈一丹,高琳,洪姣
(天津城建大学 计算机与信息工程学院,天津 300384)
随着卫星遥感技术的迅速发展,高分辨率遥感图像的应用日益广泛.从遥感图像中提取出的道路信息可被应用于车辆导航、智慧交通[1]、应急救援、城市规划[2]、图像注册、地理信息更新[3]等领域.近年来,遥感图像道路信息的提取逐渐成为研究热点.
常见的道路提取方法分为传统方法和基于深度学习的提取方法[4].传统方法需要人工设计道路特征提取方案.Shi 等[5]通过分析光谱特征,实现从光学遥感图像中提取道路中心线,但结果存在噪声问题.王小娟等[6]利用二维Otsu 阈值分割法提取道路特征,对质心点进行拟合操作,得到道路图像.Chang 等[7]提出BO-MWSA 算法,通过改进分水岭分割算法,引入波段运算和标记法,利用NTL 图像实现道路提取.上述传统提取方法设计分类规则的过程较复杂,道路提取效率低下,同时泛化能力较差,存在普遍的误分类现象,导致分割精度较低.
基于深度学习的道路提取方法利用语义分割模型训练遥感图像数据集,利用得到的参数模型提取道路信息,具有更加卓越的特征提取能力[8],适用于从海量数据中挖掘抽象复杂的深层特征并完成数据的分析与处理[9].Mnih 等[10]提出用卷积神经网络CNN 提取遥感图像道路信息,采用条件随机场优化分割结果.Zhong 等[11]将实现图像像素级别分类的全卷积神经网络FCN 用于道路提取,然而FCN 网络预测时仅考虑单个像素,忽略了像素之间的关系,造成预测结果细节缺失的现象.Hou 等[1]构建基于互补的神经网络C-unet 模型,用于道路提取.Wang 等[12]结合残差单元和UNet 模型,实验部分选用遥感图像数据集Massachusetts roads[13]训练网络,但仍出现细小路段漏提的现象.
Google 团队提出一系列DeepLab 模型[14-17],其中DeepLab V3+骨干网络采取Xception[18],通过ASPP 模块整合多尺度特征并引入编码-解码[19]结构优化网络,分割性能更具优势.赵凌虎等[20]基于DeepLab V3+改进主干网络,结合Dice Loss 函数[21]提高模型的道路提取精度.孟庆宽等[22]采用金字塔池化模块,获得多尺度道路信息特征.基于注意力机制和多尺度特征融合的遥感图像分割网络取得了一系列研究成果[23].张文博等[24]提出改进DeepLab V3+模型,在主干网络引入多尺度金字塔卷积融合多尺度特征,在解码层引入注意力机制优化分割边缘信息.张小国等[25]提出FDADeepLab 模型,引入双注意力机制,融合高级和低级特征,使用样本难度权重调节因子解决样本的非均衡性问题.许泽宇等[26]提出的E-DeepLab 模型通过加成连接的方式将编码器与解码器结合,提出改进的自适应调节损失权重方法.利用上述模型虽然提高了分割精度,但网络结构较复杂,参数规模较大,对于分割种类较少的道路提取任务不占优势.
为了实现对道路的高效率、高精度提取,解决当前语义模型参数量较大和对细小路段提取效果较差的问题,本文提出基于多尺度特征融合的轻量化遥感图像道路提取模型MFL-DeepLab V3+.设计轻量型特征提取网络并在ASPP 模块引入深度可分离卷积,减少模型参数量,提高模型的分割效率和性能.对解码区的特征融合部分进行优化设计,提出联合注意力的多尺度特征融合方法,结合网络浅层的道路细节特征与深层特征,引入注意力机制增强道路提取的完整性和准确性.
1 基础网络模型
DeepLab V3+[17]基于全卷积网络,采用编码器-解码器架构,融合多尺度特征和多分支并行结构,网络结构如图1 所示.

图1 DeepLab V3+网络结构Fig.1 DeepLab V3+network architecture
在遥感道路提取领域,利用该网络模型可以提高对目标道路特征及道路边缘信息的关注度,具有分割精度较高的领先优势.DeepLab V3+网络编码区由骨干特征提取网络Xception 和ASPP 模块组成.输入样本图像经骨干网络Xception 中的卷积操作提取初步特征,ASPP 模块使用多分支的并行结构,集合了1×1 卷积与3 个扩张率分别为6、12、18 的空洞卷积,获得不同尺度的感受野并提供更大感受野,解决池化导致的道路目标像素丢失问题.解码区首先上采样ASPP 模块输出的高维特征层,再将输入图片的空间结构还原,对深层特征图进行上采样,使之与具有较高空间分辨率的浅层特征图空间尺寸一致,进行通道堆叠.将浅层特征与深层特征融合后,恢复下采样过程中损失的空间信息.
2 方法简介
2.1 MFL-DeepLab V3+模型
提出的遥感图像道路提取模型MFL-DeepLab V3+基于编码-解码结构,分别在DeepLab V3+网络的编码区及解码区提出改进.MFL-DeepLab V3+网络结构图如图2 所示.
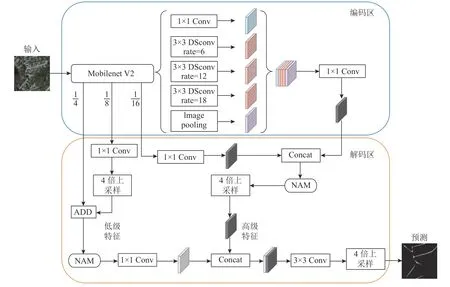
图2 MFL-DeepLab V3+网络的结构图Fig.2 Structure diagram of MFL-DeepLab V3+network
编码区.为了解决道路特征提取网络计算复杂度较高的问题,将骨干特征提取网络设计为轻量化的Mobilenet V2[27].为了使网络精准捕获道路上下文信息,减少网络参数量并提高计算效率,在ASPP 模块3 个平行的空洞卷积中引入DSConv.
解码区.为了改善模型对道路的提取效果并提高分割精度,提出联合注意力的多尺度特征融合MFFA.MFFA 对Mobilenet V2 中提取到的2 条不同大小的浅层特征进行通道维度拼接,改进的ASPP 模块输出的特征图与另一浅层特征相加.由此得到2 个多尺度特征,引入注意力机制,避免无用特征干扰,提高道路提取的准确率,最后进行浅层和深层特征的融合.
2.2 轻量型特征提取网络
由于DeepLab V3+模型的骨干网络Xception 参数量较多,将模型应用于遥感图像道路提取领域的总体计算量大且耗时长.针对上述问题,引入轻量化的Mobilenet V2 网络作为MFLDeepLab V3+的骨干网络.Mobilenet 系列网络通过引入深度可分离卷积[28](depthwise separable convolution,DSConv),有效减少了网络的运算量及参数量.与上一代网络相比,Mobilenet V2 网络增加了线性瓶颈结构和倒残差结构.
Mobilenet V2 网络的结构如表1 所示.表中,t 为瓶颈层内部的升维倍数,c 为特征维数,n 为瓶颈层的重复次数,s 为瓶颈层第一次卷积的步幅.为了减少特征丢失,Mobilenet V2 在通道压缩过程中使用Linear 函数作为激活函数,使用倒残差取代残差,扩张层使用线性激活层取代非线性激活层,避免输入的特征信息丢失,提升网络对道路特征的提取能力.

表1 Mobilenet V2 网络的结构Tab.1 Structure of Mobilenet V2
Mobilenet V2 残差结构如图3 所示.相比传统方式直接使用3×3 卷积,倒残差结构通过1×1 卷积升维扩张输入特征通道,利用1×1 卷积层降维,减少特征通道数.利用该方法,有效减少了网络参数量,降低了运算量.Mobilenet V2 引入深度可分离卷积代替传统的卷积方式,使用尺度系数缩减模型通道数,通道数缩减后,特征信息集中在缩减后的通道中.

图3 Mobilenet V2 残差结构图Fig.3 Residual structure of Mobilenet V2
2.3 改进的ASPP 模块
为了避免模型在编码过程中的连续最大池化操作造成图像分辨率的损失,在ASPP 模块中引入深度可分离卷积模块DSConv.DSConv 分为深度卷积和逐点卷积两部分,结构如图4 所示.F 与G 均为特征图,分别作为模型的输入和输出.DF、DG分别为F 与G 的宽和高,M、N 分别为F 与G 的通道数.深度可分离卷积中深度卷积的卷积核尺寸为DK×DK,逐点卷积中的卷积核大小为1×1.
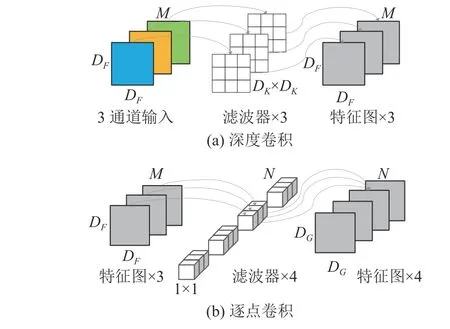
图4 深度可分离卷积Fig.4 Depthwise separable convolution
例如输入一组DF×DF×M 大小的特征图,输出大小为DG×DG×N,且普通卷积的卷积核尺寸为DK×DK,标准卷积计算量NConv的计算公式为
DSConv 卷积计算量被分为以下2 部分.
1)特征图的M 个输入通道使用相同大小的卷积核进行深度卷积,如图4(a)所示,此处卷积计算量N1为
2)如图4(b)所示,DSConv 经逐点卷积输出特征,进行一个点方向的1×1 卷积,此步骤的计算量N2为
最终,深度可分离卷积的计算量之和为
深度可分离卷积与标准卷积的计算量之比为
比值小于1.综上所述,深度卷积相比于标准卷积方式更加高效.
2.4 联合注意力的多尺度特征融合
为了丰富道路图像的局部细节信息,细化模型对道路的分割精度,设计联合注意力的多尺度特征融合机制MFFA,结构如图5 所示.
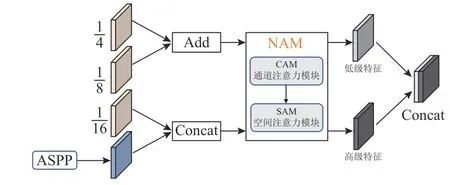
图5 MFFA 机制的结构图Fig.5 Structure of MFFA mechanism
从编码区骨干网络中提取出1/4 大小和1/8 大小的2 条浅层特征,对其进行通道维度的拼接.为了加强特征图中各特征通道表达的特征关系,引入注意力模块,提取更详细的道路图像信息.将编码区经过金字塔池化模块的特征图与1/16 大小的浅层特征进行拼接,引入注意力模块,避免无用特征干扰拟合,得到高级特征并作4 倍上采样,将特征尺寸大小调整为和浅层特征相同的大小.
为了加强网络对遥感图像中道路特征的提取,引入基于归一化的注意力机制[29](normalization-based attention module,NAM),NAM 基于CBAM 注意力机制[30]重新设计通道和空间子模块.NAM 用稀疏的权重惩罚抑制模糊的道路特征,其中批标准化(batch normalization,BN)的比例因子使用标准偏差表示特征权重,具体公式为
式中:Bin、Bout分别为批标准化的输入和输出,µB和σB分别为小批量B 的均值和标准差,γ 和β 分别为可训练的尺度因子和位移,ε 为极小的超参.
NAM 注意力机制结构如图6 所示.NAM 注意力机制的权重由通道注意力模块(channel attention module,CAM)维度和空间注意力模块(spatial attention module,SAM)维度推断得出,通过与输入特征相乘,自适应调整特征.如图7 所示,输入特征F1 首先经过CAM,具体公式为
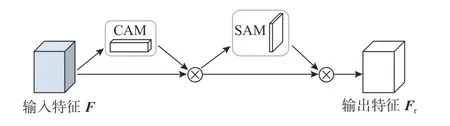
图6 NAM 注意力机制结构图Fig.6 Structure of NAM attention mechanism
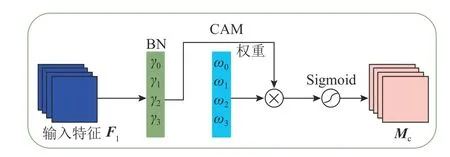
图7 通道注意力模块Fig.7 Channel attention module
式中:Mc为CAM 的输出特征,γi为各个通道的比例因子,Wγ为通道权重.
空间注意力子模块如图8 所示.NAM 在空间维度引入BN 比例因子,以衡量像素的显著程度,称作像素归一化.空间注意力模块SAM 的公式为
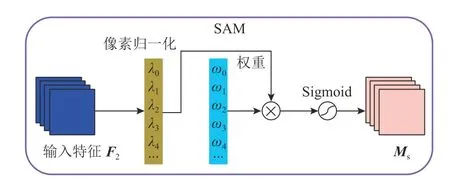
图8 空间注意力模块Fig.8 Spatial attention module
式中:Ms为SAM 的输出特征,Wλ为权重,λi为比例因子.
相较于常见的ECA、SE[31]、CBAM 等注意力机制,NAM 注意力机制无需额外的卷积层和全连接层,将NAM 同时用于提取网络的深层和浅层特征,可以使模型充分学习道路图像中深层特征与浅层特征的空间相关性,提高模型在遥感图像中的道路提取精度.
3 实验与分析
3.1 实验设置
实验采用64 位Windows10 操作系统,使用NVIDIA RTX3080Ti 显卡,1 TB 硬盘存储训练数据,基于Pytorch1.10 搭建模型框架,GPU 运行平台为NVIDIA CUDA11.3.在实验过程中,学习动量设为0.9,基础学习率Ir设为0.001,采用“Poly”学习率衰减策略.批处理大小设为10,迭代轮次总数设为100.为了防止实验结果过拟合,将权重衰减率设置为0.000 2.
为了验证MFL-DeepLab V3+模型的轻量型特征提取网络、联合注意力的多尺度特征融合及融入深度可分离卷积的ASPP 模块的有效性,验证模型用于道路提取的准确性和轻量性,分别在Massachusetts roads 数据集上开展骨干网络对比实验、注意力机制对比实验、不同模块消融实验、不同模型的分割结果对比实验及复杂度分析实验.
3.2 数据集与评价指标
实验使用的遥感影像道路数据来自于Massachusetts roads 数据集[13].该数据集涵盖美国马萨诸塞州多种地区(如城市、农村和山区等)共1 108 张卫星遥感影像,覆盖地理范围超过2 600 km2,每张图片及对应的标签图像均为1 500 像素×1 500像素.由于其标签影像存在数据缺失和标注不准确的问题,从Massachusetts roads 数据集中选取标签标注较准确的300 组图像作为训练样本.将道路图像及对应的标签图像尺寸裁剪为406 像素×406 像素.按7∶2∶1 的比例分配实验所需的训练集、测试集和验证集.由于数据样本过少将导致网络模型的鲁棒性较差,需要扩充数据,将训练集中剪裁后的图像通过旋转、水平或垂直翻转操作,最终数据增强后训练样本扩充至11 340 张.
在遥感图像道路提取任务中,图像像素划分为背景和道路2 类.采用精确率P、每秒传输帧率v、召回率R、参数量Np和F1 分数作为评价指标.P、R 和F1 的计算公式如下:
式中:TP 和FN 分别为模型正确预测道路类和背景类的像素数量,FP 为被模型预测为道路类别的背景像素数量.
3.3 实验结果与分析
3.3.1 骨干网络的对比实验 为了减少网络参数量与计算量,提升道路提取的效率,考虑替换原模型中参数量较庞大的Xception 骨干网络.为了测试替换不同骨干网络对DeepLab V3+算法的性能影响,分别对Xception 网络、常见的Resnet101网络、分割准确率较高的新型网络Efficientnet V2 及轻量型网络Mobilenet V2 进行4 组实验,用F1 和Np作为衡量不同骨干网络适配性的评价指标,实验结果如表2 所示.

表2 不同骨干网络的性能对比Tab.2 Performance comparison of different backbone networks
从表2 可见,各个网络的F1 分数较接近,虽然实验3 中Efficientnet V2 的F1 分数最高,但参数规模较大,参数量达到55.51 ×106.实验4 中骨干网络为Mobilenet V2 时,F1 分数为84.05%,参数量减少至5.13 ×106,远远小于其余网络,相比实验1 中的Xception、实验2 中的Resnet101 和实验3 中的Efficientnet V2,参数量分别减少了92.81%、90.98%和90.76%.经分析可知,Mobilenet V2 可以在保证模型分割性能的情况下大幅减少网络参数量,有效实现模型的轻量化.
3.3.2 注意力机制的对比实验 为了加强神经网络的道路特征提取并提升运算速率,考虑引入注意力机制.基于骨干网络为Mobilenet V2 的改进网络,分别引入4 种常见的注意力机制进行对比实验.
从表3 可见,在加入NAM 注意力模块后,模型分割精度优于ECA、SE 和CBAM,F1 分数高达85.03%,模型运算速率达到2.78 帧/s,可以在提升模型分割精度的同时兼顾运算效率.选择引入NAM 注意力模块,帮助网络提升道路提取性能.
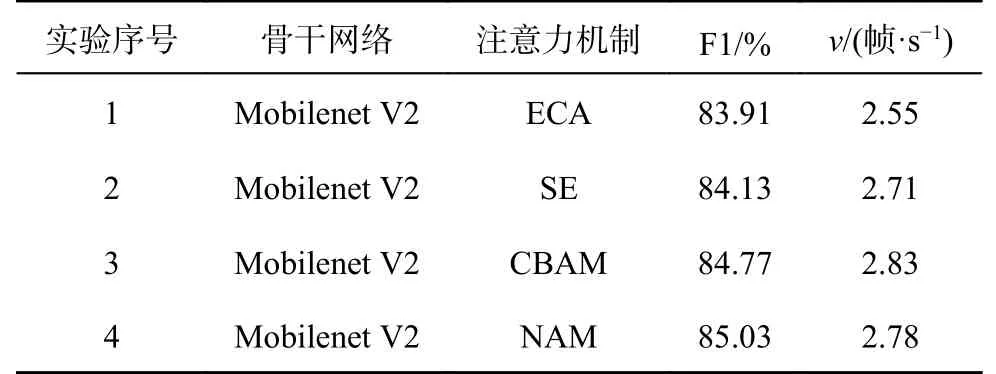
表3 不同注意力机制的性能对比Tab.3 Performance comparison of different attention mechanisms
3.3.3 各模块消融实验 为了验证替换骨干网络后,MFL-DeepLab V3+在以下3 个方面的改进是否有效:用DSConv 代替原卷积、引入NAM 注意力机制以及改进特征融合策略MFFA,根据控制变量法设计5 组消融实验,将F1 和v 作为实验评价指标,实验结果如表4 所示.

表4 MFL-DeepLab V3+模型各模块的消融实验结果Tab.4 Ablation experiment results of different modules of MFL-DeepLab V3+
实验2 和实验3 分别将深度可分离卷积DSConv 引入ASPP 模块和在编码区引入NAM 注意力模块,相较于实验1,F1 分别增加了0.62%和0.98%,v 分别提升至3.45 和2.78 帧/s.在实验4 中同时引入DSConv 与NAM 注意力机制,F1 继续提升至86.96%,v 高达3.36 帧/s.实验5 基于实验4 在特征提取网络中加入改进的MFFA 特征融合模块,虽然较实验4 运算速率降低,但与实验1 相比,v 提高了0.51 帧/s,F1 提高至87.42%,实现了模型分割精度与运算性能的平衡,验证了各个模块的有效性.
3.3.4 不同模型实验结果的对比 为了进一步验证MFL-DeepLab V3+模型的道路提取性能,将该模型与FCN[11]、DeepLab V3+[17]、FDA-DeepLab[25]及E-DeepLab[26]4 种网络模型的精确率、召回率和F1 进行对比.以上网络模型均使用统一的环境配置和Massachusetts road 数据集进行训练和测试.不同模型的道路提取结果对比如图9 所示.根据提取细节可知,各模型在提取道路交界和细小路段方面的表现存在显著差异.FCN 网络的提取效果较差,道路边缘存在信息缺失,道路图像出现大量断裂区域,这些问题导致分割结果与真实道路标签之间存在明显的差异.DeepLab V3+网络在局部出现错漏提取的现象,在树木和阴影遮挡状况下的提取结果明显地不连续.FDA-DeepLab 和E-DeepLab 模型的道路提取效果相较于DeepLab V3+有所提升,但对细小道路和道路交界区域的提取效果不佳,道路局部有断裂现象,道路边缘分割的精确度有待提高.MFL-DeepLab V3+模型的提取效果优于上述4 种模型,成功提取到细小狭窄的路段,错漏提取现象得到改善,有效避免了树木与阴影遮挡对道路提取的影响.

图9 不同道路提取模型结果的对比Fig.9 Comparison of results of different road extraction models
如表5 所示为不同模型的道路提取结果对比,其中FCN 网络的分割精度较低,3 项评价指标均约为80%.DeepLab V3+、FDA-DeepLab 和EDeepLab 分割模型的召回率和F1 分数均小于84%和86%.MFL-DeepLab V3+模型的道路提取精确率提高至88.45%,F1 达到87.42%,召回率达到86.41%,较原模型DeepLab V3+分别提升了1.53%、4.69% 和3.18%.实验结果表明,与其他4 种网络模型相比,本文方法的精确率、召回率和F1 分数均最高,有效提升了道路提取精度.
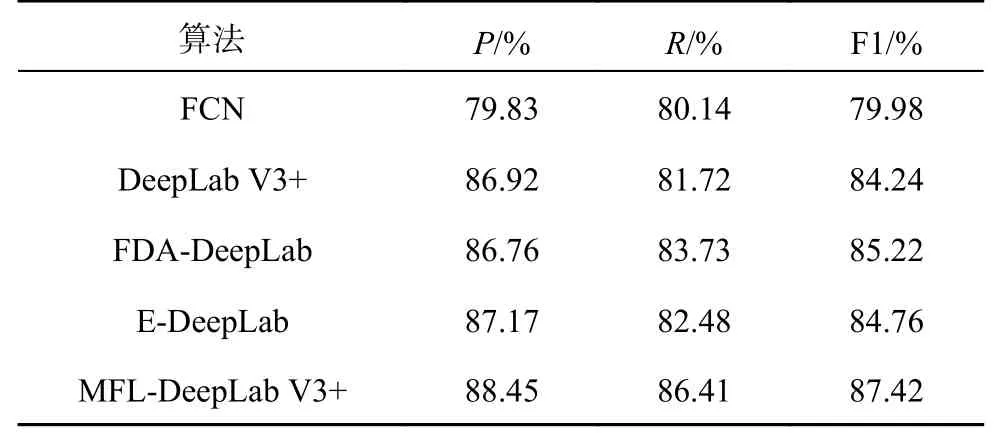
表5 不同模型的性能对比结果Tab.5 Performance comparison results of different models
3.3.5 模型复杂度分析 为了分析MFL-DeepLab V3+模型与原模型的效率和复杂度,通过与原DeepLab V3+模型的单张图片训练时间TTSP、参数量及检测速度进行对比,模型复杂度的分析如表6 所示.
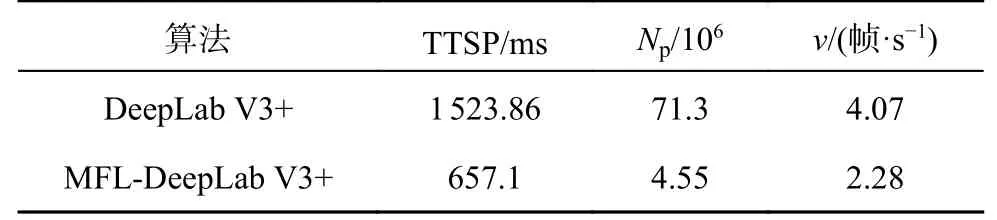
表6 模型复杂度分析Tab.6 Model complexity analysis
结果表明,MFL-DeepLab V3+模型的TTSP 大幅缩减,v 提升了约43.98%;改进后的网络参数量显著减少,模型参数量较原DeepLab V3+压缩了88.67%.MFL-DeepLab V3+模型提高了对遥感图像道路提取的精准度,在识别细窄路段和遮挡路段时表现出色,分割图像完整且边缘平滑,大大缩减了训练时间,在提高提取精度的同时有效兼顾了网络的计算量和参数量,显著增强了分割性能.
4 结 语
为了解决语义模型计算复杂度较高的问题,引入轻量型骨干网络,在ASPP 模块中引入深度可分离卷积模块,减少网络参数量,有效地提升网络的分割性能.各项对比实验表明,提出的基于多尺度特征融合的轻量化MFL-DeepLab V3+遥感图像道路提取模型在精确率、召回率和F1 分数方面均有效提升,道路提取结果完整,边缘清晰,网络参数量显著降低,分割性能更好.为了解决当前遥感图像道路提取领域的语义模型提取效果不佳的问题,重新设计解码区的特征融合部分,通过联合注意力的多尺度特征融合MFFA 加强网络的特征提取能力,在解码阶段有效地恢复道路边界信息,获取高质量的道路细节.MFLDeepLab V3+模型对遥感图像道路提取领域存在一定的参考意义.
在后续研究中,考虑将道路的结构性特点融入道路特征提取网络的设计,结合大量的样本数据,探究兼具分割效率和预测精度的遥感图像道路提取模型.
