基于改进YOLOv7-tiny的雾天目标检测算法研究
2024-05-20高武阳张麟华
高武阳,张麟华
(1. 太原师范学院计算机科学与技术学院,晋中 030619; 2. 太原工业学院计算机工程系,太原 030008)
0 引言
在户外场景下,目标检测是一项至关重要的技术[1],其准确性和鲁棒性对于实际应用至关重要[2]。然而,在大雾天气场景下,由于光线减弱和物体边缘模糊等问题,导致算法性能下降,影响检测的准确性,从而带来挑战[3]。因此,对雾天场景下的目标检测进行研究具有重要意义。
随着深度学习技术的不断发展,深度学习逐渐成为目标检测领域的研究热点。与传统方法相比,深度学习模型可以直接从原始数据中进行学习,并通过在大规模数据集上进行训练而达到泛化的能力[4]。基于深度学习目标检测算法可分为两阶段检测算法和一阶段检测算法。两阶段检测器首先生成一组候选框,然后对每个候选框进行分类和位置回归。Faster R-CNN[5]是该类别中最具代表性的算法,它采用RPN[5]生成候选框,并利用ROI Pooling[6]对每个候选框进行分类和位置回归。在解决雾天条件下的目标检测问题时,Chen 等[7]提出了一种域自适应方法,该方法在源域和目标域之间对齐特征并适应域,从而提高了目标域中的检测性能。然而,这种方法需要更多的计算资源并且产生更高的成本,使得它们不太适合具有严格定时要求的实时应用。
一阶段检测算法直接对输入图像进行分类和位置回归,而不需要生成候选框。相比两阶段检测算法在速度方面具有显著优势,特别适合于实时应用。这类算法中最具代表性的是YOLO 系列[8-10]和SSD[11]。YOLO 将图像划分为网格,并预测每个网格单元的边界框和类概率,而SSD 在不同的特征层上预测不同大小的边界框与两级检测器。Fan 等[12]将YOLOv5与暗通道增强相结合,提出了减少草莓果实错摘和漏摘的解决方案。Baidya 等[13]在无人机检测场景下,为YOLOv5 增加了一个检测头,并加入了Conv-Mixers[14]。他们在VisDrone2021 数据集上训练和测试了提出的算法,取得了与最先进方法相当的结果。
然而,在复杂的天气和光照条件下,提高目标检测的准确性仍然是一个挑战。为了解决这一具有挑战性的问题,Huang 等[15]采用了两个子网来共同学习可见性增强和目标检测,通过共享特征提取层来减少图像退化的影响。Li等[16]基于YOLOv3 设计了一种完全可微的图像处理模块,用于雾天和低光场景下的目标检测。虽然这种图像自适应方法提高了检测精度,但也引入了一些噪声。
在关于雾天目标检测的研究中,虽然检测精度有所提高,但这些方法大多主要集中在去雾和图像增强上。本研究旨在使目标检测算法在不对原始图像进行任何预处理的情况下,在雾天场景中实现目标的准确检测。
1 基础模型
YOLOv7-tiny 算法是在YOLOv7 的基础上进行精简和改进后的算法。它改进了YOLOv7算法的高效远程聚合网络(ELAN),同时保留了基于级联的模型缩放策略,从而使得YOLOv7-tiny 算法在保证一定检测精度的基础上减少了运算的参数,提高了检测速度。YOLOv7-tiny 算法由输入、特征提取网络、特征融合网络和输出四个部分组成,如图1所示。

图1 YOLOv7-tiny网络结构
输入层用于接收传入的图片。在输入层,图片需要调整为3 通道640*640 大小的图片进而进入到下一个网络结构。特征提取网络包括CBL卷积块、改进的高效远程聚合网络(ELAN-T)层和MPConv 卷积层,它可以将一些原始的输入数据维度减少或者将原始的特征进行重新组合以便于后续的使用。特征融合的主要作用是将来自多个不同源的特征或特征提取器合并为一个更好的特征表示,以提高模型的性能。YOLOv7-tiny 的特征融合网络采用了YOLOv5 系列的路径聚合特征金字塔网络(PAFPN)架构,它可以通过特征信息融合实现多尺度学习。模型的输出使用了IDetect 检测头,类似于YOLOR 模型,同时引入了隐式表示策略,以基于融合的特征值来细化预测结果。
2 改进后的模型
本文对YOLOv7-tiny算法做了如下改进,首先是添加注意力机制SimAM[17],添加在YOLOv7-tiny网络的特征融合部分的CONCAT 模块后面。然后将YOLOv7-tiny 算法的损失函数CIoU 替换为wIoU[18]。改进后网络结构图如图2所示。

图2 改进后网络结构
2.1 添加注意力机制SimAM
在具有挑战性的天气条件下,如大雾环境,传统的卷积神经网络(CNN)在目标检测任务中面临一系列限制和挑战。首先,雾的存在会导致图像模糊、对比度降低,以及色彩失真,使得传统的卷积运算难以有效提取清晰的物体边缘和精细的细节。其次雾天场景中的光照变化和遮挡给传统CNN 准确定位和检测物体带来了挑战。Yang 等[17]提出了一种3D 注意力模块SimAM,不同于现有的通道/空域注意力模块,该模块无需额外参数,可以为特征图推导出3D注意力权值。该模块的大部分操作均基于所定义的能量函数选择,避免了过多的结构调整,从而能够提取出模糊图像的重要特征。注意力机制SimAM的添加位置和数量如图2所示。
图3中(a)代表通道注意力机制,(b)代表空间注意力,(c)为三维权重注意力,即SimAM 注意力。在每个子图中,相同的颜色表示每个通道,空间位置或特征上的每个点使用单个标量。大多数现有的注意力模块会从特征X生成一维或二维权重,从而为通道注意力和空间注意力拓展生成的权重,而三维注意力模块SimAM 会直接估算三维权重。通道注意力为一维注意力,它对不同通道区别对待,对所有位置同等对待。空间注意力为二维注意力,它对不同位置区别对待,对所有通道同等对待。这些会限制它们学习更多辨别线索的能力,因此三维权重注意力SimAM优于传统的一维和二维权重注意力。

图3 不同注意力机制对比图
SimAM 注意力不需要额外的训练参数,并使用能量函数E来计算目标像素点和周围像素点之间的关系。公式(1)是能量函数,其中t是目标神经元,λ是一个常数,而μ和σ2是在该通道内去除的目标神经元的均值和方差。在公式(2)中,使用sigmoid 函数将能量函数转换为像素权重,并采取一系列值限制。
2.2 损失函数改进
IoU-Loss 作为一种损失函数,用于度量预测边界框与实际注释之间的相似度,更侧重于预测结果与真实情况之间的重叠程度。它是衡量边界框之间相似性的最广泛使用的度量。YOLOv7-tiny 中的损失函数采用CIoU,CIoU 使用了复杂的函数计算,它在大量的计算过程中消耗了大量的算力,增加了训练时间。wIoU 提出了一种动态非单调聚焦机制,用“out-lieress”代替IoU 来评价锚框的质量,并采用梯度增益分配策略,既降低了高质量锚框的竞争力,又减少了低质量锚框产生的有害梯度,使wIoU 能够专注于低质量锚框,提高探测器的整体性能。因此,我们将YOLOv7-tiny 算法的CIoU 损失函数替换为wIoU。
wIoU 有三个版本,其中wIoUvl 构建了一个基于注意力的边界盒损失,wIoUv2 和wIoUv3 是在wIoUv1 的基础上在焦点机制中加入梯度增益得到的。wIoUv1 的损失函数计算公式如公式(3)~(5)所示。
wIoUv2 的损失函数计算公式如公式(6)所示。
式(6)中:表示单调注意系数,为均值,在公式中进行归一化,使梯度增益保持在较高水平。
wIoUv3 的损失函数计算公式如公式(7)和(8)所示。
式(7)和(8)中:β为非单调聚焦系数,α和δ为超参数。当β=δ,r= 1,且锚框的离群度满足β=C(C为固定值)时,锚框将获得量高的梯度增益。β和r的值由超参数α和δ控制。
3 实验设置及结果
3.1 实验设置
3.1.1 实验环境
实验在配备了4个NVIDIA 3090Ti 的服务器上进行,CPU为Intel Xeon(R)silver 4210R。实验环境由ubuntu18.04.4LTS、Python 3.8、PyTorch 1.8.0、CUDA 11.1组成。在训练阶段,使用随机梯度下降优化器进行训练。初始学习率为0.01,动量因子设置为0.937,权重衰减设置为0.1,训练轮次设置为300,图像的分辨率设置为(640*640)。
3.1.2 数据集
本次实验选择的是ug2 数据集,ug2 数据集是一个有雾场景下的目标检测数据集。该数据集包括真实世界有雾场景下的图片和部分人工合成的有雾图片。该数据集共包括4320 张图片和对应的标签。该数据集共包含五个类别的标签,分别是行人、小汽车、大巴、自行车和摩托车。由于原始数据集是VOC 格式的,并不适合本算法的直接使用,因此本数据集在使用前,首先进行了格式转换和预处理操作,为了保证算法的通用性和鲁棒性,我们将数据集按照7∶1∶2 的比例划分训练集、验证集和测试集。为了增加样本的多样性,提高网络的性能,使用默认的图像数据增强如缩放、图像翻转、马赛克和混合等进行训练。
3.2 评价指标
本文实验的评价指标包括平均精度mAP0.5、mAP0.5∶0.95、参数Params 和浮点数Flops。平均精确度mAP 用于度量目标检测模型预测框类别和位置是否准确。在多类别目标检测中,通常对目标类别分别计算AP 值后再求平均值,得到的平均精确率mAP用来评价检测模型性能的优劣。mAP0.5表示IoU 为0.5 时所有类别的平均AP,mAP0.5∶0.95表示不同IoU 值(从0.5 到0.95,步长为0.05)下的平均mAP。mAP 的计算公式如公式(9)~(13)所示。Params 是网络模型的加权参数量。Flops 是模型在操作中使用的浮点运算数,用来反映模型的复杂度。
其中:TP为将正类预测为正类的数量;FP为将负类预测为正类的数量;FN为将正类预测为负类的数量;P为准确率,R为召回率,AP为平均准确率,APi为单一类别的识别平均准确率,N为总类别数。
3.3 实验结果
本次实验的基础模型是YOLOv7-tiny,改进后的算法在训练过程中的收敛情况如图4所示。
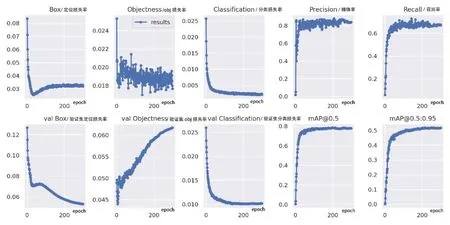
图4 模型训练过程
从图4可以看出,改进后的网络模型大约在50 个epoch 后各种类型的损失下降到一个较低的水平,并且随着训练的进行,损失值继续缓慢下降。网络模型在100 个epoch 后基本达到收敛,其训练集和验证集的类别损失、定位损失和obj损失均正常收敛。在200 个epoch 之后mAP0.5和mAP0.5∶0.95也趋于稳定并最终达到收敛水平。收敛后mAP0.5为0.782,mAP0.5∶0.95为0.515。
3.3.1 消融实验
为了验证本文所使用的方法在遥感目标检测中的实际效果,在ug2 数据集上对改进的模块进行一系列的消融实验,结果见表1。

表1 消融实验结果
从表1 可以看出,YOLOv7-tiny 算法的mAP0.5为0.765,而mAP0.5∶0.95为0.480。当给YOLOv7-tiny 算法增加了SimAM 注意力机制后,其mAP0.5为0.774,mAP0.5∶0.95为0.496,相比YOLOv7-tiny 算法mAP0.5提高了0.9 个百分点,mAP0.5∶0.95提高了1.6个百分点。YOLOv7-tiny 算法增加了SimAM 注意力机制和wIoU 损失函数之后,其mAP0.5为0.782, mAP0.5∶0.95为0.515,相比只增加了SimAM 注意力机制的算法,mAP0.5提高了0.8 个百分点,mAP0.5∶0.95提高了1.9 个百分点。与YOLOv7-tiny 算法相比,本文算法mAP0.5提高了1.7 个百分点,mAP0.5∶0.95提高了3.5 个百分点,同时Params 和GFLOPs 略有增加。这说明了本文改进算法的有效性。
3.3.2 训练曲线对比
本文在保证实验条件一致的前提下,分别对YOLOv7-tiny 算法和逐步改进后的算法进行训练,训练曲线如图5 所示,我们从两个指标对YOLOv7-tiny 和改进后算法进行对比,分别是mAP0.5和mAP0.5∶0.95。可以看出,随着epoch 的增加,mAP0.5和mAP0.5∶0.95均稳步上升。改进后的算法一开始就表现出了优于YOLOv7-tiny 的特性,随着训练的进行,曲线逐渐收敛,并在100 个epoch 左右接近收敛状态。逐步添加改进点的算法在收敛后表现出了梯度性,这表明注意力机制SimAM 和损失函数wIoU 改进点都能带来检测效果的提升,并能够相互兼容。
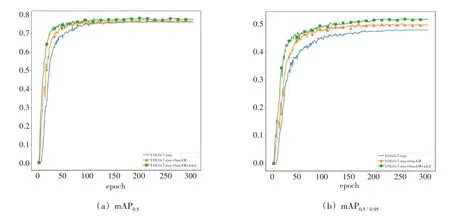
图5 改进方法对比图
3.3.3 检测结果对比
为了更为直观地验证算法的有效性,我们对雾天户外目标检测结果进行了对比展示,分别使用YOLOv7-tiny 算法和本文改进的算法对遥感图像进行可视化实验展示,检测结果如图6 所示。其中(a)为YOLOv7-tiny 算法的检测结果,(b)为改进后算法的检测结果。可以看出,YOLOv7-tiny 算法在检测有重叠和遮挡目标时出现了漏检的情况,改进后的算法克服了部分遮挡和漏检的问题。同时在YOLOv7-tiny 算法和改进后算法均检测到的目标中,改进后算法检测的目标置信度也高于YOLOv7-tiny 算法,这证明本文算法是有效的。
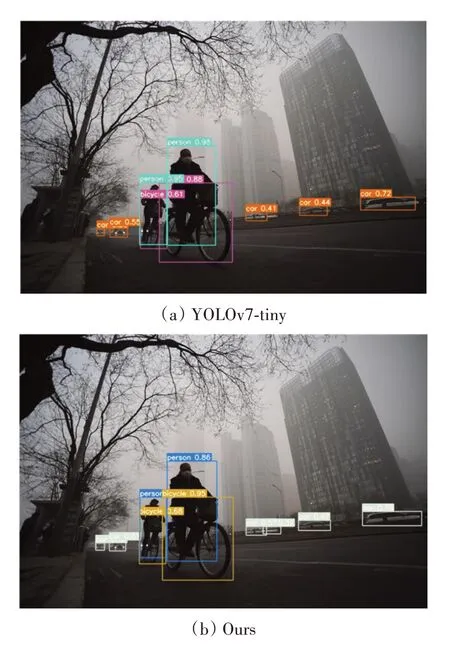
图6 检测效果对比图
4 结语
在大雾天气场景下,由于光线减弱、物体边缘模糊、目标重叠遮挡等问题,导致算法性能下降,从而影响检测性能。本文在YOLOv7-tiny 算法的基础上对算法进行改进,通过增加注意力机制和改进损失函数的方法来提高算法的检测性能。具体来说就是首先在网络的CONCAT 结构后面添加SimAM 注意力机制,从而优化特征融合,然后替换原来的CIoU 损失函数为wIoU,从而在整体上提高锚框的检测性能和定位准确度。结合了这两种改进方法的算法在保持一定计算复杂度的基础上提高了检测性能,适合应用于雾天场景下的户外目标检测任务。
