基于依存关系图注意力网络的SQL 生成方法
2024-05-25舒晴刘喜平谭钊李希万常选刘德喜廖国琼
舒晴,刘喜平,谭钊,李希,万常选,刘德喜,廖国琼
(1.江西财经大学 信息管理学院,江西 南昌 330013;2.江西农业大学 软件学院,江西 南昌 330013)
关系数据库是当前存储大量结构化数据的主流方式,而查询数据库需要使用结构化查询语言(structured query language,SQL),这对不掌握计算机知识的普通用户而言有一定的困难.Text-to-SQL 任务将自然语言问题(natural language query,NLQ)转换为机器可以执行的SQL 语句,向普通用户提供了自然语言形式的查询接口,极大地降低了数据查询和分析的门槛,因而受到了学术界的广泛关注.
Text-to-SQL 任务需要模型理解NLQ 中所涉及的表和列,理解数据库模式中各个元素之间的关系.如何正确地将NLQ 与数据库模式进行对齐是当前Text-to-SQL 问题的瓶颈[1].将NLQ 中描述的实体和关系映射到数据库模式,这在Text-to-SQL 任务中被称为模式链接(schema linking)[2].由于自然语言的表述具有多样性,问题中对数据库模式的表述不一定与实际的模式名称一致,且数据库中可能存在许多相似的模式名称,这都给模式链接增加了难度.传统的模式链接方法包括规则或字符串匹配,后续的一些模型在编码阶段使用注意力模块,这些方法大多没有考虑句子的语法结构,无法捕捉词语间长距离的依赖关系,导致模型无法正确理解句子的含义,从而无法准确地识别句子中提及的数据库模式.针对上述问题,本文提出两阶段框架.首先使用模式链接器,利用数据库模式结构和问题句子的依存句法关系,在生成SQL 之前对齐问题词和数据库模式,帮助后续模型过滤掉大部分不相关的模式项,降低训练和生成SQL 的难度.在第2 阶段,将对齐信息注入到SQL 生成器中,将它们视为附加上下文,增强SQL 生成的结果.
本文的主要贡献如下.
(1)提出两阶段的SQL 生成框架,其思想是解耦模式链接和SQL 生成,以降低SQL 生成的难度.该方法通过模式链接器识别问题中提及的数据库表、列和值,利用对齐信息指导SQL 生成.
(2)提出基于依存关系图注意力网络的对齐方法,在问题依存句法分析的基础上重塑和修剪依存关系,构建关系图注意力网络(relational graph attention network,RGAT)[3].利用问题的语法结构和模式项之间的内部关系,指导模型学习问题与数据库的对齐关系.
(3)研究对齐信息注入的SQL 生成方法,将对齐信息注入T5 模型,对T5 进行微调,以改进SQL 生成结果.
(4)在公开数据集上进行大规模实验.实验结果显示,本文提出的方法具有良好的性能.
1 相关工作
Text-to-SQL 问题需要模型理解NLQ 在哪些数据库模式上进行查询操作,因此要考虑NLQ 和数据库的模式链接,常用的技术包括注意力机制、图神经网络、预训练模型等.SQLNet 使用列注意力,将列的信息融入NLQ 的单词表示[4].TypeSQL 通过数据库和知识库识别NLQ 中的实体,将实体类型作为输入特征进行编码[5].Guo 等[2]提出模式链接的概念,利用字符串匹配和知识图谱识别问题中的实体,在编码时对问题跨度(span)标注匹配类型(column/table/value),对相应数据库列标注匹配类型(exact match/partial match).SLSQL 对Spider 数据集的模式链接进行标注,证明精确的模式链接可以提高SQL 生成的性能[6].Ryansql 在编码时加入问题-列对齐层(questioncolumn alignment)和问题-表对齐层(question-table alignment),通过注意力机制,增强问题和模式项之间的特征交互[7].Bogin 等[8]通过GNN 建模数据库模式的图结构,提出GLOBAL-GNN[9],使用门控GCN 选择与问题相关的列和表.问题和数据库模式的联合编码有助于二者的对齐.Seq2SQL 将列名、NLQ 和SQL 关键字序列通过Bi-LSTM 编码[10].Rat-SQL[11]在Transformer[12]的基础上增加关系感知自注意力机制,利用完整的关系图网络来处理N L Q 和模式项间各种预设的关系.BRIDGE[13]为了识别问题中提及的数据库值,对问题和数据库值进行模糊匹配,匹配字段作为锚文本(anchor text)附加到相应模式后输入模型.LGESQL 通过线图(line graph)考虑节点间的局部和非局部特征,通过图修剪的辅助任务识别与问题相关的模式项,提高编码器的判别能力[14].
Text-to-SQL 相关工作中对句法特征的使用较少,然而句法依存信息反映了问题的语法结构,有助于模型理解问题.SADGA 基于上下文结构和句法依存树构建问题图,基于数据库特定关系构建模式图,利用图神经网络分别对问题图和模式图进行编码,设计结构感知的聚合方法来学习问题图和模式图之间的映射关系[15].该方法直接使用原始句法依存信息,依存关系数目庞大,容易导致过拟合.S2SQL[16]在关系图注意网络中增加依存句法信息,RASAT[17]在继承T5 模型的预训练参数的基础上增加关系感知的自注意力,用于捕获模式结构、模式链接、问题依存结构、问题共指和数据库内容提及这5 种关系.S2SQL 和RASAT 均未对不同的句法依赖关系进行区分,仅保留依赖关系的方向.本文根据Text-to-SQL 任务的特点,对原始句法依存树进行修改,合并了部分依存关系标签,对并列结构的部分关系进行传播,帮助模型更好地理解问题,改进模式链接的结果.
最近一些工作使用Text-to-Text 的预训练模型T5[18],取得了不错的效果,与基于图的方法不同,基于T5 的方法对编码器和解码器都采用基于Transformer 的架构,不需要预定义的图、模式链接关系和基于语法的解码器.Shaw 等[19]的研究表明,对T5 进行微调不仅可以学习Text-to-SQL任务,还可以推广到未见过的数据库,且T5-3B 的结果可以与当时最先进的模型Ryansql[7]的结果相当.Scholak 等[20]提出的PICARD 模型通过增量解析约束语言模型的自回归解码器,在每个解码步骤中拒绝错误的词例(token),帮助模型找到有效的输出序列,可以显著提高大型预训练语言模型的性能.PICARD 的T5-Base 模型可以超越没有PICARD 的T5-Large模型.Gao 等[21]提出由任务分解、知识获取和知识组合构成的3 阶段框架,提升了模型获取通用SQL 知识的能力,使其更具有泛化能力和鲁棒性.RASAT[17]通过在多头自注意力中加入边的嵌入,为T5 提供结构信息.Xie 等[22]将其他结构化知识数据任务(structured knowledge grounding,SKG)的知识注入到T5 的多任务训练中,提高Text-to-SQL 的性能.GRAPHIX-T5[23]在T5 的基础上增加图形感知层,以增强多跳推理能力,在保持T5 强大的上下文编码能力的基础上,提高T5 的结构编码能力.这些工作都表明,T5 中蕴含着丰富的语言知识,使用合适的微调方式,可以使T5 在Text-to-SQL 任务上获得优异的表现.
2 模型简介
Text-to-SQL 的任务定义如下:给定自然语言问题Q 和数据库模式S,生成相应的SQL 查询语句.问题Q 可以表示为 Q={q1,···,q|Q|},其中 qi表示问题中的第i 个单词,|Q|为问题的长度.模式S 由一系列表 T={t1,···,t|T|}和列组成,其中 ti为数据库中的第i 个表,为该表中的第j 个列,|T| 为数据库中表的数目,为第i 个表中列的数目.
如图1 所示,提出的框架由2 个阶段组成:模式链接阶段和SQL 生成阶段.在模式链接阶段,模式链接器识别问题中提及的列、表和值.在第2 阶段,将这些对齐信息注入到生成器中,优化生成的SQL 结果.
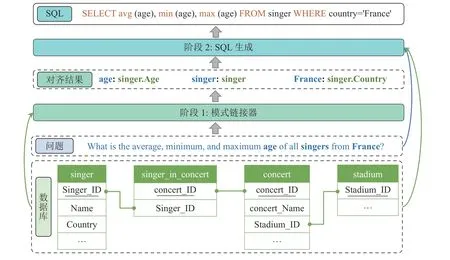
图1 基于依存关系图注意力网络的两阶段SQL 生成框架Fig.1 Two-stage SQL generation framework based on dependency graph attention network
2.1 模式链接器
模式链接器的结构如图2 所示,对问题和模式串联,经预训练模型混合编码,得到问题和模式的初始表示通过预训练模型中的多层注意力机制,已经隐式捕获了部分模式链接的信息.根据模式的结构及句子的语法信息,通过图神经网络为模式链接提供更明确的监督信号.分别对问题和模式项构造图.问题图基于句法依存树,对依存关系进行合并和传播;模式图是基于数据库模式项之间的从属关系和主外键关系.问题图和模式图经RGAT 编码,得到问题和模式的表示计算它们的链接概率.
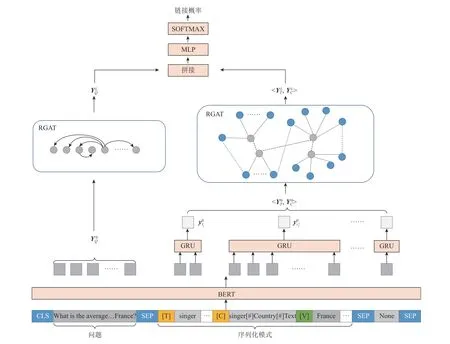
图2 模式链接器的结构Fig.2 Structure of schema linker
2.1.1 问题和模式项的联合编码 将问题Q 和序列化的数据库模式S 进行串联,得到输入序列X:
其中[None]作为特殊模式项,当问题中的单词不与任何模式项关联时,将与[None]关联.S 中的特殊字符[T]和[C]用于分割表名和列名.此外,在列名前添加了其所属的表名,在列名后添加了其类型信息(如text、number、boolean 等),并用特殊字符[#]分割.为了明确问题中提及的数据库值,将问题词与数据库中的值进行模糊匹配,将匹配结果添加到X 中.假设问题词 qi与数据库列 ckj中的值匹配,将 qi添加到相应列名后,用特殊字符[V]进行分割,即若问题词 qi与多个列的值都匹配,则将 qi添加到所有匹配列之后,一起输入模型.
混合序列X 经基于Transformer 的双向编码器(bidirectional encoder representation from transformers,BERT)[24]编码,得到问题词和每个模式项单词的嵌入表示.由于列名和表名都可能由多个单词组成,需要再经过一个门控循环单元(gate recurrent unit,GRU),得到每个列和表的初始表示.
2.1.2 依存关系的合并与传播 原始的句法分析产生的依存关系类型多达74 种,直接使用原始句法关系构造图,可能会引入大量的噪声.对原始的句法依存树进行简化和修改.对于数据库模式识别没有帮助的关系,如root(根节点)、punct(标点)、expl(填补词)、det(限定语)等关系,将它们简化为支配关系,依存弧赋予标签“forward”,保留了如nmod(名词修饰)、dobj(直接宾语)、amod(形容词修饰)等关系标签,具体见表1.

表1 保留的依存关系集合Tab.1 Collection of reserved dependencies
在原始的句法依存树中,由“and”、“or”或逗号等连接的单词之间的并列结构,通过依存弧conj(连词)连接.该结构中,第一个词作为整个并列结构的核心词,不仅支配其余并列词,还连接了与句子中其他词的支配和被支配关系.从语义上看,并列词共享与句中其他成分的依存关系,但距离第一个词越远的并列词,依赖路径越长,依赖关系越难以捕捉.如图3 所示,“year”作为并列结构中的第一个词,“name”和“budget”通过conj 关系依附于“year”,同时“year”作为“List”的从属词和“department”的支配词.语义上“name”和“budget”是“List”的宾语,“department”修饰了“name”和“budget”,这些支配和被支配关系在原始依存树上表现为多跳关系,增加了模型理解的困难.添加并列结构中的从属词与句中其他成分间的依存关系,如图3 所示为修改示例.
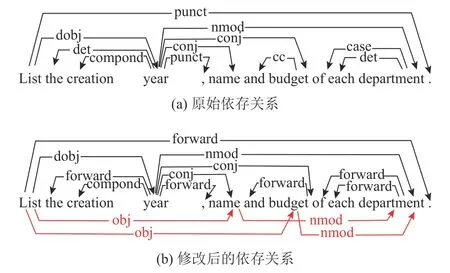
图3 依存关系修改示例Fig.3 Example of dependency modification
2.1.3 问题RGAT 模块 除上述修改,还添加了单词与自身的自连接关系.将句子结点构成的图使用RGAT[14]模型计算其表示,其中L 为网络层数,公式如下:
2.1.4 模式RGAT 模块 对于数据库模式而言,其表和列作为结点,列表间的从属关系、主外键关系作为边,构成模式关系图,同样结点的表示可以通过RGAT 计算.各模式项之间的关系定义如表2 所示.
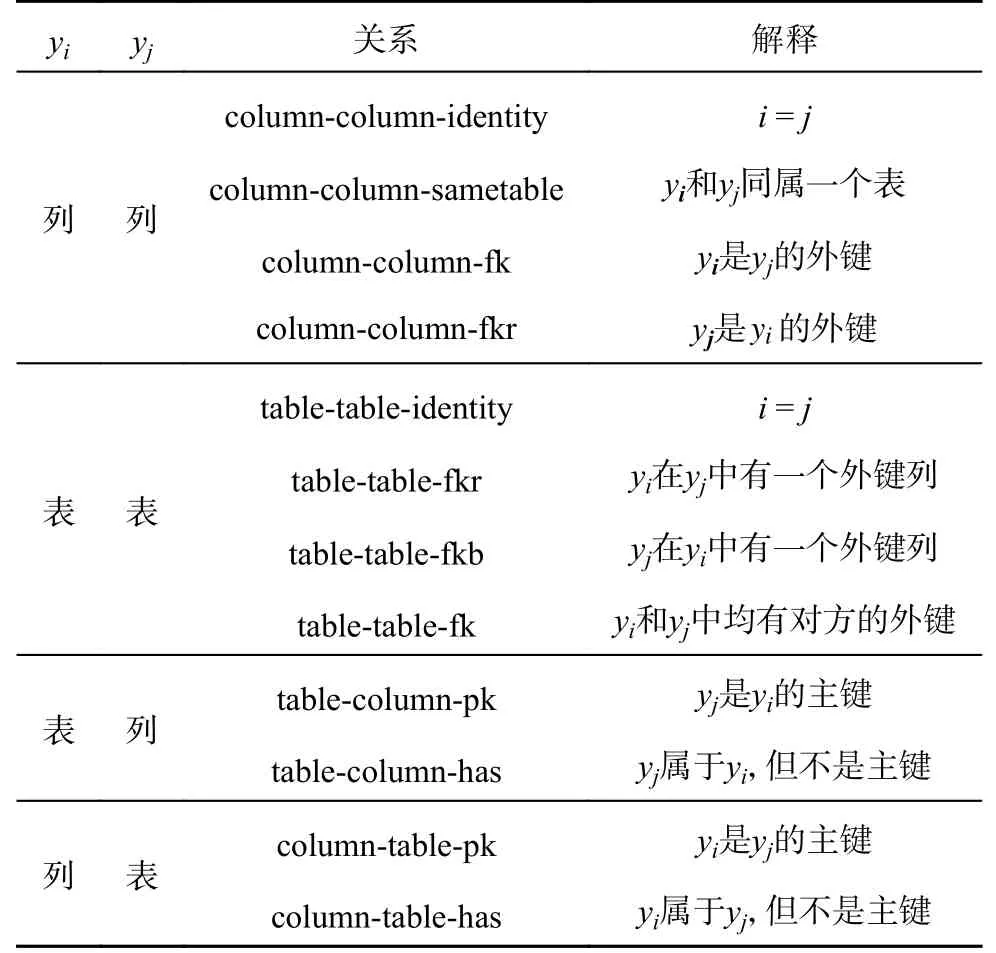
表2 模式项之间的关系Tab.2 Relation types of schema items
2.1.5 模式链接的概率计算 计算问题词 qi和模式项 sj的链接概率 Pi,j.将 qi的表示和sj的表示进行拼接,经多层感知机和softmax 操作计算链接概率,公式为
模式链接器的损失函数为交叉熵损失,即
2.2 对齐增强生成器
由于T5 在Text-to-SQL 任务上展现了强大的性能表现,通过注入模式链接信息,对T5 进行微调,实现第2 阶段的SQL 生成任务.将问题Q、模式链接结果和序列化的数据库模式S 输入模型,输入序列表示为
其中spani表示问题Q 中连续的若干个单词.“spani=tk”表示spani提及的是表tk,表示spanj提及的是列或该列的值.参照Shaw 等[19]的工作,数据库模式S 序列化为如下形式:
T5 模型基于编码器-解码器框架,双向编码器学习输入向量x 的隐藏状态h,解码器根据h 生成SQL,公式如下:
式中:θ 和 τ 分别为编码器和解码器的参数.模型采用预训练的T5 参数进行初始化,按如下目标进行优化:
3 实验分析
3.1 数据集
Text-to-SQL 目前的主流数据集是Spider 数据集[25],该数据集包含10 181 条自然语言问题和5 693 条SQL 查询以及138 个不同领域的200 个数据库;其SQL 语句覆盖了多表连接、分组、排序、嵌套查询等复杂操作,目前SOTA 模型的准确度约为70%.Spider 分为训练集、验证集和测试集,样本个数分别为7 000、1 034 和2 134.由于测试集未公开,使用验证集进行消融实验.基于Spider 数据集,SLSQL 构建了模式链接语料库,对Spider 训练集和验证集的每个实例注释了模式链接信息[6].使用SLSQL 提供的标注数据训练模式链接器.
为了验证模型的鲁棒性,在Spider-DK[26]和Spider-Syn[27]数据集上进行实验.Spider-DK 在Spider 样本的基础上加入领域知识,用于评估模型融合知识的能力.Spider-Syn 对Spider 数据集中的问题进行同义词替换,特别是与数据库模式和值相关的问题词,评估模型对词汇变化的鲁棒性.
3.2 评价指标
采用准确率P(precision)、召回率R(recall)和F1 评估模式链接器的性能.Text-to-SQL 任务的评价指标主要包括精确匹配率(exact set match accuracy,EM)和执行准确率(execution accuracy,EX),本文采用这2 个评价指标.EM 将SQL 语句拆分成SELECT、WHERE、GROUP BY 等多个组件,依次比较各组件集合,避免SQL 子句中顺序问题的影响.EX 对预测SQL 和标准SQL 的执行结果进行比较.
3.3 实验环境及参数
实验的显卡型号为NVIDIA GeForce RTX 3090,显存为24 GB,CUDA 版本11.7.模型基于PyTorch 实现,Python 版本为3.8.13,PyTorch 版本为1.10.1+cu113.
模式链接器的参数如下:BERT 版本为BERTBase,层数为12,hidden_size 为768,注意力头为12,dropout 为0.1.RGAT 的层数为8,hidden_size为768,注意力头为8,dropout 为0.2.batch_size 为12,learn_rate 为5×10-5,迭代轮次为30.依存句法分析采用斯坦福大学开发的StandfordCoreNLP.
生成器的参数如下:实验使用的T5 版本为T5-Base 和T5-Large,采用Adafactor[28]进行参数优化.T5-Base 的batch_size 为8,learn_rate 为10-4;T5-Large 的batch_size 为4,learn_rate 为5×10-5.
3.4 实验结果与分析
3.4.1 模式链接
1)实验结果分析.
在Spider 验证集上,利用模式链接器进行模式链接的结果如表3 所示.由于只有SLSQL 显式地研究了模式链接,将本文方法与SLSQL 进行比较.本文方法较SLSQL 有明显的提升,识别问题中提及的列、表、值的F1 分别提高了4.2%、2.4%和13.1%.部分样本的预测结果对比如表4 所示.本文方法在模型输入时,将与数据库值模糊匹配的问题词附加在相应列名之后,因此在值的识别上,较SLSQL 更准确,如表4 的问题2 所示,利用本文模型可以正确识别问题词“Aruba”对应“coun-try”表中“Name”列的值.此外,由于本文使用改进的句法依存关系,模型能够在一定程度上理解问题的语法结构,具有一定的全局推理能力.如表4的问题1 所示,本文模型根据“rank for winners”将“rank”识别为“matches”表中的“winner_rank”列,SLSQL 将其错误识别为词语最相似的“rankings.ranking”列.在问题3 中,“flights”表中的列“Source-Airport”和“DestAirport”中都包含值“APG”,本文模型能够根据问题中的“arriving”,将“APG”正确识别为列“DestAirport”的值.

表3 模式链接的结果Tab.3 Results of schema linking

表4 部分样本模型预测结果的对比Tab.4 Comparison of model prediction results for some samples
2)消融实验.
为了研究模型中各个组件对性能的影响,开展消融实验,结果如表5 所示.为了便于讨论,3.1 节的模型在本节中被称为默认模型.其中“-依存增强”表示使用原始句法依存树,不对依存关系进行合并和传播,“-问题RGAT”表示删去问题的RGAT 模块,“-模式RGAT”表示删去模式的RGAT 模块.实验结果显示,各模块均对模型性能有一定的贡献.删去依存增强模块后,对列的识别能力有一定的下降,删除问题RGAT 后下降得更明显.句法依存关系有助于模型理解问题的语法结构,对易混淆的相似列名识别有一定的帮助,表6 给出结果示例.例1 中“names”和“winners”的nmod(名词修饰)关系由“names”指向“winners”,经并列结构的依存关系传播,问题词“rank”通过nmod 关系支配“winners”,使得模型正确识别“rank”对应表“match”中的“winner rank”列,而删去问题的RGAT 模块后,模型将“rank”错误识别为“rankings”表中的“ranking”列.例2 中,表city 和表country 都包含名为Population 的列,由于问题词“population”通过nmod 关系支配“district”,且问题词“district”对应city 表中的District 列,“population”也对应表city 中的列.类似地,例3 中的“whose name”,其“name”指的是“state name”而不是“email name”.默认模型在识别时更精准,更倾向于将单词识别为列的引用,但由于标注精度的问题,导致表的识别结果略有下降.例如问题“How many car models are produced by each maker?”,模型将“carmodels”识别为表“model_list”的引用,语料库仅标注了单词“models”,又如问题“What is name of the country that speaks the largest number of languages? ”模型将language 识别为列“countrylanguage.language”,语料库标注为表“countrylanguage”.此类与标注不一致的识别情况不影响后续的SQL 生成.随机采样100 个错误实例发现,与标注不一致但不影响SQL 生成的错误占总数的13%.
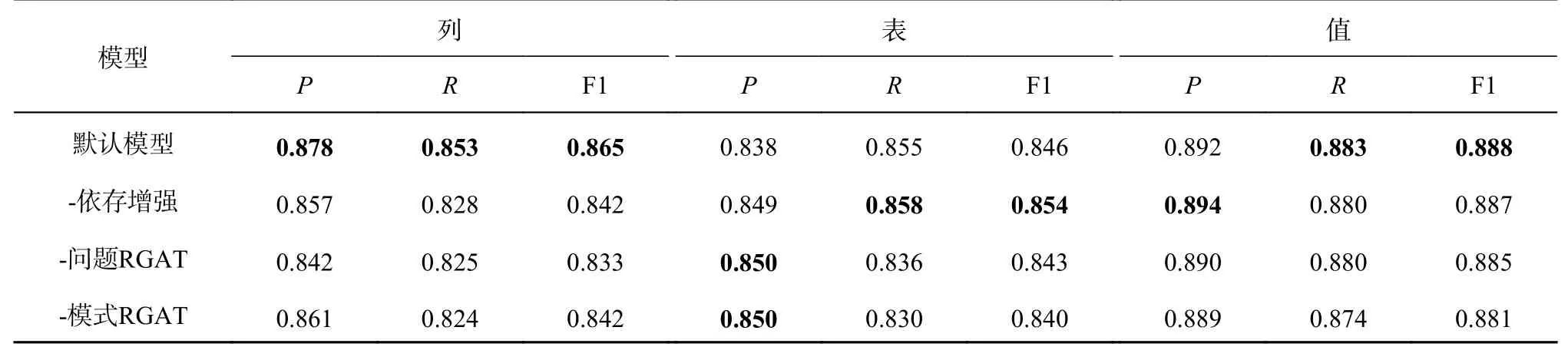
表5 模式链接的消融实验结果Tab.5 Ablation study of schema linking

表6 列预测结果的对比Tab.6 Comparison of column prediction
3)输入序列对比实验.
为了研究模式链接中问题词与数据库值的匹配,研究多种在输入序列中添加匹配信息的方式.假设问题词 qi与数据库列中的值 dm匹配,对以下3 种方式进行实验.1)列+值:将匹配到的数据库值添加到相应列名后,即[V]dm.2)问题词+值:将匹配到的数据库值添加到相应问题词之后,即 qi[V]dm.3)问题词+列:将匹配的列序号添加到相应问题词后,即 qi[V]n,其中n 为在所有列C 中的序号.对于方式1)和2),匹配到的数据库值可能有很多,在保证输入序列不超过512 的情况下,按匹配度由大到小添加匹配词.因为BERT 限制输入长度不能超过512,而列名较长,仅在问题词后添加列的编号.实验结果见表7.考虑到在问题词后添加值或列的序号破坏了原始问题的上下文,性能有所下降.相比于在列后添加匹配的数据库值,添加问题词的效果更好.问题中对于值的描述不一定与数据库中存储的值完全相同,例如问题“What is the average,minimum,and maximum age for all French singers?”,“French”对应“country”列的值“France”,添加问题词更加直观.
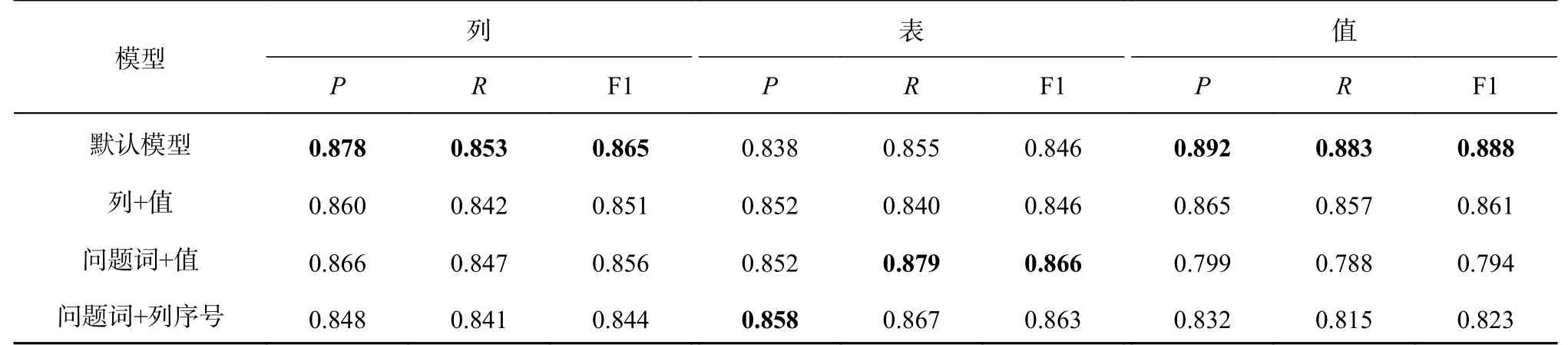
表7 输入序列的对比Tab.7 Comparison of input sequence
3.4.2 SQL 生成 本文方法与其他模型在Spider验证集上的SQL 生成结果对比如表8 所示.表中,“GT”表示不使用模式链接器预测的模式链接结果,而是使用标注的模式链接结果,即Ground Truth.根据实验结果可见,本文方法在不同规模的T5 模型上展现了较好的性能.在加入第一阶段预测的模式链接结果后,本文方法较文献[19]在原始T5 上的结果有了较大提升,EM 值在T5-Base 上提升了11.4%,在T5-Large 上的结果与T5-3B 上的结果相当.EM 反映预测查询是否和标准查询在所有组件上完全一致,然而同一查询可以有多种实现方法,例如“SELECT a FROM t ORDER BY b DESC LIMIT 1”与“SELECT a FROM t WHERE b=(SELECT MAX(b)FROM t)”是完全等价的,因此EM 存在将正例判负的情况,造成了EM 和EX 之间差距较大.本文在T5-Large 上的EX 值超过了同规模的所有基线模型,甚至比Unifiedskg[22]在T5-3B 上的结果高1%.实验证明,使用准确的模式链接信息可以显著提升模型的性能,在使用标注的模式链接结果后,本文方法在T5-Large 上的结果甚至超过了RASAT[17]在T5-3B 上的结果.

表8 SQL 生成实验结果的对比Tab.8 Comparison of SQL generation results
为了显示模型在不同难度的查询上的生成能力,按照Spider 数据集的样本划分规则,将查询分为4 个级别:容易 (easy)、中等 (medium)、难(hard)、很难 (extra hard),实验结果如表9 所示.由实验结果可见,准确的模式链接可以提升难度较大的SQL 生成问题的结果.由于预测的模式链接结果不够准确,模型尚有较大的提升空间,需要进一步的研究.
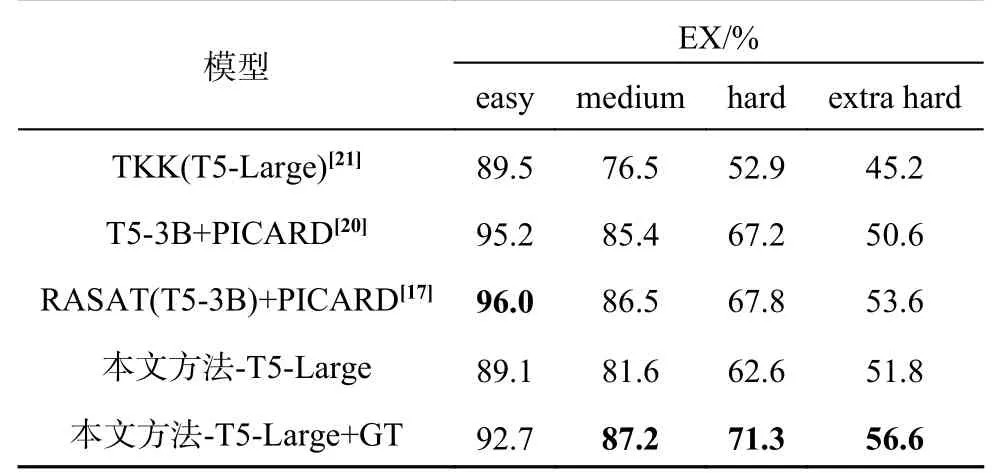
表9 不同难度上的EX 结果对比Tab.9 Comparison of EX accuracy on different difficulty levels
为了验证模型的鲁棒性,在 Spider-DK 和Spider-Syn 数据集上进行实验,模式链接器未重新训练,即仍然使用基于SLSQL[6]标注的Spider 数据集训练的结果,实验结果见表10.这2 个数据集更贴合实际的应用场景,Spider-DK 结合了一些领域知识,Spider-Syn 模拟了用户不熟悉数据库的模式,在问题中没有准确提及模式词的情况.实验结果显示,本文方法具有鲁棒性,在2 个数据集上的表现均超过基线模型.
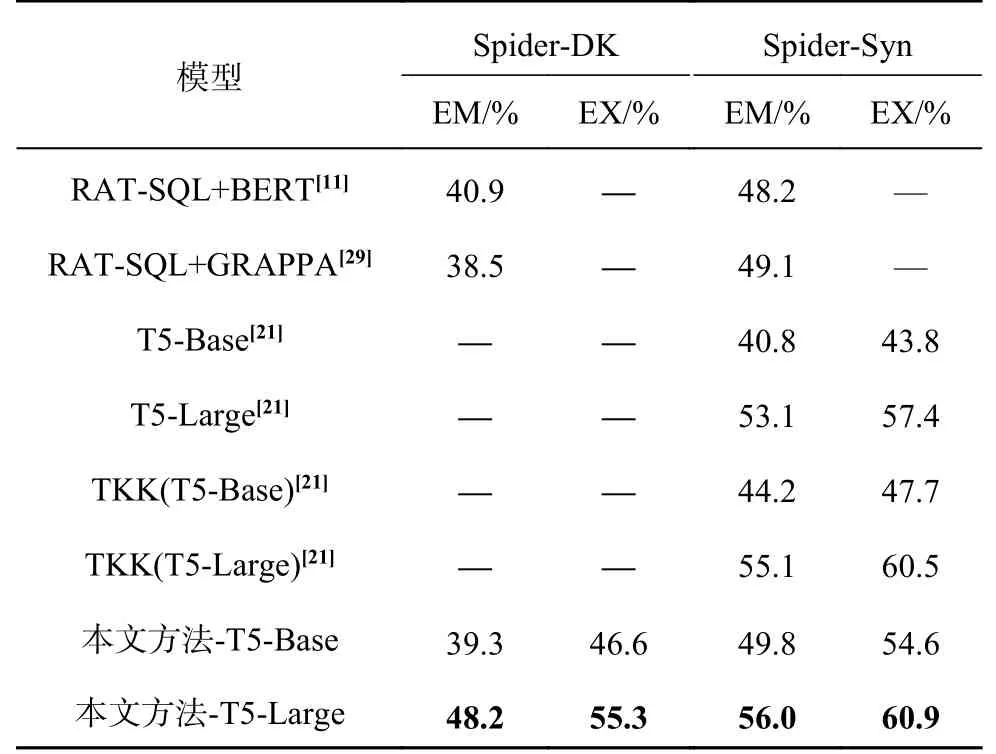
表10 Spider-DK 和Spider-Syn 上的SQL 生成结果Tab.10 SQL generation results on Spider-DK and Spider-Syn
4 结 语
本文提出两阶段的模型以解决Text-to-SQL问题,通过模式链接器识别问题中提及的数据库表、列和值,将对齐信息融合到基于T5 的生成器中,指导SQL 生成.模式链接器基于关系图注意力网络,根据问题句法依存树和模式项之间的内部关系构造图.在构造问题图时,对依存关系进行合并和传播,有助于模型捕获长距离的依赖关系.模型将模式链接和SQL 生成解耦,以降低Text-to-SQL 问题的复杂性,在Spider 及其变体上的实验证明了该模型的性能.下一步将对模式链接模块继续进行优化,提高SQL 生成的准确率.
