基于监督学习与深度强化学习的任务型对话模型设计与实现
2024-05-23李昱珩朱彦霞
李昱珩 朱彦霞


摘 要:【目的】探讨智能对话系统中任务型对话模型的设计,提出一个基于监督学习和强化学习的任务型对话系统框架。【方法】采用监督学习和强化学习相结合的方法。首先,将开放域对话模型的生成回复嵌入到任务型回复的过程中,构建一个综合的对话模型。其次,利用监督学习和迁移学习的方法,构建对话策略模型,用于指导对话系统的决策过程。最后,采用深度强化学习算法进行优化更新,以提高对话系统的性能。【结果】实验结果表明,任务型对话系统模型在评估指标BLEU、ROUGE和F1分数方面优于其他基准模型。该模型具备良好的对话生成能力和回复多样性,能够生成准确且多样化的回复。【结论】通过综合应用监督学习和强化学习的方法,成功设计了一个基于任务型对话模型的智能对话系统框架。该框架在任务型对话上取得了较好的性能,为智能对话系统的发展提供了有益的探索。
关键词:任务型对话系统;监督学习;强化学习
中图分类号:TP181 文献标志码:A 文章编号:1003-5168(2024)06-0020-05
DOI:10.19968/j.cnki.hnkj.1003-5168.2024.06.004
Design and Implementation of a Task-Oriented Dialogue Model Based on Supervised Learning and Deep Reinforcement Learning
LI Yuheng1 ZHU Yanxia2
(1. School of Mathematical Sciences, East China Normal University, Shanghai 200241, China; 2. Henan General Hospital, Zhengzhou 450000, China)
Abstract:[Purposes] This study aims to explore the design of task-oriented dialogue models in intelligent conversational systems and propose a task-oriented dialogue system framework based on supervised learning and reinforcement learning. [Methods] The study adopts a combined approach of supervised learning and reinforcement learning. Firstly, the generation replies from open-domain dialogue models are incorporated into the task-oriented dialogue process, constructing a comprehensive dialogue model. Then, using methods of supervised learning and transfer learning, a dialogue policy model is constructed to guide the decision-making process of the dialogue system. Finally, deep reinforcement learning algorithms are employed for optimization and updates to enhance the performance of the dialogue system. [Findings] Experimental results demonstrate that the task-oriented dialogue system model outperforms other baseline models in evaluation metrics such as BLEU, ROUGE, and F1 scores. The model exhibits good dialogue generation capabilities and response diversity, generating accurate and diverse replies. [Conclusions] The study successfully designs an intelligent dialogue system framework based on task-oriented dialogue models by integrating supervised learning and reinforcement learning. The framework shows promising performance in task-oriented dialogue tasks, providing valuable exploration for the development of intelligent conversational systems.
Keywords: task-oriented dialogue system; supervised learning; reinforcement learning
0 引言
隨着人工智能技术的快速发展,人机交互、智能助手、智能客服、问答咨询等人机对话场景的广泛应用,以及ChatGPT的问世极大地推动了自然语言处理(Natural Language Processing,NLP)领域的快速进展,使得智能对话系统的研究成为学术界及各应用行业的研究热点之一。
目前,智能对话系统主要分为开放域对话系统和任务型对话系统。开放域对话系统主要用于闲聊领域,旨在提供自由流畅的对话体验。而任务型对话系统则专注于帮助用户完成特定任务,旨在提供任务相关的指导和支持。任务型对话系统的设计旨在满足用户对特定任务的需求,并通过提供准确的指导和目标导向的交互,能够提供准确的信息和服务,在特定的领域的任务中表现出色,实用性较强。近年来,任务型对话系统的关键技术取得了显著的进展,并在众多领域得到广泛应用。典型的任务型对话系统包括苹果的Siri、微软的小娜(Cortana)[1]、阿里巴巴的天猫精灵[2]和京东的JIMI客服机器人等。然而,任务型对话系统在特定任务的应用场景中依然面临着对话数据规模有限以及用户需求复杂、需要进行多轮互动等挑战。为了提高对话任务的效率,本研究对基于监督学习与强化学习的任务型对话模型进行了研究与探索。
1 相关研究
1.1 任务型对话系统一般过程
任务型对话系统实现方式主要是端到端(End-to-End)和管道(Pipeline)。端到端方法[3]使用单一模块直接完成从输入的文本建模到输出的回复,其训练参数少、泛化能力强、应用场景较灵活,但优化难度与解释性较差。管道方法[4]将系统视为一个流水线,把任务分为自然语言理解(Natural Language Understanding,NLU)、对话状态跟踪(Dialog State Tracking,DST)、对话策略学习(Dialogue Policy Learning,DPL)、自然语言生成(Natural Language Generation,NLG)4个模块,模块间可并行且通过级联实现对话,其复杂度高、易于解释、商用性强。
任务型对话系统的一般过程如图1所示。任务系统首先通过自然语言理解(NLU)将用户话语(Utterance)转化为语义信息,并提取用户意图(Intent)和槽值(Slot)信息;其次对话状态跟踪(DST)根据自然语言理解(NLU)的信息评估得到用户目标和请求,构建并记录对话状态;再次对话策略学习(DPL)根据对话状态(Dialog State)来决策系统采取的动作(Action);最后自然语言生成将对话策略(DPL)生成的对话动作转换为最终的自然语言。
1.2 任务型对话系统研究进展
在任务型对话系统中,准确理解用户意图并提取槽值数据中的关键信息对于实现准确性至关重要[5],因此,近年来NLU领域涌现出许多新的技术及应用成果。叶铱雷等[6]针对任务型多轮对话,提出了一种粗粒度意图识别方法,该方法针对特定复杂场景下的多轮对话,将意图识别任务分解为对话序列标注和意图分类两个任务,有效地提高用户意图识别率;高作缘和陶宏才[7]提出了一种基于RoBERTa-WWW及可模块替换的压缩多任务联合模型,该模型意图识别、语义槽填充等联合进行训练,同时引入Focalloss机制均衡优化数据;王明虎等[8]提出了一种基于RoBERTa和图增强Transformer的序列推荐方法,该方法利用RoBERTa对评论文本进行预训练,以捕捉语义特征和初步建模用户的个性化兴趣,将商品交互的时序特征图输入到图增强Transformer后,再接入全连接层,以提升用户兴趣偏好的整体性捕捉和实现对商品的预测评分。
对话策略是根据自然语言理解的结果和对话状态跟踪的输出来制定对话动作,因此对话策略学习在自然语言理解和自然语言生成中发挥着重要作用。Levin等[9]最早将对话策略建模称为马尔可夫决策过程(Markov Decision Process,MDP)并进行了复杂性分析,为基于强化学习的对话策略研究奠定了基础;Takanobu等[10]提出了一种基于对抗性逆强化学习的引导对话策略学习算法,用于多领域任务导向对话中的联合奖励估计和策略优化;Wu等[11]提出了Switch-DDQ框架,该框架扩展了Deep Dyna-Q(DDQ)框架,集成一个切换器,该切换器可以自动确定使用真实体验还是模拟体验进行Q学习,提高了模型训练效率。
2 设计与实验
2.1 基于监督学习与强化学习的任务型对话模型设计
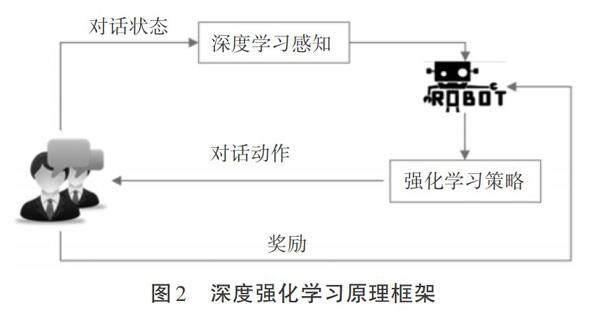
监督学习(Supervised Learning,SL)和强化学习(Reinforcement Learning,RL)是机器学习领域中两个重要的分支。监督学习是一种利用已标记的训练数据去学习输入函数与输出函数之间映射关系的机器学习任务。它通常应用于解决分类问题和回归问题,其中分类问题涉及将输入实例分配到预定义的类别中,而回归问题涉及预测连续值输出。强化学习是一种涉及智能体(Agent)与环境(Environment)之间不断交互的学习过程。在这个过程中,智能体通过与环境进行交互,不断学习并改进其策略(Policy),以最大化获得其回报(Reward)。强化学习的目标是通过试错和学习,使智能体能够在复杂的动态环境中做出准确的决策并获得最大的累积回报[12]。强化学习过程的实质[13]是Agent随着时间推移与环境交互反馈进行不断学习的过程。在t时刻,Agent接受狀态s遵循π(a|s)策略从动作空间中选择一个动作a,作用于环境,环境反馈奖赏r并且依据概率P(s'|s,a)转换到下一个状态St'。强化学习的最终目的是通过调整自身策略来最大化累计奖赏Rt=[k=0∞λrt+k],其中:λ∈[0,1]为折扣因子;状态动作函数为Qπ(s,a)=[E(t=0∞γrt|S=s,A=a,π]),根据π=argmaxQπ(s,a)(a∈A)得到最优策略。深度强化学习是深度学习与强化学习的深度融合,该方法可通过构建并训练Agent用于知识库的构建与学习,其原理框架如图2所示。
目前,基于强化学习的对话策略技术[14]主要有基于值函数逼近的对话策略、基于策略梯度的对话策略、基于层次的对话策略、基于强化学习模型的对话策略、基于逆强化学习的对话策略等。在现实世界中,非基于模型的对话策略算法的训练试错成本相对较高,在考虑成本的前提下,一种可行的方法是利用成熟的模型来完成环境交互过程。具体来说就是根据学习到的模型去规划一系列动作,然后将这些动作应用于相似的场景中(如采用Model Predictive Control,MPC模型[15]),或者根据模型生成模拟样本数据并利用这些模拟数据进行策略或值函数的评估(如Dyna-Q方法[16]),这样的方法能够在较低的成本下改善对话策略算法的性能。
本研究设计的基于监督学习和强化学习的任务型对话系统框架如图3所示。该框架将开放域对话模型的生成回复嵌入到任务型回复的过程中。首先,采用监督学习的方法构建对话策略模型,利用行业中现有的真实对话数据集。其次,借鉴迁移学习思想,将用户输入传递给现有的成熟或开源的对话模型,获取初步的用户意图和槽值,并进行初步的用户或Agent反馈,计算Q(s,a|θi)。最后,在此基础上将初步形成的用户意图和槽值传入基于监督学习构建的对话模型中,获取Yi,并计算损失函数L(θi)=Es,a,r,s'[Yi-Q(s,a|θi))2](其中:s表示当前状态;a表示当前状态下采取的动作;r表示当前状态下采取a动作所对应的奖惩;s'代表下一个状态;i表示迭代次数)。在训练过程中,记录真实用户体验过程,并利用深度强化学习算法更新对话模型和经验池。
本模型中基于监督学习生成的对话模型,可作为基于开放模型的对话模型迁移到新环境中的验证。同时,在真实环境中应用深度强化学习,能够实现对模型的优化更新,减少真实人员验证的参与度。
2.2 任务型对话模型实验
2.2.1 实验环境与测试数据。
2.2.1.1 实验环境。本实验操作系统为Windows 10;处理器为 amd ryzen 55 800x;内存128 GB;显卡为A4 000;采用Python编程语言3.6版本。
2.2.1.2 实验测试数据。以某大赛提供的电商客服为实验数据[17],实验数据集合基本情况见表1。
2.2.2 实验过程及结果。
2.2.2.1 数据预处理过程。本研究的数据预处理工作包括对Session进行拆分以获取对话历史记录,合并同一ID用户的连续对话内容,删除停用词等操作。对于多轮对话,本研究保留了上一轮的对话信息,数据集构建的样例如图4所示。
2.2.2.2 任务型对话测试。本模型测试过程中的一个回复生成情况如图5所示。
2.2.2.3 性能测试。本研究使用了Seq2Seq模型、BERT-Retrieval模型与本研究提出的模型对测试数据集进行了实验对比和性能评估。在深度强化学习中,本研究将折扣因子γ设为0.7,dropout概率设为0.05。模型的优化方法采用了Adam优化器,学习速率设为0.001。BLEU和ROUGE分数是广泛应用于自然语言处理和多轮对话生成任务中的评估指标,用于衡量模型输出与目标文本之间的相似度;DISTINCT2用于评估回复的多样性;而F1分数则用于评估准确性和召回率。各模型性能测试结果见表2。
从表2可知,本研究模型在BLEU、ROUGE和F1分数方面表现优于其他基准模型,这表明该研究模型在对话生成方面能够有效地学习京东客服的对话模式,并且回复模型的多样性也表现较好。
3 结语
本研究基于监督学习和深度强化学习的模型设计了一个整合开放域任务型对话模型的框架。通过监督学习方法构建对话策略模型,利用真实任务型对话数据集进行训练;利用迁移学习思想,将用户输入传递给开放域对话模型,获取初步的用户意图、槽值、Agent反馈;用t时刻输入词汇及基于监督学习对话策略输出词汇作为t时刻状态;用度量相似性的评价指标双语评估替换指标作为奖励。同时,记录真实用户体验并利用深度强化学习算法更新对话模型和经验池,减少了真实人员验证的参与度,且该模型在实验中性能表现较好。
参考文献:
[1]HOY M B.Alexa,siri,cortana,and more: an introduction to voice assistants[J].Med Ref Serv Q,2018(1):81-88.
[2]天猫精灵鲍娟:天猫精灵用AI连接家庭全场景智慧营销[J].国际品牌观察,2021(20):47-48.
[3]王堃,林民,李艳玲.端到端对话系统意图语义槽联合识别研究综述[J].计算机工程与应用,2020(14):14-25.
[4]赵阳洋,王振宇,王佩,等.任务型对话系统研究综述[J].计算机学报,2020(10):1862-1896.
[5]于丹,闫晓宇,王艳秋,等.任务型对话机器人的设计及其应用[J].软件工程,2021(2):55-59.
[6]叶铱雷,曹斌,范菁,等.面向任务型多轮对话的粗粒度意图识别方法[J].小型微型计算机系统,2020(8):1620-1626.
[7]高作缘,陶宏才.面向任务型对话机器人的多任务联合模型研究[J].成都信息工程大学学报,2023(3):251-257.
[8]王明虎,石智奎,苏佳,等.基于RoBERTa和图增强Transformer的序列推荐方法[J].计算机工程,2024:1-12.
[9]LEVIN E,PIERACCINI R,ECKERT W. Learning dialogue strategies within the Markov decision process framework[C]. 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings,1997:72-79.
[10]TAKANOBU R,ZHU H L,HUAN M L.Guided dialog policy learning: reward estimation for multi-domain task-oriented dialog[J]. CoRR,2019:100-110.
[11]WU Y X, LI X J, LIU J J, etal. Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2019(33):7289-7296.
[12]MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature,2015(7540):529-33.
[13]馬骋乾,谢伟,孙伟杰.强化学习研究综述[J].指挥控制与仿真,2018(6):68-72.
[14]徐恺,王振宇,王旭,等.基于强化学习的任务型对话策略研究综述[J].计算机学报,2024,1-33.
[15]KOLLER T, BERKENKAMP F, TURCHETTA M, et al. Learning-Based Model Predictive Control for Safe Exploration[J]. Annual Review of Control,Robotics,and Autonomous Systems,2020(3):269-296.
[16]PENG B L, LI X J, GAO J F, et al. Deep dyna-q: Integrating planning for task-completion dialogue policy learning[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne,Australia,2018:2182-219.
[17]SIMON J Y. JDDC-Baseline-Seq2Seq[EB/OL]. (2018-05-07)[2023-11-12]. https://github.com/SimonJYang/JDDC-Baseline-Seq2Seq.
