一种分层强化学习的知识推理方法
2024-05-24孙崇王海荣荆博祥马赫
孙崇 王海荣 荆博祥 马赫

摘 要:针对知识推理过程中,随着推理路径长度的增加,节点的动作空间急剧增长,使得推理难度不断提升的问题,提出一种分层强化学习的知识推理方法(knowledge reasoning method of hierarchical reinforcement learning,MutiAg-HRL),降低推理过程中的动作空间大小。MutiAg-HRL调用高级智能体对知识图谱中的关系进行粗略推理,通过计算下一步关系及给定查询关系之间的相似度,确定目标实体大致位置,依据高级智能体给出的关系,指导低级智能体进行细致推理,选择下一步动作;模型还构造交互奖励机制,对两个智能体的关系和动作选择及时给予奖励,防止模型出现奖励稀疏问题。为验证该方法的有效性,在FB15K-237和NELL-995数据集上进行实验,将实验结果与TransE、MINERVA、HRL等11种主流方法进行对比分析,MutiAg-HRL方法在链接预测任务上的hits@k平均提升了1.85%,MRR平均提升了2%。
关键词:知识推理; 分层强化学习; 交互奖励; 链接预测
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)03-023-0805-06
doi:10.19734/j.issn.1001-3695.2023.07.0309
Knowledge reasoning method based on hierarchical reinforcement learning
Sun Chonga, Wang Haironga,b, Jing Boxianga, Ma Hea
(a.College of Computer Science & Engineering, b.The Key Laboratory of Images & Graphics Intelligent Processing of State Ethnic Affairs Commission, North Minzu University, Yinchuan 750021, China)
Abstract:In the process of knowledge inference, with the increase of the length of the inference path, the action space of the node increases sharply, which makes the inference difficulty continue to increase. This paper proposed a knowledge reasoning method of hierarchical reinforcement learning(MutiAg-HRL) to reduce the size of action space in the reasoning process. MutiAg-HRL invoked high-level agents to perform rough reasoning on the relationships in the knowledge graph, and determined the approximate location of the target entity by calculating the similarity between the next step relationship and the given query relationship. According to the relationship given by the high-level agent, the low-level agents were guided to conduct detailed reasoning and select the next action. The model also constructed an interactive reward mechanism to reward the relationship between the two agents and the choice of actions in time to prevent the problem of sparse reward in the model. To verify the effectiveness of the proposed method, it carried out experiments on FB15K-237 and NELL-995 datasets. The experimental results were compared with those of 11 mainstream methods such as TransE, MINERVA and HRL. The average value of the MutiAg-HRL method on the link prediction task hits@k is increased by 1.85%, MRR increases by an average of 2%.
Key words:knowledge reasoning; hierarchical reinforcement learning; interactive reward; link prediction
0 引言
近年來,知识图谱(KG)已经逐渐成为管理海量知识的有效手段[1],被广泛应用于各个领域,产生了一些大规模知识图谱,如Freebase、Wikidata等。这些知识图谱虽然已经颇具规模,涵盖了音乐、电影、书籍等领域,但仍存在大量信息缺失问题,如Freebase中71%的人没有出生地信息,Wikidata中只有2%的人类实体具有父亲信息。据统计,大部分知识图谱中,69%~99%的实体至少缺失一个属性信息[2]。知识缺失将直接影响基于知识图谱的下游任务的效果[3~5]。知识推理作为知识图谱补全的有效方法,已经成为日益重要的研究课题[6]。
知识推理通过知识图谱中已知的知识,挖掘尚未被发现的知识,对残缺的知识图谱进行补全[7]。众多学者从不同的角度出发,对知识推理进行研究,并取得了一定的研究成果。例如,基于嵌入的推理,通过将知识图谱中的实体和关系,映射到低维向量空间中得到其向量表示[8],这些向量包含了实体原有的语义信息,可作为判断实体间相似度的依据,以此进行推理。典型的有TransE[9]、TransH[10],此类方法简单且易于扩展,但对于复杂关系的建模效果不佳。因此,Trouillon等人[11]构建了ComplEx模型,在对知识图谱进行嵌入时引入了复数空间,能更好地对非对称关系进行建模;Dettmers等人[12]构建了ConvE模型,引入了一种多层卷积网络,提高了模型的特征表达能力,可以更好地建模三元组。由于基于嵌入的推理方法是将推理过程转换为单一的向量计算,没有考虑知识图谱中路径上的信息,使得该类方法在多跳推理路径上的推理能力受到限制。所以,针对多跳问题的推理方法相继被提出,如SRGCN[13]、MKGN[14]、ConvHiA[15],该类方法通过多步推理找到目标实体,同时生成从头实体到尾实体的完整推理路径,增强了知识推理的可解释性[16]。在多跳推理中,基于深度强化学习的推理方法成为当前知识推理研究的热门方向,其方法被应用于诸多知识图谱下游任务[5]。例如DAPath[17]、SparKGR[18]、MemoryPath[19]、HRRL[20]等方法,使用神经网络提取特征向量,对知识图谱中的事实进行建模,在推理的过程中,外部环境通过给予智能体一定的奖励来促使智能体做出最优动作,以取得最大化的预期效果。
最近,有学者提出了离线强化学习[21]的知识推理方法,该方法不需要智能体频繁与外部环境进行交互,相对传统的基于强化学习的方法而言开销较小,但却存在当智能体选择错误动作时无法被及时纠正的问题,最终导致推理任务失败。基于强化学习的知识推理方法可以通过智能体与环境的不断交互,给予智能体惩罚,来纠正错误的动作选择,从而保证了推理路径的可靠性,进而有效提高了知识推理的准确度。但在知识推理过程中,随着路径长度的增加,推理的难度也会随之增加。现存的多跳推理中基于强化学习的单智能体推理方法,对短路径推理较为有效,而长推理路径上的推理往往效果不佳,而且会导致奖励稀疏的问题。为此,本文提出一种分层强化学习的知识推理方法(knowledge reasoning method of hierarchical reinforcement learning,MutiAg-HRL)。首先对知识图谱进行聚类处理,帮助高级智能体进行粗略推理,选择出与查询关系高度相关的关系,在此基础上指导低级智能体进行细致推理,选择出下一步动作,通过分层策略降低了模型的动作空间,有效解决了长推理路径问题,在构建策略网络时引入dropout策略,防止模型出现过拟合问题。此外,本文方法通过交互奖励构造,及时对智能体每一步动作的选择给予及时奖励,避免奖励稀疏的问题。
1 MutiAg-HRL方法模型
MutiAg-HRL方法使用分层强化学习,将知识推理过程看作两个马尔可夫序列决策过程(Markov sequence decision process,MDP)。该方法主要包含策略网络构建和交互奖励构造两个模块,通过策略网络的构建来指导智能体进行关系和动作的选择,并使用交互奖励构造模块对每一时刻智能体的选择及时给予奖励。方法模型如图1所示。
MutiAg-HRL首先使用K-means++算法对实体嵌入进行聚类,根据与当前节点et相连接的关系类型,将知识图谱分为若干个节点簇,并通过节点之间的关系将这些节点簇连接起来,这些关系则作为高级智能体下一步关系选择的候选关系集合,在此基础上进行知识推理任务。
本方法通过分层策略,将传统基于强化学习的知识推理过程分为关系选择和动作选择两部分。首先,将与当前实体相连接的关系作为当前实体的下一步关系选择的候选关系集合,通过高级策略网络对候选关系集合进行概率分布计算,指导高级智能体选择出分数较高的下一时刻的关系;其次,通过低级策略网络对与高级智能体所选关系相连接的实体进行概率分布计算,指导低级智能体选择出下一时刻的动作实体,直至到达目标实体ep则此次推理任务结束。在构建策略网络时,采用门控循环神经网络(gated recurrent unit,GRU)对历史推理路径进行编码,将历史编码与当前節点状态作为高级策略网络输入进行粗略推理,最终得到与给定查询关系rq高度相关的关系rt+1。rt+1与当前节点状态作为低级策略网络的输入进行细致推理得到下一步的动作选择。为防止模型出现过拟合问题,本文还引入了dropout策略对高级策略网络和低级策略网络进行动作退出处理,暂时性地随机隐藏部分神经元,降低模型的参数量。
为了使模型收益最大化,本文通过引入全局奖励和交互奖励函数构造出交互奖励模块,智能体到达目标关系和实体时给予其全局奖励,否则通过交互奖励函数对高级智能体和低级智能体作出的每一步选择进行相似度计算,并将其作为奖励分数及时给予智能体相应的奖励,加强了高级策略网络和低级策略网络之间的联系,提高了模型推理准确度。
2 策略网络
首先对预训练的实体嵌入进行K-means++聚类,将原知识图谱根据关系相似度划分为多个节点簇,再利用实体之间的关系来加强这些节点簇之间的联系,得到处理后的知识图谱G′,在此基础上进行分层强化学习(hierarchical reinforcement learning,HRL)的知识推理。为了保证模型的纠错能力,本文方法还对知识图谱中的三元组〈h,r,t〉添加了逆三元组〈t,r-1,h〉,通过这些逆三元组,智能体能够在推理出现错误时实现后退操作。本文将知识推理过程分为高级策略网络推理和低级策略网络推理两部分,通过高级策略网络获得的关系,指导低级策略网络完成具体的动作选择,找到目标实体后,此次推理任务结束。
2.1 高级策略网络
将当前节点et、给定查询关系rq通过GRU模块对历史推理路径进行编码,得到的历史编码信息ht-1作为高级策略网络的输入,在对知识图谱进行K-means++算法分簇处理后,将与当前时刻所在节点相连接的关系作为候选关系集合,构建出初步的高级策略网络πh′θ,再通过dropout策略对中部分神经元进行随机隐藏,得到最终的高级策略网络πh′θ。高级智能体在高级策略网络的指导下,选择出概率较高的关系作为下一时刻的关系选择。高级策略网络如图2所示。
由表1可以看出,本文方法在NELL-995數据集上取得了最好的推理效果。对比数据集来看,FB15K-237的数据比NELL-995稀疏,而稀疏环境往往会导致大量的路径被截断,不利于RL代理的多跳推理路径的探索,所以NELL-995上的知识推理效果要普遍优于FB15K-237。在FB15K-237数据集中,hits@1和hits@3指标均有提高,而hits@10和MRR指标却下降,导致该现象的原因可能是MultiHop模型是单智能体推理模型,虽然部分指标在长路径推理中效果不如本文方法,但也因此导致MultiHop模型结构要比本文方法简单,降低了模型的复杂度,使其hits@10和MRR指标要优于本文方法;在NELL-995数据集中,各项指标均有明显提升,分析其原因,即使本文方法由于需要多智能体导致资源消耗较大,可由于NELL-995数据集相比较FB15K-237数据集而言规模较小,模型复杂导致的资源消耗问题也不会使模型效果太差。TransE模型作为结构最简单的基于嵌入的模型,在保证连通性的同时大大降低了计算复杂度,相比较其他模型而言,也能在MRR指标上取得较好的效果,但是该类方法解释性较低;而基于强化学习的知识推理不仅推理出结果,还可以提供整条推理路径,大大增加了推理过程的可解释性。
4.2 消融实验
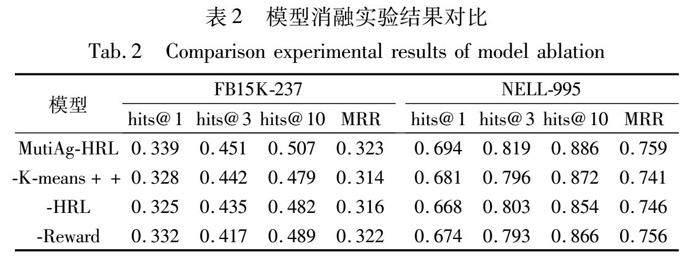
为了更好地论证本文模型引入聚类算法、分层策略网络结构和交互奖励机制的有效性,使用平均倒数排名MRR和推理结果命中率hits@k作为评价指标,在FB15K-237和NELL-995数据集上对方法中三个模块进行了消融实验,结果如表2所示。
通过消融实验证明了本文方法中三个模块的有效性。由表2结果可知,三个模块均对模型推理效果存在一定的影响,在NELL-995数据集上的影响尤为明显。这主要是该数据集规模较小,只有18个关系类型,而高级策略网络在进行关系选择时受数据集关系数量的影响较大,所以与FB15K-237数据集相比,在NELL-995数据集进行知识推理时加入高级策略进行关系选择,会大大提高推理的准确度。本文方法在进行知识推理任务前,先对知识图谱进行聚类处理,使相似度高的节点彼此靠近,提高了智能体所做选择的准确度;在进行知识推理时,通过交互奖励机制对智能体的每一步关系选择和动作选择及时地给予奖励,对于常见的基于强化学习的知识推理模型中的路径多样性奖励、路径长度奖励和单独的全局奖励而言,本文模型的交互奖励函数可以对智能体每一时刻的选择及时地给予奖励,帮助模型选择更高奖励的行为,有效解决了基于强化学习的知识推理模型在推理过程中遇到的稀疏奖励问题,实现收益最大化,因此删除模型中的聚类模块和奖励模块对模型的推理效果也存在一定影响。
4.3 案例研究
通过实验结果与消融实验结果分析,可以看出本文分层强化学习框架在知识图谱推理上的优越性。首先,通过聚类算法对知识图谱进行分簇处理,使关系类型较为相似的事实聚集在一起,便于后续进行知识推理时的关系选择和动作选择;其次,通过分层策略将知识推理分为两部分,高级智能体在高级策略网络的指导下先选择出与查询关系高度相关的关系作为下一时刻的关系选择,而低级策略网络只针对与高级策略网络中选择的关系相连接的实体进行概率分布计算,低级智能体根据实体概率分布选择出下一时刻的动作,大大降低了动作空间的大小,不仅节约了计算资源,还提高了模型推理准确度。为了更直观地表示本文模型在推理时寻找推理路径的过程,本节对路径推理进行案例研究,如图4所示。
图4中的例(a)(b)说明了本文模型能够完成不同推理任务的路径推理,其中,由于知识图谱中存在对已知事实构建的逆三元组,所以在完成例(a)推理任务时可以通过逆三元组及时找到与目标实体高度相关的实体。逆三元组还可以在智能体作出错误决策时及时退回,纠正之前作出的错误决定,实现路径纠错。
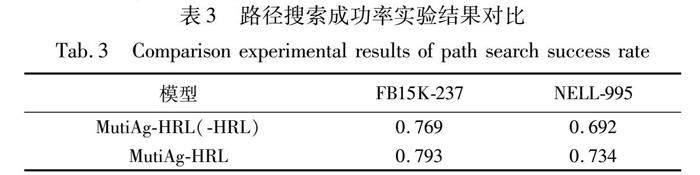
为了评估本文模型的分层策略在进行知识推理过程中路径搜索的效率,本节还对分层策略进行消融(-HRL),与本模型的路径搜索成功率进行对比分析,路径搜索成功率如表3所示。
由表3的实验结果可知,引入分层策略,FB15K-237数据集中的路径搜索成功率提升了2.4%,NELL-995数据集中的路径搜索成功率提升了4.2%。其原因可能是在知识推理过程中进行具体的动作选择时,只将与所选关系相连接的实体作为候选动作空间,大大降低了动作空间的大小,提高了模型的路径搜索成功率。因此,本文通过分层策略进行知识推理,能够有效提升知识推理过程中的路径搜索成功率,从而提升模型的知识推理准确度。
5 结束语
本文提出了一种多智能体的强化学习知识推理方法MutiAg-HRL。模型通过使用分层策略方法,将知识推理过程分解为两个马尔可夫序列决策过程,有效解决了模型在进行长路径推理时动作空间过大的问题;在进行强化学习推理之前采用聚类算法对知识图谱进行处理,辅助智能体更准确地进行下一步选择;通过交互奖励机制及时给予智能体奖励,防止模型出现奖励稀疏的问题,提高了模型的推理能力。
在未来的研究中,将考虑在分层强化学习中引入规则挖掘模块,在进行知识推理之前对与给定查询高度相关的规则进行挖掘,用于指导模型进行知识推理,进而再度提升模型的知识推理效果。此外,还将进一步优化模型的奖励机制,帮助模型更快地找到目标实体。
参考文献:
[1]刘玉华, 翟如钰, 张翔, 等. 知识图谱可视分析研究综述[J]. 计算机辅助设计与图形学学报, 2023,35(1): 23-36. (Liu Yuhua, Zhai Ruyu, Zhang Xiang, et al. Review of knowledge graph visual analysis[J]. Journal of Computer Aided Design & Computer Graphics, 2023,35(1): 23-36.)
[2]官赛萍, 靳小龍, 贾岩涛, 等. 面向知识图谱的知识推理研究进展[J]. 软件学报, 2018, 29(10): 2966-2994. (Guan Saiping, Jin Xiaolong, Jia Yantao, et al. Knowledge reasoning over knowledge graph: a survey[J]. Journal of Software, 2018,29(10): 2966-2994.)
[3]Wu Wenqing, Zhou Zhenfang, Qi Jiangtao, et al. A dynamic graph expansion network for multi-hop knowledge base question answering[J]. Neurocomputing, 2023,515: 37-47.
[4]Shahryar S, Han Qi, Bauke D V, et al. Methodology for development of an expert system to derive knowledge from existing nature-based solutions experiences[J]. MethodsX, 2023,10: 101978.
[5]Cui Hai, Peng Tao, Xiao Feng, et al. Incorporating anticipation embedding into reinforcement learning framework for multi-hop know-ledge graph question answering[J]. Information Sciences, 2022, 619: 745-761.
[6]Ji Shaoxiong, Pan Shirui, Cambria E, et al. A survey on knowledge graphs: representation, acquisition, and applications[J]. IEEE Trans on Neural Networks and Learning Systems, 2022,33(2): 494-514.
[7]Liu Hao, Zhou Shuwang, Chen Changfang, et al. Dynamic know-ledge graph reasoning based on deep reinforcement learning[J]. Knowledge-Based Systems, 2022,241: 108235.
[8]于铁忠, 罗婧, 王利琴, 等. 融合TuckER嵌入和强化学习的知识推理[J]. 计算机系统应用, 2022,31(9): 127-135. (Yu Tiezhong, Luo Jing, Wang Liqin, et al. Knowledge reasoning combining tucker embedding and reinforcement learning[J]. Computer Systems & Applications, 2022,31(9): 127-135.)
[9]Bordes A, Usunier N, Alberto G, et al. Translating embeddings for modeling multi-relational data[C]//Proc of Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 2787-2795.
[10]Wang Zhen, Zhang Jianwen, Feng Jianlin, et al. Knowledge graph embedding by translating on hyperplanes[C]//Proc of the 28th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014: 1112-1119.
[11]Trouillon T, Welbl J, Riedel S, et al. Complex embeddings for simple link prediction[C]//Proc of the 33rd International Conference on International Conference on Machine Learning.[S.l.]: JMLR.org, 2016: 2071-2080.
[12]Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2D know-ledge graph embeddings[C]//Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 1811-1818.
[13]Wang Zikang, Li Linjing, Zeng Dajun. SRGCN: graph-based multi-hop reasoning on knowledge graphs[J]. Neurocomputing, 2021, 454: 280-290.
[14]Zhang Ying, Meng Fandong, Zhang Jinchao, et al. MKGN: a multi-dimensional knowledge enhanced graph network for multi-hop question and answering[J]. IEICE Trans on Information and Systems, 2022, E105.D(4): 807-819.
[15]Li Dengao, Miao Shuyi, Zhao Baofeng, et al. ConvHiA: convolutio-nal network with hierarchical attention for knowledge graph multi-hop reasoning[J]. International Journal of Machine Learning and Cybernetics, 2023,14: 2301-2315.
[16]Du Zhengxiao, Zhou Chang, Yao Jiangchao, et al. CogKR: cognitive graph for multi-hop knowledge reasoning[J]. IEEE Trans on Knowledge and Data Engineering, 2021,35(2): 1283-1295.
[17]Tiwari P, Zhu Hongyin, Pandey H M. DAPath: distance-aware know-ledge graph reasoning based on deep reinforcement learning[J]. Neural Networks, 2021,135(5-6): 1-12.
[18]Xiao Yi, Lan Mingjing, Luo Junyong, et al. Iterative rule-guided reasoning over sparse knowledge graphs with deep reinforcement learning[J]. Information Processing and Management, 2022,59(5): 103040.
[19]Li Shuangyin, Wang Heng, Pan Rong, et al. MemoryPath: a deep reinforcement learning framework for incorporating memory component into knowledge graph reasoning[J]. Neurocomputing, 2021, 419: 273-286.
[20]Saebi M, Krieg S, Zhang Chuxu, et al. Heterogeneous relational reasoning in knowledge graphs with reinforcement learning[J]. Information Fusion, 2022, 88: 12-21.
[21]Paulo H, Jemin G, Mou Shaoshuai. Distributed offline reinforcement learning[C]//Proc of the 61st Conference on Decision and Control. Piscataway, NJ: IEEE Press, 2022: 4621-4626.
[22]Kristina T, Danqi C, Patrick P, et al. Representing text for joint embedding of text and knowledge bases[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1499-1509.
[23]Li Zixuan, Jin Xiaolong, Guan Saiping, et al. Path reasoning over knowledge graph: a multi-agent and reinforcement learning based method[C]//Proc of IEEE International Conference on Data Mining Workshops. Piscataway, NJ: IEEE Press, 2018: 929-936.
[24]Lin X V, Socher R, Xiong Caiming. Multi-hop knowledge graph reasoning with reward shaping [EB/OL]. (2018-09-11). https://arxiv.org/abs/1808.10568.
[25]Adnan Z, Summaya S, Junde C, et al. Complex graph convolutional network for link prediction in knowledge graphs[J]. Expert Systems with Applications, 2022,200: 116796.
[26]Feng Jianzhou, Wei Qikai, Cui Jinman, et al. Novel translation knowledge graph completion model based on 2D convolution[J]. Applied Intelligence, 2022, 52(3): 3266-3275.
[27]Zhang Denghui, Yuan Zixuan, Liu Hao, et al. Learning to walk with dual agents for knowledge graph reasoning[C]//Proc of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 5932-5941.
