稀疏激光雷达深度图无监督域自适应算法
2024-05-20张睿杰
张睿杰
(重庆交通大学机电与车辆工程学院,重庆 400074)
0 引言
深度传感在许多任务中有着非常重要的作用,如定位[1]、3D传感[2]和自动驾驶[3]。激光雷达设备可以通过激光传感器测量物体与设备之间的距离,因此常常被集成到自主机器人和车辆中,以提供深度信息。然而,由于现有的激光雷达只能提供有限的水平扫描线,并且测量距离通常不会太远,激光雷达提供的深度图无法为机器人提供足够的深度信息来确定与其他物体的距离。而且增加激光雷达扫描密度的成本过高。因此,从稀疏激光雷达扫描深度图中估算深度具有重要意义。现有技术通常采用深度学习神经网络生成预测深度图。
深度补全模型[4]的性能主要取决于激光雷达的密度和精度。随着扫描密度的增加,雷达的成本将大大增加。目前,一台16 线Velodyne激光雷达的成本约为6000 美元,一台64 线Velodyne 激光雷达的成本约为8000 美元。对于自动驾驶来说,激光雷达对于探测车辆周围物体的距离至关重要,探测的准确性将影响车辆的行驶安全。如果车辆配备更精确、扫描更密集的激光雷达,无疑会大大增加成本。
同时,用于深度补全训练的准确值很难得到。KITTI数据集中的准确值是用64线Velodyne激光雷达对单个场景进行多次扫描的结果结合起来得到的,测量过程十分耗时。然而,使用在现有数据集上训练过的模型用于在稀疏激光雷达上进行深度补全,结果的精度往往不理想。
因此,研究如何利用已有的数据集来训练稀疏激光雷达扫描输入,并得到精确结果的深度补全模型具有现实意义。本文提出了一种无监督域自适应方法来解决这种问题。该方法可以提高密集激光雷达扫描训练的模型在稀疏激光雷达数据上的性能。
1 网络结构
1.1 深度补全网络
在本节中,首先构造一个疏密深度补全网络。参考疏密结构(sparse-to-dense structure),在网络中实现编码层和解码层。疏密网络结构如图1所示。

图1 基于深度补全的疏密深度卷积神经网络结构图
为了便于后续实验,首先构建一个简化的疏密网络。激光雷达扫描输出的是灰度图像,灰度值表示深度值。KITTI数据集中深度图的大小不统一,因此输入首先被裁剪成统一的大小,然后被送入网络中。裁剪后的训练数据将被转换成一维特征图,然后送到编码层。编码层用于从激光雷达扫描输入中提取特征。编码层使用预训练ResNet 的卷积层[5]。在保证反向传播过程的同时,ResNet 在提取深度特征方面表现良好。实验中使用的是预训练过的ResNet-18 网络的卷积层。
编码层由4 个卷积层(Conv)组成,每个卷积层包含最大池化层(MaxPool)和归一化层(Batch Normalization)。编码层生成的深度特征图将被送到解码层。解码层包含4 个上采样层,上采样层由上投影(Up-Projection)模块实现。上投影模块的结构如图2所示。

图2 上投影模块结构图
与传统的上卷积相比,上投影模块增加了一个短连接,类似于ResNet 中的res-block。通过这种结构,可以更好地传播特征[6]。实验表明,在深度补全任务中,该结构比传统的特征传播方法具有更好的效果。
同时,为了实现无监督域自适应算法,在上采样层之后增加一个掩码卷积层。在输入网络之前不对输出进行采样处理,以生成与输入大小相同的预测深度图。
1.2 深度补全的无监督域自适应算法
无监督域自适应(unsupervised domain adaptation,UDA)是一种能够使在带标签的源域数据上训练的模型在不带标签的目标域数据上表现良好的方法。源域和目标域两个数据集的数据存在偏差。每个领域都有一些本领域独有的特征,这可能对其他领域上有用数据产生干扰。UDA 的目标是在不同领域的数据之间找到“共同特征”进行学习。
为了应用UDA 算法,本文在疏密网络的基础上构造一个网络,使模型能够适应稀疏激光雷达的扫描输入。该网络结构如图3所示。

图3 基于无监督域自适应的适应疏密输入的网络结构图
其中,共享网络是疏密网络结构,由稀疏的和密集的激光雷达扫描输入共享。共享网络输出的特征图用来计算两个域之间的差异,表现为自适应损失。为了在减少差异的同时提高预测精度,对密集输入经过共享网络的输出进行卷积和上采样操作。最终的输出与对应的真实值进行比较,并计算缺失的均方差损失(mean squared error loss)。
首先,考虑将最大均值差异(maximum mean discrepancy,MMD)距离应用于无监督域自适应的深度补全算法[7]。本文构建了一个具有5核的多核最大均值差异(multiple kernel maximum mean discrepancy,MK-MMD)来表示自适应损失,MK-MMD 由多个单一的MMD 组成,MK-MMD计算如式(1)所示。本文使用MK-MMD对每个维度的特征进行自适应,并将所有维度的结果相加作为自适应损失。
用于深度补全的特征图比较大,在计算MMD 距离时对GPU 内存的要求比较高。与MMD 相比,计算CORAL 距离的特征二阶统计量需要的资源更少。因此,本文选用特征的二阶统计量来最小化两个域之间的距离。源特征图的二阶统计量与目标特征图的二阶统计量之间的距离如式(2)所示。
其中,d为特征矩阵的列数,为平方矩阵的Frobenius 范数,矩阵的Frobenius 范数被定义为矩阵中各元素绝对值的平方和,C为基于协方差矩阵的源特征和目标特征的非线性变换,表达式如式(3)所示。
其中:D为源数据和目标数据的特征矩阵。
2 实验结果与分析
2.1 实验设置
本文使用KITTI基准数据集进行网络训练和验证。原始数据集从KITTI网站下载。对原始数据按4∶1 比例采样得到稀疏激光雷达扫描深度图,原始数据集和稀疏数据集以相同的结构构造,而稀疏数据集中的真实值仅用于验证集。数据集分为三部分,包括训练集、验证集和测试集。网络通过训练集进行训练;验证集在每个训练集之后使用以避免过拟合;测试集对训练后的模型性能进行测试。该训练集包含超过80000 组激光雷达扫描数据。验证集包含超过4000组数据,测试集包含1000组数据。
2.2 评价指标
本文将采用均方误差(mean squared error,MSE)、平均绝对误差(mean absolute error,MAE)、逆深度均方根误差(root mean squared error of the inverse depth,iRMSE)和逆深度平均绝对误差(mean absolute error of the inverse depth,iMAE)作为评价指标,计算分别如式(4)~(7)所示。
2.3 实验结果
为了评估在训练过程中使用UDA 算法是否可以提高模型性能,我们比较了在原始密集数据上训练的模型和基于UDA 算法的训练模型的性能。模型的预测结果对比见表1。原始模型和基于MMD 和基于CORAL 方法的网络预测深度图如图4和图5所示。

表1 基于UDA方法的网络对于稀疏激光雷达扫描图的预测性能
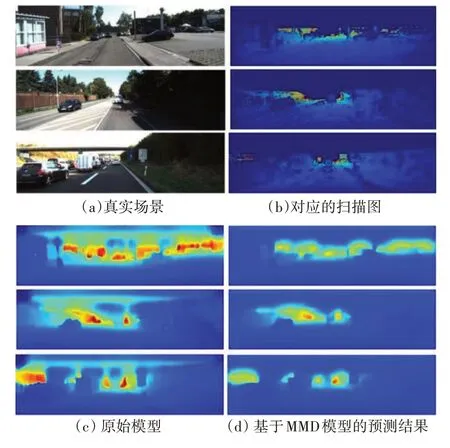
图4 原始模型与基于MMD的模型预测结果对比

图5 原始模型与基于CORAL的模型预测结果对比
可以看出,基于MMD 方法训练的网络的MSE 略好于基于CORAL 方法训练的网络,而其他三个指标相对较差;两种方法的预测结果的RMSE相对原始模型有所减小,这说明预测结果更加准确;对于基于MMD 的方法,其他三项指标相较原始模型表现更差。此外,从彩色的预测深度图中可以发现,基于CORAL 方法训练的网络预测出的深度图上的目标轮廓更加清晰,物体的轮廓更平滑,更容易区分;而对于未经UDA 训练的模型,虽然可以在预测结果中区分出目标位置,但目标轮廓存在一定程度的失真。
UDA 损失应用于疏密网络的深层结构中,能够使域差异达到最小化。因此,当输入稀疏激光雷达扫描图时,自适应后的网络可以生成与密集输入相对应的输出接近的预测结果。
3 结语
针对密集扫描激光雷达设备成本高、现有数据集训练的补全网络在稀疏激光雷达扫描输入表现不佳的问题,本文提出了一种网络适应稀疏输入的方法。该方法基于无监督域自适应算法,只需要稀疏的激光雷达扫描数据,以及现有数据集中提供的原始密集输入数据,从而减少了获取稀疏扫描数据集的成本。
无监督域自适应算法是使用特定的算法来量化来自不同领域的两个特征之间的差异。差异可以表示为不同域之间的距离,并通过损失函数计算,期望在训练过程中将其最小化。深度补全算法能够从激光雷达扫描图中得到预测的深度图。实验对比结果表明,该方法能在一定程度上提高模型预测的精度,基于无监督域自适应算法的方法预测的深度图可以显示更清晰、更平滑的目标轮廓。
