基于云计算智慧平台的健康养老信息推送算法研究
2024-05-23赵丽
赵 丽
(六安职业技术学院 经济管理学院,安徽 六安 237158)
进入信息资源爆炸时代后,互联网技术开始逐步渗入到人们日常生活中[1],在健康、养老等领域发挥巨大作用。而面对海量信息资源,如何捕捉用户个人偏好,为其提供所需信息,逐渐成为很多人关注的重点[2]。对于健康养老用户群体来说,其表现出的信息需求更加个性化,想要将信息推送给合适的对象,就需要信息推送算法的辅助来识别用户需求并找到符合其需求的信息,为这一群体提供更高质量的养老服务。
1 应用云计算智慧平台设计健康养老信息推送算法
1.1 建立健康养老信息主题抽取方案
考虑到不同健康养老信息表达的主体不同,为了找到符合要求的推送信息,应用LDA主题模型建立一种健康养老信息主题抽取方案,将每条信息分解为多个词项,并分析词项和文档关联[4]。应用LDA主题模型进行三层式有向概率计算,获取每个词项的出现概率,与该词项属于某个主题的概率,从而确定健康养老信息的主题。
在已知信息浅层主题数量后,将文本内某个词汇出现的概率计算表示为式(1):
(1)
式中,αi表示第i个词汇,p表示概率值,l表示浅层主题,L表示健康养老信息包含的浅层主题数量,β表示潜在变量,P(αi|βi=l)表示目标词汇属于浅层主题的概率,P(βi=l)表示文本属于该主题的概率。
为了便于理解分析,通过图1所示的词项文档矩阵分解模式,简化式(1)的计算过程。

图1 词项文档矩阵分解示意图
在词项文档矩阵分解结束后,分别建立词项-主题矩阵、主题-文档矩阵,运用LDA模型进行信息主题抽取时,其核心环节就是计算两个矩阵的乘积,考虑文本语义关联后,计算出健康养老信息文本中,目标词汇出现概率。
(2)
式中,d表示文本,δ表示文档分布,φ表示主体分布。
通过求解LDA主题模型可以了解健康养老信息文本中每个词汇出现概率,从中选择出现概率较高的词汇,计算其属于各个主题的概率[4],根据概率值判断当前健康养老信息内容对应的主题,根据信息主题可以将待推送的信息进行分类,辅助推送信息的选择。
1.2 构建用户兴趣度模型
从互联网用户信息浏览历史数据入手,分析各种用户浏览行为,并运用熵权理论计算该行为的权重。以此为基础,构建用户兴趣度模型。其中,互联网用户兴趣度计算公式为:
K(c)=H(ε(c),q(c),ι(c),t(c)),
(3)
式中,c表示健康养老信息,K表示用户兴趣度,H表示兴趣度函数,ε表示保存率,q表示转发率,ι表示点击率,t表示用户在消息页面停留时间。
考虑到用户浏览健康养老推送信息时,各种行为对兴趣度贡献不一样,为了得到更加深入地了解用户兴趣,需要对各种操作行为设置对应的权值。
(4)
式中,w1、w2、w3表示熵权法计算出的权重,η表示信息长度,e表示信息文本中的某一词汇。
在实际操作过程中,需要针对用户浏览记录组建指标矩阵,根据用户浏览行为对兴趣度的影响,从正、逆两个方向对浏览行为数据进行标准化处理。
(5)
应用标准化处理后的数据,和用户浏览行为权重量化结果,构建用户兴趣度模型:
(6)
式中,η表示用户兴趣度模型,w表示权重因子,υ表示用户,F表示用户点击推送信息的时间间隔,Y表示用户使用推送结果的时间跨度。
1.3 设计信息协同过滤推荐算法
在已知待推荐信息主题和用户兴趣偏好后,应用协同过滤推荐算法建立健康养老推送信息筛选策略。实际操作过程中,假如用户对一条健康养老信息有兴趣,则与该信息同属一个主题的其他信息,也很有可能获得用户关注,如图2所示。
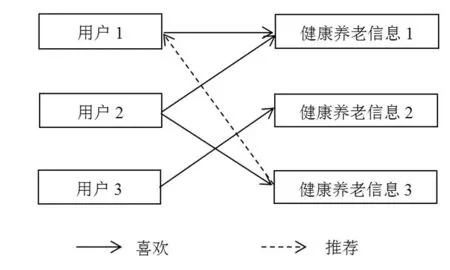
图2 基于项目的协同过滤算法
运用图2所示的基于项目的协同过滤算法进行健康养老信息推荐时,为了简化信息推荐步骤,需要将用户偏好和信息主题均映射为健康养老标签,通过修正后的余弦相似度计算公式,获取不同健康养老信息的相似度,将相似度较高的信息归纳在一个标签内,根据用户的历史浏览内容确定用户兴趣标签,而后再搜索相似度最高的信息资源进行推送。
协同过滤推荐算法的实现主要包括两个步骤。首先,依据健康养老信息资源体系的标准规范,定义用户兴趣关键词,并将所有关键词划分到不同的分类标签之内,然后,应用修正后的余弦相似度计算公式,获取两个向量夹角的余弦值,并以此来衡量选定个体之间的相似程度,当余弦值为0时,每两个向量之间表现出垂直的特点,这也表明两者之间完全不同,反之,余弦值越靠近1,则表明两者之间完全相似。
1.4 生成基于云计算智慧平台的信息推送策略
在健康养老信息推送实现过程中应用云计算智慧平台,本质上是采用虚拟化技术汇总可推送信息,在平台中形成资源池。实际推送过程中可以将每个信息推送问题描述为一个任务,通过云计算智慧平台分离任务要求,在多个虚拟机的共同作用下从资源池找到最符合要求的信息资源,将其推送给用户完成任务。在平台上运行MapReduce框架,实施“分而治之”的思想,将健康养老信息推送任务分解为多个子任务,任务处理主要依托于map(映射)和reducer(规约)两个函数,分解过程如图3所示。
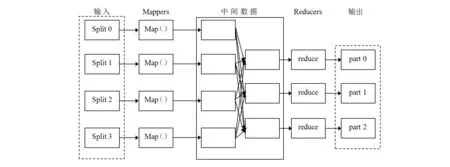
图3 云计算智慧平台的MapReduce数据处理框架
利用云计算智慧平台执行信息推送服务时,其服务质量计算过程如式(7)所示。
hSr={ωr,Mr,Br,Er,Or},
(7)
式中,r表示云计算智慧平台的虚拟机,S表示信息推送任务集,h表示服务质量,ω表示操作时间,M表示内存,B表示网络带宽,E、O分别表示安全性、信息推送能耗。
而后,分析养老信息推送总时间:
(8)
式中,ω′表示云计算智慧平台完成信息推送服务消耗的总时间,ξ表示平台内虚拟机数量,λ表示健康养老信息推送任务,ωrλ表示虚拟机r完成推送任务λ消耗的时间。
用户对云计算智慧平台推送服务的满意程度可以通过式(9)~(11)进行计算。
(9)
(10)
(11)
根据上述计算结果,对云计算智慧平台进行调整,确保其在健康养老信息推送过程中,可以保证信息推送任务执行情况符合要求。
2 实验
2.1 实验准备
提出的健康养老信息推荐算法应用了云计算智慧平台,属于创新型研究项目。为了确保该算法可以发挥良好的信息推送性能,需要进行实验测试。在实验准备节点利用现有的开源云平台(Cloud Foundry)开发出全新的云计算智慧平台,该平台的主要架构如图4所示。
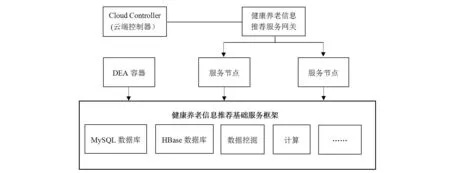
图4 健康养老信息推送服务云计算智慧平台架构
由图4可知,服务节点不能直接从DEA容器包含应用中获取服务,而是需要在基础服务架构上创建一个服务实例,经由基础架构绑定服务实例和DEA容器,绑定后DEA也可以通过服务实例获取读物节点提供的信息。
考虑到健康养老信息推荐涉及的内容繁多,且所有信息都需要上传到平台,以便后续信息筛选和信息推送,为了避免出现失误,在开发云计算智慧平台时,需要添加一个后台管理工具cfdo(云代工厂),该工具提供的主要功能如表1所示。
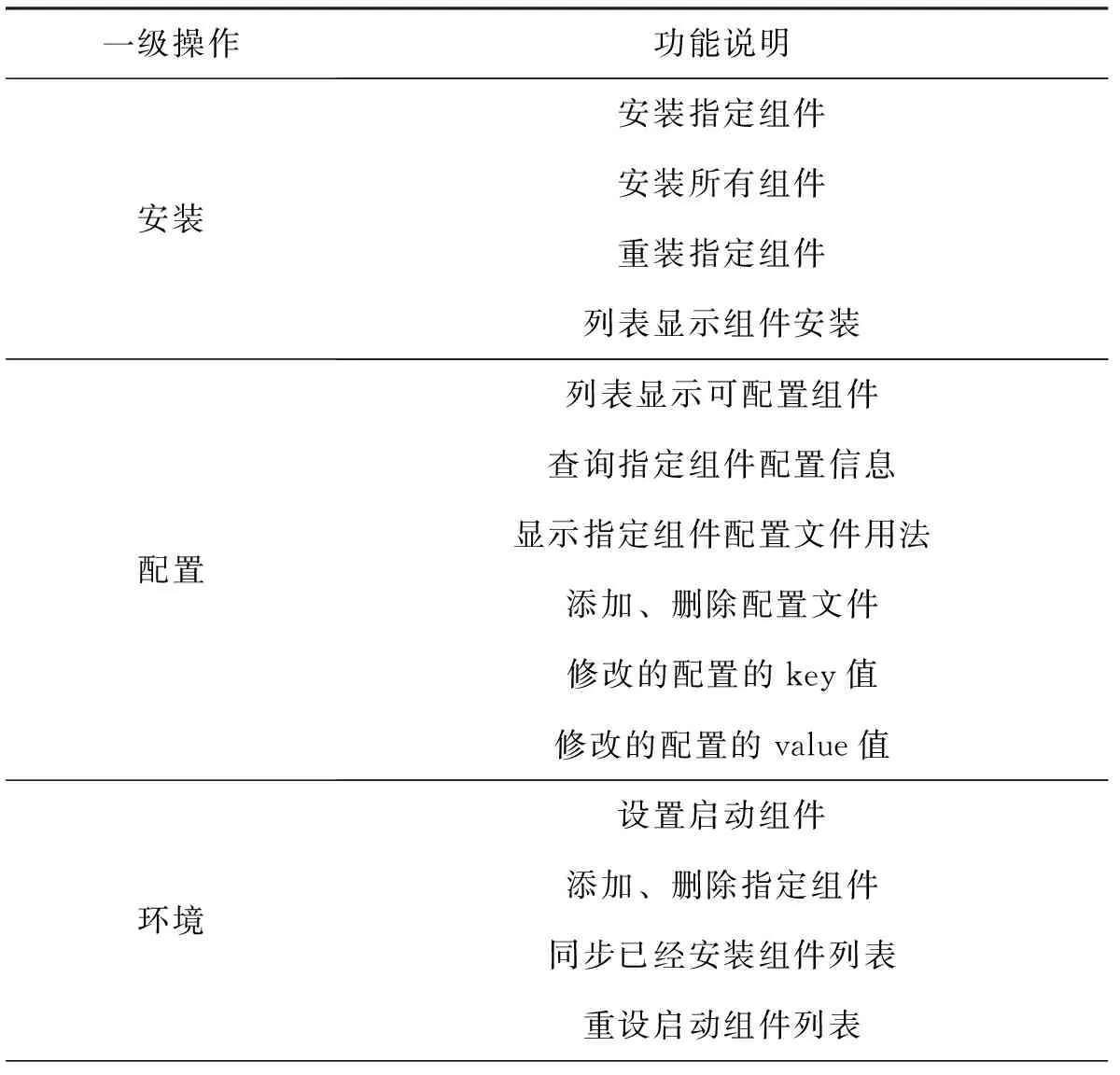
表1 后台管理工具cfdo主要功能操作
可用于健康养老信息推送的云计算智慧平台开发结束后,采集此次实验所需的数据,从网络上获取带有特征标签的健康养老相关的公开数据构建实验数据集。再选择100名健康养老用户来作为实验对象,应用所提算法进行健康养老信息推送实验。同时,为了提升实验结果的说服力,此次实验过程中还同时应用了文献[2,5-6]提出的方法进行信息推送,与所提算法推送结果进行对比,体现所提算法的优越性。
2.2 实验结果分析
根据用户注册时选取的兴趣标签,以及用户历史浏览数据,构建用户兴趣模型。建模完成后,筛选所有用户兴趣标签只保留3个记录在数据库中,形成图5所示的存储记录。
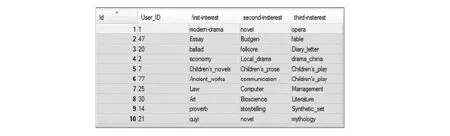
图5 用户兴趣标签记录结果
以图5所示的用户兴趣标签为基础,在云计算智慧平台的辅助下进行健康养老信息推送,用户最终接收到的信息如图6所示。

图6 信息推送结果
从图6可以看出,所提信息推送算法具有可行性。而为了对比该算法推送结果和其他方法的推送结果,采用F-Measure指标衡量信息推送准确性,该指标是准确率和召回率的加权调和平均值,具体计算公式为:
(12)
式中,F表示F-Measure指标,R表示健康养老信息推送结果的召回率,P表示推送结果的准确率。
应用公式(12)进行计算时,准确率和召回率需要依据用户浏览记录进行计算,最终得出不同信息推送算法的F-Measure对比结果如图7所示。
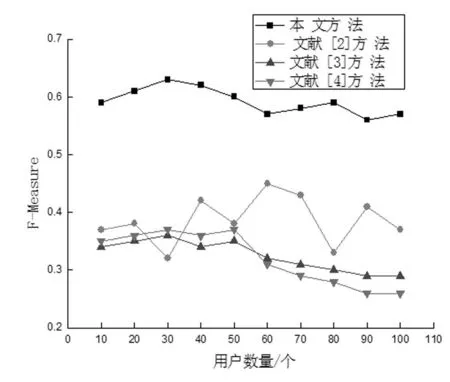
图7 不同信息推送算法的F-Measure对比
由图7可知,所提方法的F-Measure值在0.6左右,上下浮动不大,而其他3种方法信息推送F-Mrasure平均值分别为0.41、0.35和0.34。综上所述,所提方法与3种文献提出方法相比,信息推送F-Measure值提升了31.67%、41.67%、43.33%,应用该算法可以推送出更加符合用户需求的信息。
总之,随着人们对健康养老问题的重视程度不断增加,健康养老信息推送也成为备受关注的问题。为了提升信息推送质量,提供更好的健康养老服务[7],设计一种基于云计算智慧平台的推送算法,利用云计算强大的数据处理能力,可以实现信息精准推送,满足人们的个性化信息需求。
