基于集成学习的电商销量预测研究分析
2024-05-23张晓颖贺伊雯王立越
张晓颖,贺伊雯,王立越
(长春大学 理学院,长春 130022)
随着大数据时代的兴起,用户信息和电商销售数据成为了电商行业中不可或缺的重要数据资产。在大数据架构和分析技术的支持下,这些数据的价值随着市场需求的增长而不断提升,使得电商销售数据的重要性日益凸显。目前针对电商销售预测的研究主要集中在3个方面:(1)销售预测理论研究。RANA等[1]提出了由遗传算法优化的深度学习模型,并证明了所提出的方法在提供准确的销售预测方面的优越性,记录的调查结果可以作为零售商店寻求提高其销售预测能力的宝贵资源。GAO等[2]在分析数据空间理论的基础上,构建了基于数据空间的制造业多价值链协同数据管理系统架构,建立了基于数据管理系统的产品销售智能预测模型。(2)推荐系统研究。HUANG等[3]基于知识图的推荐技术主要用于解决推荐系统在分析大数据量时遇到的可解释性、冷启动等问题,介绍了基于知识图的推荐技术的4个方面:推荐算法、评价指标、数据集和模型。NI等[4]提出了一种基于RippleNet的混合推荐模型,使用Node2vec-side进行项目肖像建模,并探索项目之间潜在的关联关系。(3)销售数量预测研究。唐中军等[5]在给定有限样本量的情况下,提出了多证据动态加权组合预测和MEDWCF方法对产品的销量进行预测,从而在产品上市前为管理者做出更有效的营销决策。BOONE等[6]讨论了数据爆炸对产品预测的影响以及如何提高数据爆炸的利用率,总结了如何从时间序列数据中洞察消费者行为。
在大数据和互联网快速进步的背景下,电商销售环境变得日益动态且复杂。这种多变的环境使得传统的时间序列预测算法难以实现准确预测。针对这一挑战,许多学者正积极研究具有更强泛化能力的机器学习算法。SINGH等[7]探究了京东某店铺的销售额与相关变量间存在的关系,首先对将商品分为种类最多的两种和种类最少的两种然后分别使用GBDT算法和BP神经网络进行相应的预测。RAIZADA等[8]对几种监督学习算法,如随机森林、KNN、SVM等进行对比分析,建立预测模型,准确估计沃尔玛门店在不同地理位置的几家零售店的可能销售额。在以往传统机器学习算法往往都只是采用一个学习器模型(单个算法模型)来进行的,在某些情况下,单一的学习方法势必存在缺陷,为解决单一学习器在预测中的泛化能力弱等问题,不少学者将集成学习的方法加以研究SHILONG等[9]对沃尔玛的商品销售数据进行分析,利用特征工程提取特征,然后利用LGBoost和XGBoost预测特征的未来销量。它适用于内存资源较少的情况,可以获得很好的销售预测效果。ROHAAN等[10]在随机森林和神经网络等模型的的自定义模型堆中找到了合适的B2B销售倾向模型,从而实现更好的规划和管理,提高销售预测的准确性。
由于目前传统时间序列预测算法对于大数据环境下的电商销售预测已经不再适用,而单一的机器学习模型在预测时又存在着在不同的条件下所表现出的泛化能力弱等问题,本研究采用基于集成学习的方法,对比随机森林RT、渐进梯度回归树GBRT与一般线性回归、弹性网络、支持向量回归、KNN回归树、决策树、多层感知机、AdaBoost在真实环境下电商销售量数据的预测性能,探讨出一个更为高效的电商销量预测方法。
1 基于集成学习的电商销量预测算法
1.1 随机森林
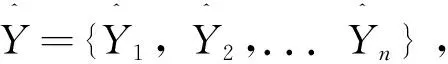
(1)
接下来使用自助法重抽样法来生成单棵CART树的样本,并用随机向量(X,Y)来对样本进行标记,其中训练集的标签值用Y来表示,这样组合模型h(X,θn)就可以用来表示整个随机森林,其中模型的均方误差可表示为:
EX,Y(Y-h(X))2,
(2)
当随机森林中树的数目无限增大时有:
EX,Y(Y-avnh(X,θn))2→EX,Y(Y-Eθh(X,θ))2,
(3)
其回归函数表示为:Y=Eθh(X,θ),在现实场景中,可以假设k充分大,于是可用近似公式:Y=avnh(X,θn)进行替代。
随机森林的泛化误差可以用PE进行表示,那么可以得到CART树的平均泛化误差就为:
PE(tree)=EθEX,Y(Y-Eθh(X,θ))2,
(4)
对于假定所有的θ,都有EY=Exh(X,θ),则有:
(5)

Step1.对数据进行抽样。通过随机且有放回的bootstrap重抽样的方式对每个学习器进行抽样,这里样本子空间定义为抽取到的样本,通过这种方式就完成了对于每个学习器的样本训练集的构建;
Step2.属性子空间的构造。属性子空间的构造包括两个方面一个是对属性子空间进行组成,一个是设置各节点的准侧,在这里前者使用给定的随机参数变量,后者使用各个属性分裂值中较优的为准则;
Step3.建立决策树。决策树是一棵在样本子空间上的无剪枝衍生决策树,然后将决策树进行组合形成一个学习器;
Step4.构建随机森林模型。对Step3所建立的决策树构建成随机森林模型,并对模型进行测试;
Step5.决策投票。首先通过随机森林模型对各个事件进行检测,然后收集来自于各个学习器对与检验数据的投票结果,最后采用较多得票数的策略作为该测试数据的最终方法,并决定其结果。
1.2 渐进梯度回归树
渐进梯度回归树(GBRT)是源自Boosting算法的一种改进迭代回归算法。GBRT 的关键是将全部迭代的数的结果一一相加,累加出的结果作为最后的结果。因此,每一个树都不是最后预测结果的直接决定因素。本研究对电商销量进行预测,电商销量也正是步步累加的结果。预测之前先初始化损失函数。结合实际情况,损失用RMSE来衡量。对于损失函数的优化也就是利用GBRT来缩小预测结果的RMSE,使其达到最小。
GBRT算法的具体步骤如下:
输入:训练集T={(x1,y1),(x2,y2),...?,(xm,ym)}和损失函数L(y,f(x));
Step1.初始化损失函数,即通过迭代使真实值和预测值差异最小化:
(6)
Step2.开始算法迭代:
(1)对m=1,2,3,……,M,迭代建立M棵数;
(2)对i=1,2,3,……,N,用模型中损失函数的负梯度来估计残差,因此残差也就是损失函数的均方误差:
(7)
(3)对rmi进行拟合得到一棵回归树,以便得到第m棵树的叶节点区域RMj;
(4)对j=1,2,3,……,J,计算
cmj=argmin∑xi=RmjL(yi,fm-1(xi)+c),
(8)
(5)更新回归树:
(9)
Step3.完成M棵树的迭代,得到最终模型:
(10)
当随机森林与GBRT进行比较时,能够看到GBRT在一些方面做出了改进:(1)GBRT预测精度一般都比较高,也常常高于随机森林算法,主要的原因就是GBRT在理论上通常都会在模型收敛的时候才停止训练;(2)当能够控制每一次迭代的步长和权值时,就能够尽可能避免过拟合,而在GBRT算法中前后的迭代关系之间可以修复一些较差的树的结果,因此这也是改进的一个方面;(3)由于串行迭代GBRT在训练时对计算空间要求不高,这也使得算法更为有效;(4)因为单个学习器性能并不会影响GBRT的预测精度,即使部分学习器性能较差,通过多次选代,依然可以得到较优的结果。
2 数据仿真
2.1 数据来源与说明
研究数据来源于某线上销售平台的真实历史销量数据与相关数据记录,对原始数据进行性质类别的划分,可以分为:(1)用户的行为数据,其中包括商品交易时间、商品ID、商品点击次数、商品加购次数、商品收藏次数、商品购买次数、在售天数。(2)商品的销售数据,包括每日商品销量、平均价、吊牌价。3.平台的活动数据,包括活动类型、节奏类型。
2.2 特征处理
在原始的数据集的基础上,即商品在用户的行为数据、商品的销售数据和平台的活动数据,通过特征工程理论对上述原始数据的特征进行自动化特征工程处理[13],并利用pandas库和scikit-learn库进行共同处理,在处理过程中主要分为数据集成和自动化特征处理两个部分,数据集成处理示意图如图1所示。

图1 数据集成处理示意图
对数据进行自动化特征处理如表1所示。

表1 参考文献类型数据的自动化特征处理一览表
2.3 模型选择和评价
机器学习中有非常多的回归预测算法,诸如:广义线性模型中的线性回归(LinearRegression)、弹性网络(ElasticNet)等;K近邻中的KNN回归树(KNeighbors Regressor);AdaBoost的迭代算法、决策树、神经网络中的多层感知器(Multi-Layer Perception)和支持向量机之中的支持向量回归、以及本研究所介绍的两种集成学习算法、随机森林(RF)和渐进梯度回归树(GBRT)等。为比较机器学习当中的众多回归预测算法的优度,选取具有代表性的9种回归预测算法,并利用5折交叉检验进行评价,具体结果如表2所示。

表2 各种方法的5折交叉检验表
各算法在5折交叉检验表中的平均得分如图2所示。
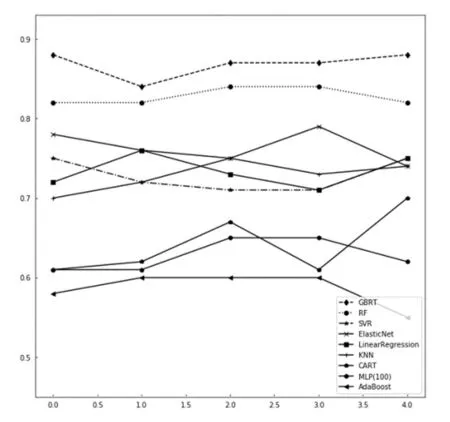
图2 各算法得分折线图
从表1和图2中可看出,拟合优度值较高的是随机森林算法和梯度提升回归树算法,分别达到86.8%和82.8%,得分折线位置远高于其他算法,且得分均值标准差分别为0.014 7和0.009 8。因此,相较于其他回归预测算法而言,随机森林算法和渐进梯度回归树算法在电商销量预测中所表现出的性能优于其他算法。于是选择随机森林算法和渐进梯度回归树算法对电商销量进行算法参数的调整,以使得算法的整体性能更加优越。
2.4 随机森林调参
为了获得算法的最优参数,采用网格搜索(GridSearchCV)对算法进行参数优化。网格搜索不仅可以自动调整参数,还可以交叉验证各参数组合的平均计算精度。此次实例采用5折交叉验证的方法,并取平均值作为模型的预测评价指标。因此,根据随机森林的原则,随机森林的最优参数可以通过网格搜索的方法进行寻找,具体如表3所示。

表3 随机森林最优参数表
2.5 渐进梯度回归树调参
同理,根据梯度提升树原理,利用网格搜索的方法得出随机森林的最优参数,具体如表4所示。

表4 渐进梯度回归树最优参数
3 预测结果分析
在调整优化参数后,需要对算法的性能进行评估,也就是把预测结果与真实值进行比对。利用回归模型中常用的拟合优度、均方误差、均方根误差、平均绝对误差,来评价随机森林算法和梯度提升树算法在电商销量预测过程中的算法适用性情况。
根据5折交叉验证和网格搜索得出的随机森林与GBRT的最优参数,调参后对相应的评价指标进行计算,如表5所示。

表5 随机森林与GBRT的评价指标表
根据性能评价指标表看出,随机森林对电商销量预测的拟合优度(R2)达到85.9%,均方误差(MSE)为7.427,均方根误差(RMSE)为2.725,平均绝对误差(MAE)为0.947。GBRT对电商销量预测的R2达到88.01%,MSE为6.244,RMSE为2.499,MAE为0.982。从拟合优度来说,GBRT算法相对于随机森林对电商销售量的预测效果更好,除平均绝对误差略比随机森林的平均绝对误差高一点之外,其他性能指标比随机森林效果较优。
从预测结果来看,原始数据中商品的销量有高有低,部分商品虽然存在所谓的高销量即“异常值”点,但这两种算法都较好的拟合了原始数据,对这些“异常值”点也都有较好的表达。通过均方误差,均方根误差,平均绝对误差来说均处于可以接受范围之内。整体来看,随机森林算法和GBRT算法对于电商销量预测来说都能较好的符合实际电商销售预测场景中的应用,但GBRT算法在性能指标上相对优于RF随机森林算法,如图3、4所示。
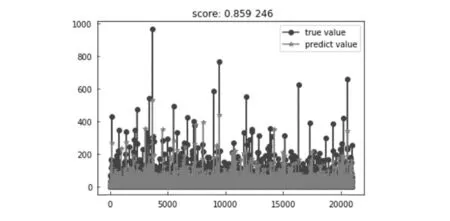
图3 随机森林预测结果

图4 GBRT预测结果
4 结 语
通过某线上销售平台的真实历史向量数据与相关数据记录用集成学习的随机森林和渐进梯度回归、普通线性回归、弹性网络、支持向量回归、KNN回归树、决策树、多层感知机、AdaBoost分别对电商销量数据进行了分析和预测,并评价了各模型的预测性能差异。如结果所示,随机森林和GBRT预测性能更优。通过搜索最优参数,得出更优的电商销量预测模型。利用k折交叉验证对具有代表性的算法进行评价,认为更新参数后的随机森林和GBRT在电商销量预测中所表现出的性能优于其他算法。最后,相对较好的两种更新后的集成算法中,GBRT的预测效果更好。随着网络购物用户的増多,使得电子商务交易量越来越大,这也使得电商产生的销售数据成指数级上涨,近些年来,“大数据”和“机器学习”的概念和技术开始被商界广泛关注,大量的销售数据就变成了一个有待开发和挖掘的数据宝库,只要有技术有需求,自然宝库的价值也就开始凸显。所以在日常的销售预测中应该关注更多的销售细节,将数据更加分类化,这样即使在研究方法一定的情况下,也能够提高现有数据的利用效率,提升电商行业整体价值水平。
