基于YOLOv7的糖果气泡缺陷识别研究
2024-05-20方晓东朱婷婷李星佑
方晓东, 朱婷婷, 吴 旻, 李星佑, 薛 胜
(南京林业大学机械电子工程学院,江苏 南京 210037)
1 研究背景
1.1 糖果气泡
企业在生产硬糖的过程中往往会出现气泡缺陷[1],主要有以下几点原因:糖浆中的空气未充分排出:制作硬糖时,如果没有充分去除糖浆中的微小气泡,这些气泡在糖块成形过程中会被保留下来;糖浆中含水量、温度过高,会导致硬糖在成形过程中出现沸腾,从而形成表面气泡;冷却速度过快,糖浆外部会迅速凝固形成硬壳,将内部气泡困住。
硬糖中出现气泡缺陷会影响其外观和口感,因此需要对含气泡的硬糖进行检测剔除。检测气泡缺陷的常用方法分为人工检测与在线检测[2,3]。其中人工检测是通过对硬糖的外观进行仔细观察,可以直观地看出表面或内部存在的气泡;还可以用小锤等工具敲击糖块,听声音判断是否存在空洞。这种方法简单易行,但容易遗漏, 且主观性较大,只能检查样品的一部分。在线检测包括透光检测[4]、X光检测[5]。透光检测是利用光线透过糖块,观察到内部的气泡。这种方法使用透光装置,能够全面地检查每个糖块。X光检测是使用X光片或CT扫描进行无损检测,可以清楚地显示出糖块内部的气泡情况。这种方法准确可靠,但需要专门设备,成本较高。剔除方法通常是利用人工目视或借助工具检测气泡后,手动将其舀除或挑掉。也可以在线检测后,设置气嘴将含气泡糖块自动挑剔,确保送入包装的硬糖无气泡缺陷,以保证产品质量。
1.2 目标检测
目标检测是计算机视觉领域的一个重要任务,旨在识别图像或视频中的物体并确定它们的位置。目标检测具有广泛的用途,如自动驾驶、安全监控、工业质检、医疗影像分析等。
在目标检测任务中,模型需要识别物体的类别,并且精确地标定出物体在图像中的位置,通常以矩形边界框的形式表示。早期的目标检测方法主要基于手工设计的特征提取器和机器学习分类器,如Haar级联检测器和Histogram of Oriented Gradients (HOG)。这些方法在一些场景下表现不错,但通常对于复杂的背景和物体变化敏感性较高。
深度学习的兴起改变了目标检测领域。卷积神经网络(CNN)在图像特征提取方面表现出色,为目标检测任务提供了更强大的工具。一些重要的深度学习目标检测算法包括:Region-CNN (R-CNN)[6]、Fast R-CNN[7]、Faster R-CNN[8]等,它们引入了候选区域生成和卷积神经网络来提高检测性能和速度;YOLO(You Only Look Once)[9]算法通过将目标检测问题转化为回归问题,同时预测目标的类别和位置,实现了实时性能和较高的准确度;SSD[10](Single Shot MultiBox Detector)是一种基于单次前向传播的目标检测器,可以同时检测多个不同尺寸的目标;RetinaNet[11]引入了Focal Loss来处理目标检测中的类别不平衡问题,提高了目标检测的鲁棒性。
目标检测算法的训练需要大量的标记数据,常用的数据集包括COCO、PASCAL VOC、ImageNet等。这些数据集包含了多种不同类别的物体和相应的边界框标注,用于模型训练和性能评估。目标检测领域仍然在不断发展,包括改进性能、提高鲁棒性、减少标注成本、处理遮挡和多目标等方面的挑战。近年来,深度强化学习和自监督学习等方法也在目标检测中得到了应用。
总之,目标检测算法经历了从传统方法到深度学习方法的演进,不断取得了突破性的进展,为许多实际应用提供了有力的支持。
2 识别算法
2.1 图像预处理
对采集到的相关糖果图像进行预处理,让图像更好地适应模型:采用直方图均衡化方法来调整糖果图像的亮度分布,使得糖果图像中的亮度级别更加均匀,从而增强图像的对比度,使得气泡缺陷细节更加清晰;采用中值滤波[12]方法:用中值代替像素周围邻域的值,可以有效去除图像中的噪声,使得图像更加清晰。传统的图片缩放方法按照固定尺寸来进行缩放会造成图片扭曲变形的问题。Letterbox自适应缩放技术通过填充最少的灰边像素来将任意大小的图片调整为所需输入图片大小。resize为640×640的RGB图像。通过图像预处理,便于后续的糖果气泡缺陷检测。
图1 输入图层ReOrg操作
2.2 模型构建
ReOrg操作是对输入的信息进行切片操作,和YOLOv5的focus操作类似,使输入图层尽可能保持原信息并进行下采样:将一张图隔列隔行取值,切分成4块再进行信息的拼接,类似的下采样操作还包括均值池化,最大值池化等,但池化操作会将原始信息进行加工(均值)或舍弃(最大值),丢失原始信息源,在一定程度上,切片拼接操作可以最大程度保留信息源。
2.3 参数设计与优化
2.3.1 simOTA
Label assignment在目标检测中非常重要,它是一个预定义的规则,能够分配每个anchor的正负,不同大小、形状、遮挡程度的目标,其positive/negative的判定条件不同,需要使用动态的分配方法实现Label assignment。OTA将Label assignment问题从global层面出发并看成了一个最优传输的问题[13],“全局花费最小”时,可得到最优的标签分配方式。OTA[14]需要使用Sinkhorn-Knopp algorithm来优化,这会增加额外的训练时间。使用simOTA能够做到自动地分析每个gt要拥有多少个正样本、能自动决定每个gt要从哪个特征图来检测。相比较OTA,simOTA运算速度更快、避免额外超参数。
2.3.2 重参化
结构重参数化[15](structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。在现实场景中,训练资源一般是相对丰富的,我们更在意推理时的开销和性能,因此我们想要训练时的结构较大,具备某种好的性质(更高的精度),转换得到的推理时结构较小且保留这种性质(相同的精度),即用一个结构的一组参数转换为另一组参数,并用转换得到的参数来参数化(parameterize)另一个结构。只要参数的转换是等价的,这两个结构的替换就是等价的。在卷积计算中:
(1)
对于输入特征图,先进行K(1)和I卷积,K(2)和I卷积后再对结果进行相加,与先进行K(1)和K(2)的逐点相加后再和I进行卷积得到的结果是一致的。说明在YOLOv7中可使用结构重参数化,在保证结构不变的情况下获得更高的检测精度。原本在训练的时候,identity支路、3×3支路、1×1支路推理前需要融合三者的w、b来获取训练时各支路的w、b ;w1在identity支路上进行bn后得到w11,b11;w2在3×3支路上进行bn后得到w21,b21;w3 在1×1支路上进行bn后得到w31,b31;重参化后identity和1×1支路的权重会转换为3×3形状的权重后进行bn,bn的公式如下:
(2)
其中:β、γ是可训练参数,参与整个网络的BP。训练时三条支路如图2所示。
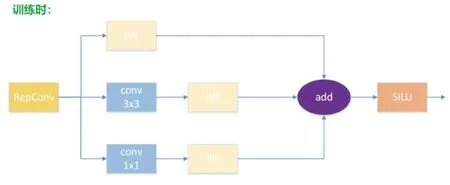
图2 训练时三条支路
转换后的3×3的权重为wnew=w11+w21+w31;推理时的新的3×3卷积将是:
(3)
推理时结构重参化如图3所示。

图3 推理时结构重参化为一条支路
3 实验结果与分析
3.1 采集设备
搭建的糖果图像采集装置如图4所示。
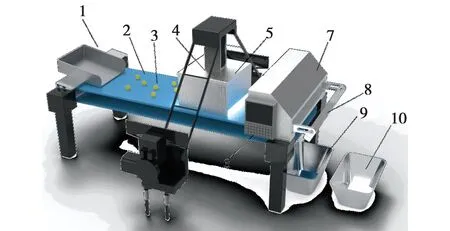
图4 糖果图像采集装置1.上料机构;2.传送带;3.硬糖;4.工业相机;5.光源;6.Jetson Xavier NX板;7.PLC与喷阀机构;8.气动喷嘴;9.缺陷糖果收集箱;10.标准糖果收集箱
采用专门的仪器设备采集到相关的糖果图像。具体为:使用专门的仪器设备3D激光轮廓传感器[16],型号为MV-DP2470-01H。首先将3D激光轮廓传感器固定在距离撒有糖果的传送带高75 cm的位置,然后打开光源,通过3DMVS软件控制传感器启动、调换模式进行图像的拍摄,接着检查传感器是否可以拍摄照片。准备完毕后启动传送带进行拍摄,糖果的RGB图如图5所示。最后关闭传感器,整理收到的图像数据。运用2.1节中的图像处理技术对图像进行预处理使后续的缺陷检测提高精度。根据采集到的图片,观察缺陷种类,将所有糖果划分为正常糖果、轮廓不规则糖果、表面光滑带气泡糖果、表面坑洞带气泡糖果,随后进行数据集的划分。
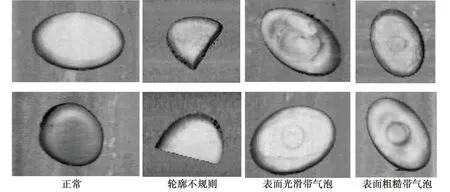
图5 相关糖果的RGB图
3.2 YOLOv7网络
YOLOv7网络主要由BackBone网络、Neck网络和Detect网络组成,YOLOv7结构示意图如图6所示。BackBone网络[17]包含CBS结构、SPP结构、CSP结构,作为特征提取器,用来从输入图像中学习和提取视觉特征。这些视觉特征包含了输入图像的空间信息,是对象检测任务的重要信息来源。Neck网络[18]包含路径聚合网络PAN[19]和特征金字塔FPN网络[20],可以做到如下内容。(1)在不同尺度上聚合特征: Neck网络会聚合和整合Backbone网络输出的不同尺度的特征图,合并它们的语义信息。这对检测不同尺度目标非常有帮助。(2)强化特征表达: Neck网络中通常会引入注意力机制或残差结构来增强特征图在通道或空间方向的表示能力,输出更强大的特征。(3)减少目标丢失: 通过跨尺度信息交互,可以减少仅存在于某一个尺度下的小目标被漏检的情况。(4)提升检测头效率: Neck网络缩减了特征图的大小和通道,减少了检测头的计算量,提高检测速度。这种多尺度特征融合增强了检测网络表示不同大小目标的能力,既提高了检测精度,也优化了检测速度。Detect网络根据Backbone和Neck提取到的特征图,来预测和生成最终的对象检测结果,包括如下内容。(1)生成边界框(Bounding Box): Detect网络会在特征图的每个位置上,预测 potential 的边界框坐标(如框的中心点、宽高等)。(2)类别预测(Classification): 为每个预测到的边界框生成一个类别概率分布,预测该框所包含目标的类别。(3)评分预测(Scoring): 为每个边界框预测一个置信度分数,表示预测框中是否包含某个目标的置信程度。Detect网络中的关键是令牌分配算法(Token Labeling Algorithm)。该算法使用迭代优化的方式为每个特征图位置分配最匹配的边界框。这样一来,Detect网络可以高效且准确地完成检测和识别。

图6 YOLOv7网络结构示意图
3.3 实验结果
本研究采用召回率(recall)、精准率(precision)、作为YOLOv7网络评价指标。
(3)
(4)
其中TP表示将正确类预测为正确类别的个数,FN表示将正确类别预测为错误类别的个数,FP表示将负类别预测为正确类别的个数。
实验结果如图7所示。
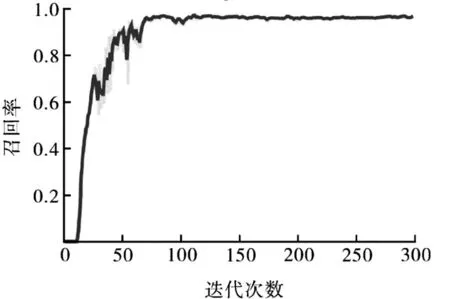
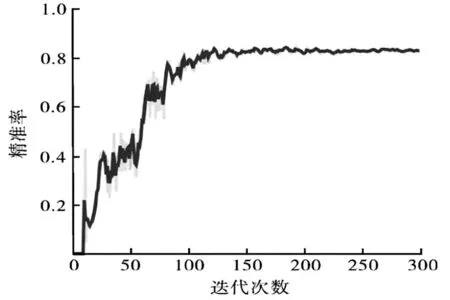
图7 实验结果
实验结果显示,在经过200次迭代后,YOLOv7网络趋于收敛,其召回率达到97%,这表明该网络能够实现对缺陷的糖果的精准检测分类。
