营商环境评估的企业级复合区块链构建方法
2024-05-25李素陈泽宋宝燕张浩林
李素,陈泽,宋宝燕,张浩林
(辽宁大学 信息学院,辽宁 沈阳 110036)
营商环境包括市场主体在准入、生产经营和退出等过程中涉及的政务环境、市场环境和法治环境等有关外部因素和条件的总和[1-3].良好的营商环境对于现代化经济高质量发展具有重要意义[4].由于营商环境包含的信息源种类复杂,政务、市场、法治及企业经营等数据存在信息孤立、跨域访问效率低、中心化存储易被篡改、可信度差等问题[5-8].营商环境评估也对企业级复合区块链构建带来数据保护、技术标准和互操作性、风险管理与安全、资源与成本等挑战.如何高效存储企业营商环境信息,提高信息的可信度和安全性,有效支持营商环境的评估,是领域研究的热点和难点[9].
针对上述问题,本文引入区块链技术实现多源异构的企业营商环境数据高效存储[10-12],在满足政务、市场、法治及企业经营等数据去中心化可靠存储需求的同时,提高数据的安全性和可信性[13-15].本文的主要贡献如下.
(1)为了防止营商环境评估时企业原始数据被篡改,引入改进的哈希函数SHA256 算法对企业原始数据进行加密.通过在数据块哈希运算中增加运算次数,增大SHA256 算法逻辑和压缩函数复杂度,进一步提高运算的抗碰撞性及Hash 结果的雪崩效应,从而提高数据安全性.
(2)为了降低区块链系统的通信和存储压力,提出链上和链下相结合的存储模式.引入改进的基于非易失性内存(non-volatile memory,NVM)的Key-Value 型数据库Level DB,实现在链下存储企业原始数据.Key 值为经过改进后的SHA256 算法加密的Hash 值,Value 值为企业原始数据.
(3)针对传统区块链存在交易确认速度慢、吞吐量小的问题,提出企业级复合区块链的构建方法.公有链采用基于有向无环图(directed acyclic graph,DAG)的Conflux 存储链下Level DB 中企业原始数据对应的Key 值,联盟链存储企业状态数据,确保企业原始数据去中心化存储,不可篡改和可追溯.
1 相关工作
目前,国内外许多专家学者对区块链链上链下的存储优化方法进行研究,取得了一定的研究成果.
在Level DB 优化方面,Lu 等[16]针对Level DB写放大提出WiscKey 方法,该方法将键从值中分离出来,同时只在Compaction 时合并键,利用该方法可以大大降低写放大,但它使得垃圾回收和范围查询复杂化.Lepers 等[17]提出的Kvell 模型采取每一项键值在磁盘上乱序的方式,可以减轻基于NVMe SSD 键值存储的写停顿,但不适用于通用的SSD 系统.Kaiyrakhmet 等[18]提出SLM-DB 存储结构,该结构采用单级的 LSM-tree,适用于具有NVM-SSD 存储的系统,通过NVM 上的B+树来索引SSD 上面的单层LSM-tree,以实现快速读,但该方式引入了维护B+树和LSM-tree 一致性的额外开销.Kannan 等[19]提出的NoveLSM 在NVM上采用持久化可变内存表,可以在某种程度上减少访问时延,但造成了更严重的写入停顿.
在结构链优化方面,Lewenberg 等[20]提出构建Inclusive 区块链,Inclusive 将Nakamoto 共识和GHOST 规则扩展到DAG,设计了框架,以包括链外交易.Leonov 等[21]提出PHANTOM 平台,参与节点为本地区块DAG 找到近似的k-cluster 解决方案,以修剪潜在的恶意区块.对剩余区块进行拓扑排序,获得最终的区块总顺序.当区块生成率很高时,Inclusive 和PHANTOM 都很容易受到有效性攻击.Eyal 等[22]提出构建Bitcoin-NG区块链,Bitcoin-NG 通过定期选举一个Leader,并允许该Leader 在一段时间内指定交易全序的方式提高吞吐量,但没有减少交易的确认时间.Derek等[23]提出Vault 区块链,Vault 选择分片技术对区块链进行构建,以便降低存储成本,权衡网络带宽成本的增加.虽然所有分片的综合吞吐量很大,但分片间交易的吞吐量有限.
综上所述,现有方法存在读写性能差、存储效率低、交易确认速度慢和吞吐量小等问题.本文综合考虑Level DB 优化和区块链存储效率问题,提出营商环境评估的企业级复合区块链构建方法.
2 企业原始数据链下存储
企业级复合区块链总体架构由Level DB、公有链和联盟链组成,以实现链上链下数据协同.链上通过链下实现计算和存储能力的扩展,链下与链上对接实现异构信息的共享.如图1 所示,在企业级复合区块链架构中,Level DB 数据库存储企业原始数据信息,Value 为原始数据,Key 为通过改进的哈希函数SHA256 算法加密后的Hash值.负责交易的公有链存储Level DB 数据库中企业原始数据对应的Key 值,负责状态的联盟链存储企业的状态数据.

图1 企业级复合区块链的架构图Fig.1 Architecture diagram of enterprise composite blockchain
2.1 企业原始数据的加密计算
为了进一步提高数据的安全性,在将原始数据存入链下Level DB 前,采用改进的哈希函数SHA256 算法对企业原始数据进行加密.SHA256 算法采用6 个逻辑函数和1 组常数 Kt,输入为512 bit 的消息块 xi,将 xi分为16 组32 bit 的字 M0,M1,···,M15,输出为256 bit 的报文摘要[24].SHA256 算法的过程如下.
1)初始化.
2)准备消息列表 Wt:
逻辑函数的计算方式为
式中:ROTR(x)为循环右移函数,POTR(x)为循环左移函数.
4)当 0 ≤t ≤63时,执行压缩函数Ch:
逻辑函数的计算方式为
5)计算每个分组的中间散列值:
式中:i为消息的第 i个分组,所有分组处理完毕后,输出256 bit 的Hash 值.在对SHA256 算法进行改进时,在每个512 bit 的数据块哈希运算中增加16 次运算,保证消息的每个bit 可以影响到更多的bit 位,进一步改善算法的非线性扩散性.加大SHA256 算法逻辑和压缩函数的复杂度,以加速消息的差分扩散程度,使得递推过程具有更强的随机性,消除局部碰撞的依从条件.改进后SHA256 算法过程如下.
1)对消息块 M(i),i=1,2,···,N,进行如下循环.
a)准备消息列表 Wt:
b)工作变量初始化:
2)当 0 ≤t ≤79时,执行如下压缩函数:
式中:T1、T2为中间变量.压缩函数采用80 个32 bit 的字 Kt{256}(0 ≤t ≤79)常数序列,前64 个32 bit 的字见文献[25],后16 个32 bit 的字定义如下:
改进后的SHA256 算法使用的6 个逻辑函数基于32 bit 的字(如 x、y、z)进行操作,每个逻辑函数的操作结果是新的32 bit 的字,具体定义如下:
式中:SHR(x)为逻辑右移函数,每一组的循环操作如图2 所示.

图2 改进后的SHA256 算法操作Fig.2 Improved SHA256 algorithm operation
采用改进后的哈希函数SHA256 算法,对企业原始数据加密生成相应的Hash 值,作为链下Level DB 数据库中的Key 值,开展后续的存储操作.
2.2 基于NVM 的链下Level DB 存储模型构建
将企业原始数据加密后的Hash值作为Key 值,原始数据作为Value 值,对应存入链下Level DB 中.Level DB 是基于LSM-tree(log-structured merge tree)架构的Key-Value 非关系型数据库存储系统,它写入快,占用空间少,但LSMtree 架构有写停顿、写放大和不利于读的缺点.在LSM-tree 架构的基础上,提出基于NVM 的LSMtree 存储模型.利用该模型,可以提高访问速度、持久性、并发性和扩展性,同时具有更好的集成性.链下Level DB 存储模型架构如图3 所示.
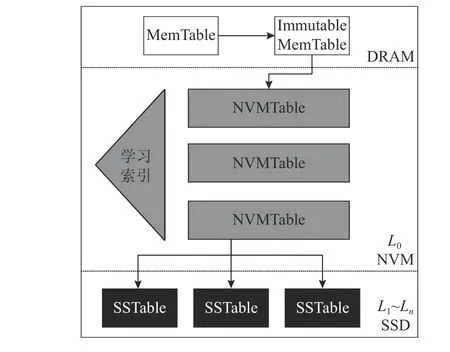
图3 链下LevelDB 存储模型架构Fig.3 Off-chain LevelDB storage model architecture
如图3 所示,将原有LSM-tree 架构中的 L0层放在NVM 上,L1~Ln层存储在固态硬盘(solid state disk,SSD)上,解决数据合并时的写时延问题.对L0层的文件引入学习索引,使得 L0层文件之间有序,在降低读时延的同时提高 L0层文件中数据的查找速度.在NVM 层上使用学习索引,利用学得的模型对数据的位置进行预测,以便加快数据在NVM 上的查找速度.通过学习索引,可以找到 L0层中某一个key 的位置.每个NVMTable 需要单独学习一个索引模型.建立key 到数据位置的近似映射.从近似映射的位置开始,和目标 key 进行大小比较,通过向前或向后线性搜索,确定正确的位置.如图4 所示,选择分段集合模型索引(piecewise geometric model index,PGM-index)进行位置定位.
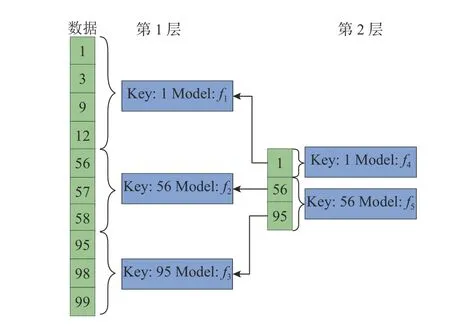
图4 PGM 索引示例图Fig.4 Example diagram of PGM index
在PGM 索引第1 层,将数据分成3 个分区,每个分区由简单的线性模型 (f1,f2,f3)表示.通过构建这些线性模型,每个线性模型能够利用预先设定的误差,在各自的分区内进行相应的key 值预测.将第1 层的划分边界当作其自身的排序数据集,计算另一个误差有界的分段线性回归.如此反复,直至顶层的 PGM 变得足够小,以加快数据查找速度.
3 链上企业级复合区块链的构建
3.1 Conflux 公有链构建
为了提高区块链的性能,从有向无环图(DAG)的特殊结构出发,采用基于主干链的DAG 共识协议Conflux 共识,构建企业级复合区块链中的Conflux 公有链.Conflux 公有链的架构如图5 所示.
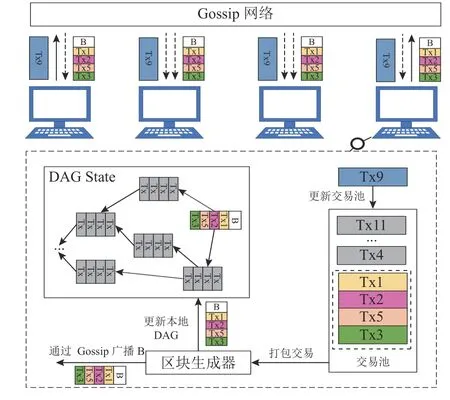
图5 Conflux 公有链架构图Fig.5 Architecture diagram of Conflux public blockchain
Conflux 中的交易由2.2 节链下Level DB 中企业原始数据对应的Key 值组成.Conflux 从预定义的创世区块开始,确定区块链的初始状态,所有区块和边构成一个DAG 结构.Conflux 中的所有参与节点通过Gossip 网络连接,每当一个节点发起一项交易或生成一个新区块,它将通过 Gossip 网络将交易广播给所有其他节点.Conflux 底层区块的数据结构如图6 所示,采用树图的形式,通过并行处理方式加大出块速度,且不会因为链分叉问题降低安全性,使得每个企业都可以并行地上传交易,即企业原始数据对应的Hash 值,使得整个系统可以更高效地处理区块和交易.
在Conflux 公有链中,提出基于主干链的DAG 共识协议进行共识操作.该共识可以处理并发区块,不会丢弃任何并发区块作为分叉.除创世区块外,每个区块都有一条出度的父边(见图6的实线箭头),表示区块之间的投票关系.每个区块可以有多条出度的引用边(见图6 的虚线箭头),表示区块的生成顺序.DAG 中的所有父边一起形成一棵父树,其中创世区块是根.在父树中,Conflux 选择一条从创世区块到其中一个叶区块的链作为主链.Conflux 采用Ghost 协议选取主链,从创世区块开始,计算每个节点的子树大小,拥有最大子树的节点成为主链上的一个节点.
每当一个节点生成一个新的区块时,它首先计算其本地DAG 状态下的主链,并将主链中的最后一个区块设置为新区块的父块.在DAG 中查找没有入度边的所有端区块,创建从新区块到每个端区块的引用边.给定一个从创世区块开始、只包含父边的主链,排序算法利用主链将DAG 中的所有区块划分为epoch,主链上的每个区块都对应一个epoch.当进行共识确定区块总序时,Conflux对epoch 进行排序,根据epoch 的拓扑顺序对每个epoch 中的区块进行排序.当确定交易顺序时,交易的顺序由包含这笔交易的区块总序确定先后顺序.
按照上述过程,对企业上传的原始数据对应的Key 值进行数据上链操作.
3.2 Fabric 联盟链的构建
由于企业众多,为了进一步降低网络资源消耗,选取一定比例通过验证的企业节点构建联盟链,通过这些预选节点实现共识算法、公开验证、安全存储.采用联盟链Hyperledger Fabric 部署联盟链.联盟链主要负责企业状态数据存储,存储过程中所使用的符号及其含义如表1 所示.在满足合约执行触发条件后,智能合约会自动地访问、共享和存储数据,根据预先定义的约束执行数据存储操作.

表1 联盟链状态数据存储过程使用的符号及其含义Tab.1 Symbols used by consortium chain state data storage procedure and their meanings
企业状态数据存储的主要流程如下.
1)系统初始化.每个企业节点须通过监管机构节点身份认证,认证通过后成为合法的联盟链网络节点.获取分别表示用于加密数据的公私密钥对及其证书.执行系统初始化,企业节点从邻近企业总部节点的记录池中下载当前联盟链的区块数据存储位置索引表.2)状态数据上传.企业节点 Ni向本地的企业总部节点 BSj发送上传请求,请求包括 Ni当前使用的和数字签名 Sig_1,以确保数据来源的可靠性和真实性.BSj接收并验证Ni的请求和身份信息,以确认其合法性并作出回应.Ni使用当前公私密钥对中的公钥对状态数据 Data进行加密,并将该状态数据连同它的数字签名一起发送给 BSj,通过它的公钥 PKBSj对 Ni发送过来的记录数据进行加密,得到最终的上传数据 Record.上述过程的形式化语言描述如下:
3)收集上传数据.本地企业总部节点 BSj对上传的 Record进行验证.若数据安全有效,则将Record存入本地记录池;反之则忽略.
4)本地企业总部节点工作量证明.
每经过一个周期,BSj将 T内收集到的所有有效数据合并为一个数据集合 Data_set(Data_set={Records||Timestamp}),并对其进行数据签名,以确保 Data_set来源的合法性和可验证性.先找到有效工作量证明的 BSj,可以获得记录本次数据区块的权利,并获得相应奖励.获得记账权的 BSj须将当前的 Data_set和计算出来的 x广播给其他企业总部节点,用于验证和检验.若其他企业总部节点验证通过,则该 BSj将 Data_set合并为新的数据区块,并存储在联盟链中,得到相应的系统奖励.
5)企业总部节点间的区块共识.
在最短时间内计算出有效工作量证明的企业总部节点 BSj成为当前共识过程中的主节点(Leader),其他企业总部节点作为从节点(Slave),联盟链采用拜占庭容错(practical byzantine fault tolerance,PBFT)共识机制进行共识,共识过程如下.
a)Leader收集各 Slave 的 Data_set,并将其整合到一个新的数据区块中,同时附加上 Leader的数字签名和新数据区块的 Hash以备检验.Leader向各个 Slave广播新生成的数据区块,以等待其他节点的验证.上述过程的形式化语言描述如下:
b)Slave收到数据区块后,对 L eader发送过来的区块 Hash和数字签名信息进行验证,确认区块Hash和数字签名的正确性和合法性,并将验证结果 Result与自己的数字签名广播给其他 Slave,实现 Slave间互连、互查.
c)某个 SlaveBSl接收并汇总其他 Slave的验证结果,与自己的验证结果比较,验证后向 Leader发送一个回复 Reply.该 Reply包括 Slave自身的验证结果(my_result)、收到的所有验证结果(R ece_results)、验证对比的最终结论(Comparison)和对应的数字签名.上述过程的形式化语言描述如下:
其中,Data_3=my_result||Rece_results||Comparison,SigBSl=SignSKBSl(Data_3).
d)Leader收集汇总所有 Slave的验证回复.若所有 Slave都验证通过当前区块的正确性和合法性,则 Leader整合该数据区块、参与验证的 Slave的证书集合({CertBS})以及对应的数字签名并发送给所有的 Slave.此后,该数据区块将以时间顺序存储在联盟链中,Leader从中获得系统的奖励.上述过程的形式化语言描述如下:
e)若部分企业总部节点未验证通过,则Leader将分析和查验这些企业总部节点的验证结果.Leader重新发送该数据区块给这部分企业总部节点进行二次验证.若仍有节点不通过,则将按照少数服从多数的原则,超过一定比例的企业总部节点验证通过该数据区块,将该数据区块按d)的方式加载到联盟链中.
通过上述共识过程,企业状态数据将存入联盟链Fabric 中,以便为后续对企业营商环境进行评估时提供关联数据溯源和分析支持.
4 实验与分析
实验数据集来自区块链与智能金融研究中心InplusLab 实验室开发的区块链数据智能平台XBlock 中的数据集,所有数据集都进行了标准化的清洗和归类,并统一为标准的一致格式.数据集的具体内容如表2 所示.

表2 实验数据集介绍Tab.2 Introduction to experimental datasets
实验从链下Level DB 读写性能、企业级复合区块链存储效率2 个方面,对比分析营商环境评估的企业级复合区块链构建方法的有效性.
4.1 链下Level DB 数据读写性能对比
当进行Level DB 读写性能测试对比时,设置L0层文件数量上限为10,对比测试在4、8、16 kB 3 种不同大小Value下的读写时延.在每种Value 下,分别生成10 万条均匀分布的测试数据,再生成测试数据范围内均匀分布的10 万条查询.在修改 L0层前,读操作时延包括读内存和读磁盘.写操作时延包括3 种:1)在数据写入内存表前,将数据及它的校验值写入磁盘的时延;2)数据写入MemTable 的时延;3)2 次合并带来的尾时延.如图7、8 所示分别为修改前、后的Level DB 的读、写时延对比图.图中,RLb、WLb分别为修改前Level DB 的读、写时延,RLa、WLa分别为修改后Level DB 的读、写时延.
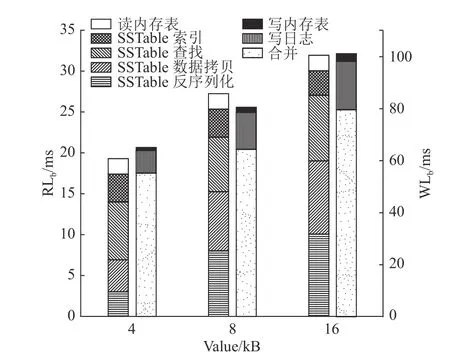
图7 修改前LevelDB 读、写时延的对比图Fig.7 Comparison of reading and writing latency of LevelDB before modification

图8 修改后LevelDB 读、写时延的对比图Fig.8 Comparison of reading and writing latency of LevelDB after modification
如图7、8 所示,与未修改 L0层相比,修改后的 L0层总体读时延都降低了约50%,由于将 L0层放在NVM 上,缩短了 L0层的查询路径,同时引入了查找学习索引,效率比传统 SSTable 的二分查找快.总体写时延都降低了约30%.由于内存表持久化的过程由DRAM 到SSD 变为DRAM 到NVM,减少的大部分时延都来自合并.
4.2 链上企业级复合区块链的存储效率对比
实验环境为20 台服务器、32 核CPU、128 GB 内存、10 TB 存储空间.区块链采用Docker 虚拟化技术部署,使用Kubernetes 管理Docker 集群.对比存储模型为公有链以太坊Ethereum 和联盟链Hyperledger Fabric.实验结果如图9 所示.图中,de为存储的企业实体数据集大小,t 为存储所需的时间.
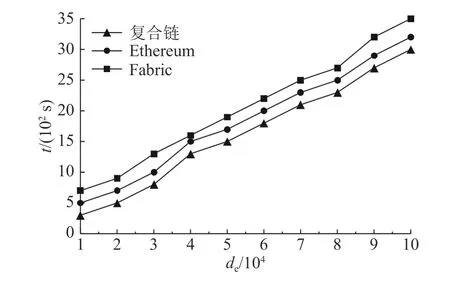
图9 企业级复合区块链的存储效率对比Fig.9 Storage efficiency comparison of enterprise composite blockchain
从图9 可知,提出的企业级复合区块链存储结构的存储效率高于Ethereum 和Fabric,复合区块链中的公有链采用基于DAG 的区块结构和Conflux 共识,加快了区块构建和共识过程,提高了存储效率.
5 结 语
营商环境的好坏直接影响企业的经营状况和当地的经济发展.针对营商环境评估时面临的企业原始数据质量不高的问题,本文提出营商环境评估的企业级复合区块链构建方法,采用链上和链下相结合的存储模式,对企业原始数据进行存储.引入改进的哈希函数SHA256 算法对企业原始数据进行加密,并将其存入链下基于非易失性内存的Level DB 数据库中,以降低系统的通信和存储压力.将数据上链存储,分别将Level DB 中的Key 值对应存储到基于DAG 的Conflux 公有链,将企业状态数据对应存入联盟链Hyperledger Fabric,为营商环境评估提供可信的存证数据.通过实验对比分析,验证了所提方法的有效性.
